7-quantification
MMML Tutorial Challenge 6: Quantification
定义:
Empirical and theoretical study to better understand heterogeneity, cross-modal interactions, and the multimodal learning process.

Sub-Challenge 1: Heterogeneity
定义:
Quantifying the dimensions of heterogeneity in multimodal datasets and how they subsequently influence modeling and learning.
对于modality异质性的探究有以下几个维度:

有研究者对modality biases进行了探究,例如在下面的VQA task中,因为训练集中80%的banana都是黄色的,因此在使用一个绿色的banana image进行测试的,VQA model也错误的回答成了黄色:
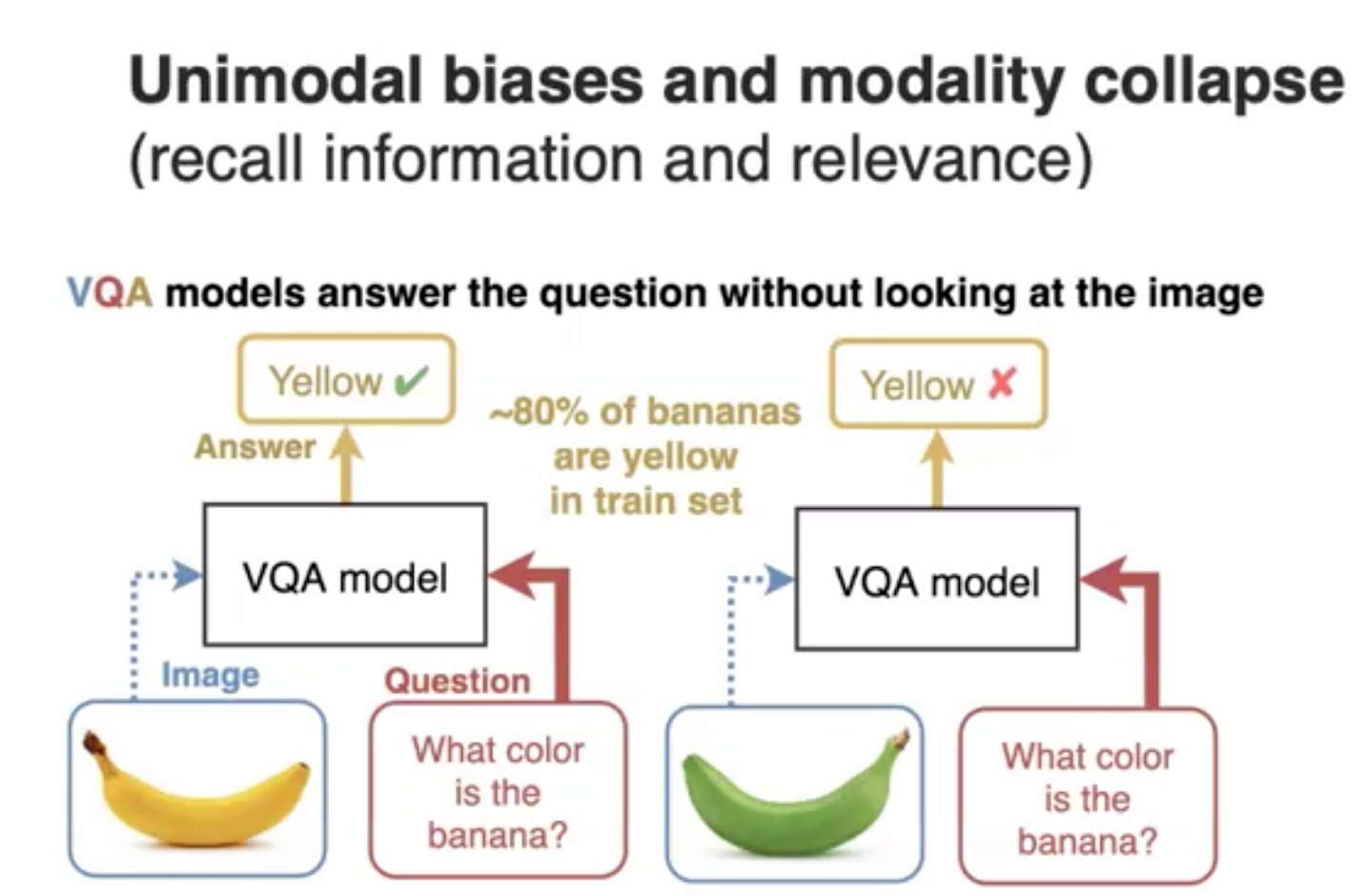
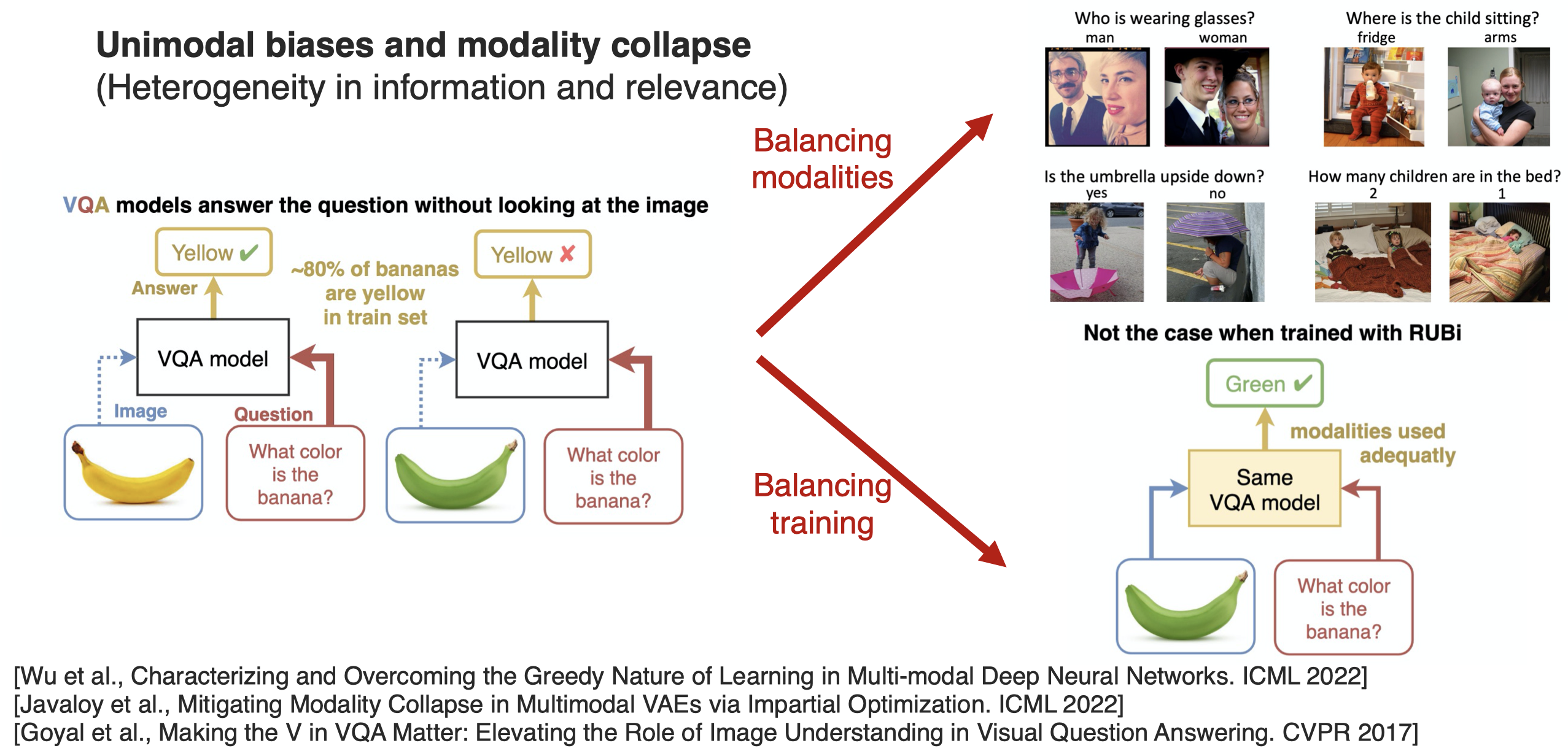
为了解决这个问题,研究人员提出了两种方法。第一种是直接从数据集的角度进行平衡;第二种是从训练过程进行平衡,让VQA model不仅仅依赖于单一的modality,而是也能够充分利用visual modality的信息:
在单模态中也存在social biases。比如下面的例子,模型会简单的根据桌子上有一个电脑而错误的认为在桌子前的是男性;也会因为图片中一个人手里拿的是网球拍,就认为这个人是男性(Hendricks et al., Women also Snowboard: Overcoming Bias in Captioning Models. ECCV 2018):

另外的研究发现,跨模态反而可能进一步增加social biases:
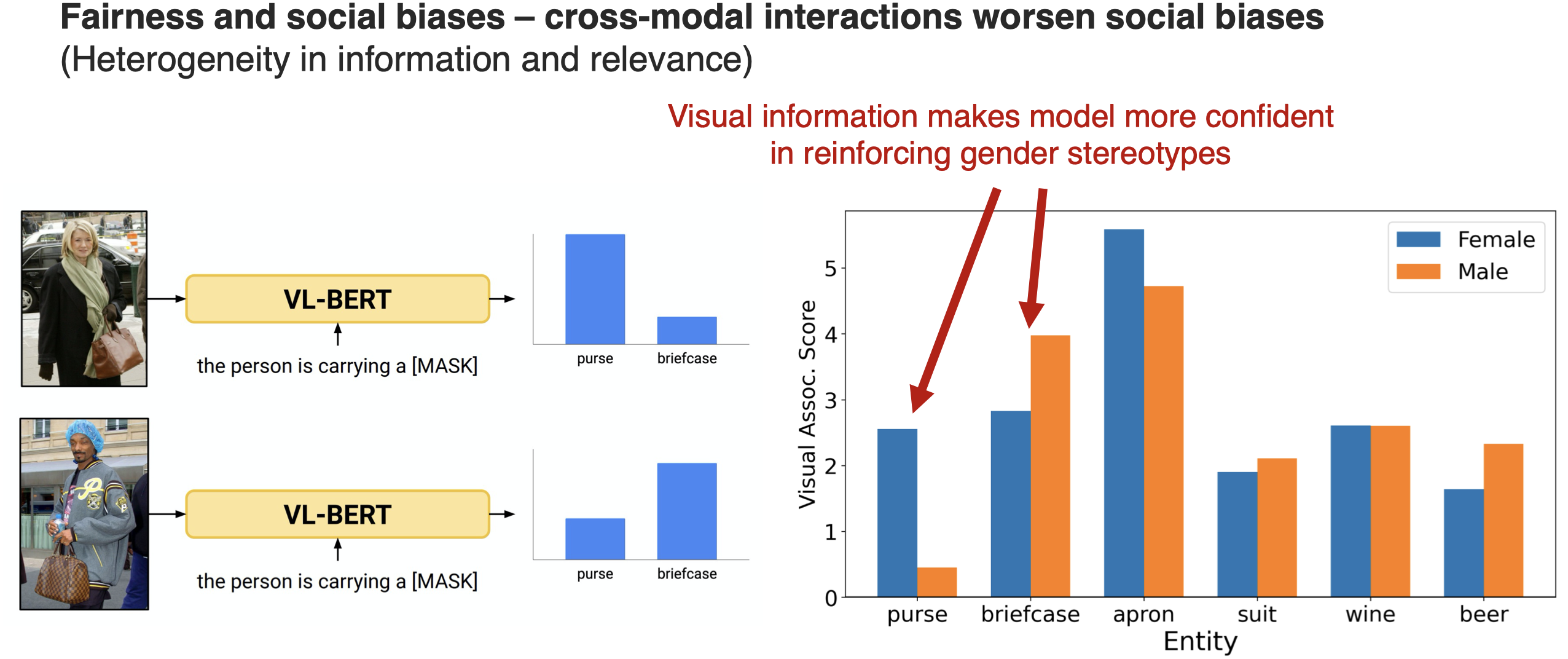
引入visual information之后反而进一步增加了对性别的刻板印象(stereotype),比如总是认为男性带公文包;女性带钱包。
有研究针对heterogeneity中存在的噪音、多模态模型对于缺失模态的鲁棒性、多模态模型性能和鲁棒性的关系进行了探究:
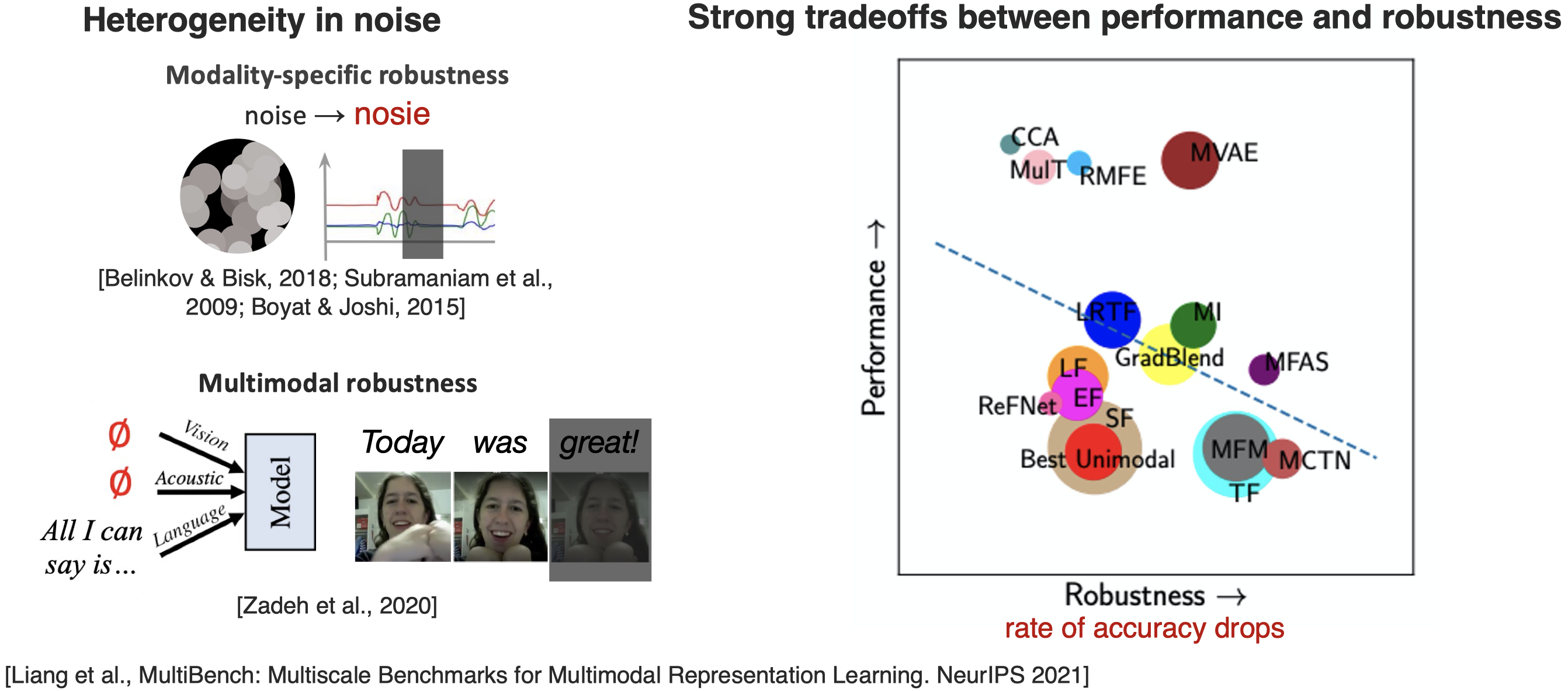
为了提升模型的鲁邦性,有几种方法被提出:
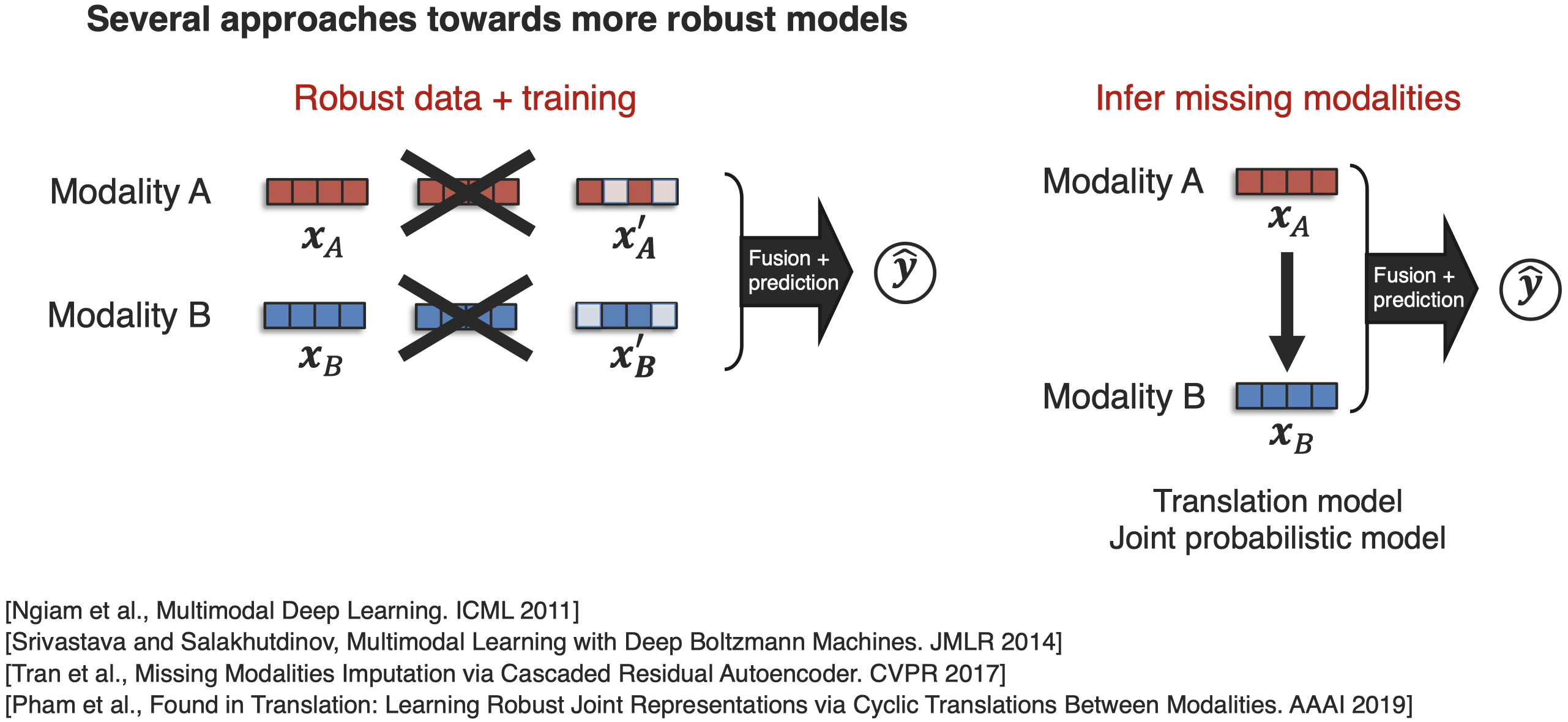
比如在训练时就人为遮盖掉不同的modality input;使用modality translation来推测缺失的modality等。
Sub-Challenge 2: Cross-modal Interactions
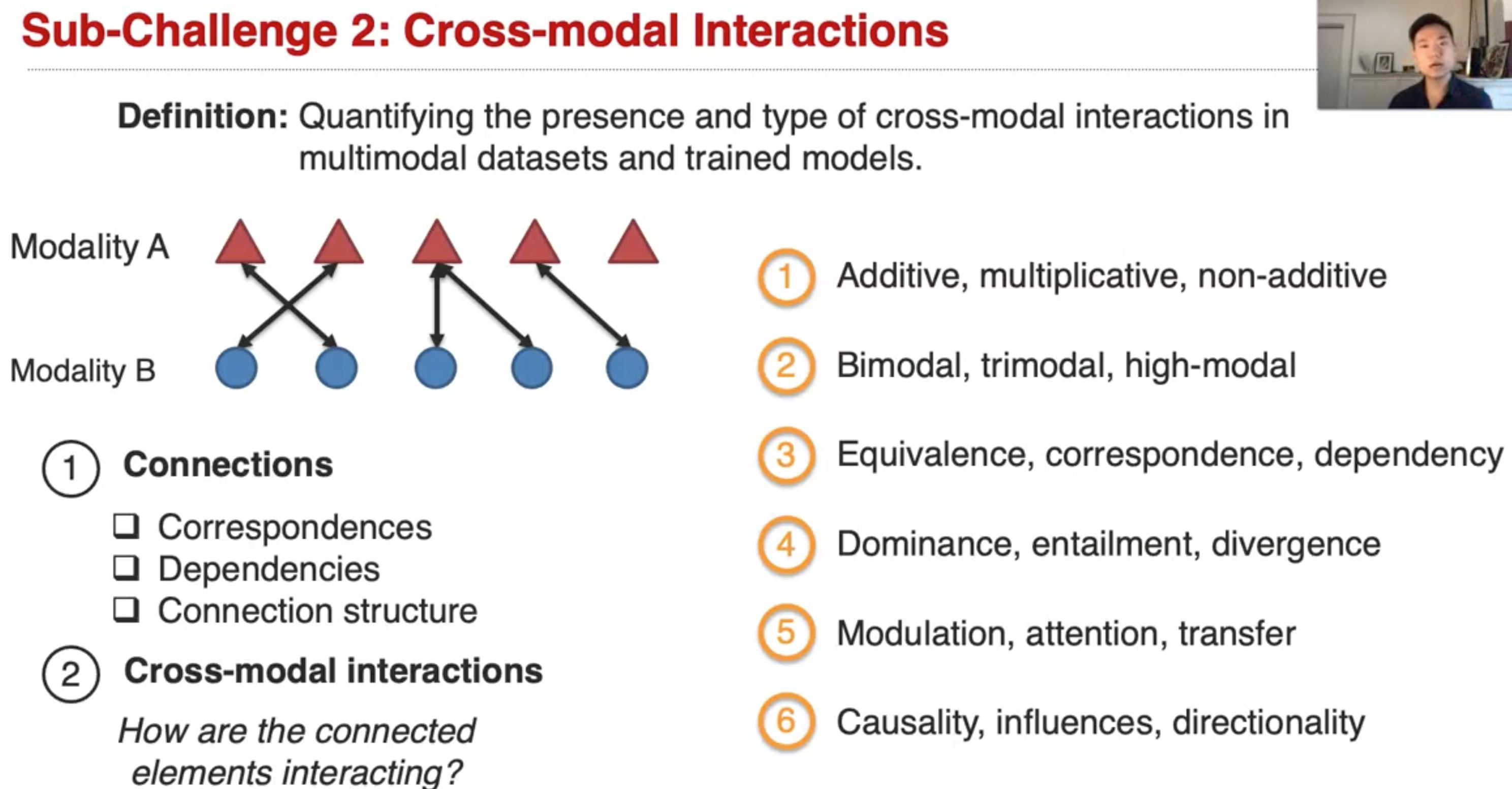
cross-modal interaction尝试解释不同模态element之间的联系:
Quantifying the presence and type of cross-modal connections and interactions in multimodal datasets and trained models.
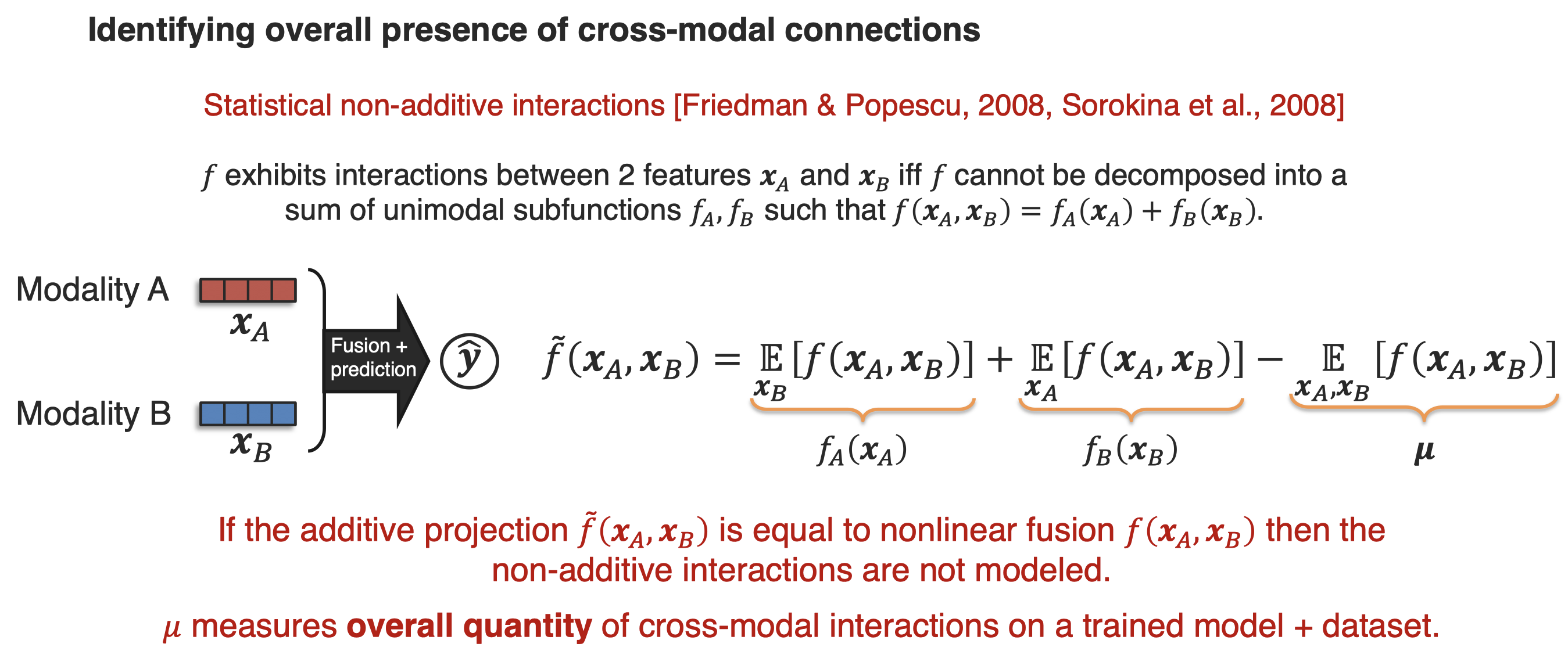
下面的工作通过representation fission确定了overall cross-modal interaction的存在:
接下来,研究人员对individual cross-modal interaction进行了探究(Liang et al., MultiViz: An Analysis Benchmark for Visualizing and Understanding Multimodal Models. arXiv 2022):


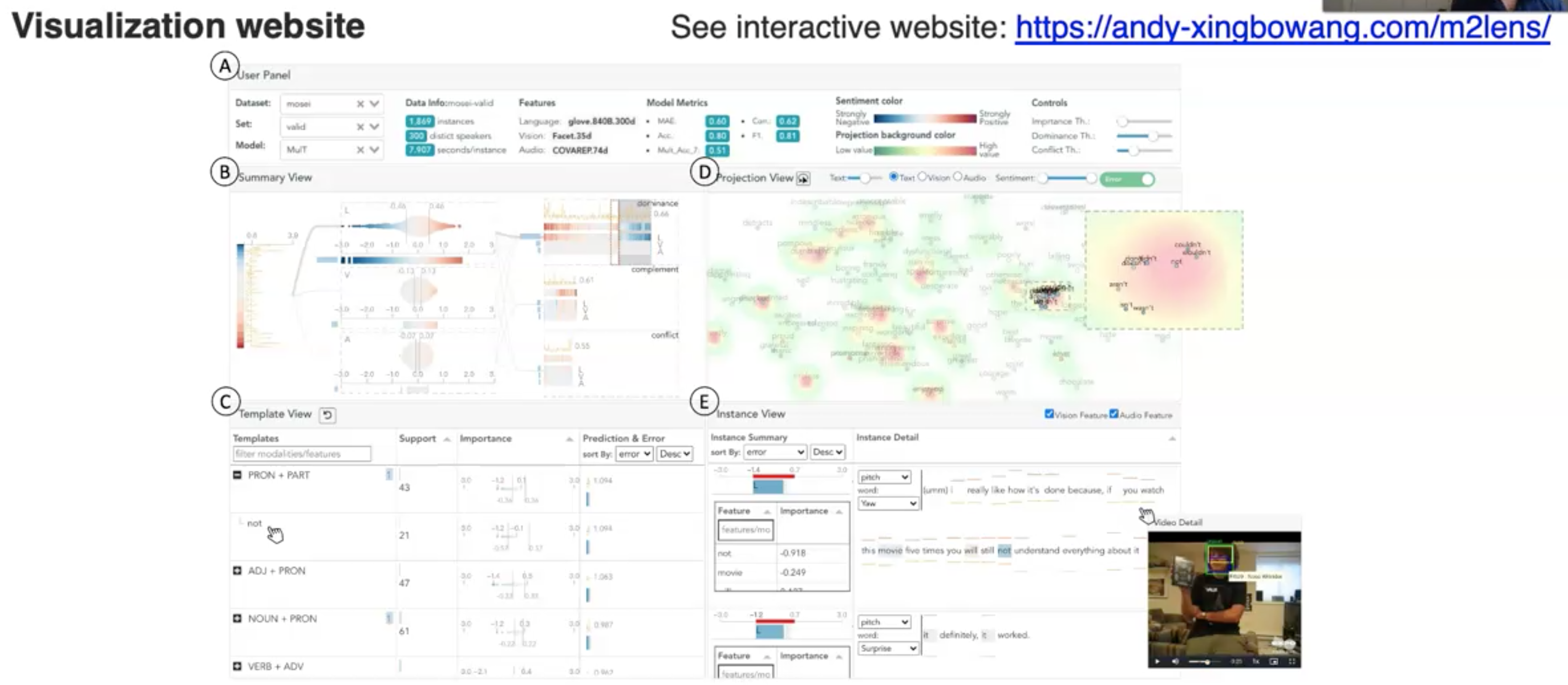
进一步,M2Lens对cross-modal interaction进行了分类(Wang et al., M2Lens: Visualizing and Explaining Multimodal Models for Sentiment Analysis. IEEE Trans Visualization and Computer Graphics 2021):
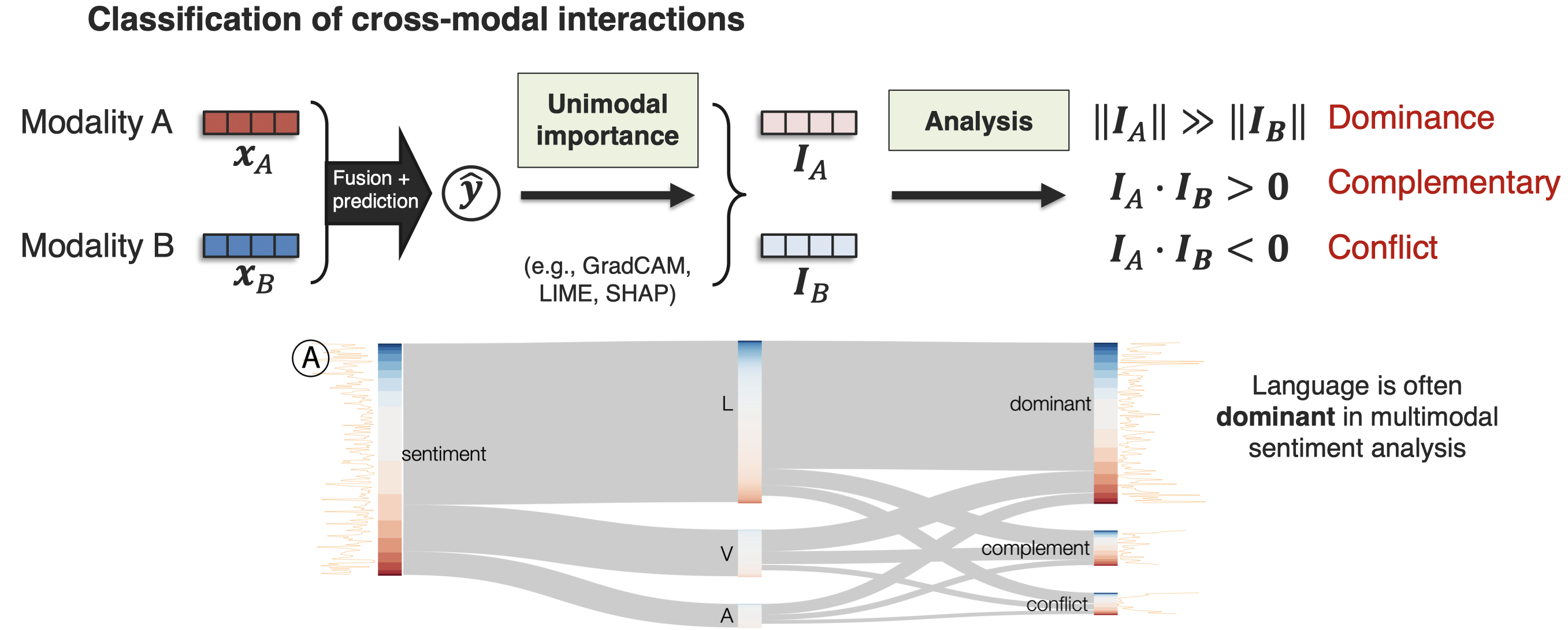
作者还提供了一个可视化的网站:
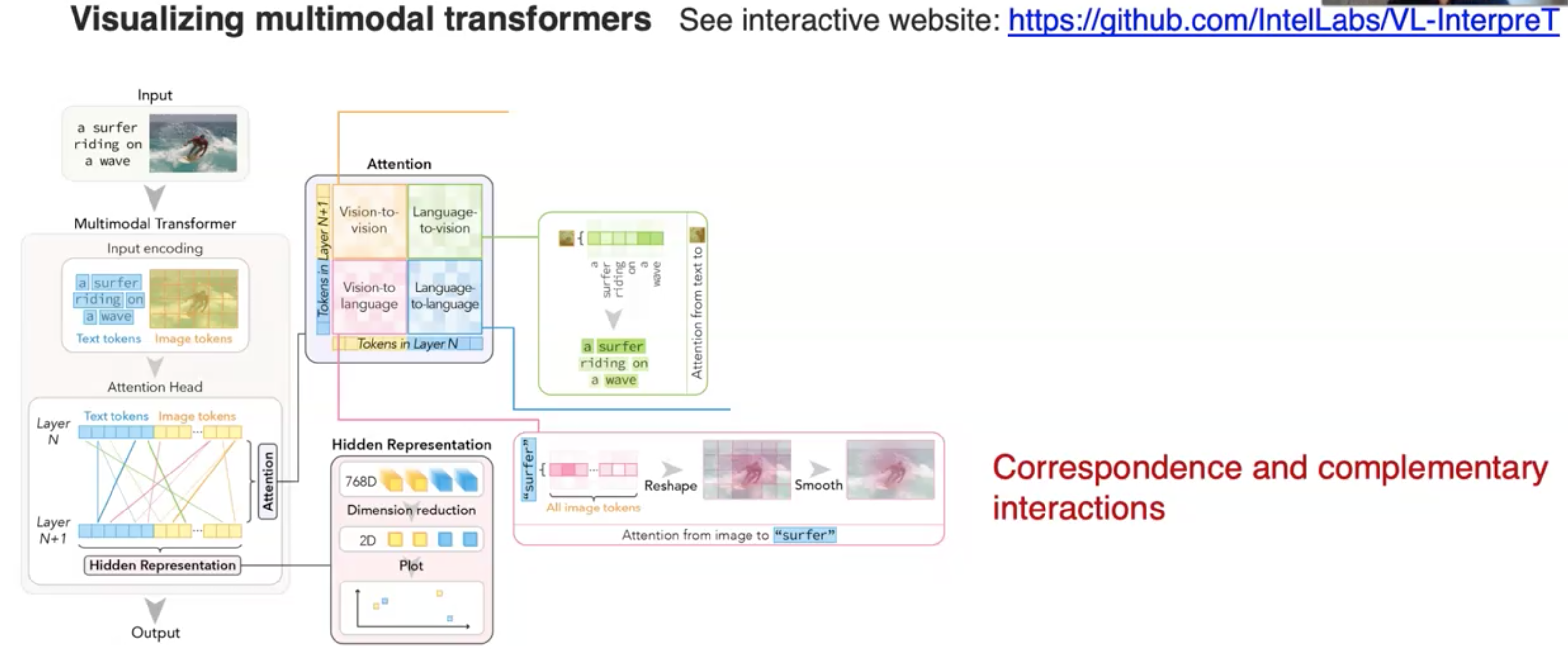
最近的,研究者实现了multimodal Transformer的可视化(Aflalo et al., VL-InterpreT: An Interactive Visualization Tool for Interpreting Vision-Language Transformers. CVPR 2022):
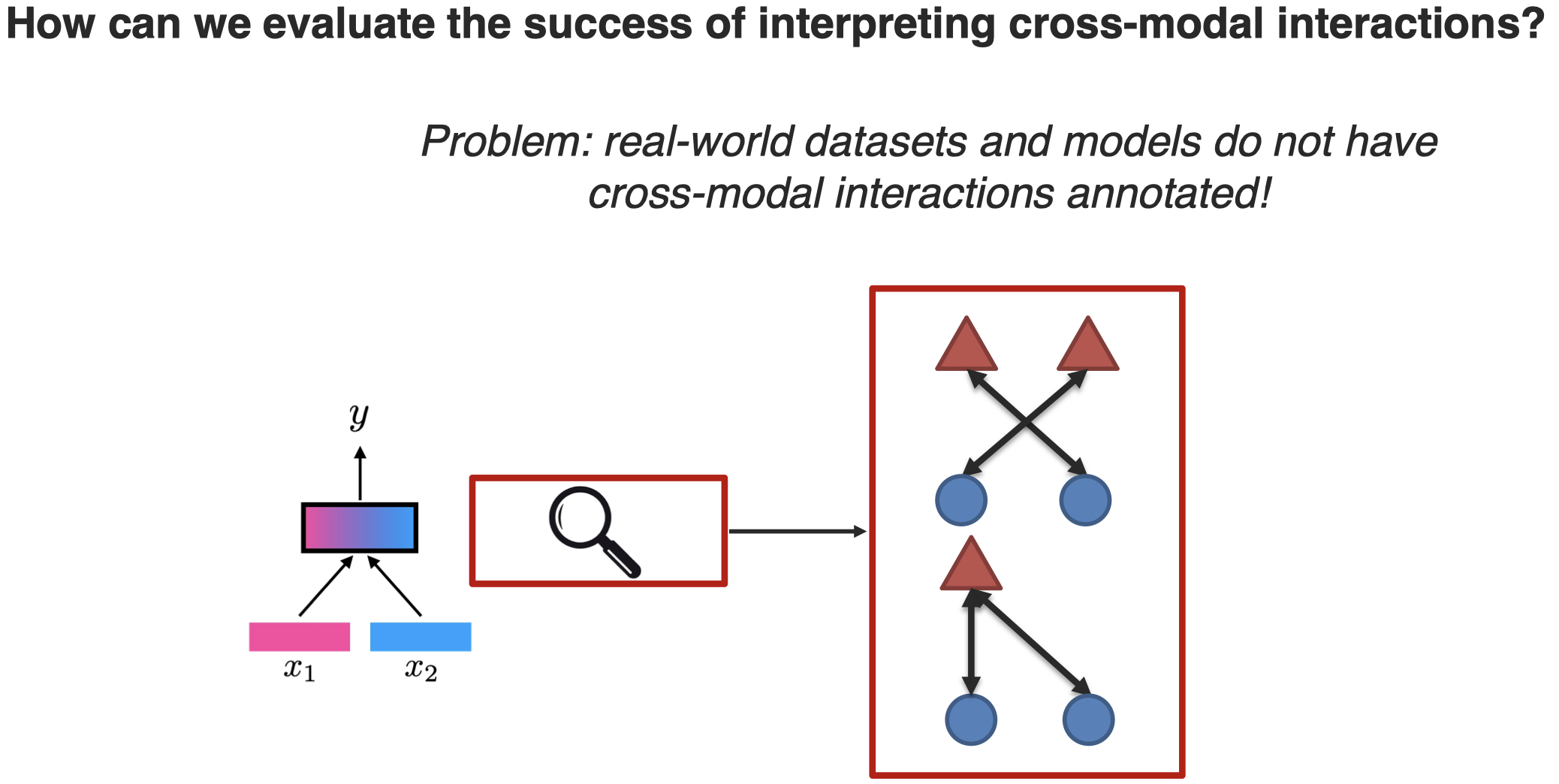
另外有研究者尝试对interoperation model进行评估,因为虽然这些model本身是用来解释multimodal model的,但是这些方法解释的是否正确,能不能让人真的理解,还需要进一步评估。
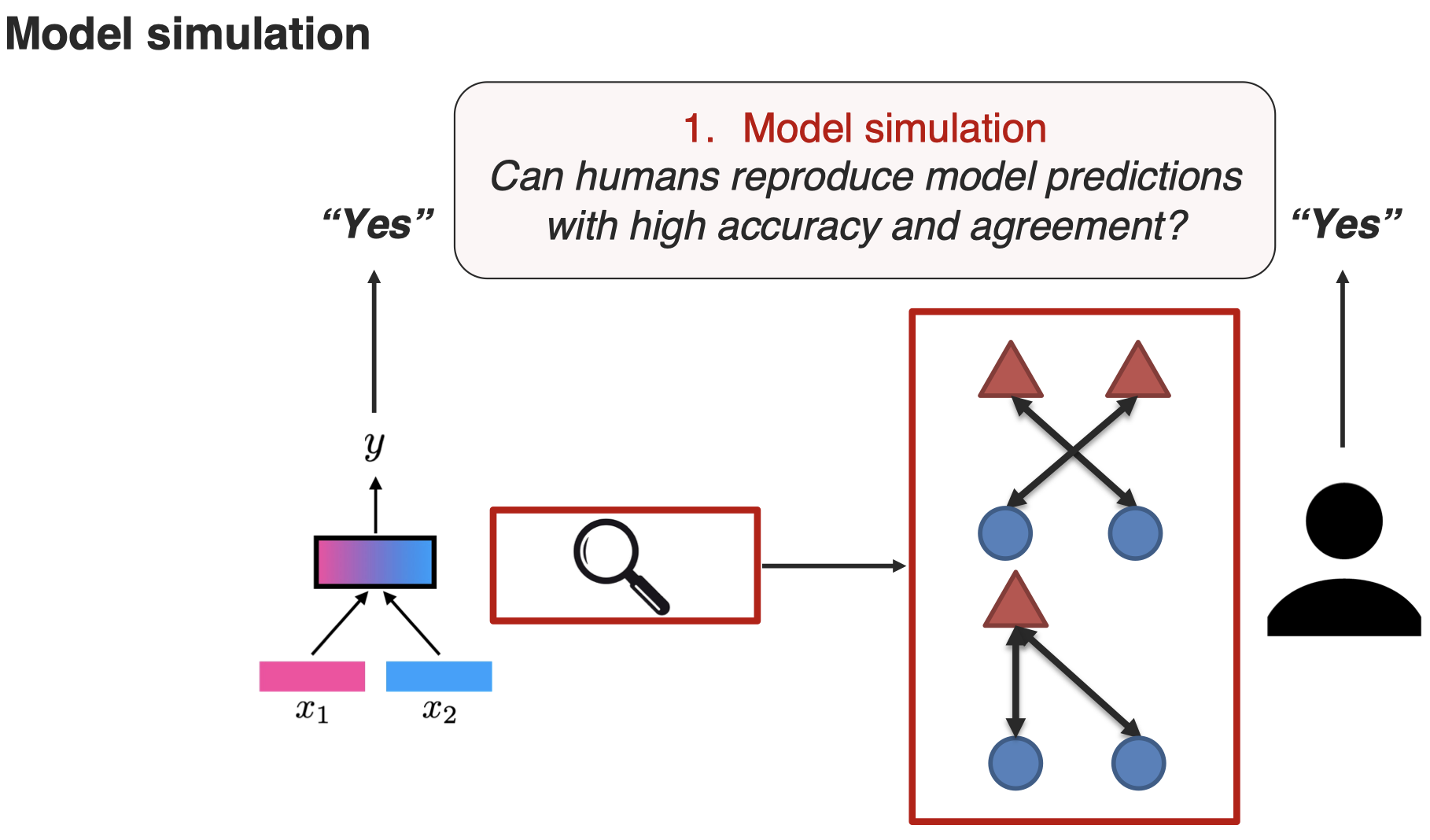
evaluating interoperation model是一个非常challenging的方向,一个最新的方法是引入人工来评估(Liang et al., MultiViz: A Framework for Visualizing and Understanding Multimodal Models. arXiv 2022):
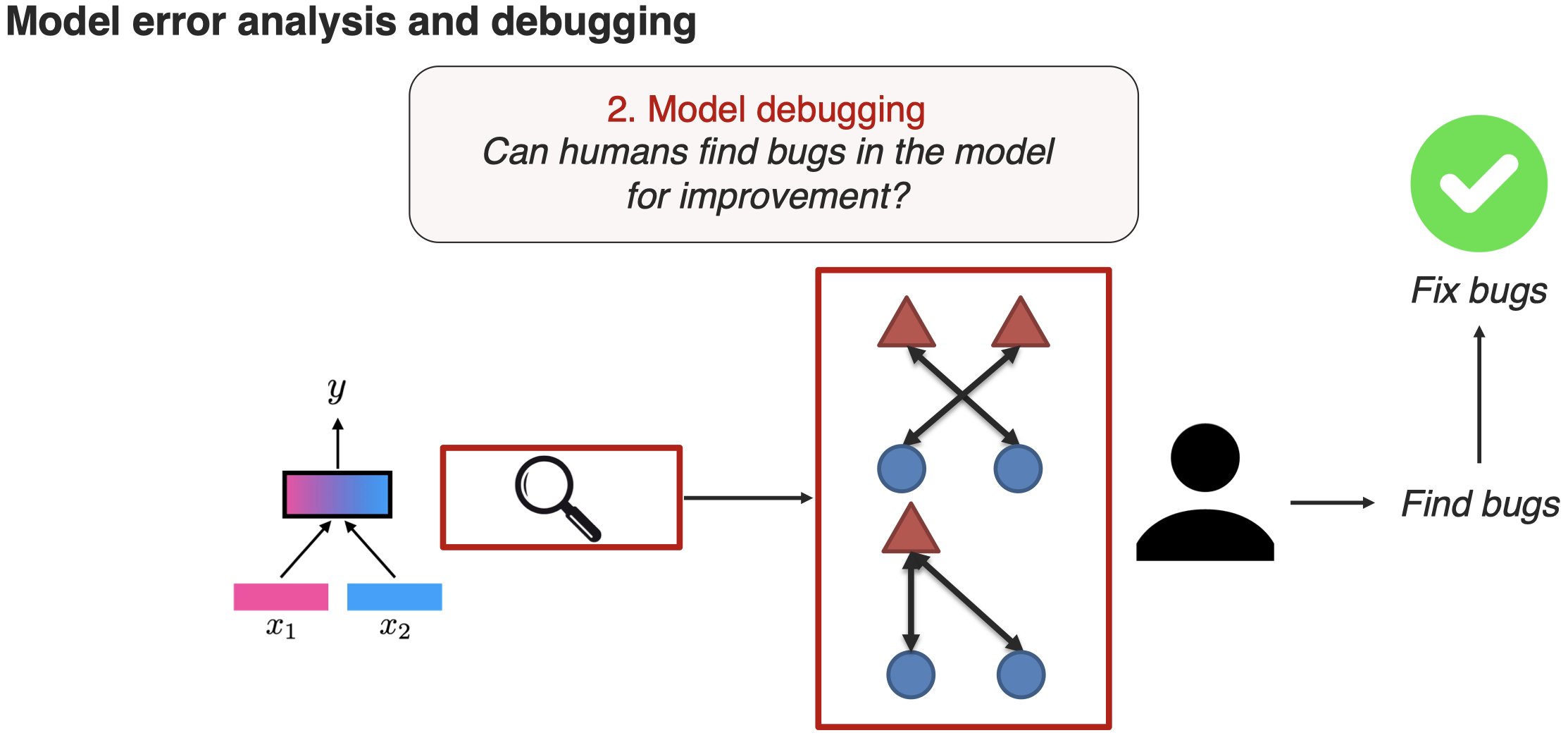
这一方向还有很多的挑战:
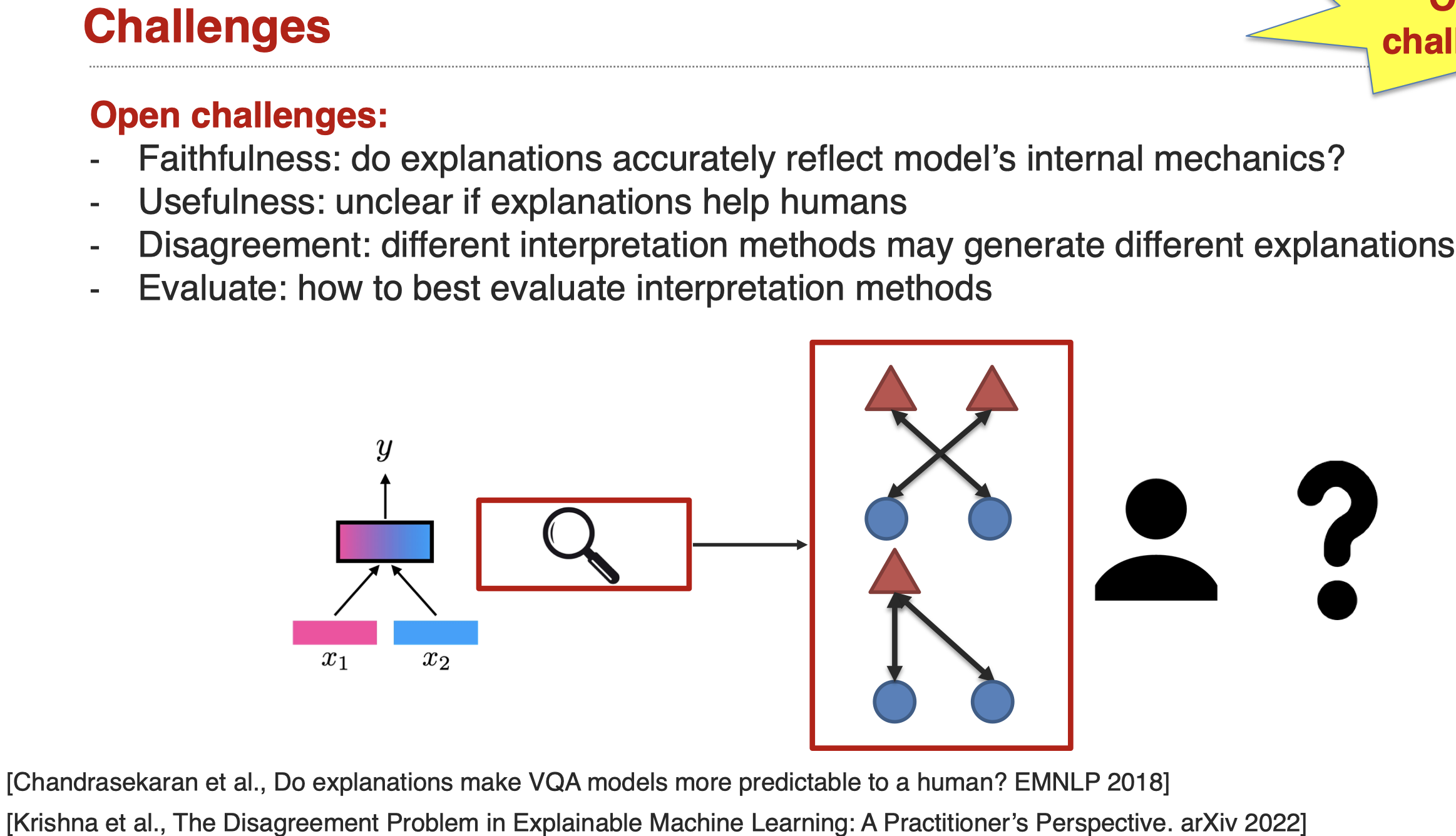
Sub-Challenge 3: Multimodal Learning Process
接下来是对multimodal learning process的探究:
Characterizing the learning and optimization challenges involved when learning from heterogeneous data.
例如在下面的一个例子,引入新的modality总能够带来更好的性能吗?(Wang et al., What Makes Training Multi-modal Classification Networks Hard? CVPR 2020)

答案是没有,在上面的实例中,更多的modalities并没有带来更好的性能,相反它意味着更大的计算复杂度,实际上是一个更糟糕的结果。
一种可能的解释是,不同模态的过拟合-泛化的合适点不是一致的(Wang et al., What Makes Training Multi-modal Classification Networks Hard? CVPR 2020):

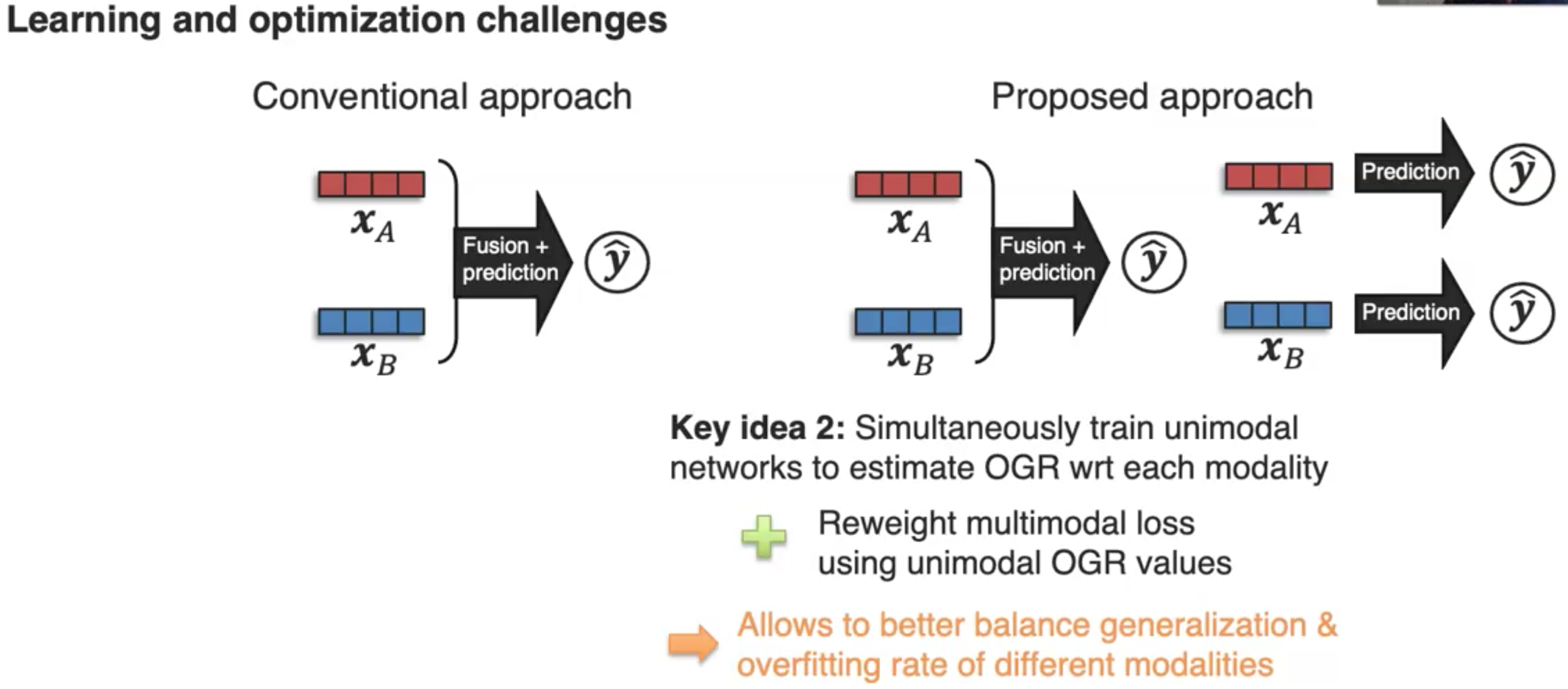
解决这一问题的作者提出的方法是,首先通过记录training checkpoints来得到不同modality的overfitting-to-generalization ratio(OGR):
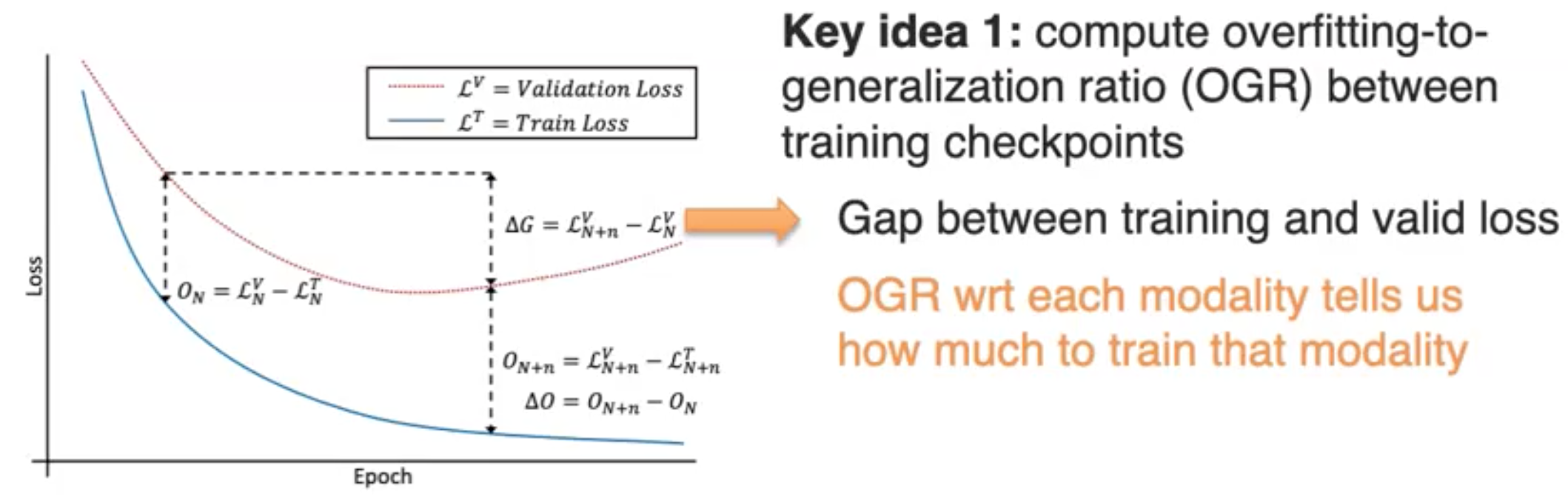
然后尝试在不同模态的OGR之间进行平衡:
除了上述三个challenge外,还存在许多的challenges:
