2-representation
MMML Tutorial Challenge 1: Representation
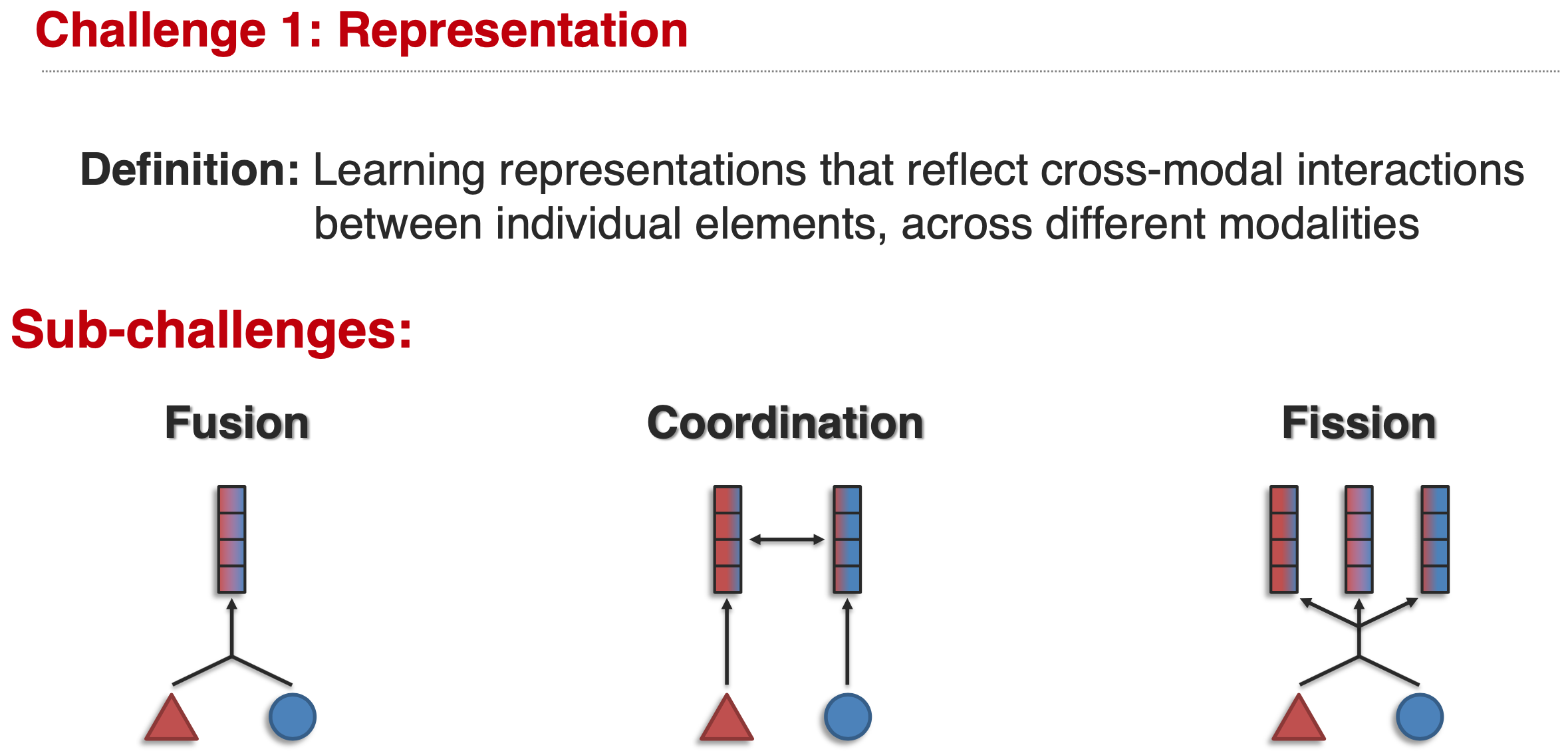
Challenge 1 Representation:
Learning representations that reflect cross-modal interactions between individual elements, across different modalities.
Representation challenge有三个sub-challenge,Fusion、Coordination和Fission。
Sub-Challenge 1: Representation Fusion
fusion的定义:
Learn a joint representation that models cross-modal interactions between individual elements of different modalities.
学习模态之间的联合表示。有两种fusion:
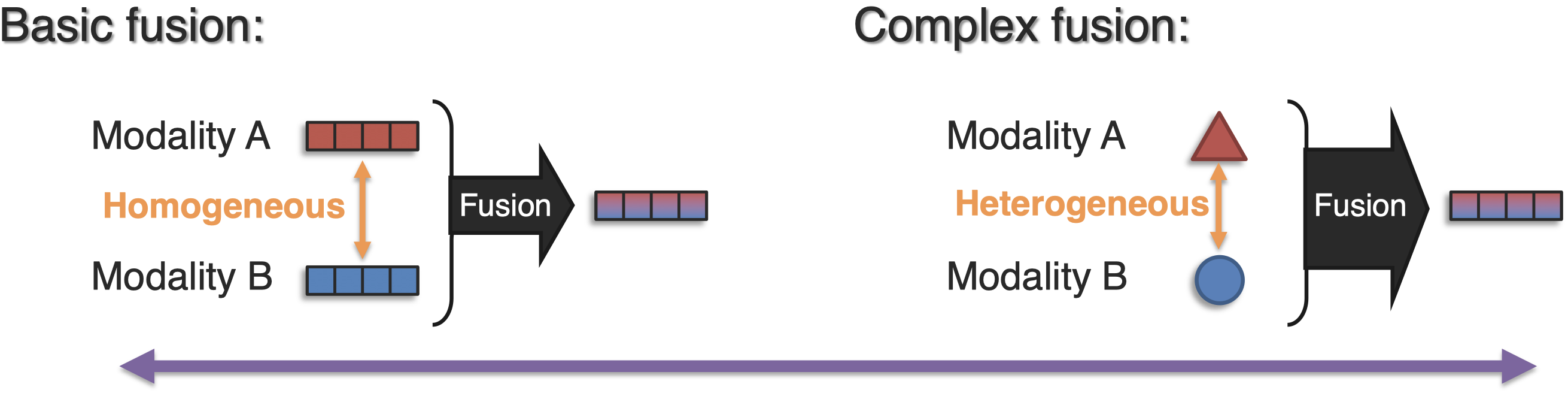
basic fusion指融合两个已经同质较多的modality;complex fusion是指融合异质性强的modality。basic fusion是很重要的,因为对于complex fusion在网络学习过程中,随着抽象层次的增加,不同模态之间的同质性是在增加的,最后进行融合的时候,可以看做是一个basic fusion。
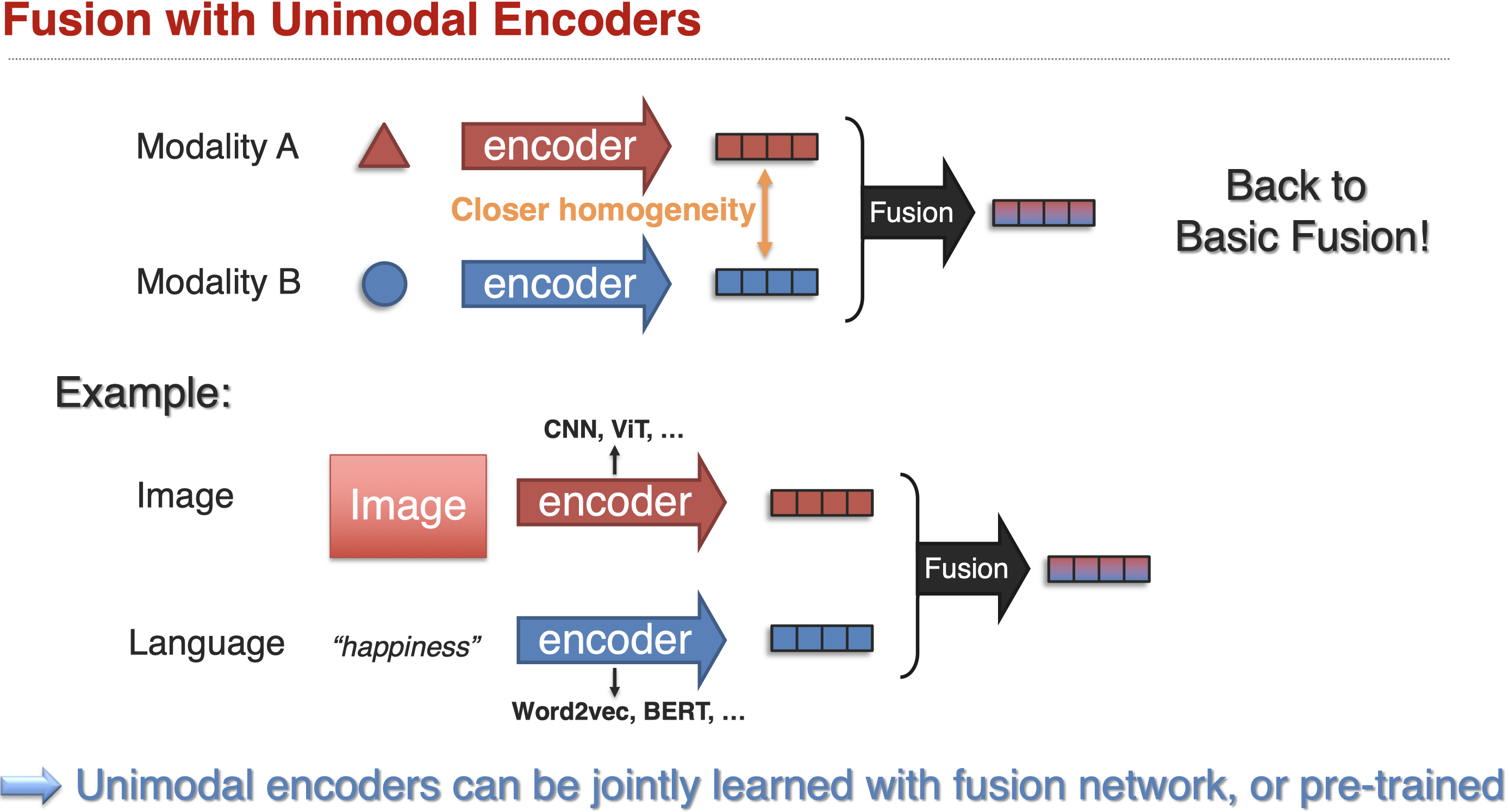
Basic fusion
首先,对于两个模态,我们可以简单的把它们的表示拼接到一起,叫做additive fusion:

additive fusion可以应用到更复杂的情况:
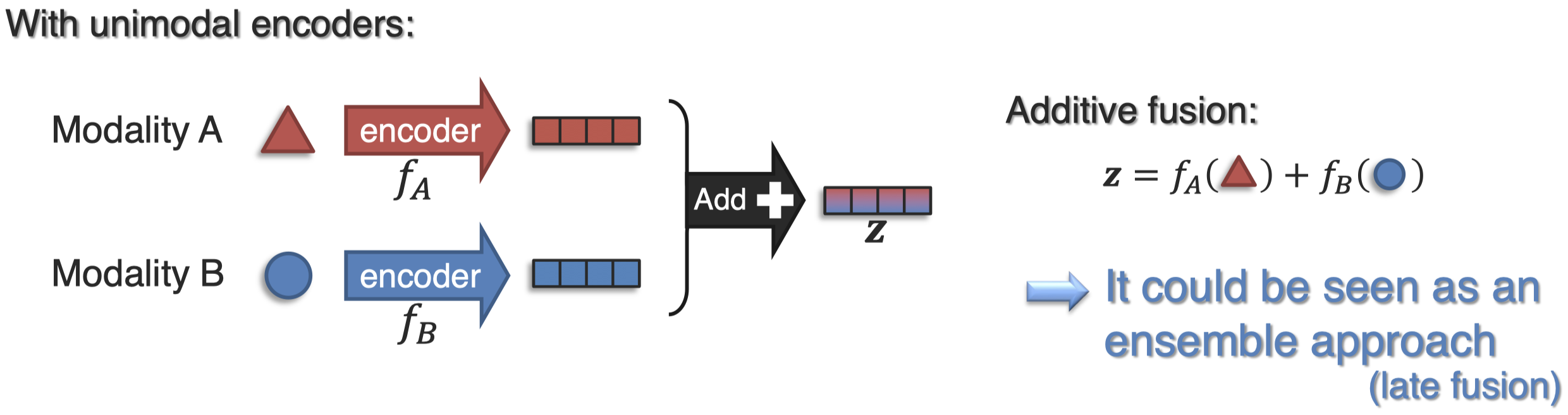
additive fusion可以看做是一种集成的方法,或者叫做late fusion。
如果认为这样加性的混合不能够满足模态交互的要求,那么可以采用乘法的交互,multiplicative fusion。

bilinear fusion:

tensor fusion,从张量角度融合表示。(Zadeh et al., Tensor Fusion Network for Multimodal Sentiment Analysis, EMNLP 2017)
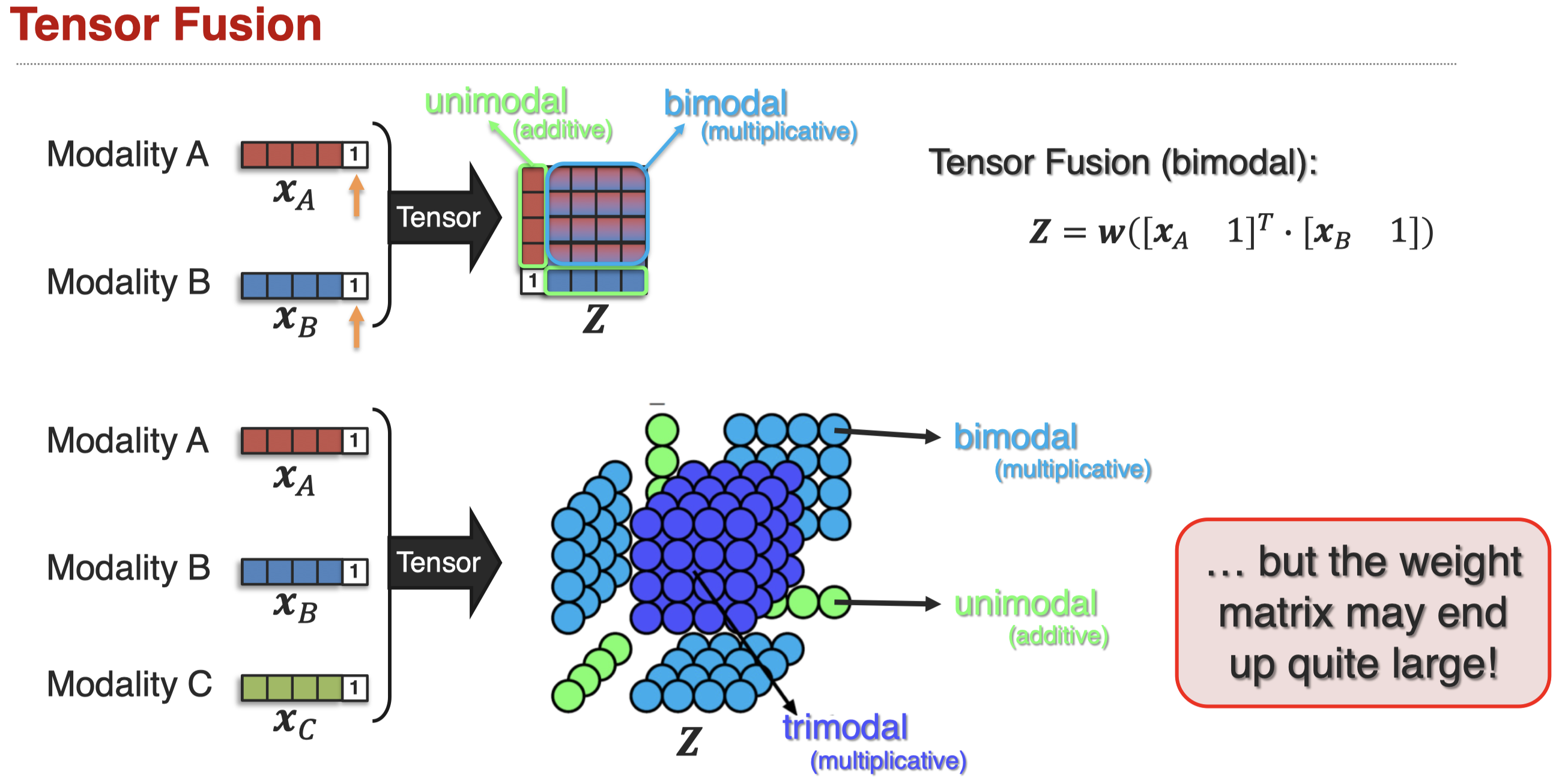
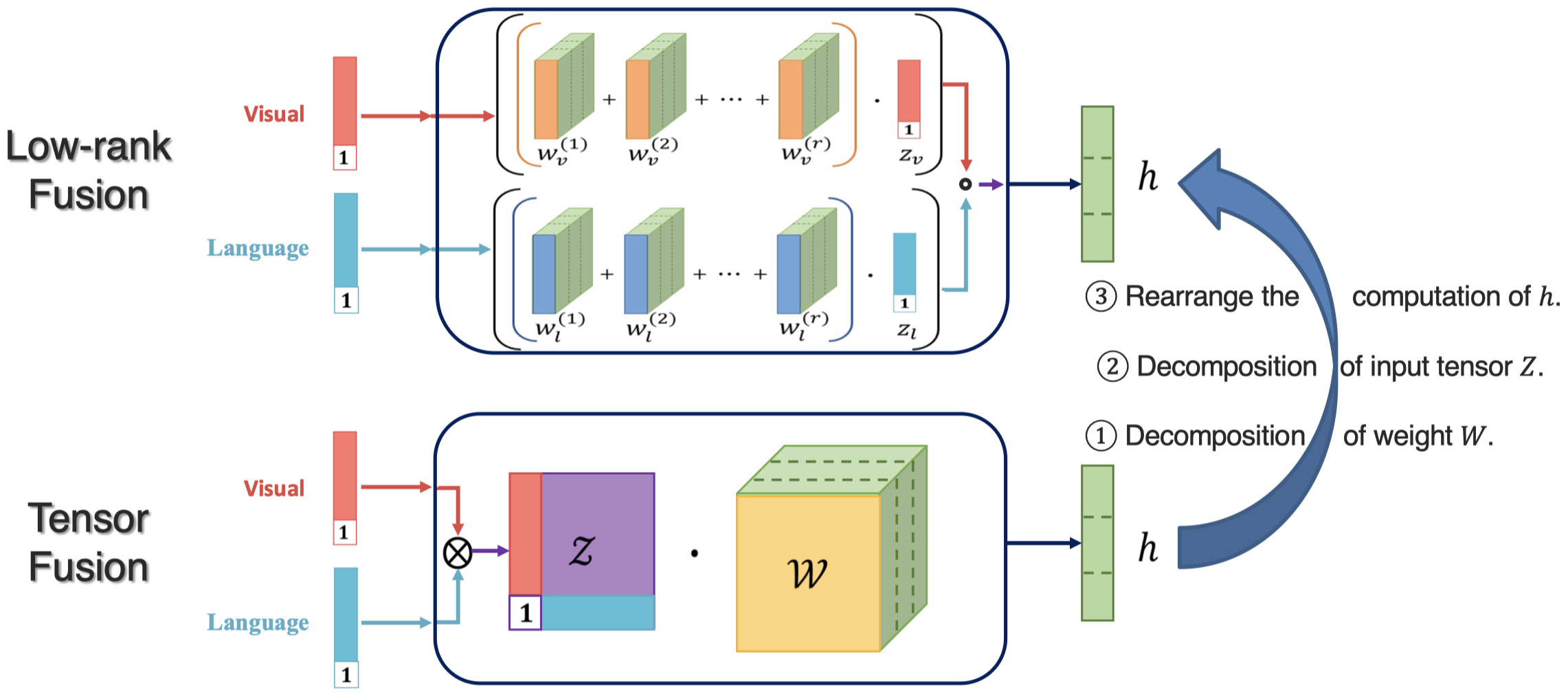
tensor fusion的结果tensor,会随着modality的数量增加而指数式增加。因此出现了降低计算成本的low-rank fusion(Liu et al., Efficient Low-rank Multimodal Fusion with Modality-Specific Factors, ACL 2018)。
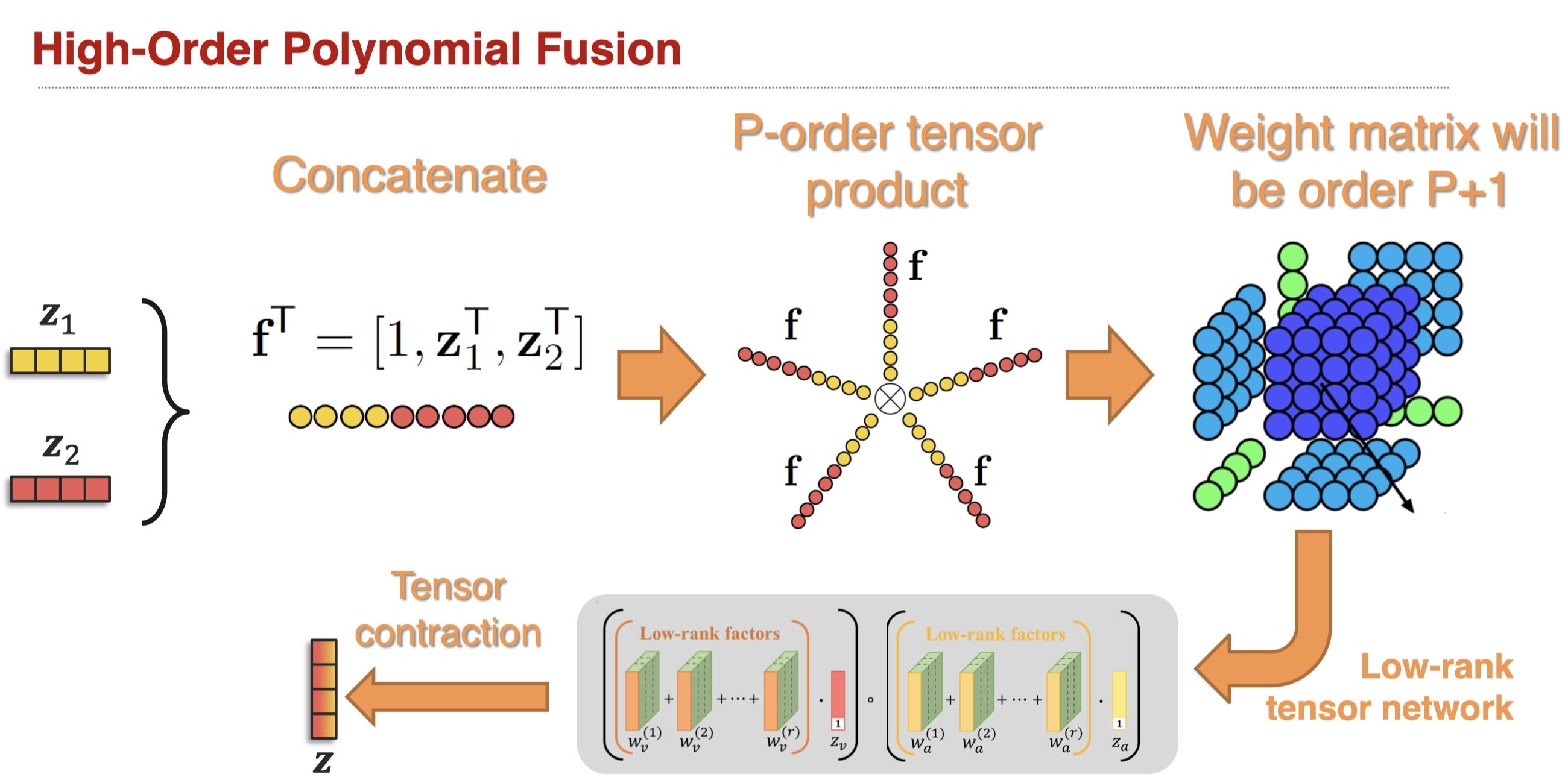
如果进一步拓展加法fusion和乘法fusion,我们可以获得high-order polynomial fusion(Hou et al., Deep Multimodal Multilinear Fusion with High-order Polynomial Pooling, Neurips 2019)。

gated fusion,对于不同模态,设计融合信息的gate(Gated Multimodal Units for information fusion,)。

gate的设计可以是线性的,非线性的或者是核函数,都是在衡量模态间的相似程度。
Nonlinear Fusion就是利用神经网络进行融合,比如通过一个MLP。

对于这种方法,可以看做是一种early fusion,因为仅仅是拼接了两个向量后,然后进行融合,只不过融合的方法变成了神经网络。对于nonlinear fusion,必须注意的是,它真的学习到了nonlinear interaction吗?
之后有人提出了EMAP方法衡量fusion方法对nonlinear interaction的建模能力。核心思想是,通过EMAP,将nonlinear fusion投影到additive fusion上,如果得到的additive fusion的预测能力和nonlinear fusion的预测能力相近,那么就说明fusion没有很好的建模非线性的信息。

作者发现,部分的fusion方法表现出来的结果,并没有很好的建模非线性的交互信息。
Complex fusion
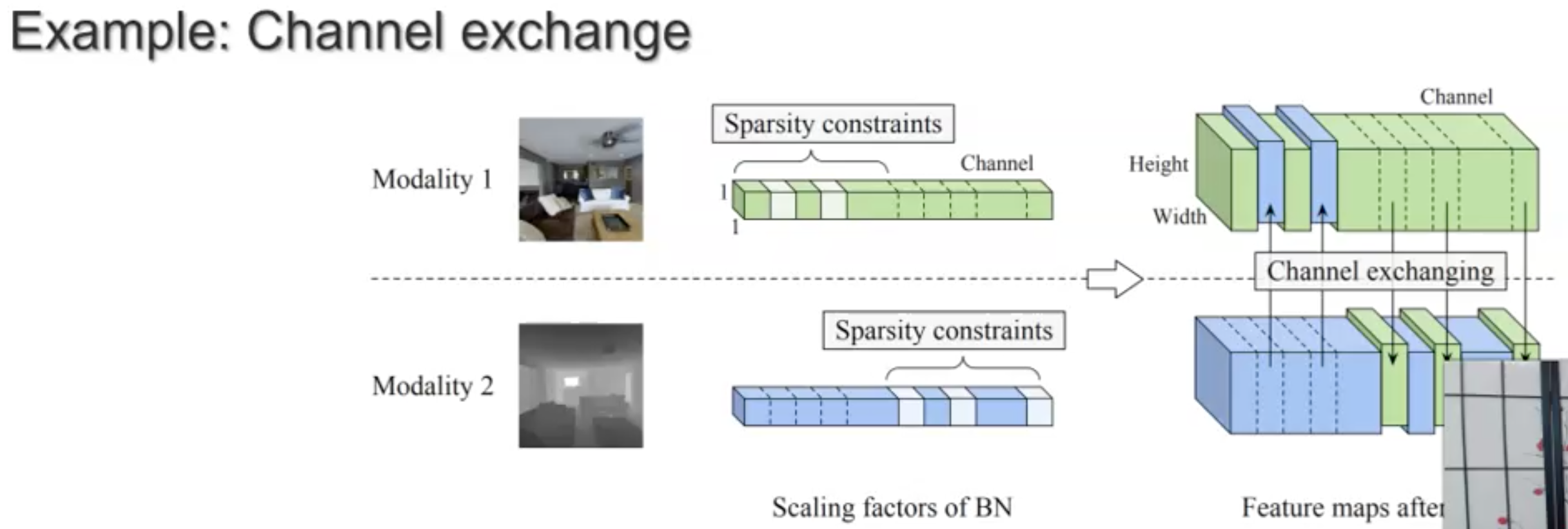
仍然是非常有挑战的方法,如何直接处理异质性很强的模型?下面是一个实例,通过进行channel exchange直接进行模态fusion(Deep multimodal fusion by channel exchanging)。
Sub-Challenge 2: Representation Coordination
模态信息的协作coordination,定义是:
Learn multimodally-contextualized representations that are coordinated through their cross-modal interactions.
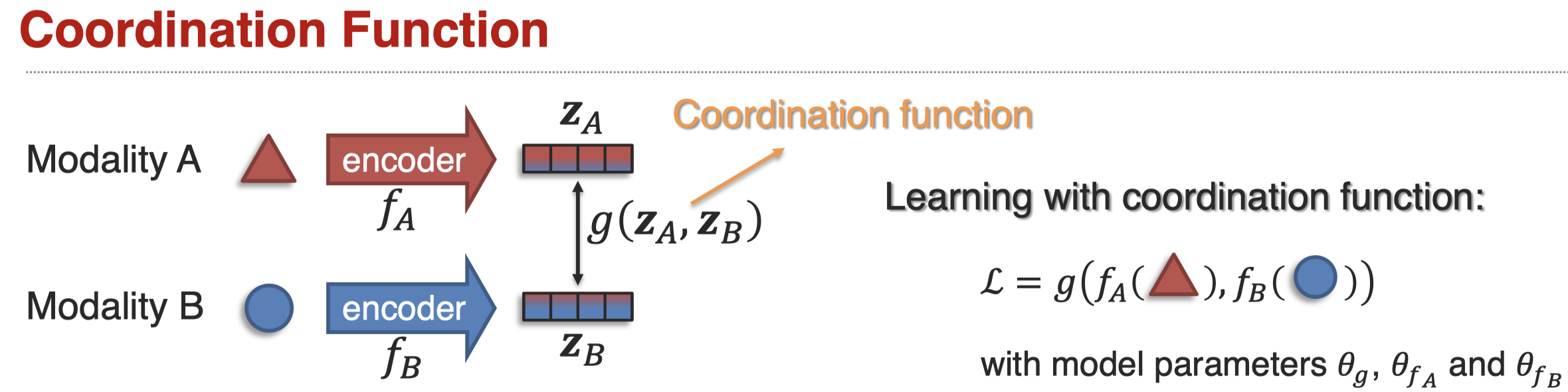
和fusion不同的是,它不会把所有模态信息融合到一个表示空间中,而是用某种方式保持模态信息的一致。存在两种coordination:

一般的,这种coordination function以loss function的形式实现:
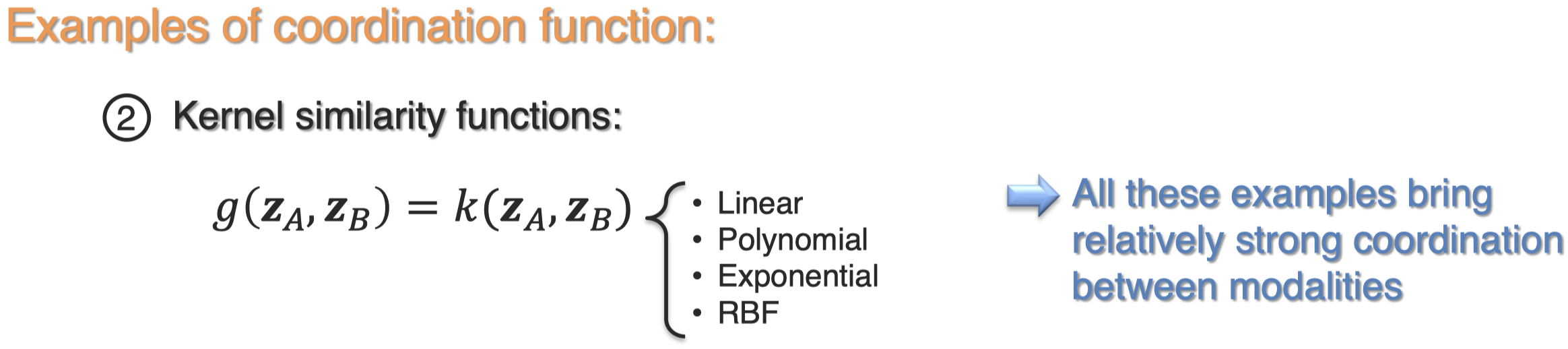
下面是几种coordination function示例:


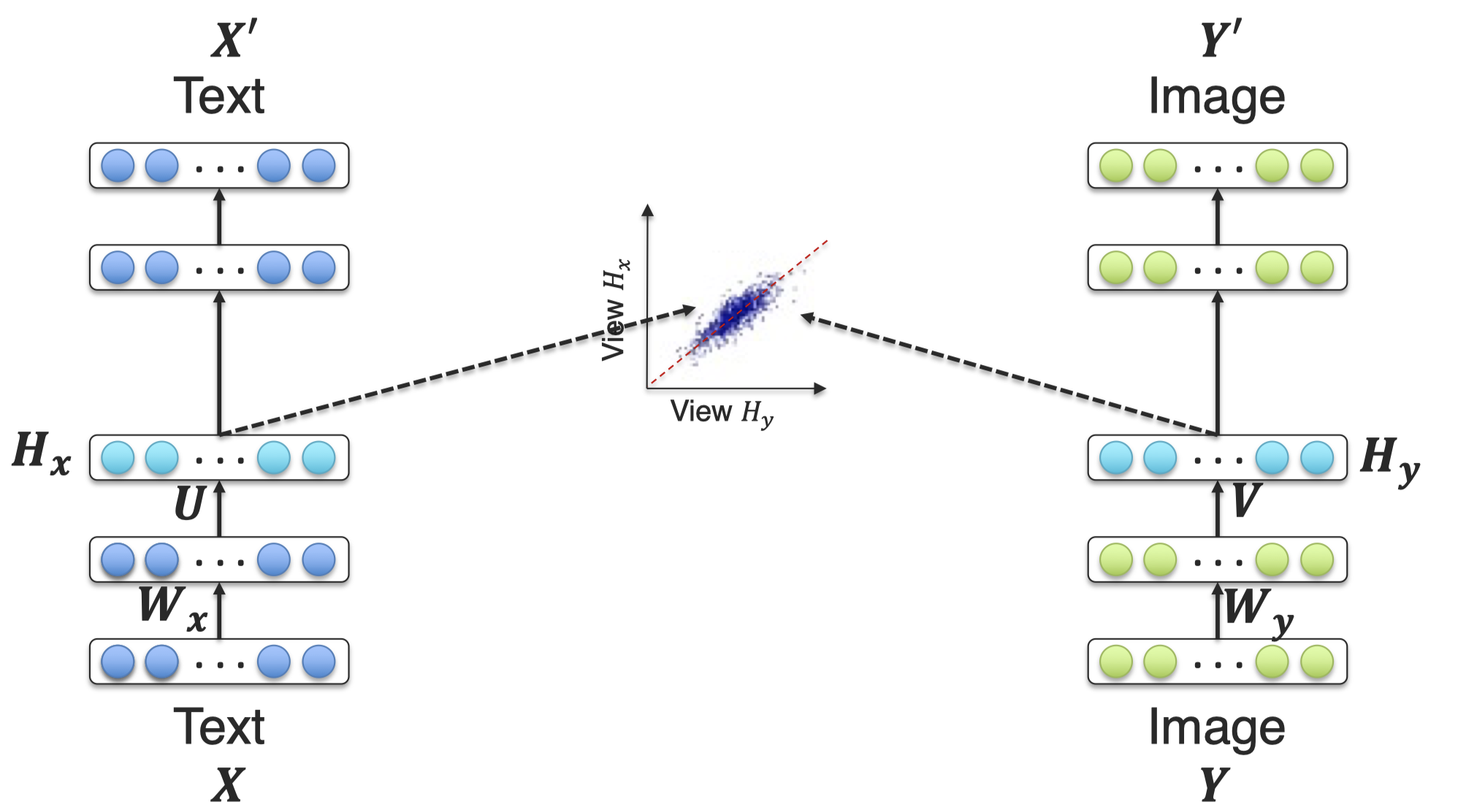
CCA是指让不同模态的latent representation保持较强的相关性,下面是一个实例(DCCAE,Wang et al., On deep multi-view representation learning, PMLR 2015)。
还有的方法,假设模型能够学习到完整的intact的表示,不同模态的表示只是intect representation在不同view下的表现(Xu et al., Multi-View Intact Space Learning, TPAMI 2015):

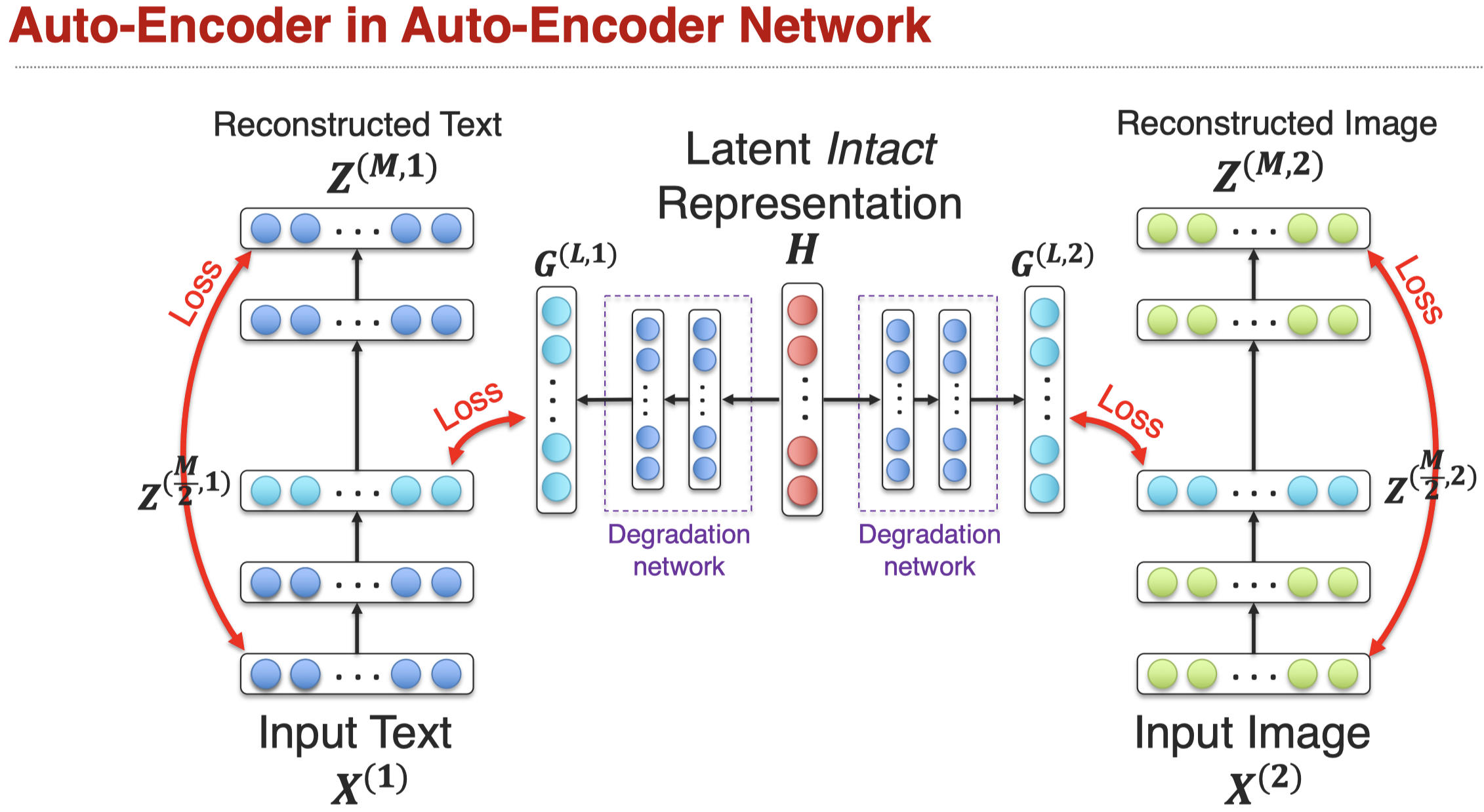
再比如下面的方法,通过学习intact representation,然后设计在单个模态的degradation network(Zhang et al., AE2-Nets: Autoencoder in Autoencoder Networks, CVPR 2019):
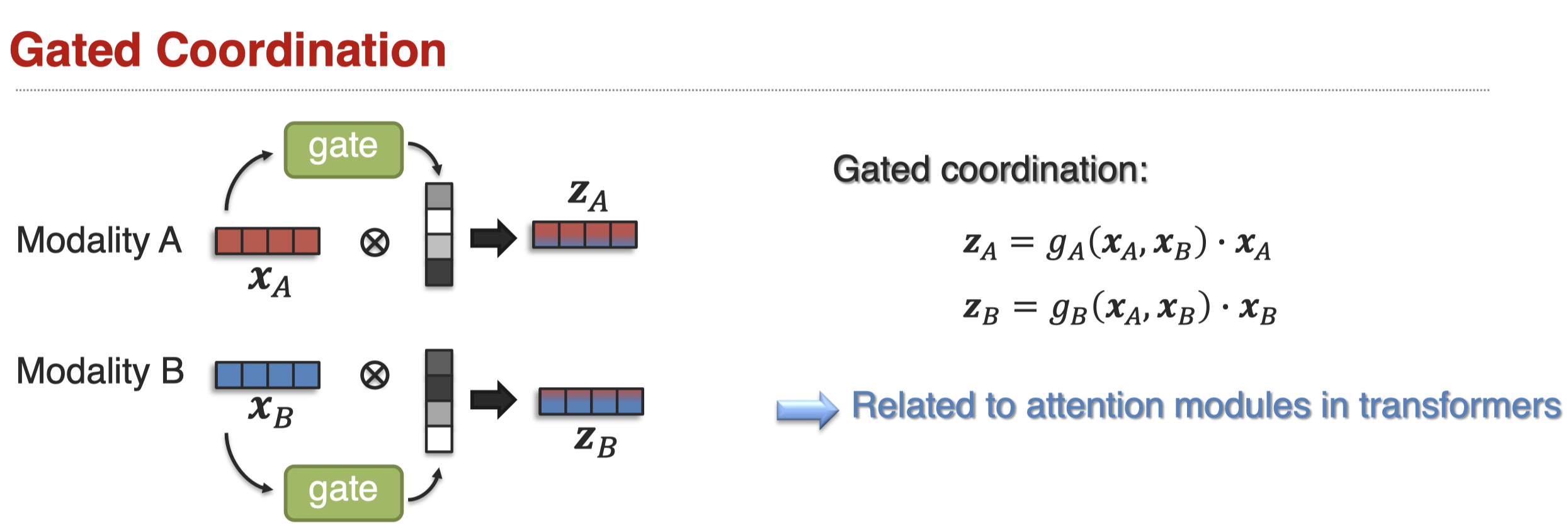
还有gated coordination:
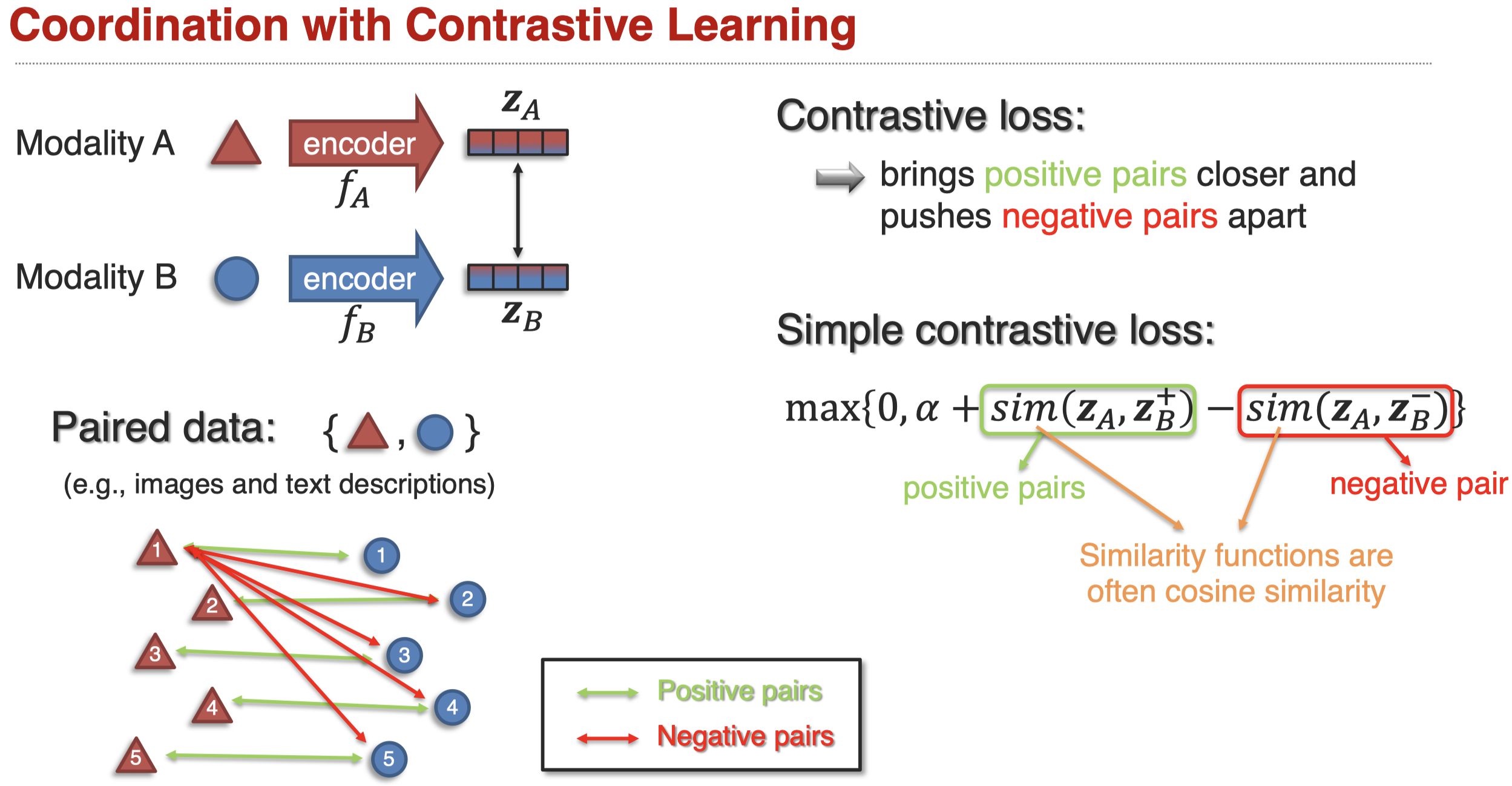
另外一个popular的方法是对比学习Contrastive learning。它不需要像前面的方法一样,人工设计某种相似度函数,强迫latent representation互相靠近,而是定义关联的不同模态element pair,通过定义loss,让关联的不同模态的element pair互相靠近,不相关的pair互相远离,这样最后学习到的latent representation自然会表现出关联的相近,不关联的远离。
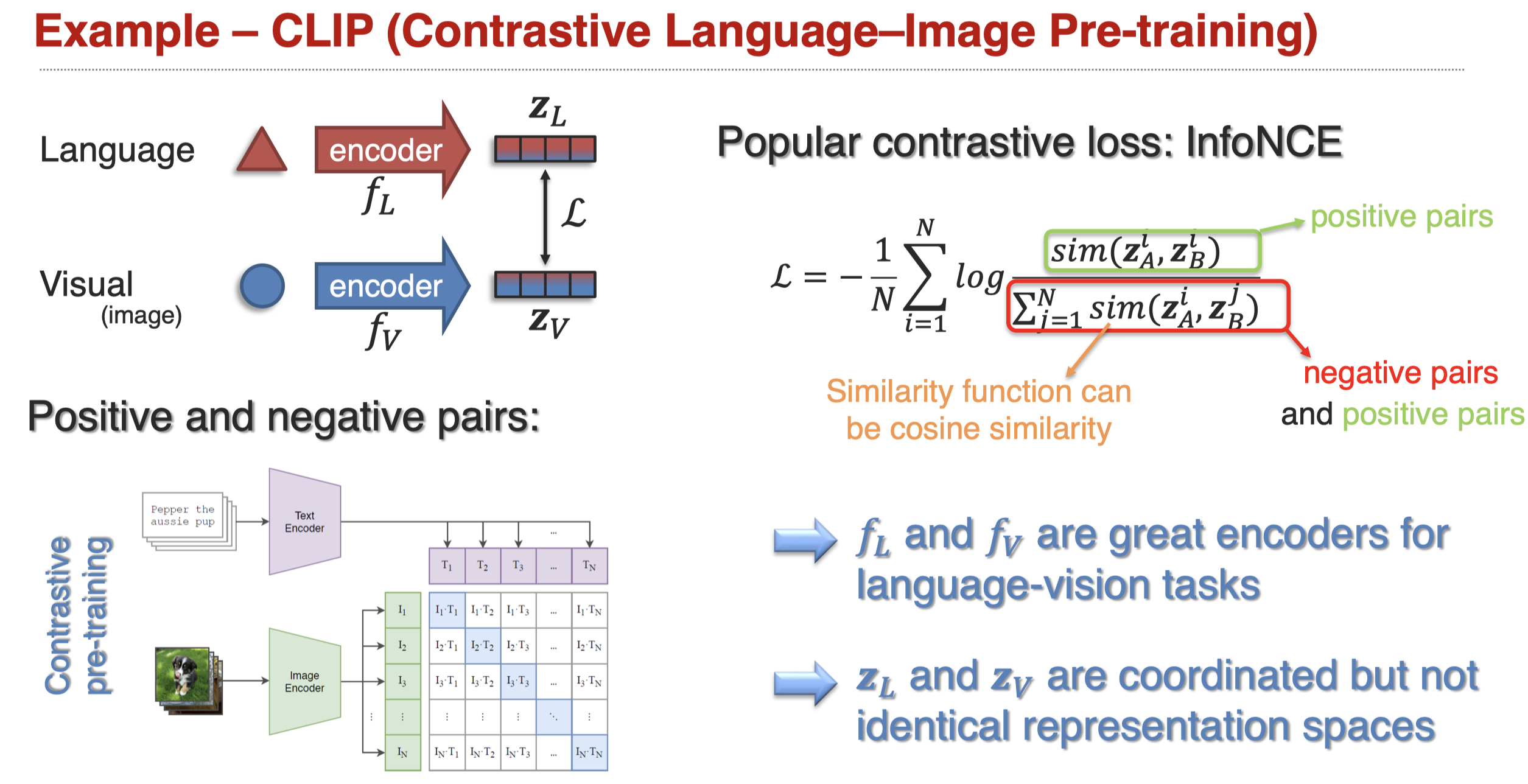
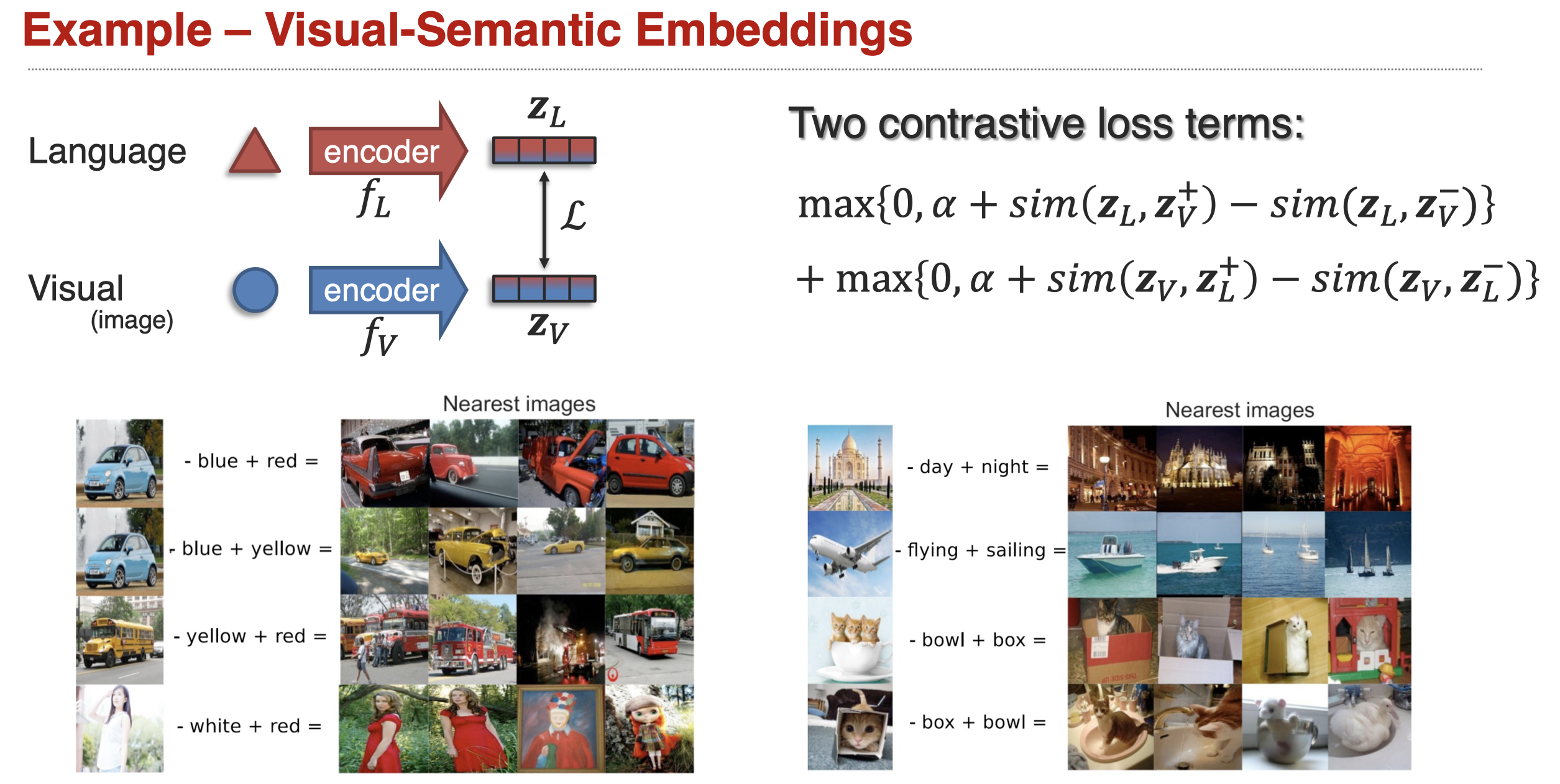
举例,比如CLIP(Radford et al., Learning Transferable Visual Models From Natural Language Supervision, arxiv 2021):
再比如(Kiros et al., Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models, NIPS 2014):
Sub-Challenge 3: Representation Fission
fission定义:
learning a new set of representations that reflects multimodal internal structure such as data factorization or clustering.
同样有两种类似的fission:

Modality-Level Fission,期望能够学习只包含在modality A中的信息,学习至包含在modality B中的信息,学习同时包括A和B的信息:
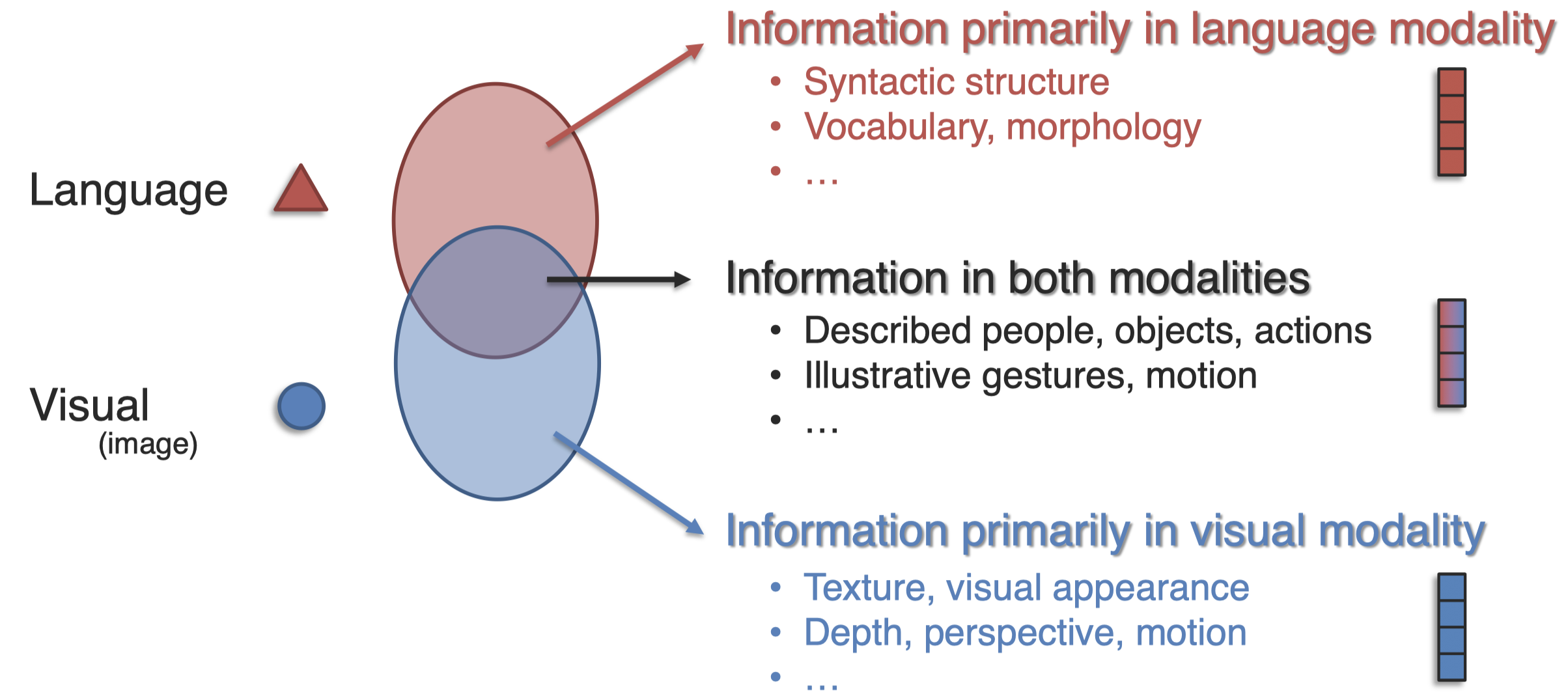
如何学习这三种不同的表示?
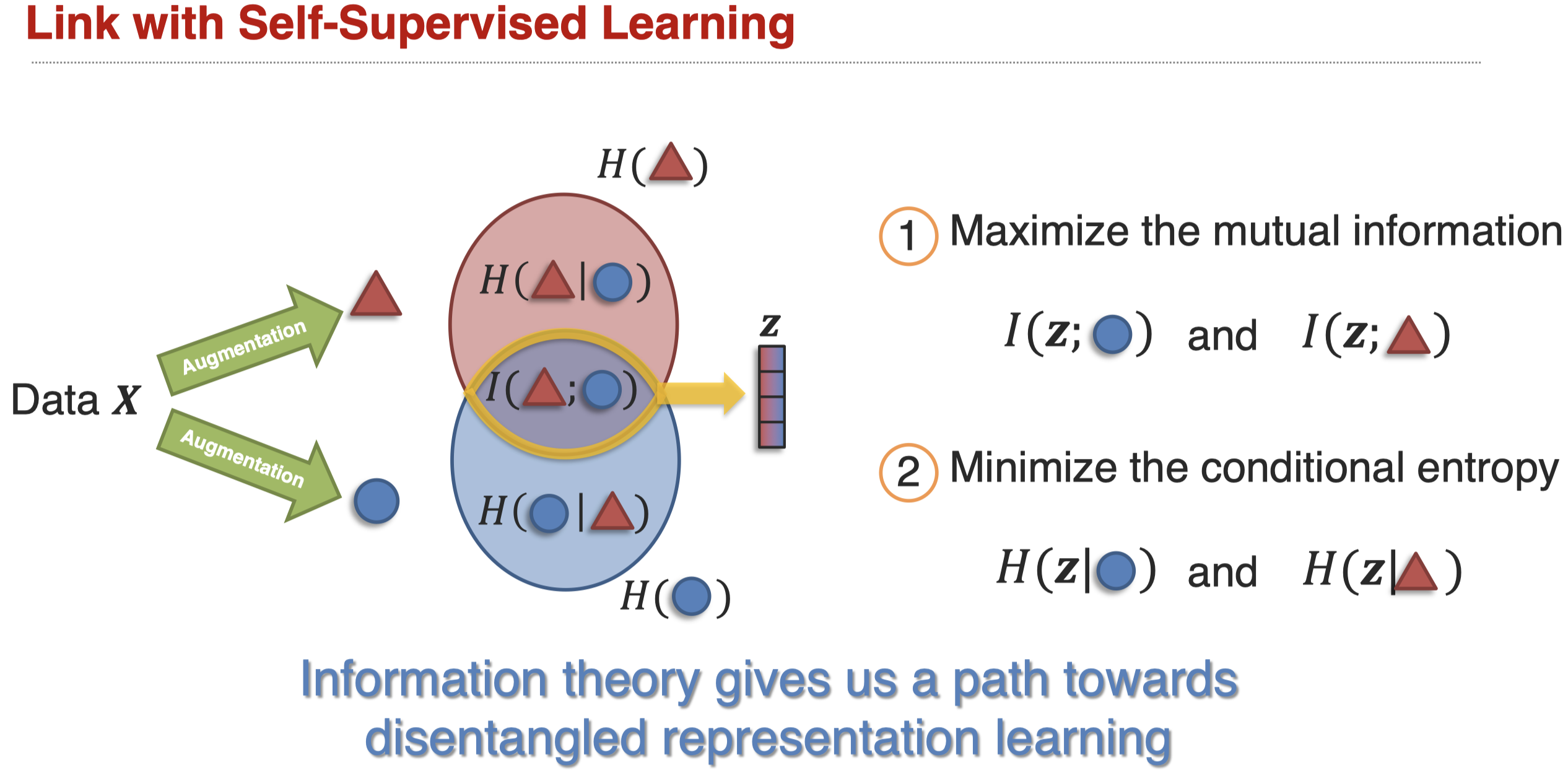
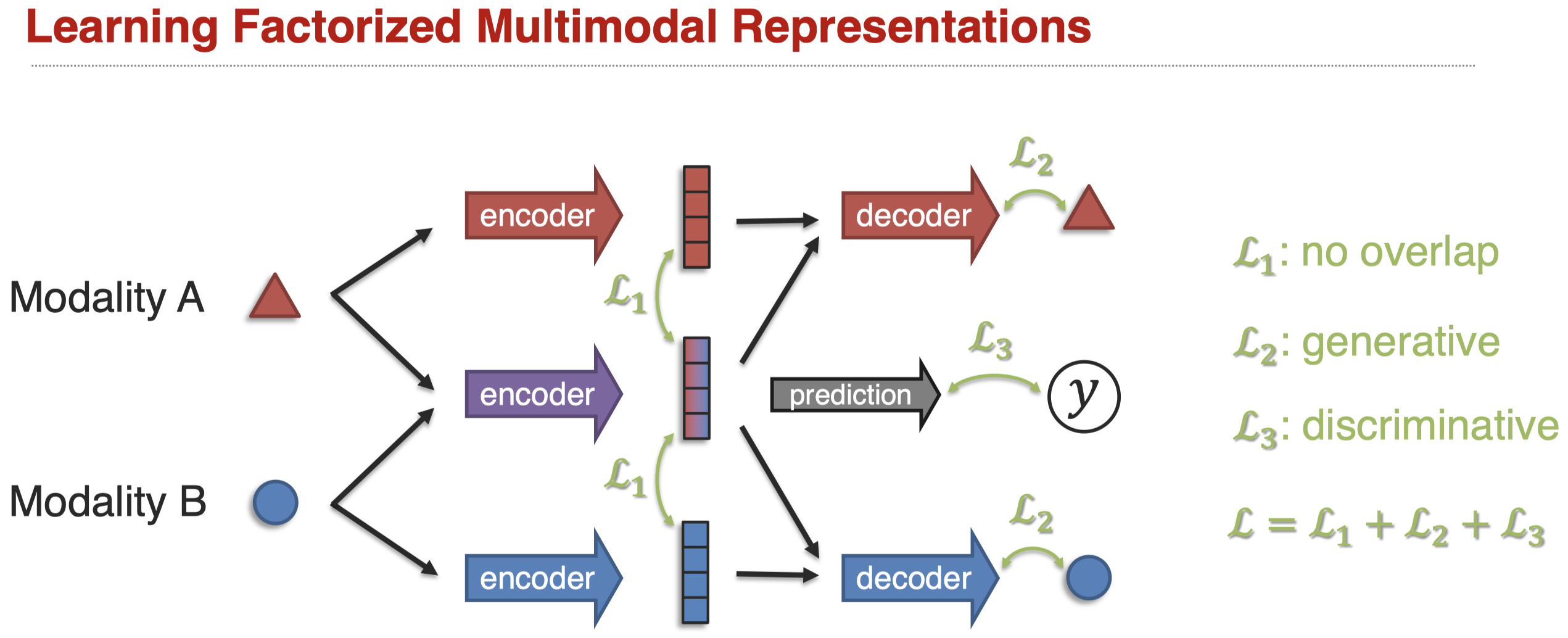
有一种方法是从loss的角度,让不同的表示有不同的倾向(Tsai et al., Learning Factoriazed Multimodal Representations, ICLR 2019)。我们使用\(L_1\)让不同的表示尽可能有所区别,避免信息重叠;使用\(L_2\)还原原来的模态信息;使用\(L_3\)进行预测任务。
对于上面这种做法的理解,可以从信息论的角度看(Tsai et al., Self-Supervised Learning from a Multi-View Perspective, ICLR 2021):
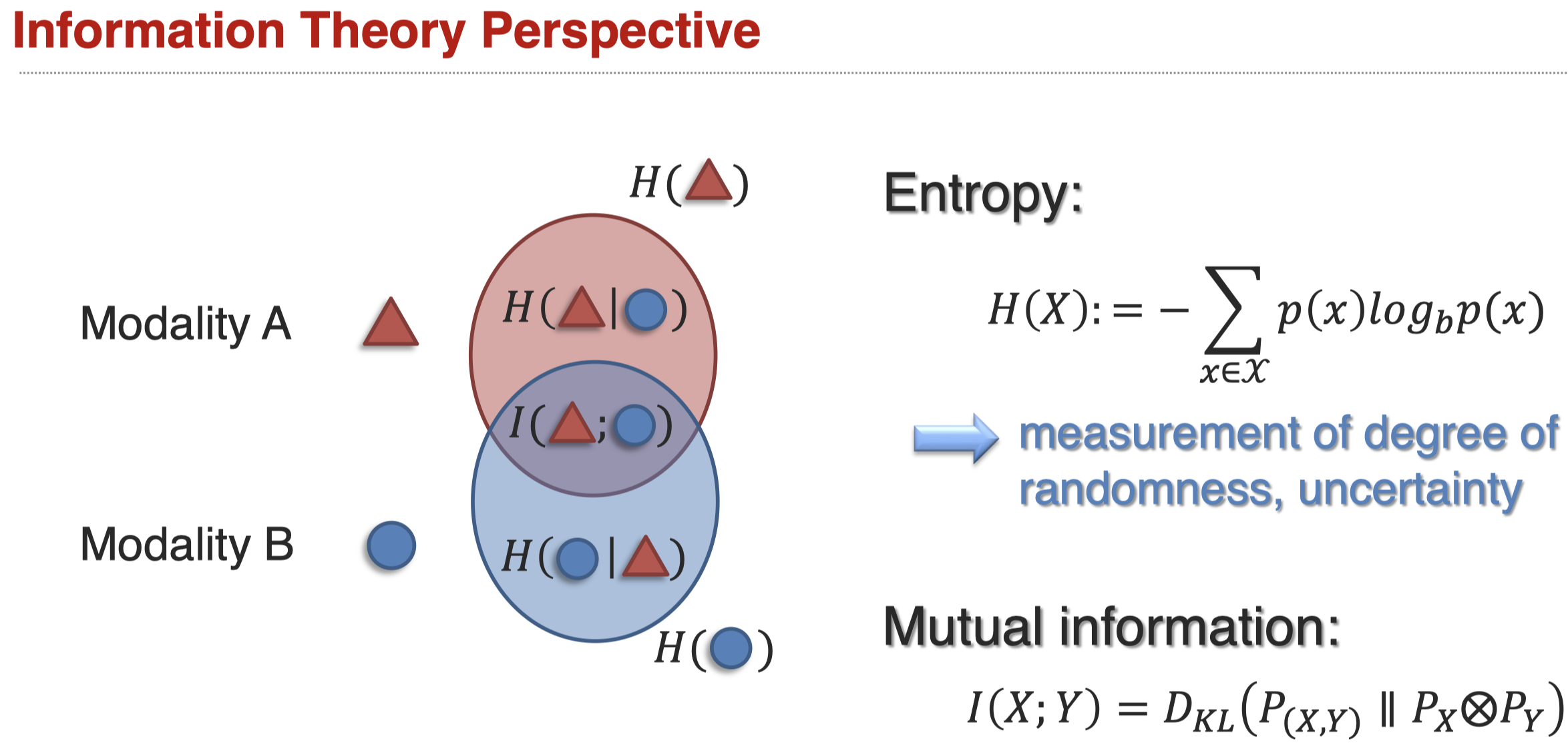
让mutual information尽可能的大,让条件熵尽可能的小。