5-generation
MMML Tutorial Challenge 4: Generation
generation的定义是生成raw modality,也就是说应该和input modalities是不同的modality:
Learning a generative process to produce raw modalities that reflects cross-modal interactions, structure, and coherence.
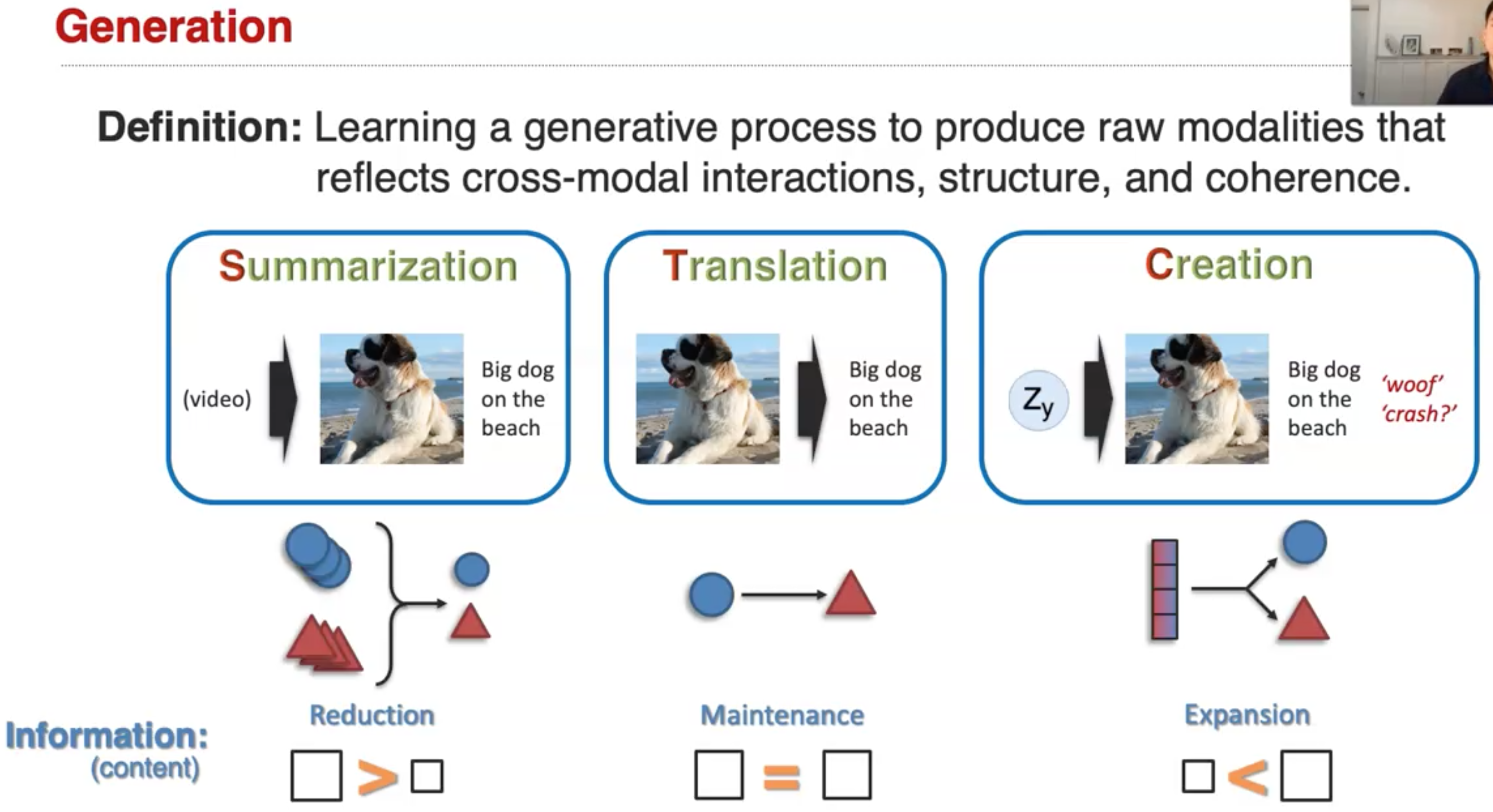
generation的两个维度:
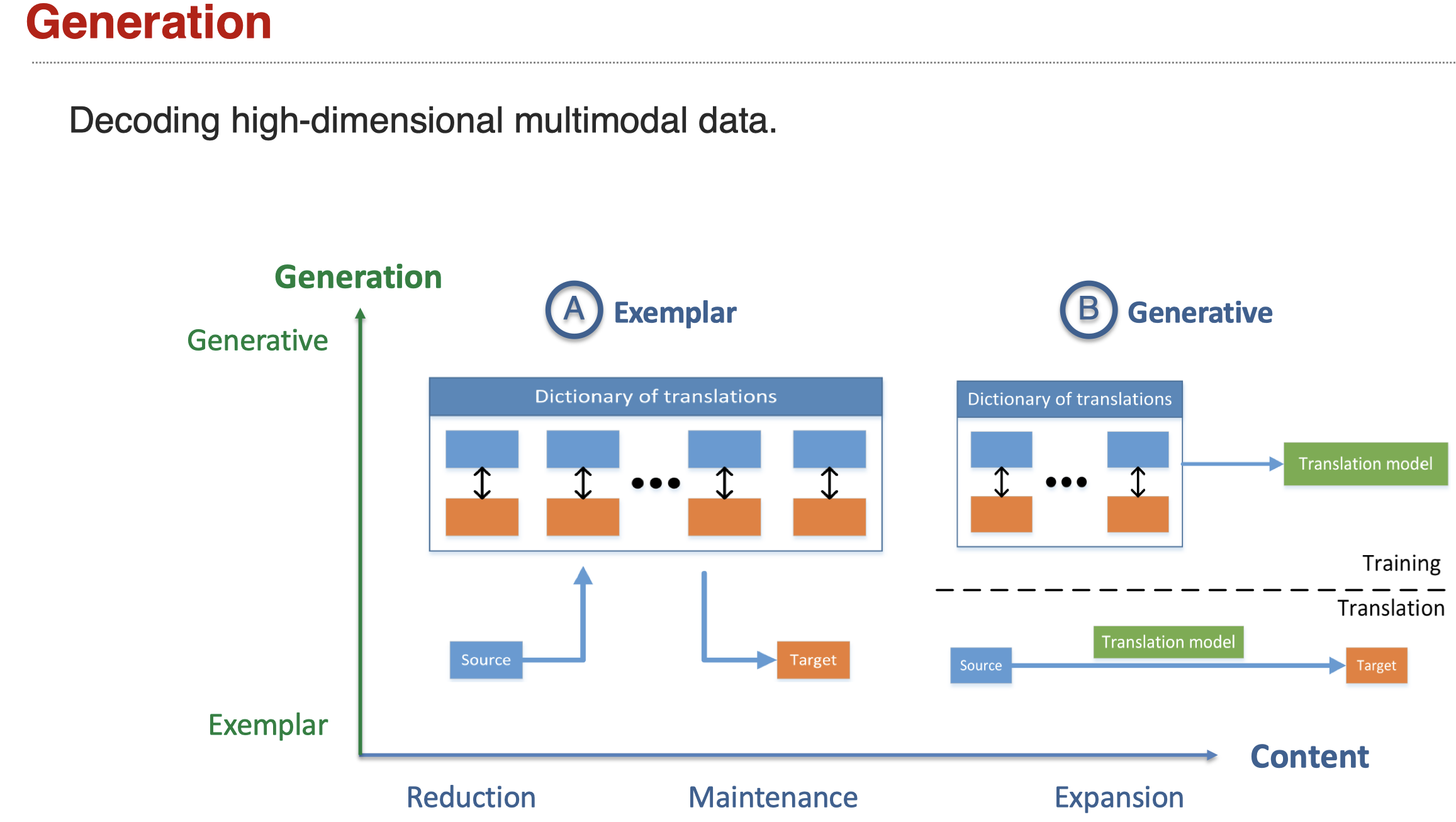
Sub-challenge 1: Translation
translation定义:
Translating from one modality to another and keeping information content while being consistent with cross-modal interactions.
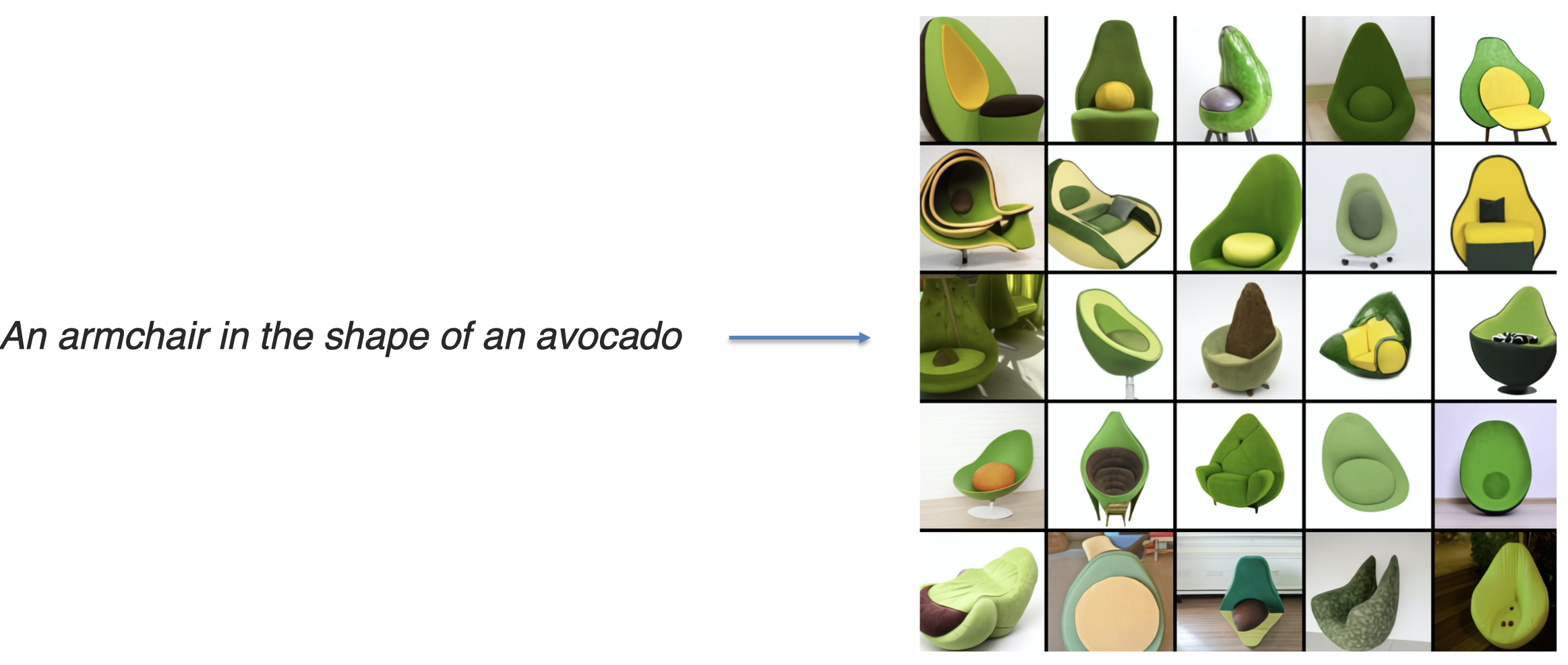
比如DALLE(Ramesh et al., Zero-Shot Text-to-Image Generation. ICML 2021):

从content和generation的角度来看,因为我们做的translation,因此我们不需要存在信息损失,所以利用coordination来保持两个模态的信息能够互相协作。

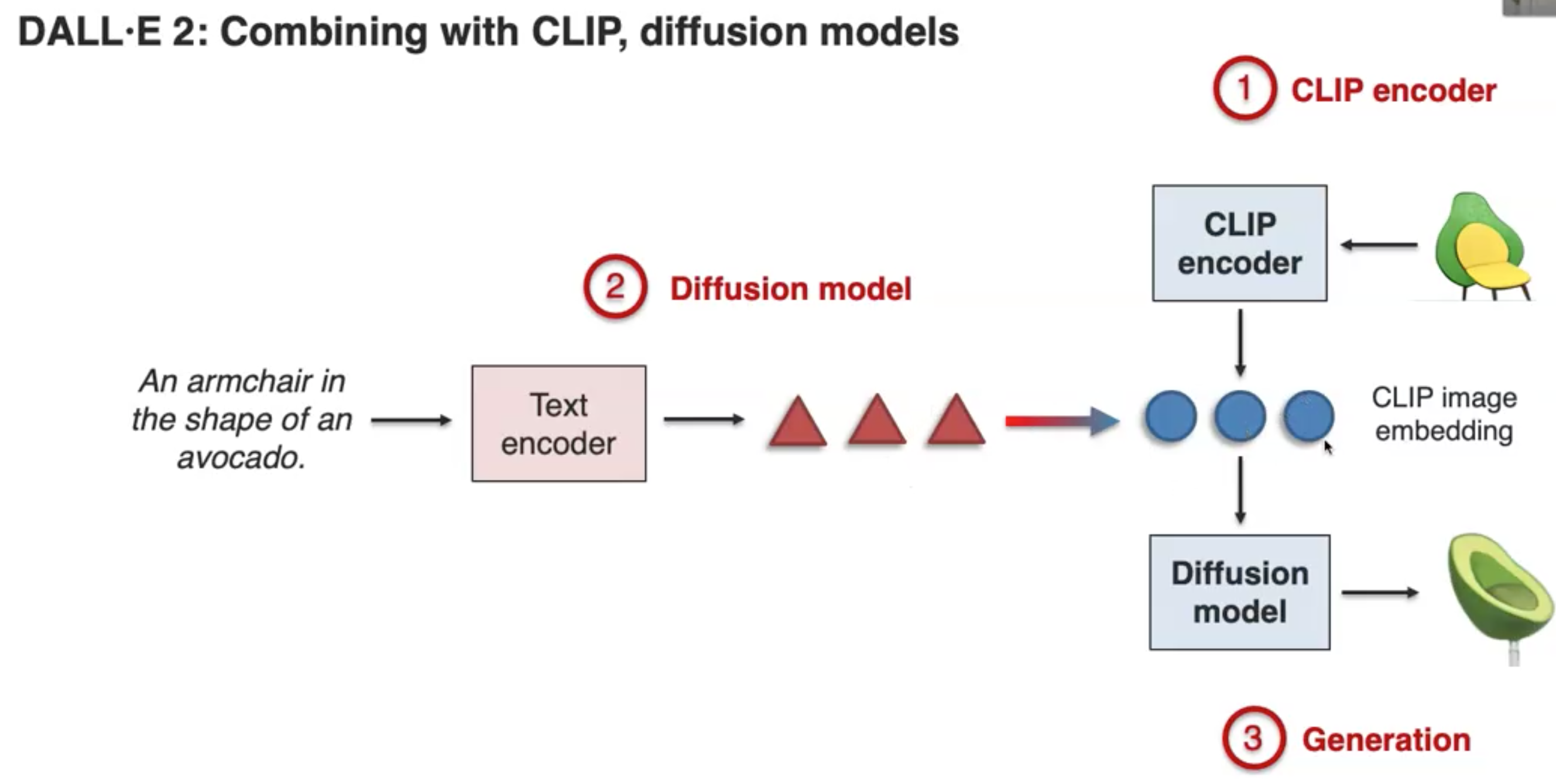
比如DALL E 2(Ramesh et al., Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022)和DALL-E核心原理是一致的:
Sub-challenge 2: Summarization
summarization的定义是缩减信息量并且找出重要的信息:
Summarizing multimodal data to reduce information content while highlighting the most salient parts of the input.
比如下面的例子,通过video和language生成summary(Palaskar et al., Multimodal Abstractive Summarization for How2 Videos. ACL 2019):
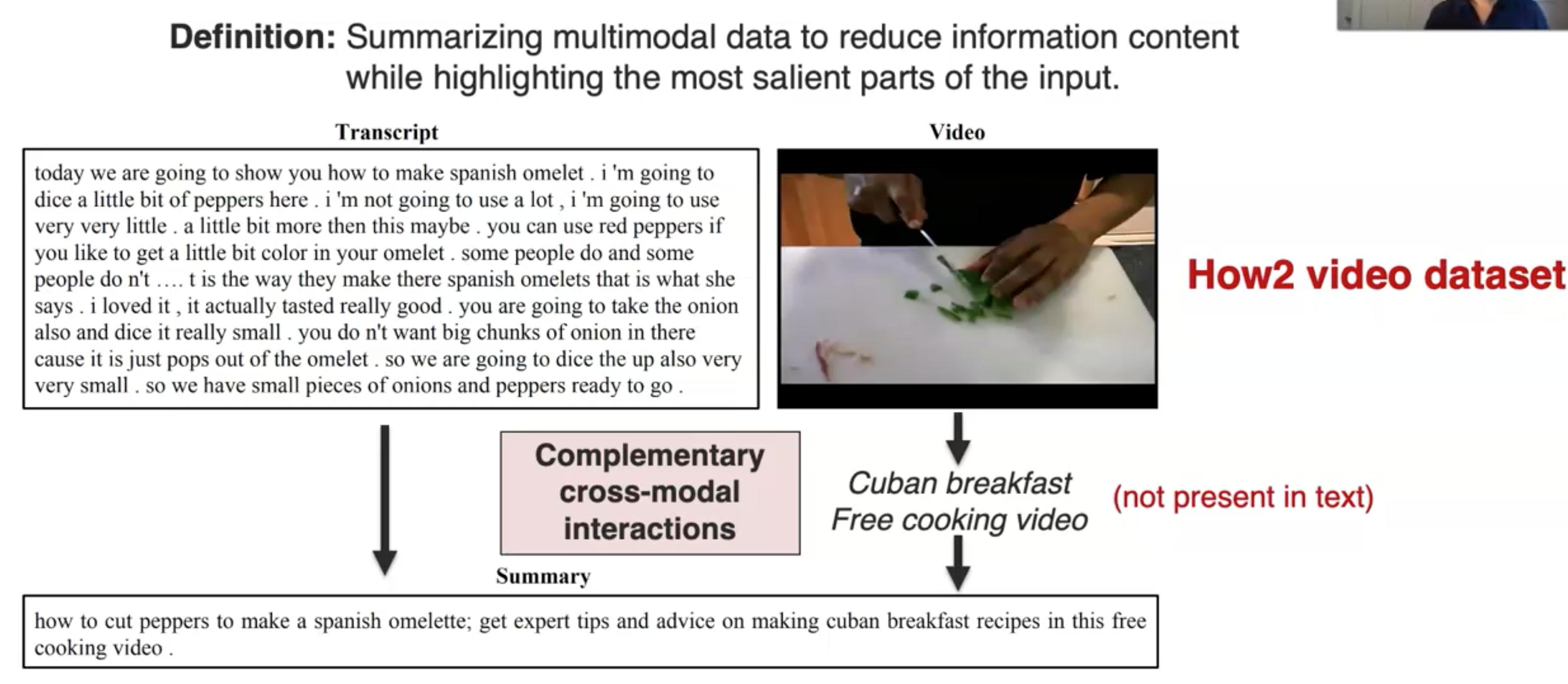
summarization的content就需要是进行模态的fusion,并且生成的时候需要进行信息的缩减:
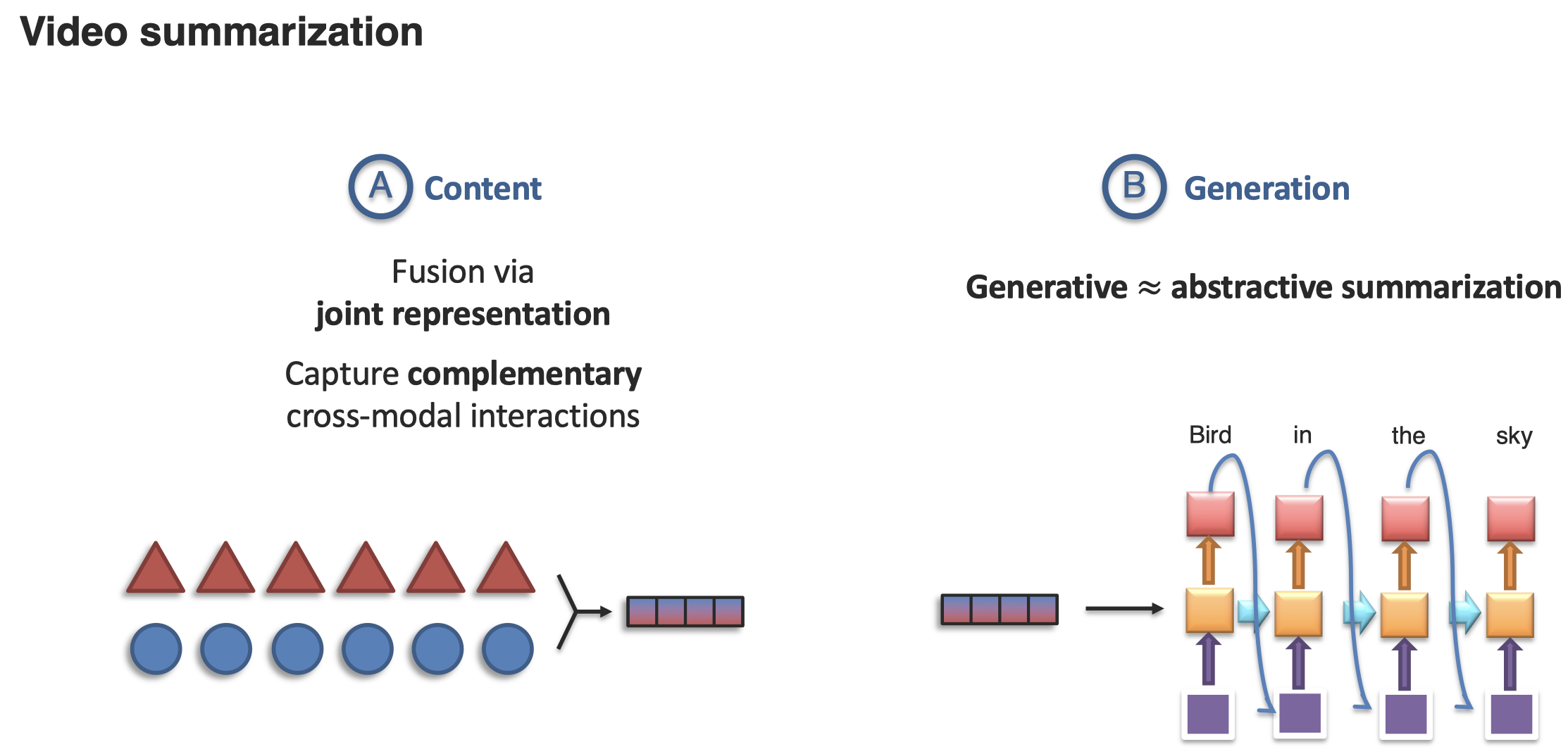
Sub-challenge 3: Creation
creation需要创造新的modalities,是一个非常具有挑战性的方向:
Simultaneously generating multiple modalities to increase information content while maintaining coherence within and across modalities.

实际上现在没有特别符合creation方向的方法,一个非常初步的方法是(Tsai et al., Learning Factorized Multimodal Representations. ICLR 2019):
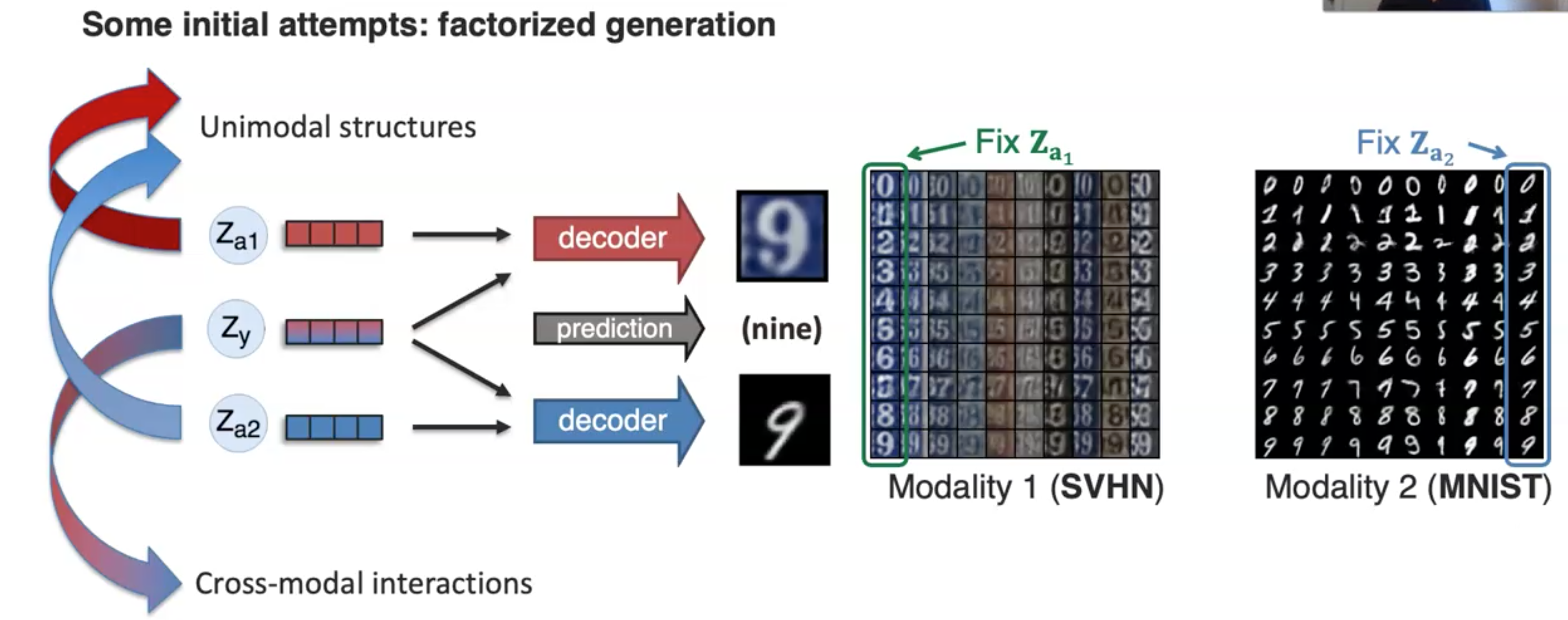
还存在很多的可以研究的点:
