4-reasoning
MMML Tutorial Challenge 3: Reasoning
Reasoning的定义:
Combining knowledge, usually through multiple inferential steps, exploiting multimodal alignment and problem structure.
reasoning的基础是前面的representation和alignment,然后我们才可以考虑如何combine合适的不同模态的信息来得到理想的预测在值。
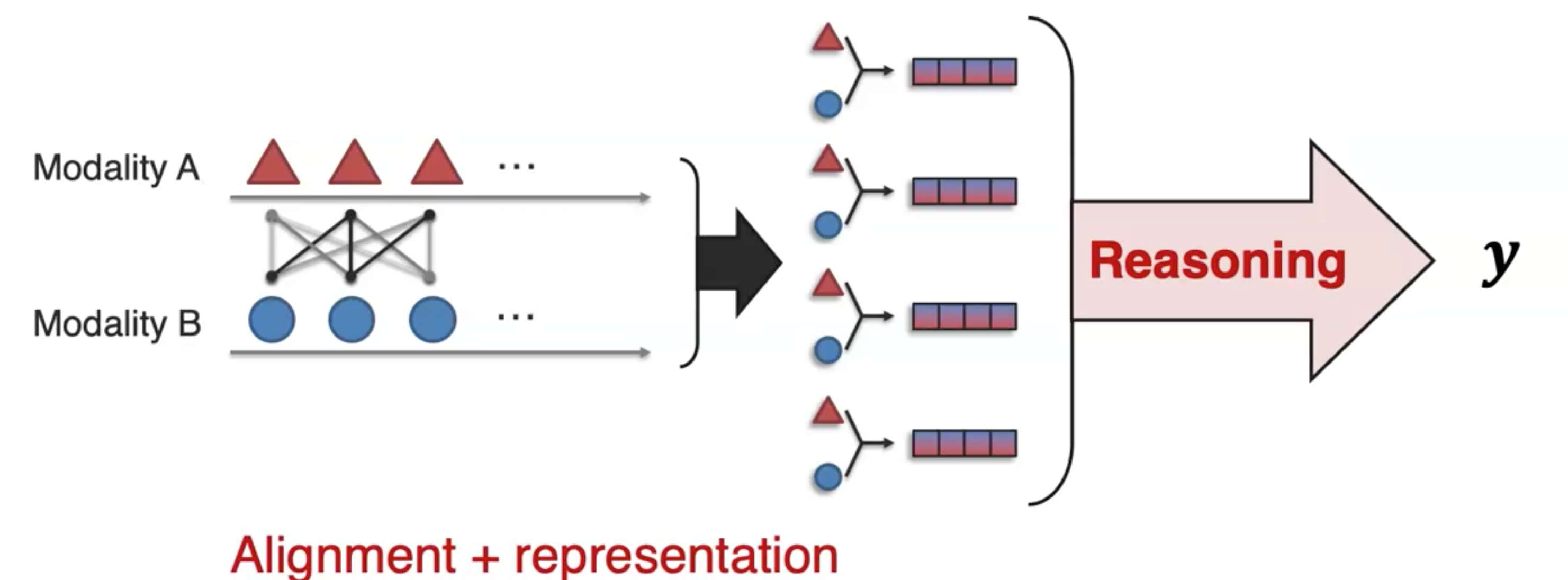
可以看到,reasoning和representation fusion在原理上是有相似之处的,但是reasoning比fusion更加的复杂,它可能需要multi-step实现对各种不同complex structure建模;fusion更多是指single-step的融合。
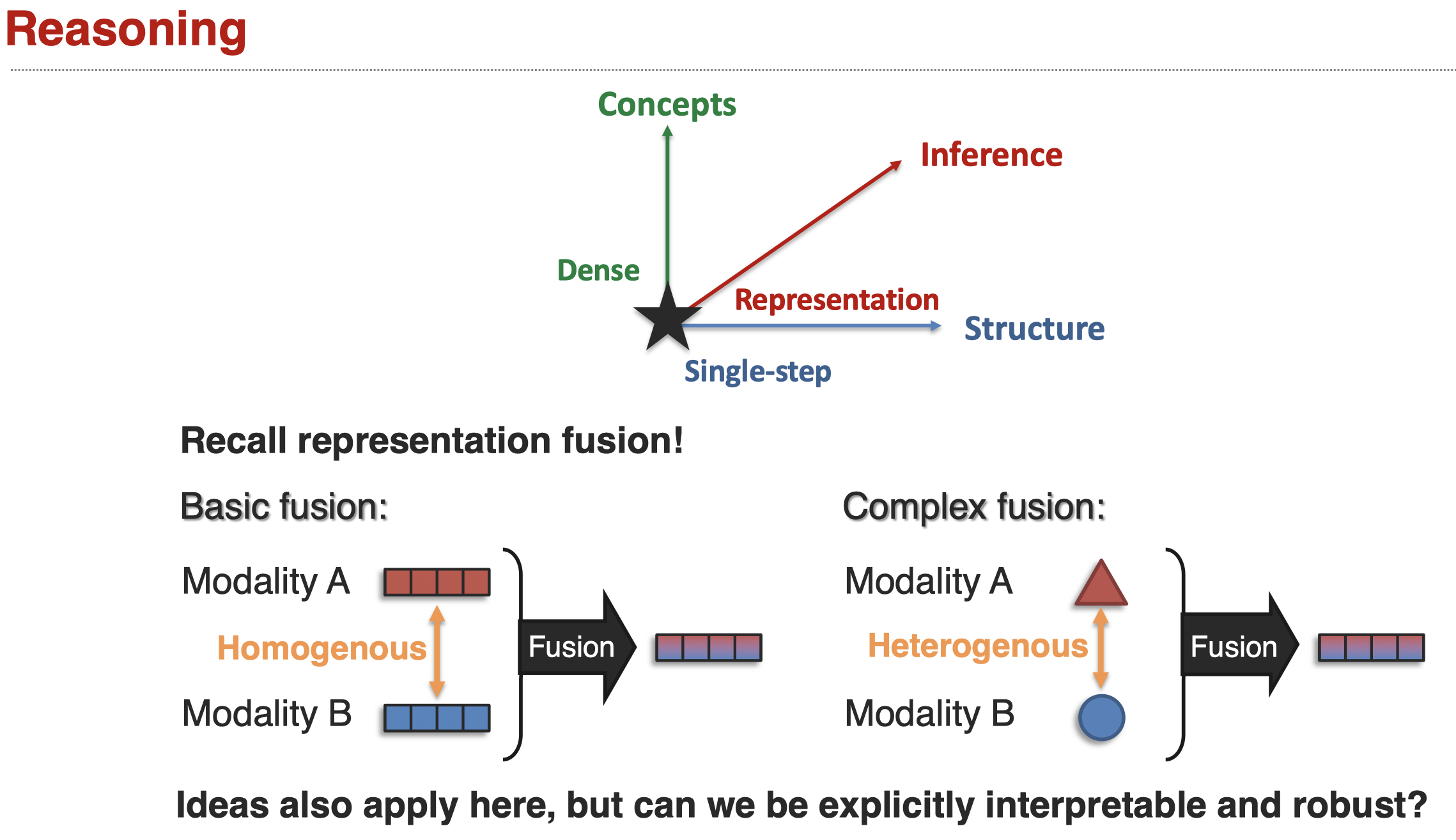
Sub-Challenge 1: Structure Modeling
定义,如何建模出现在不同模态间的复杂结构
Defining or learning the relationships over which composition occurs.
可能存在以下不同的结构:

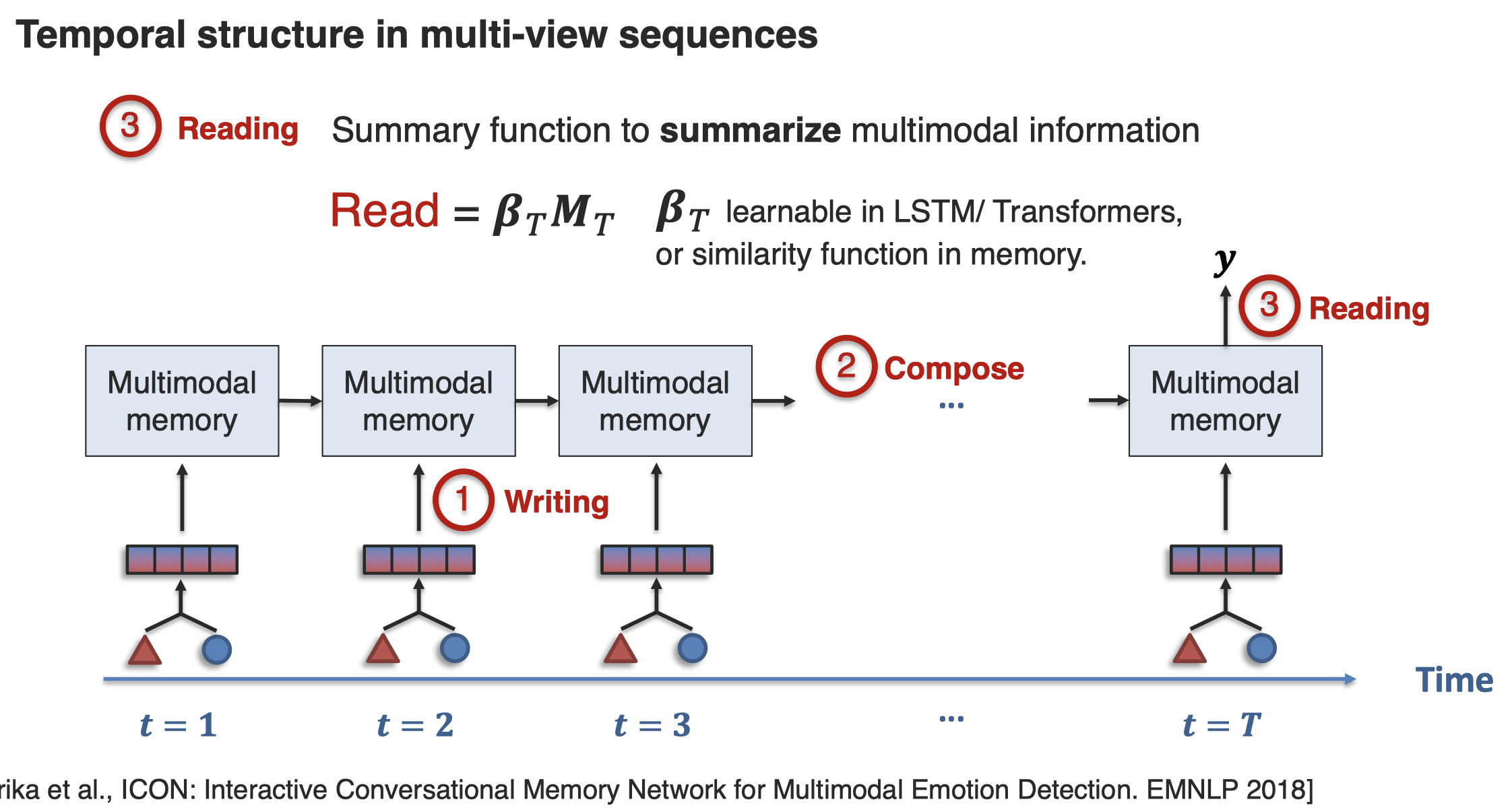
接下来看一下如何实现对Temporal Structure的建模How can we capture cross-modal interactions across time? 一种方法是通过memory network来实现:
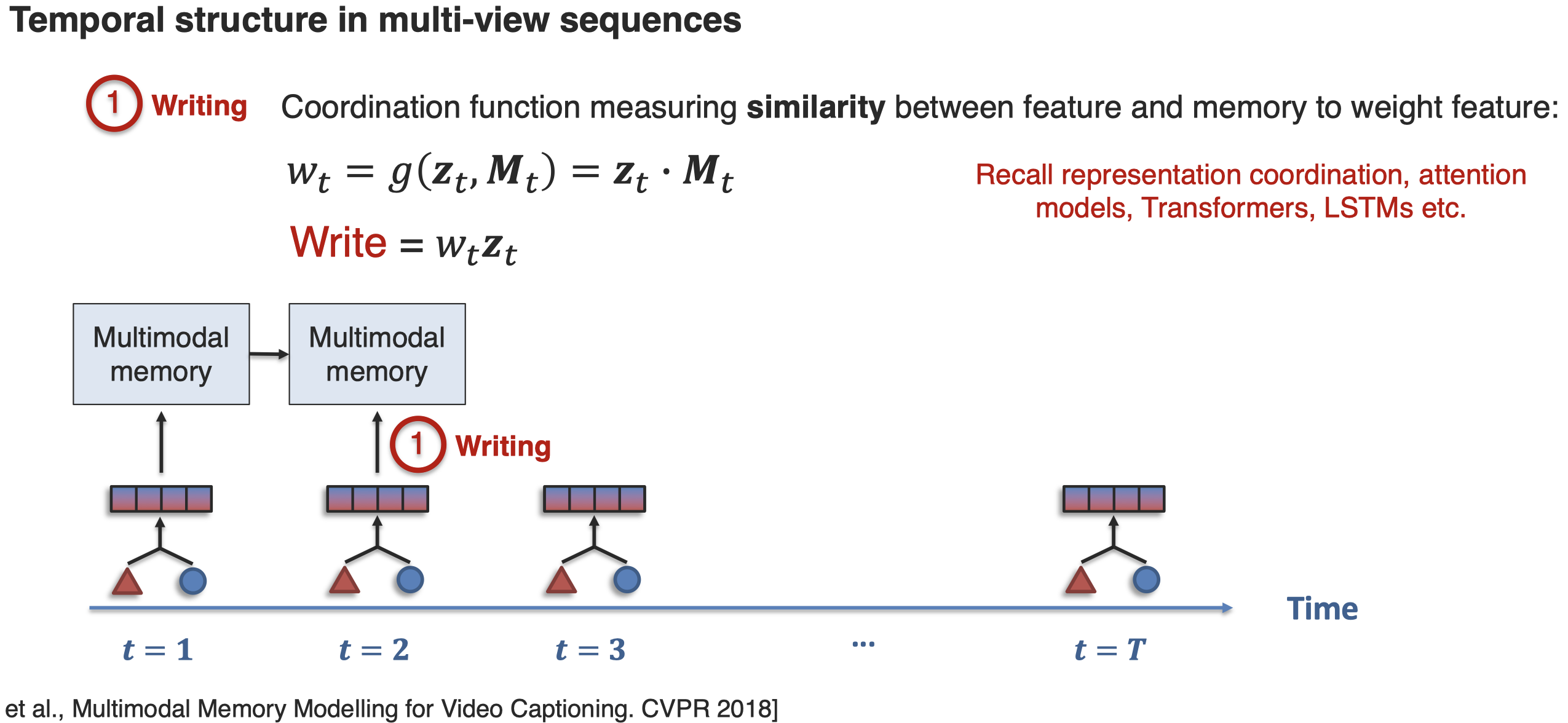
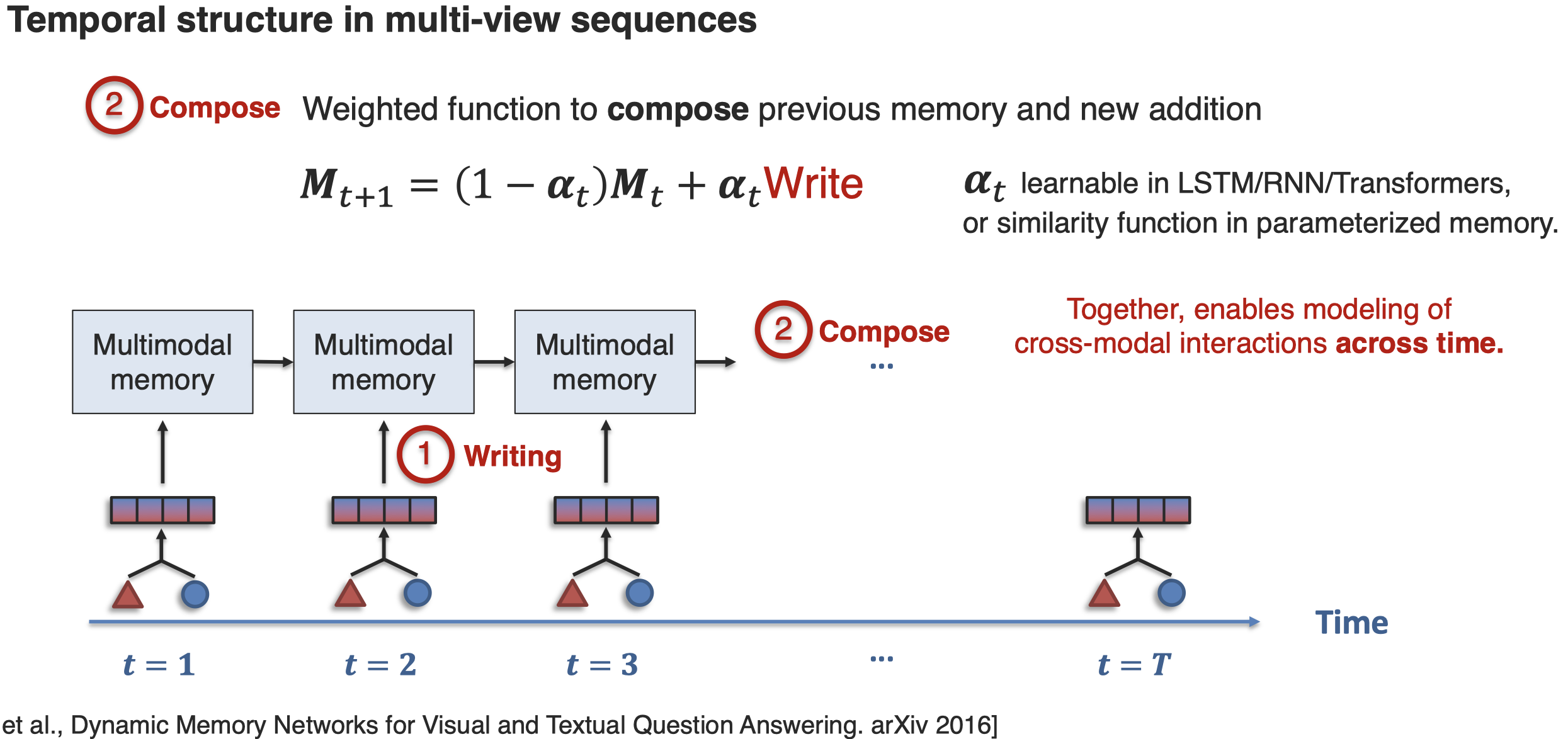
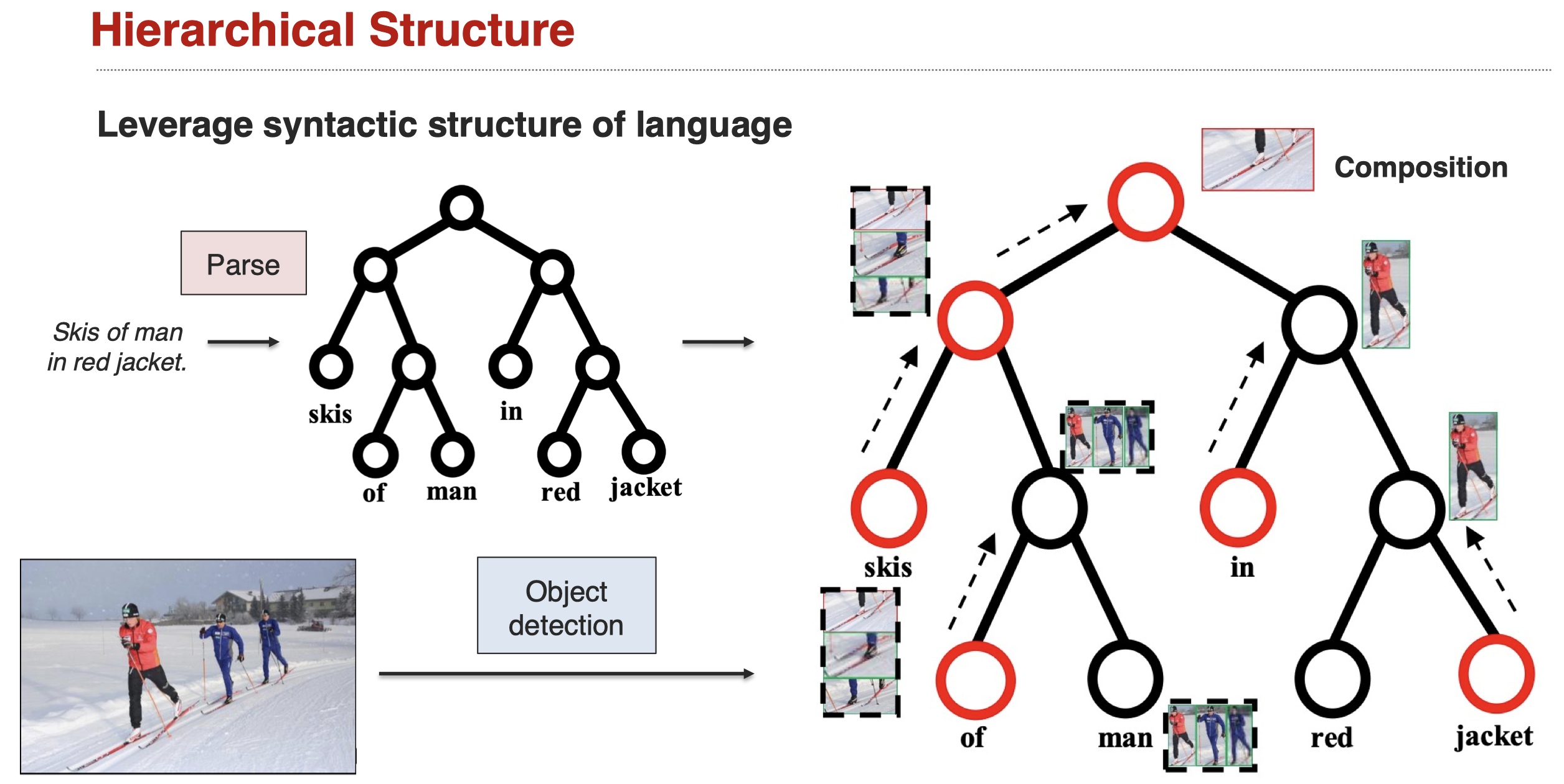
接下来是建模hierarchical structure,比如在visual grounding中,期望利用language的语法结构,然后能够利用这样的语法结构进行推理:
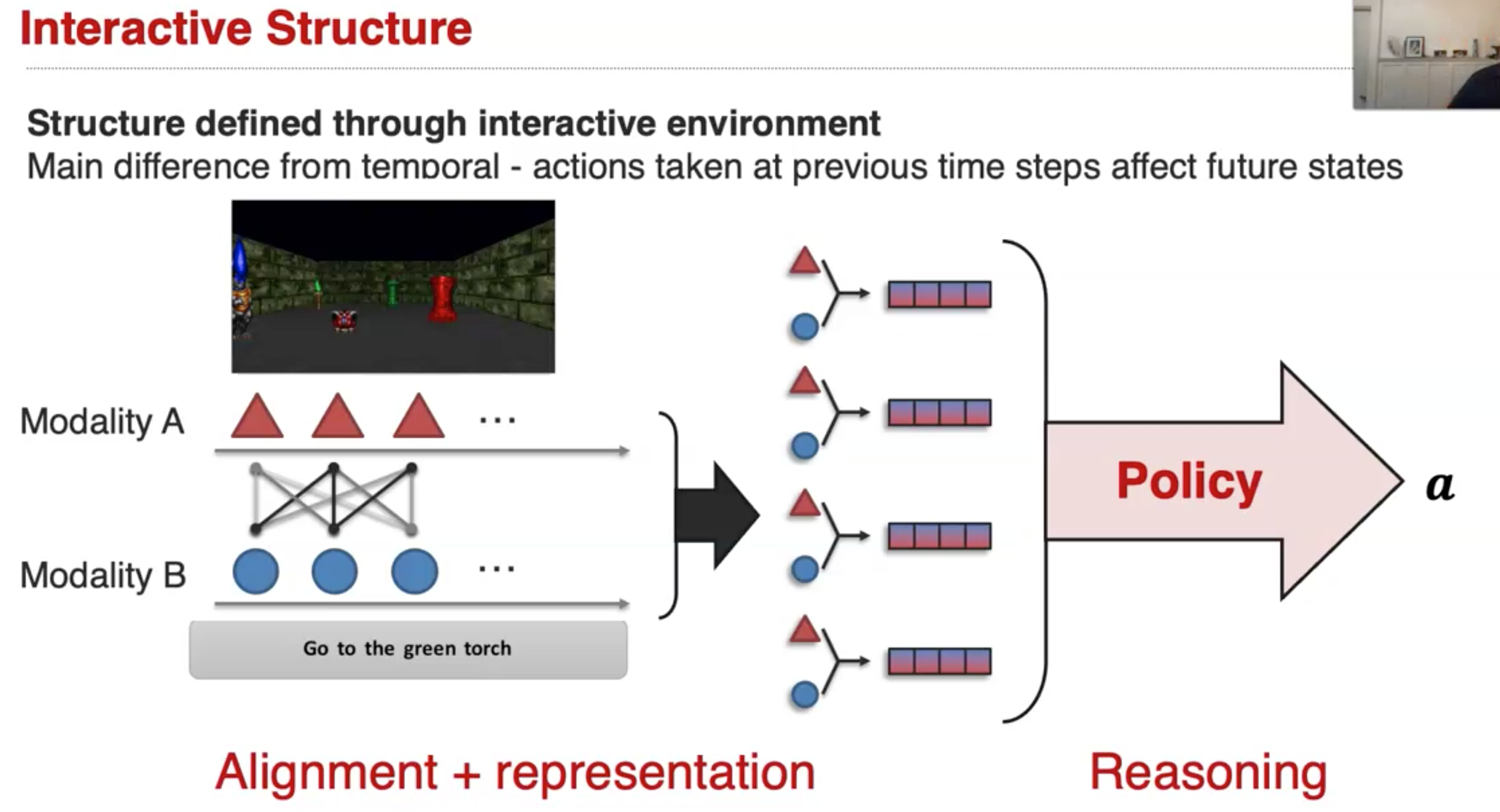
interactive structure,它同样是一种时间上的结构,但是和一般的temporal structure不一样的是,interactive structure中前一步的action,会影响未来的action。而在一般的temporal structure中不一定这样,temporal structure中的元素可能仅仅存在时间先后的联系,不一定存在直接的明确的影响。
建模interactive structure更多的依赖于reinforcement learning,这是一个很大的方向,完全可以作为一个新的tutorial,这里不进行详细的了解。
最后是structure discovery,我们不在自己定义complex network进行reasoning,而是通过网络结构搜索,让机器自动学习合适的reasoning structure。下面是一个实例(Xu et al., MUFASA: Multimodal Fusion Architecture Search for Electronic Health Records. AAAI 2021):
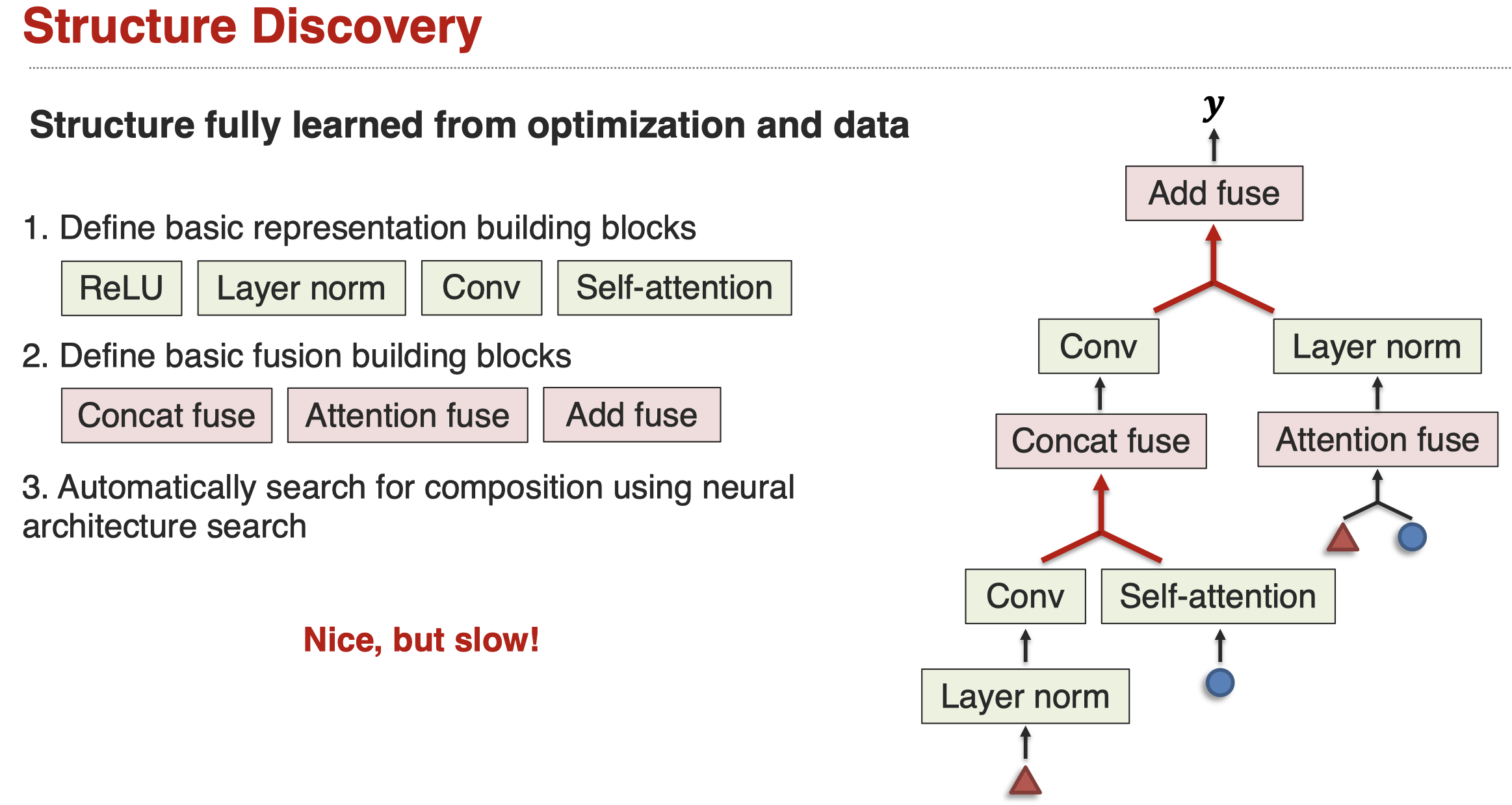
这样做的好处是无需人工的设计网络架构,我们做的只是定义好各种building blocks,让机器自己去找合适的结构就可以。缺点是需要大量的计算,机器需要不断的尝试不同的架构,进行训练,然后评估。
Sub-Challenge 2: Intermediate Concepts
中间概念intermediate concepts的定义:
The parameterization of individual multimodal concepts in the reasoning process.

引入中间概念来辅助推理,可能是的reasoning process更加可信赖,更加interpolate。
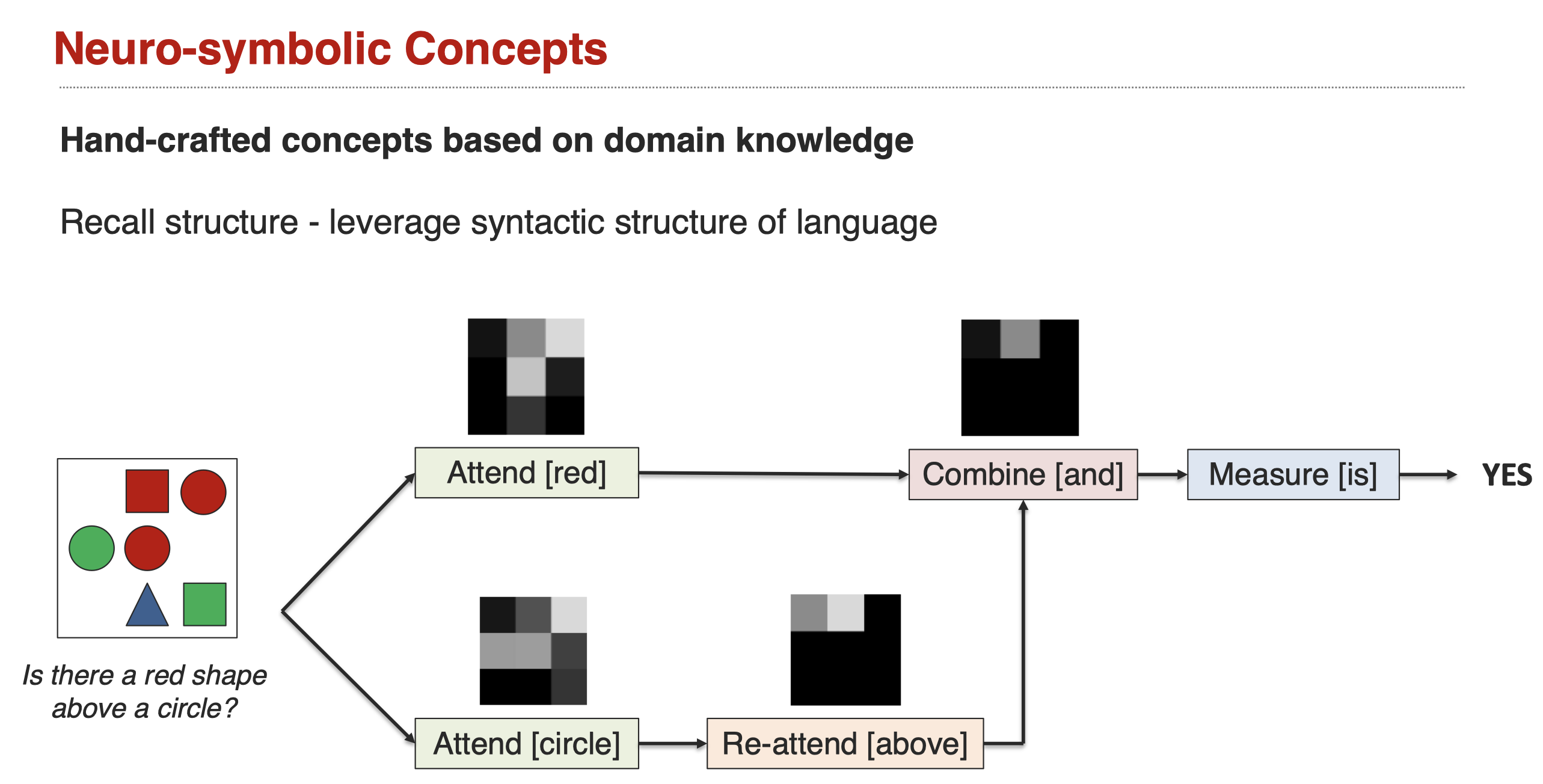
下面是一个借助neuro-symbolic的实例(Andreas et al., Neural Module Networks. CVPR 2016]),它人工设计了概念作为中间状态:
Sub-Challenge 3: Inference Paradigm
inference paradigm challenge定义:
How increasingly abstract concepts are inferred from individual multimodal evidences.
粗暴一点的说,就是如何能够考虑逻辑?
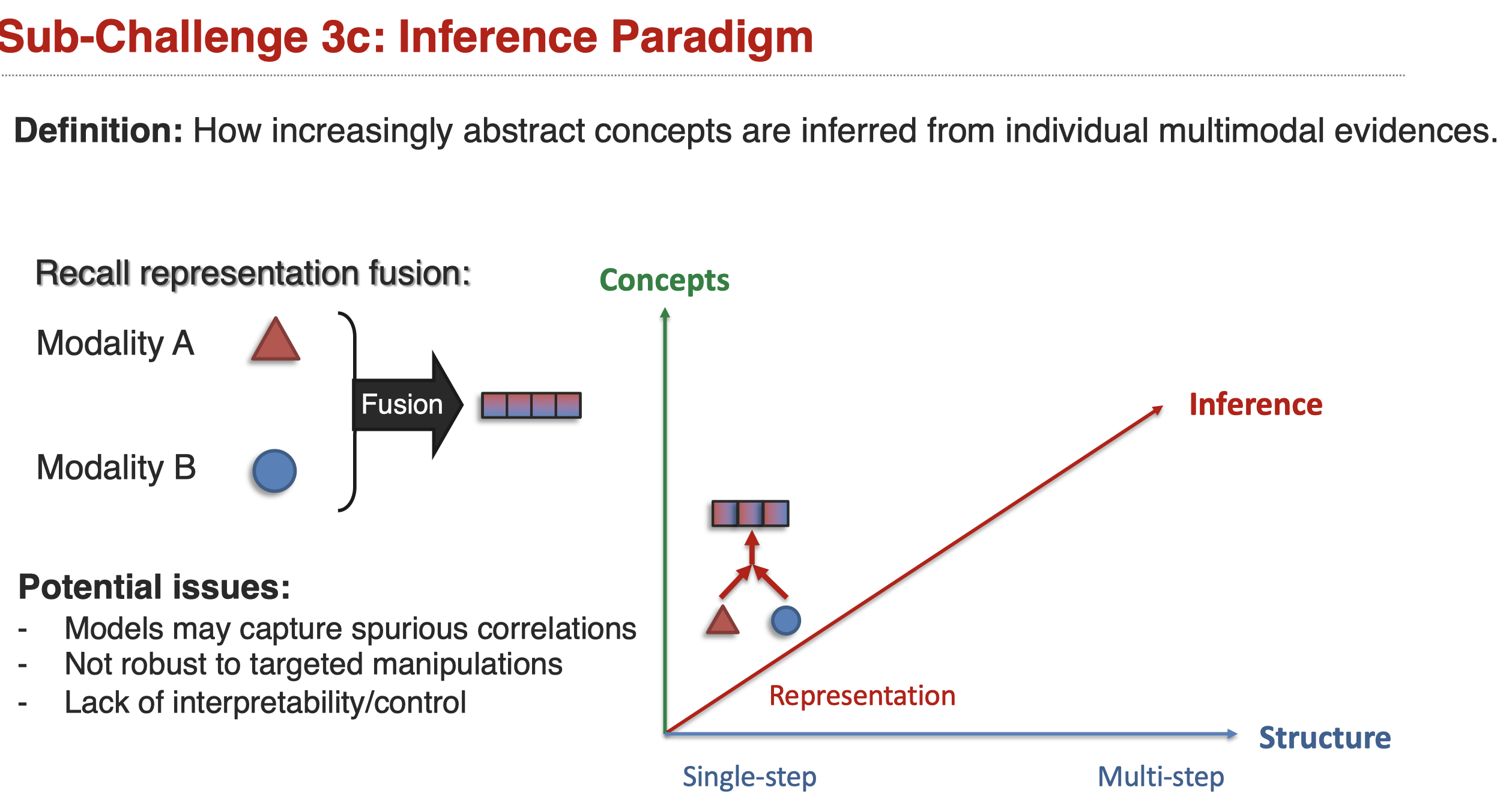
几种可能存在的inference模式:
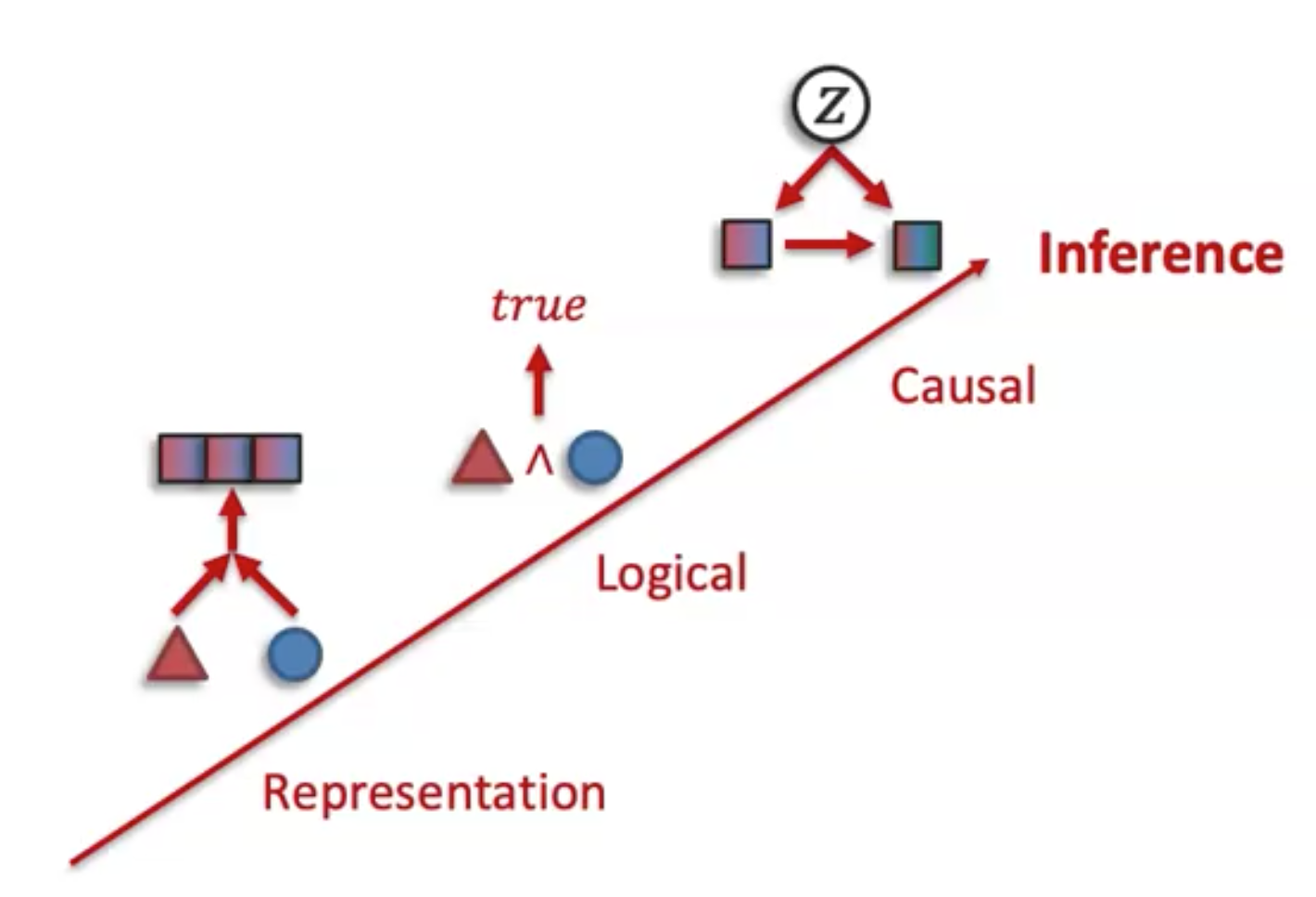
首先是对于logical inference,以VQA举例,很多的模型实际上无法捕获逻辑联系,比如在下面的实例中(Gokhale et al., VQA-LOL: Visual Question Answering Under the Lens of Logic. ECCV 2020):

研究者提出的一种解决方案是,建模了可微分的逻辑操作符:

接下来是casual inference。当我们尝试简单的改变预测目标时,现在的很多模型会出现预测错误的情况,并且它们很可能捕获了错误的潜在correlation(Agarwal et al., Towards Causal VQA: Revealing & Reducing Spurious Correlations by Invariant & Covariant Semantic Editing. CVPR 2020)。比如在下面的例子中,雨伞和灯笼的颜色是无关的,但是模型错误的捕获了这种联系:

在另外的例子中,斑马和斑马的数量是相关的,但是模型没有能够捕获相关性:

那如何能够让模型更加robust?研究人员提出的一种方案是同时处理这种不相关的object和相关的object:

Sub-Challenge 4: Knowledge
接下来是如何利用knowledge辅助多模态融合?
The derivation of knowledge in the study of inference, structure, and reasoning.

接下来是几个knowledge的实例。首先是multimodal knowledge graph辅助VQA(Marino et al., OK-VQA: A visual question answering benchmark requiring external knowledge. CVPR 2019):

为了能够利用knowledge辅助QA,研究人员提出的方法(Gui et al., KAT: A Knowledge Augmented Transformer for Vision-and-Language. NAACL 2022):
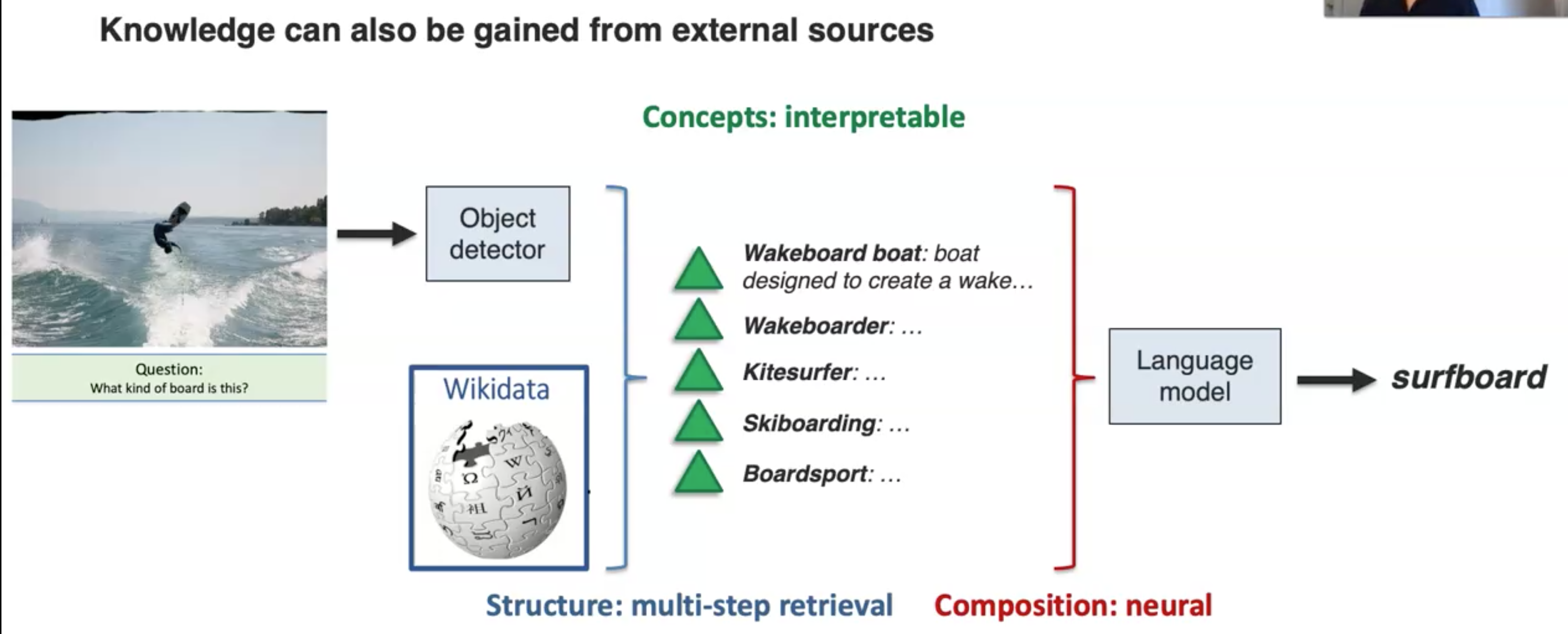
另一个利用multimodal knowledge graph的例子(Zhu et al., Building a Large-scale Multimodal Knowledge Base System for Answering Visual Queries. arXiv 2015):

实际上,还存在着大量可以研究的点:
