6-transference
MMML Tutorial Challenge 5: Transference
Transference是指对于一个资源可能受限的主modality,使用另外的modality进行辅助。定义:
Transfer knowledge between modalities, usually to help the primary modality which may be noisy or with limited resources
存在两个可能的关键挑战:
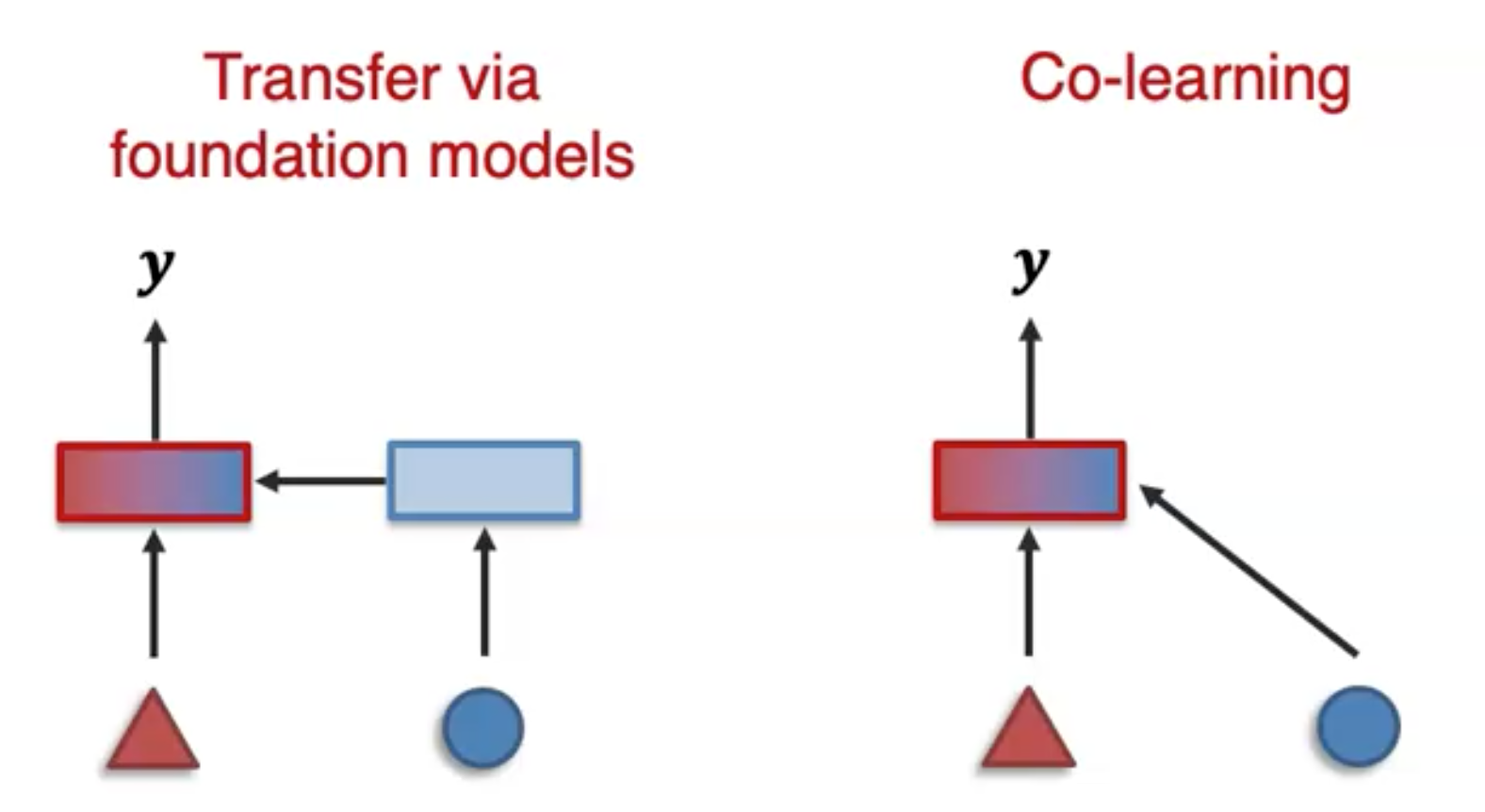
Sub-Challenge 1: Transfer via Foundation Mondels
challenge定义,通过利用pretrained model来迁移knowledge:
Adapting large-scale pretrained models on downstream tasks involving the primary modality.

下面是一个利用language model辅助visual task的实例(Tsimpoukelli et al., Multimodal Few-Shot Learning with Frozen Language Models. NeurIPS 2021):

在这个过程中,提前训练好的language model的参数是不变的。
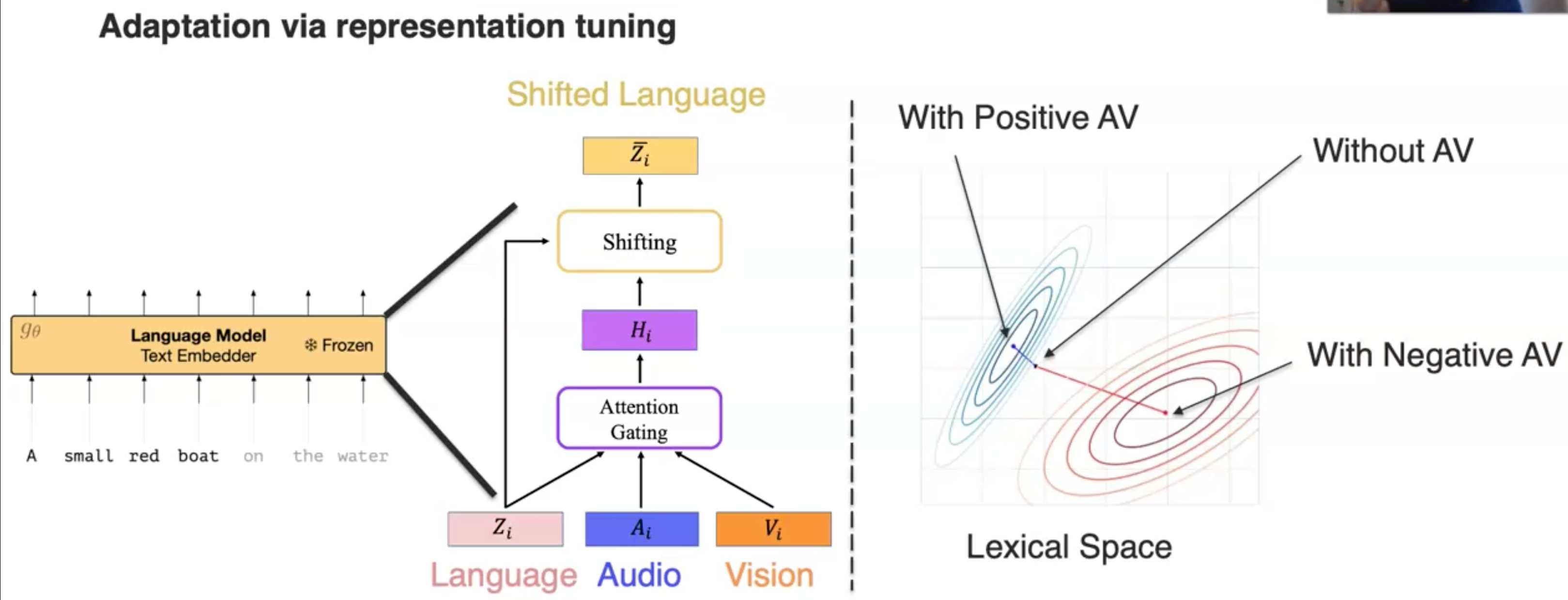
还有一个方法是representation tuning,例如下面的例子,通过self-attention衡量audio information和vision information对language representation的重要程度,然后shift language representation(Ziegler et al., Encoder-Agnostic Adaptation for Conditional Language Generation. arXiv 2019, Rahman et al., Integrating Multimodal Information in Large Pretrained Transformers. ACL 2020):
还有研究者使用multitask learning进行模态信息的迁移(Liang et al., HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning. arXiv 2022):

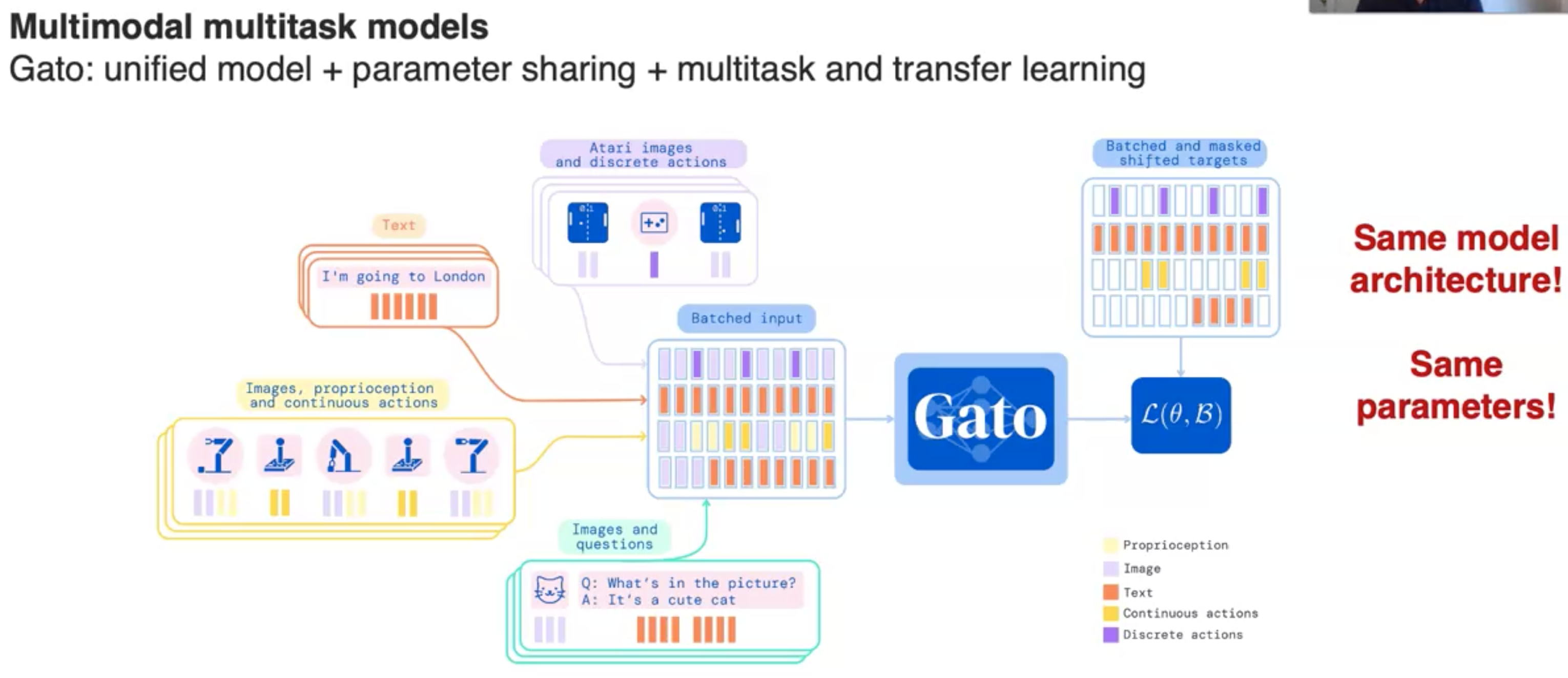
还有类似的Gato(A Generalist Agent):
Sub-Challenge 2: Co-learning
通过共享representation space来transfer information,定义:
Transferring information from secondary to primary modality by sharing representation spaces between both modalities.
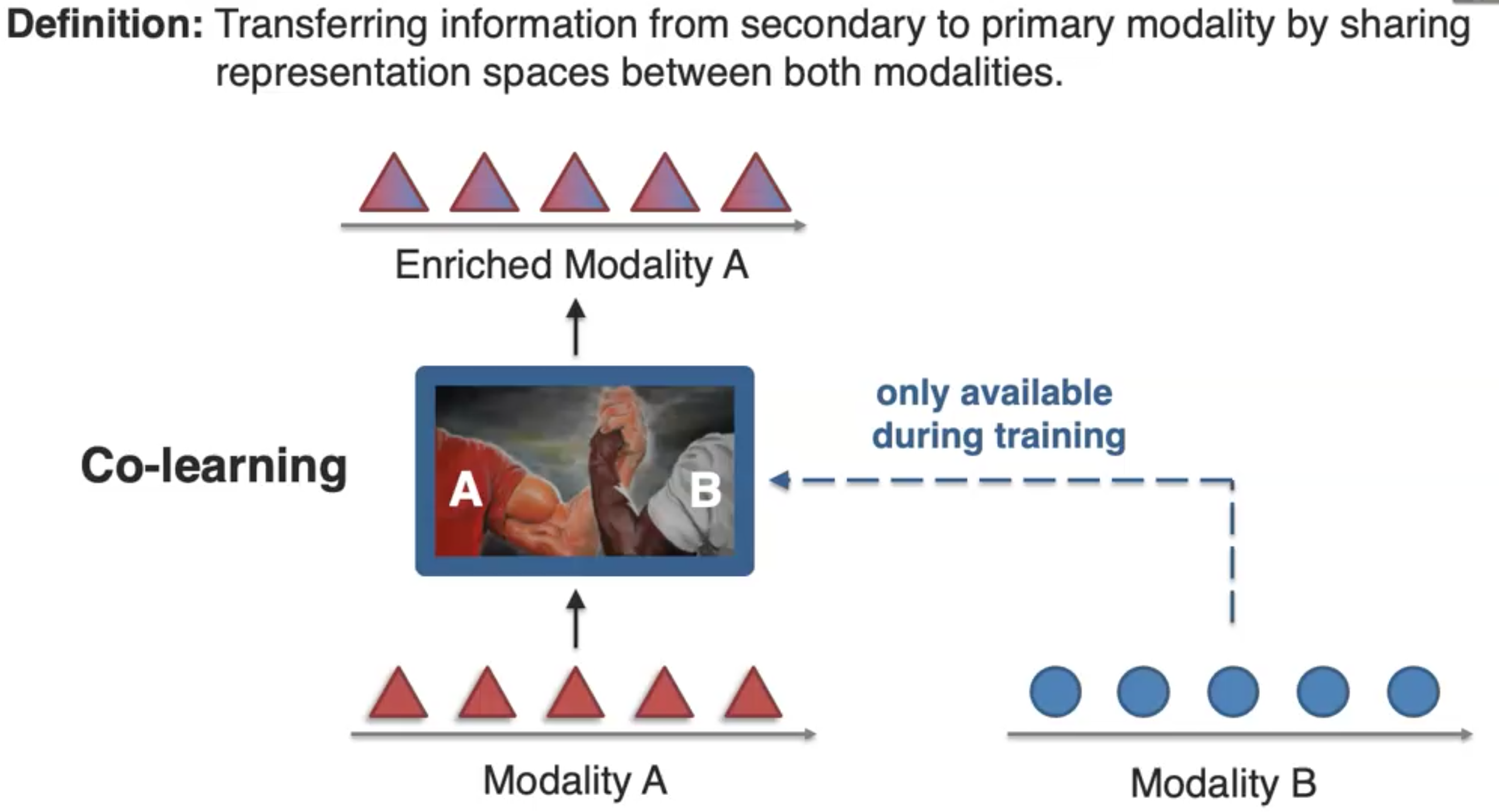
对于如何引入modality B,有两种方式:

可以在input layer融合modality B,也可以在prediction layer引入modality B。
Co-learning via fusion
一个通过fusion进行co-learning的实例如下图(Socher et al., Zero-Shot Learning Through Cross-Modal Transfer. NeurIPS 2013)。它通过把image embedding靠近相应的word embedding,比如horse image embedding应该接近horse word embedding。在实现的时候,采用了challenge 1 representation中的coordination方式,让两个在不同空间的表示互相协作靠近。这样做好友一个好处就是它可以用于zero-shot,比如对于从来没有见过的class cat。因为我们已经学习到了cat的word embedding,通过model处理后,cat的image embedding应该会靠近cat word embedding。

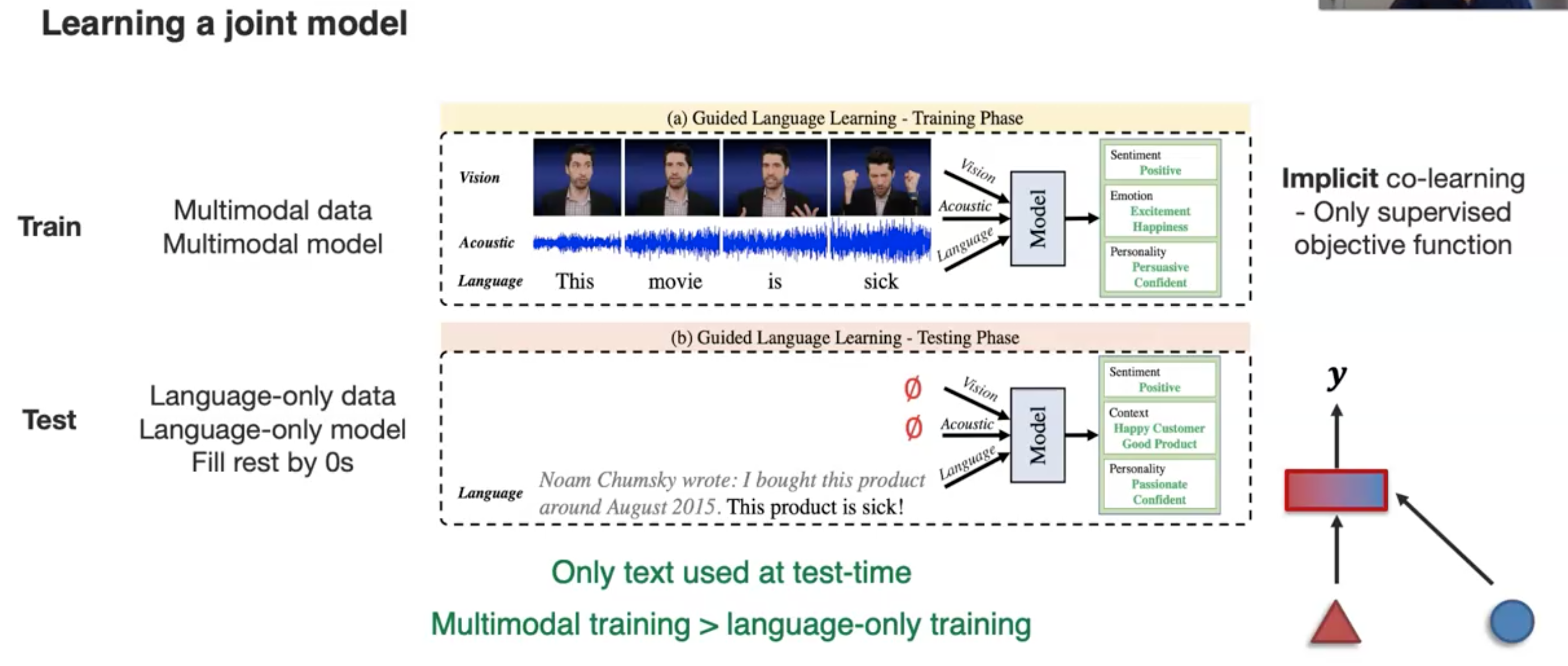
另一个实例是学习joint model(Foundations of Multimodal Co-learning.):
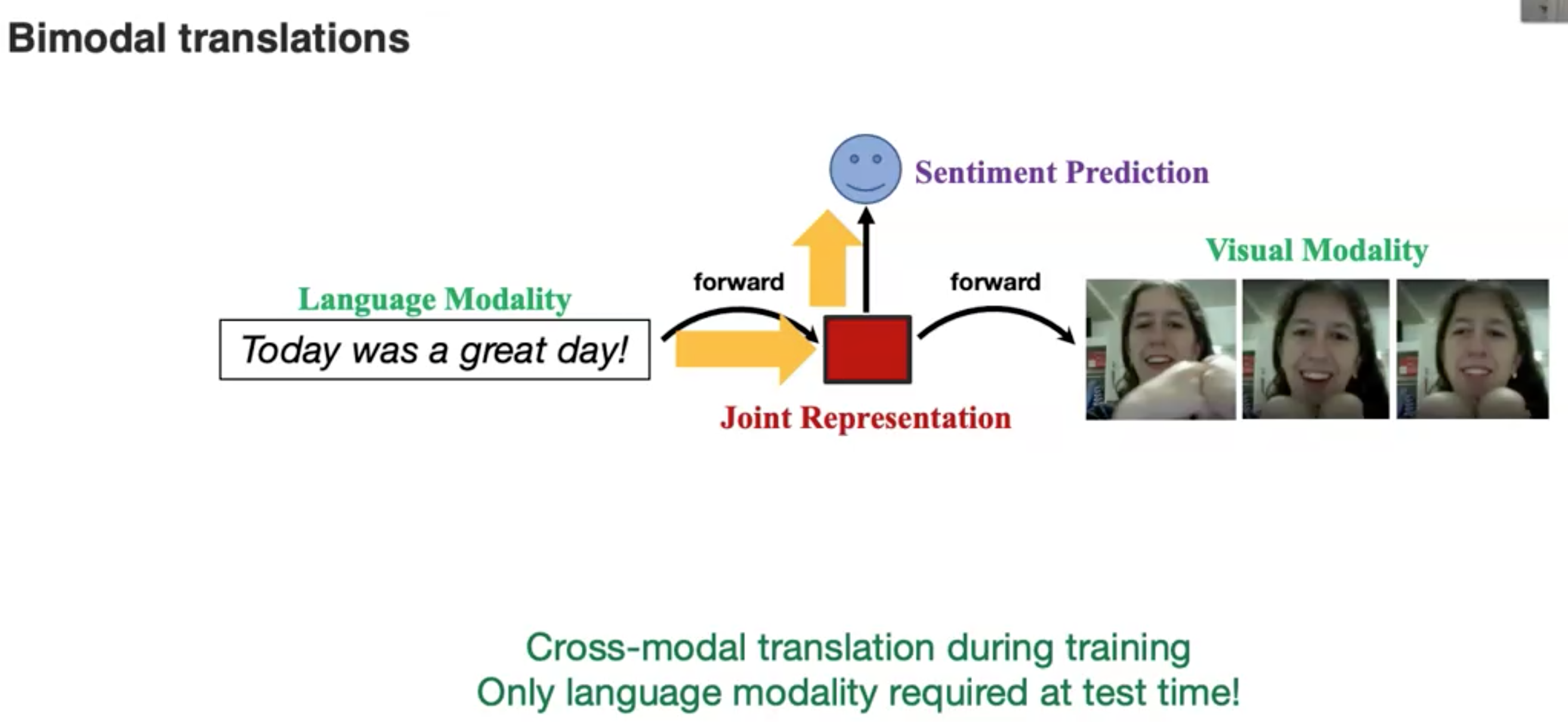
Co-learning via translation
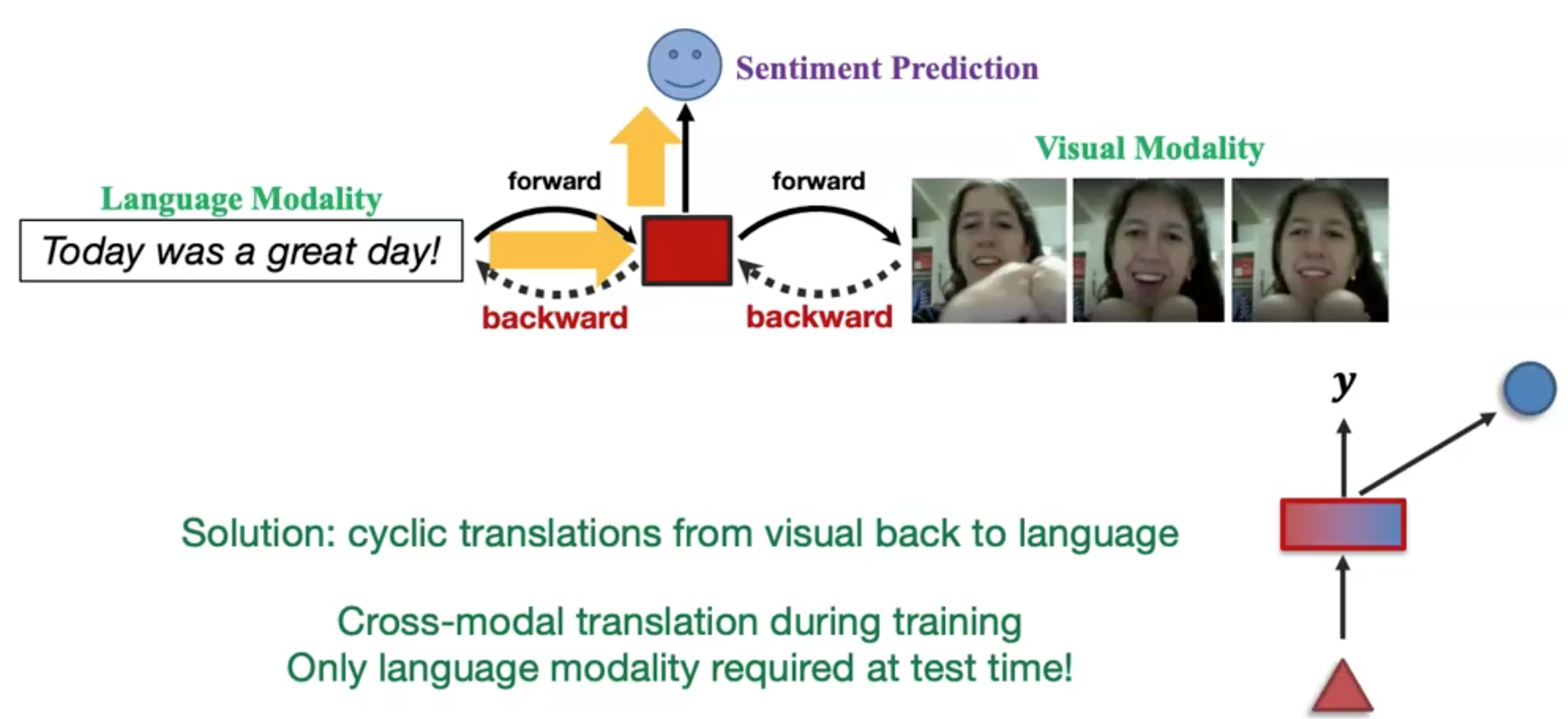
接下来是通过在预测层融合其它modality的information。下面是一个在language和text之间进行信息迁移的实例(Pham et al., Found in Translation: Learning Robust Joint Representations via Cyclic Translations Between Modalities. AAAI 2019):
但是这样的做法并不能确保两个模态的信息都被完全使用了,因为这仅仅是language到visual的translation:
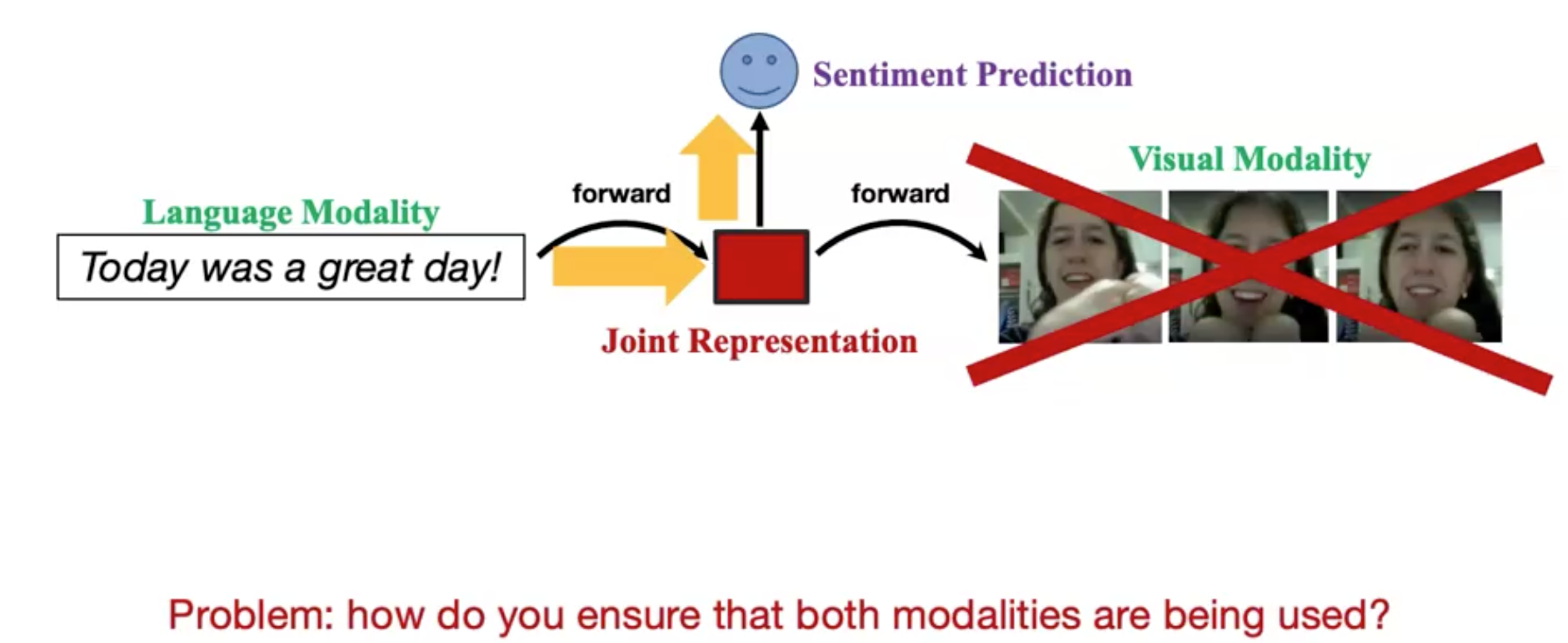
作者的做法是让image再翻译回language:
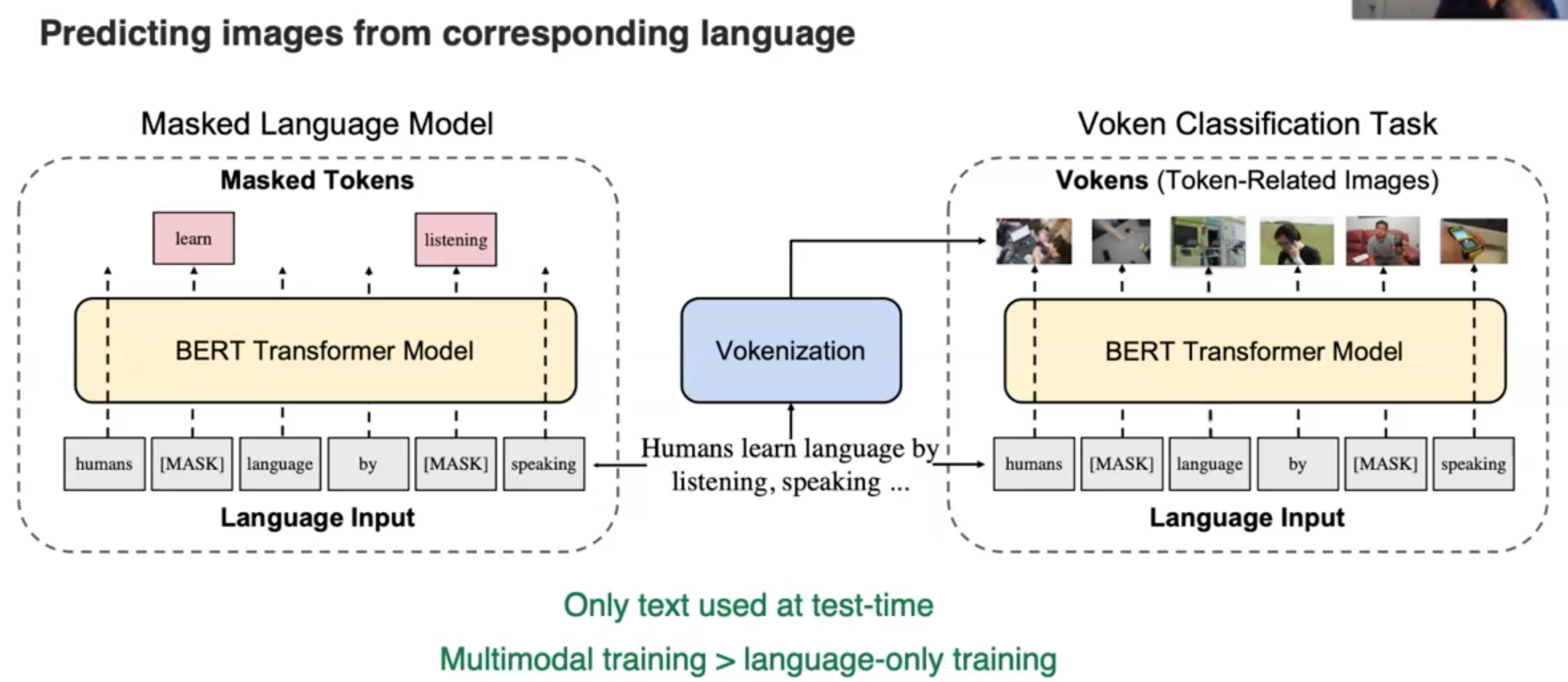
之后,同样有研究者通过language来生成对应的image(Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision. EMNLP 2020):
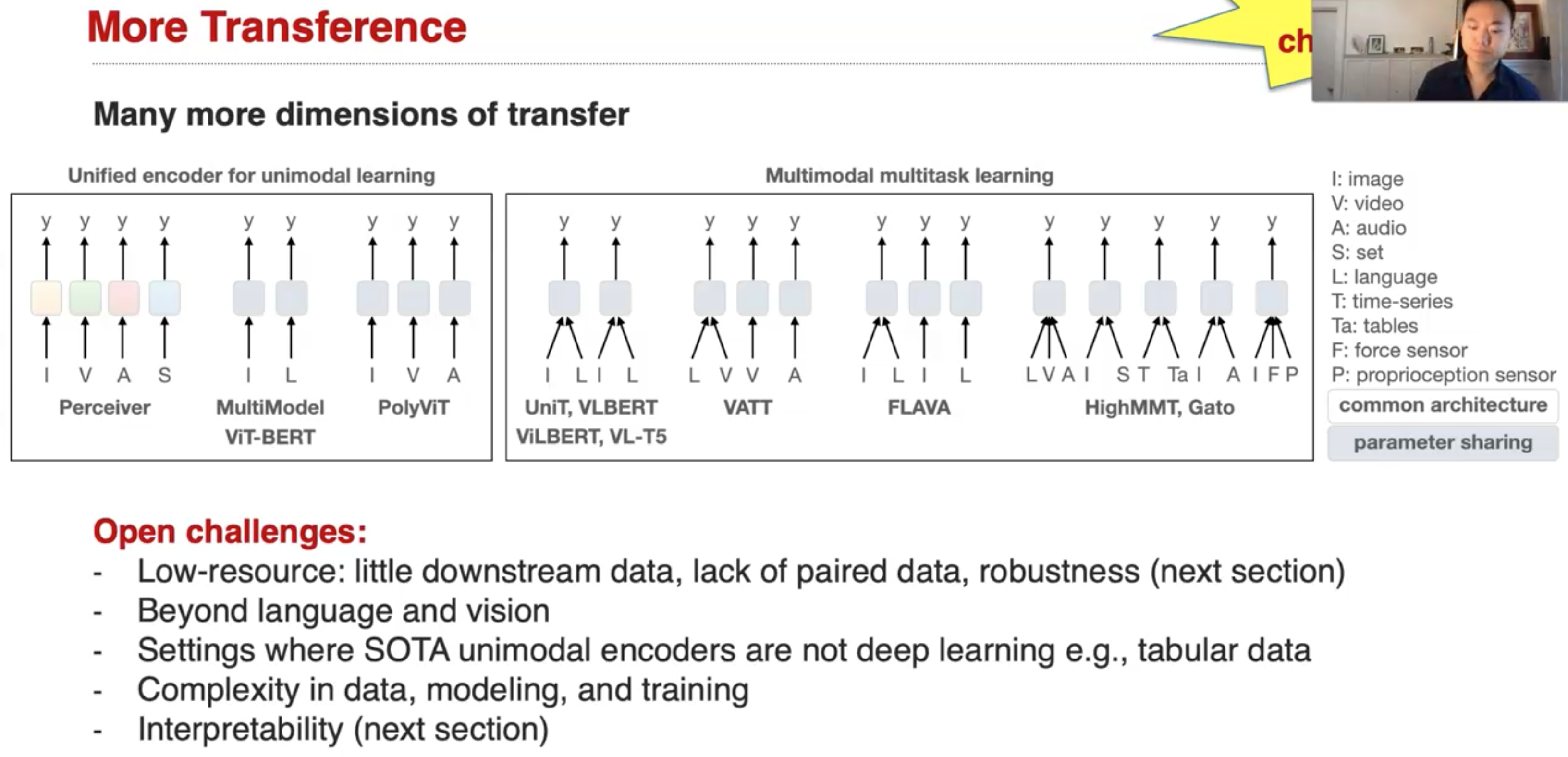
还存在更多可以探究的challenge: