3-alignment
MMML Tutorial Challenge 2: Alignment
Alignment定义:
Identifying and modeling cross-modal connections between all elements of multiple modalities, building from the data structure.
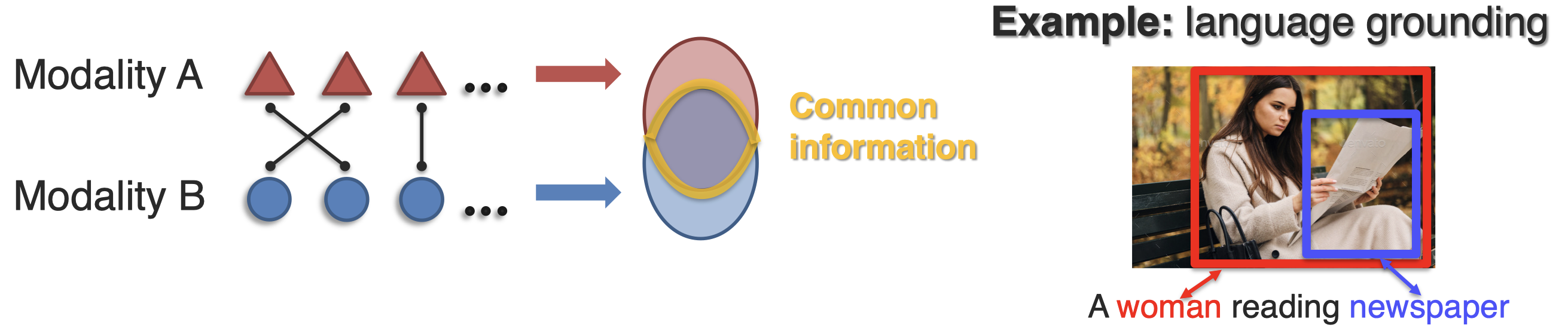
存在三种可能的connection:

equivalence表示两个不同模态的element之间是完全相等的,correspondences表示两个element信息互相补充比如图像和对图像内容的描述,dependencies表示两个element之间存在关系。
dependency示例:
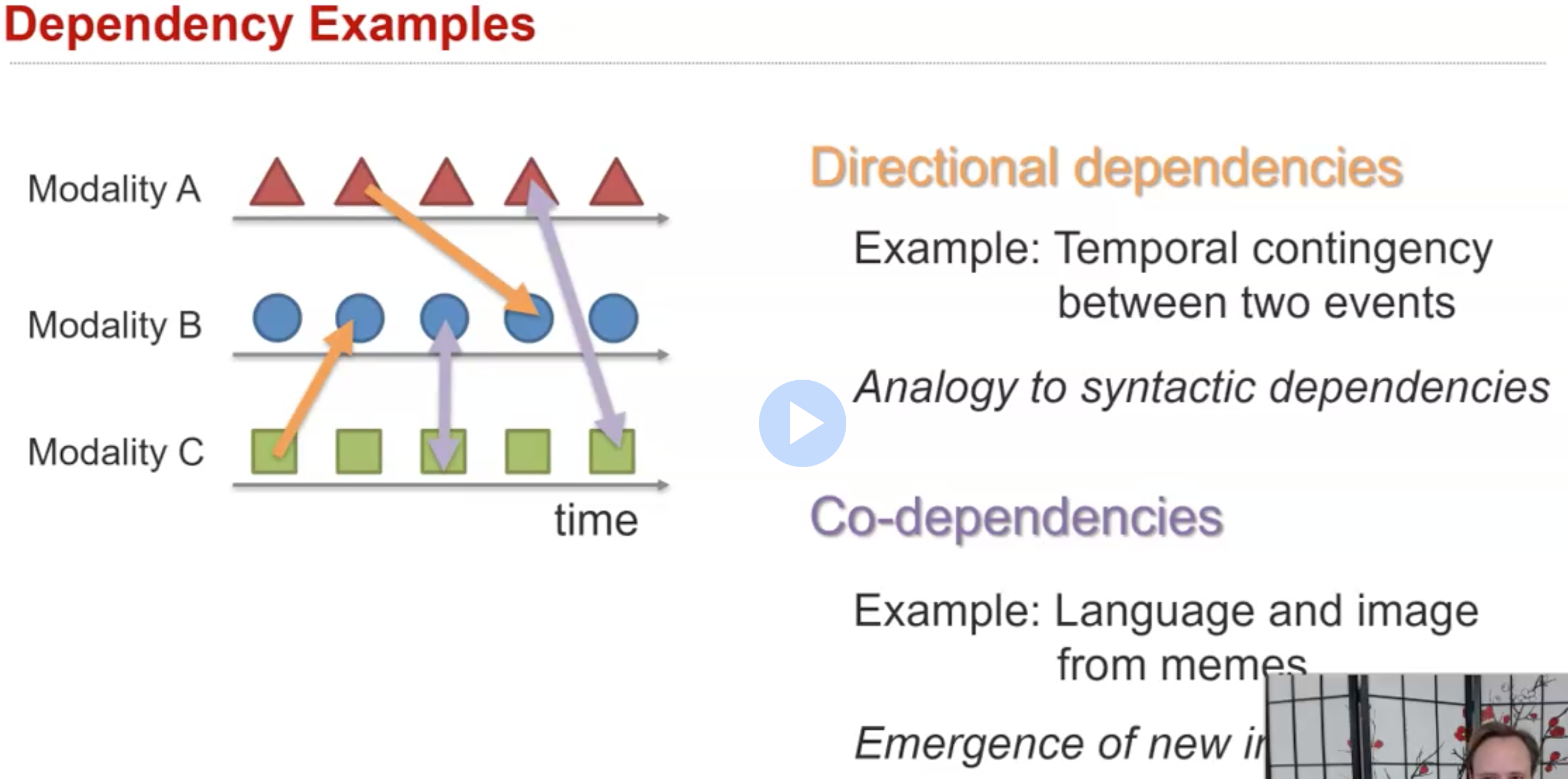
比如说存在时间上的前后关系;或者是比较特殊的co-dependencies,指不同的元素总是同时出现。
Sub-Challenge 1: Explicit Alignment
定义:
Identifying explicit connections between elements of multiple modalities.
比如把图像中的object和对应的文本描述关联起来:
speech的对齐:

在图像和文本的对齐中,对于模态element的定义是明确的。但是对于某些模态的定义就不够确切。比如如果我们希望对齐两个video。
比如存在有研究如何对齐两个video的方法:

Sub-Challenge 2: Implicit Alignment
定义:
Implicitly model connections between elements for better representation learning.
比如期望实现下面的三个模态对齐:
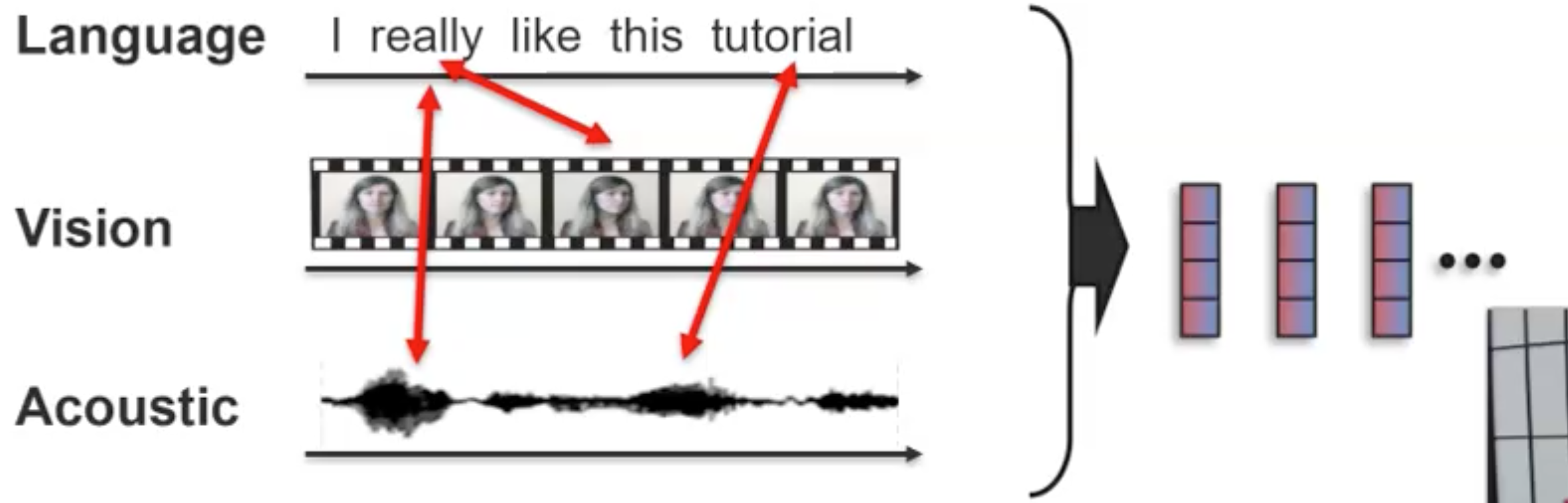
我们无法直接提前选择好explicit connection,但是我们可以利用神经网络实现implicit connection。比如一个简单,但是efficient的方式是把所有的模态拼接到一起后,使用Transformer,通过self-attention,潜在地把不同模态的element融合到一起:

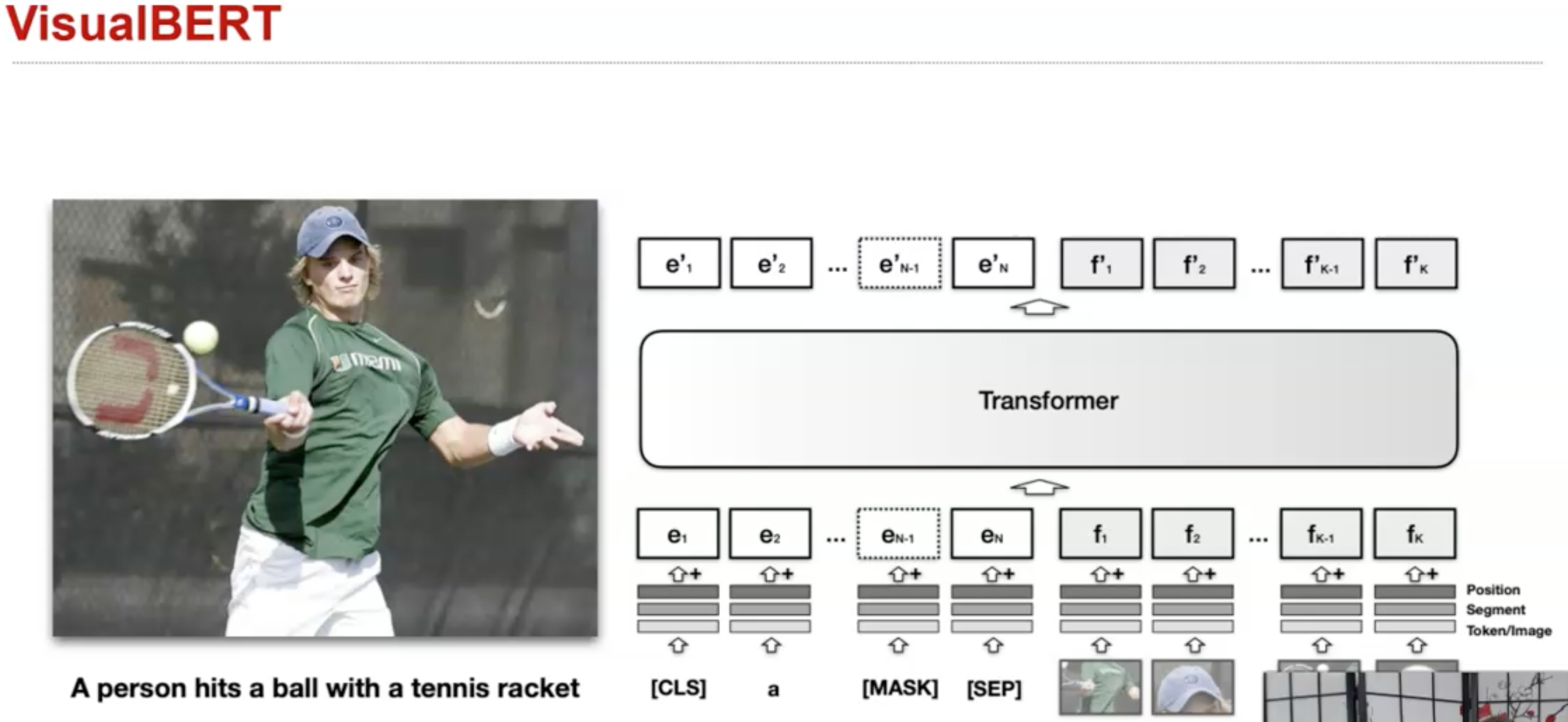
Transformer会把所有可能相关的element关联到一起。VisualBERT是一个关联image-language的实例:
上面的方法会直接把不同模态信息进行融合,最近出现了更多的pair-wise alignment:
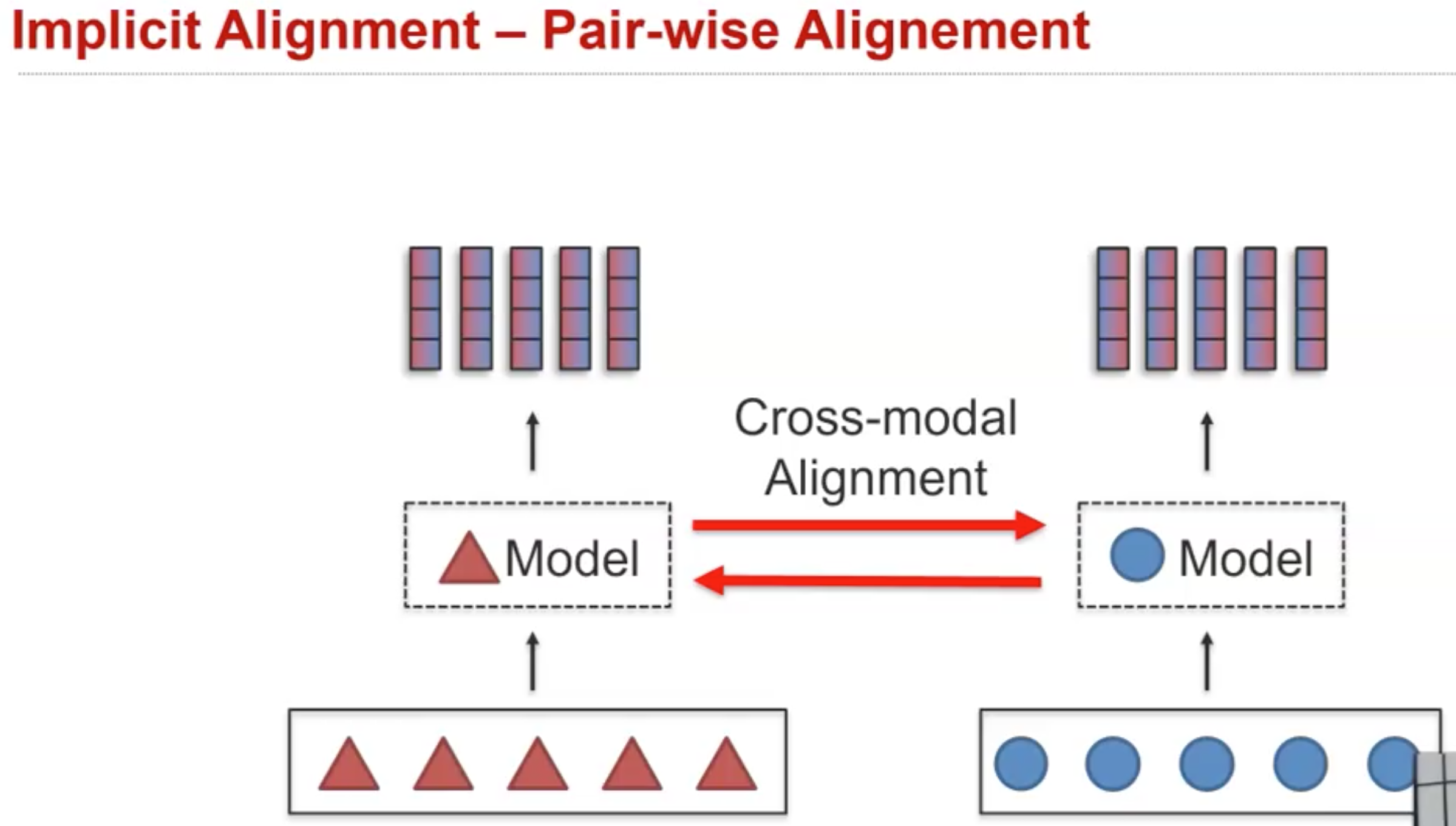
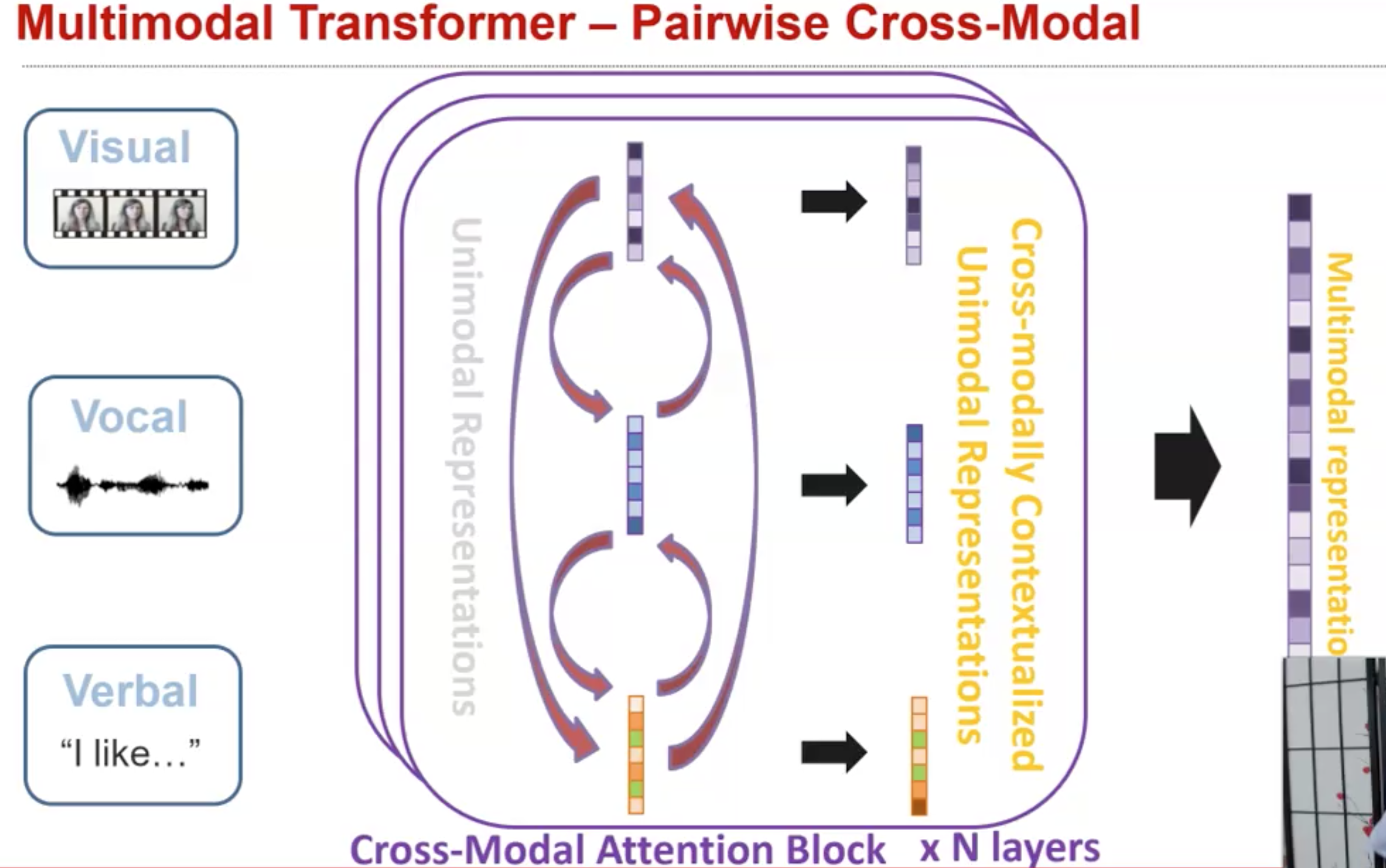
仍然保持各自在不同的表示空间,但是对于modality A会尝试对齐来自modality 的信息,对于modality B尝试对齐来自modality A的信息。如果出现了三个以上的模态,同样可以进行跨模态的对齐。实现的主要思路是,比如我现在有个word embedding,使用这个word embedding作为query embedding,计算来自video slice的image embedding的相似度,然后基于attention聚合image embedding,这样就到达了衡量image对于language的重要程度。下面是一个cross-modal pairwise Transformer的实例:
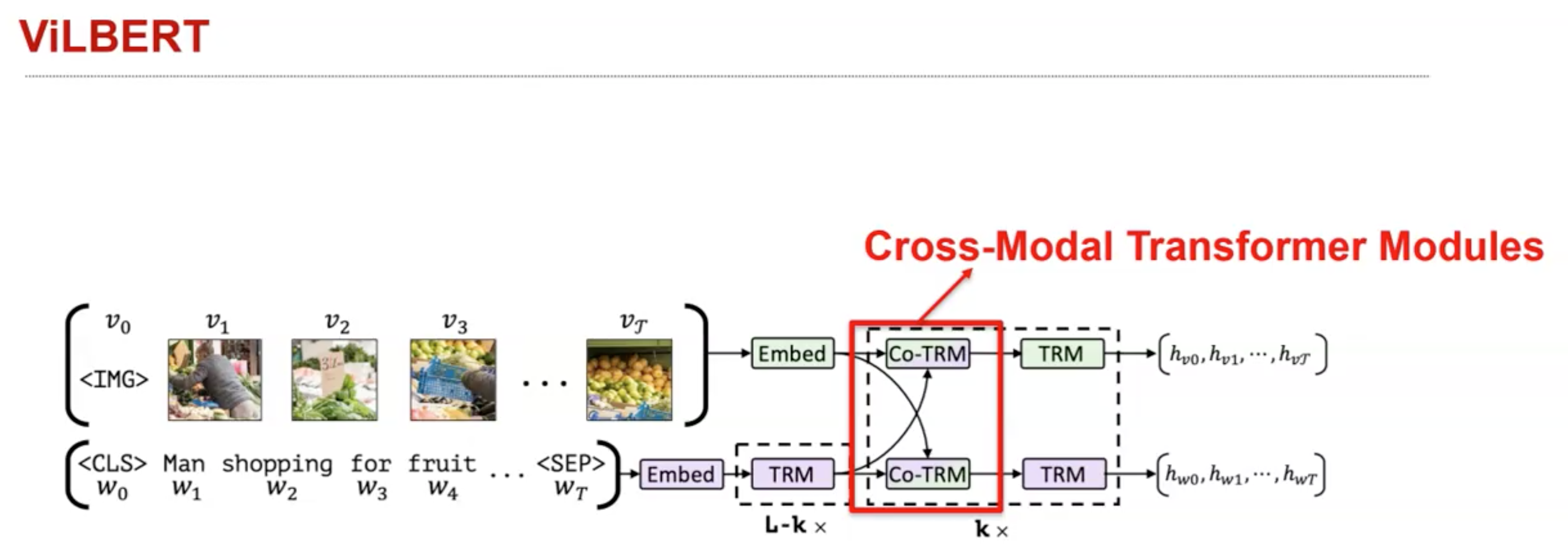
使用到了这种cross-modal Transformer的实例,比如ViLBERT(ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks):
再比如LXMERT:

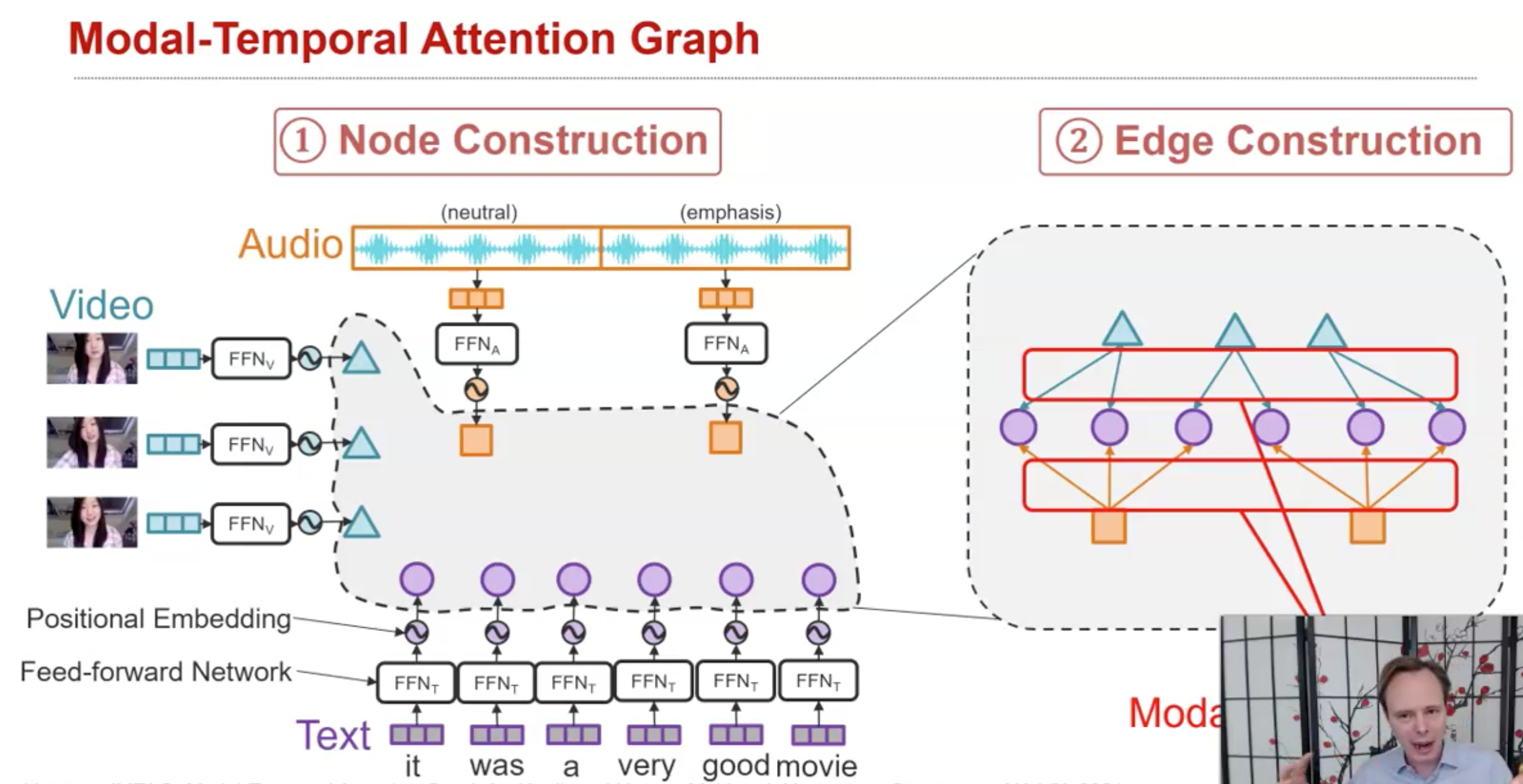
另外一个最近的研究兴趣是使用GNN实现alignment,不同模态的element可以互相关联到一起,通过不断的迭代GNN,对于每一个node都能够不断的看到更大的视野。
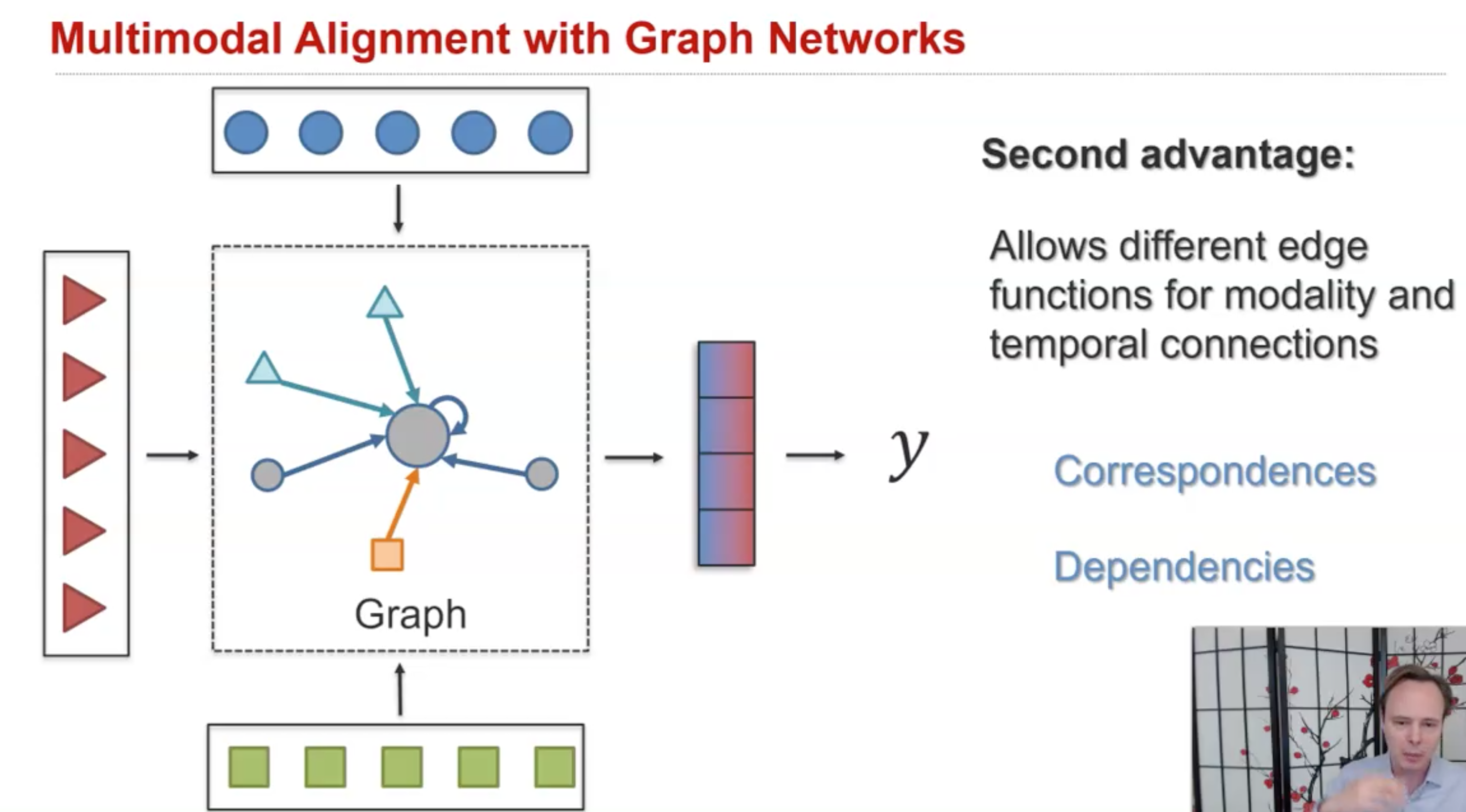
下面的方法是实例MTAG(Modal-Temporal Attention Graph for Unaligned Human Multimodal Language Sequences, NAACL 2021):