1-intro
CMU MML Tutorial Louis-Philippe Morency
MMML Tutorial: Introduction
多模态介绍
什么是multimodal?
在数学上,我们描述多模态是在概率上有不同的分布趋势。
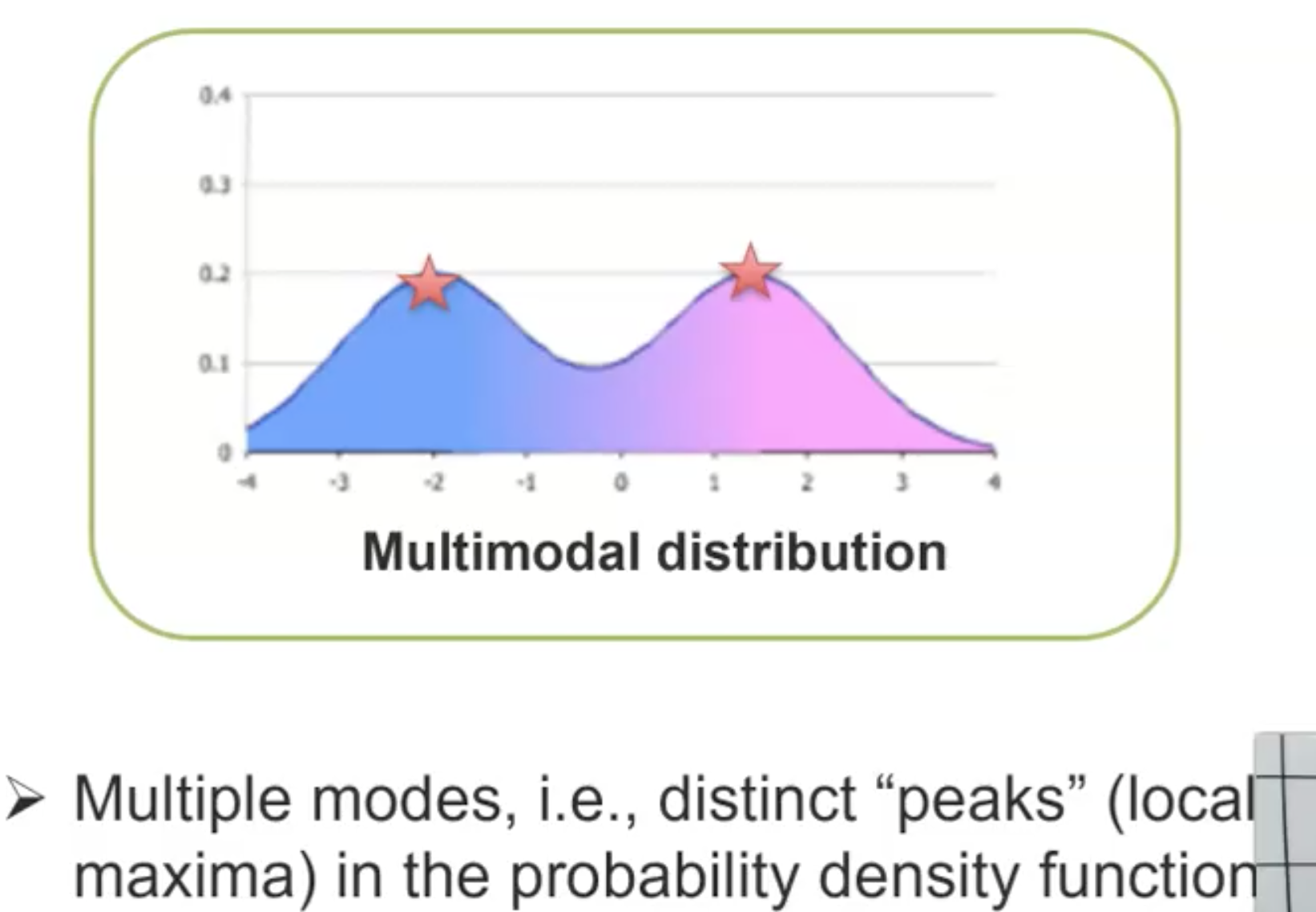
但是现在,我们大多提到多模态,更多是在指multiple modalities。更准确的说是sensory modalities。
不同的模态意味着拥有不同的特征或者说信号。

那么接下来,什么是模态Modality?
一种较通用的定义是,多模态是指
Modality refers to the way in which something expressed or perceived.
也就是指信息被表达或者感知的方式。
下面是对于模态理解的一种角度:
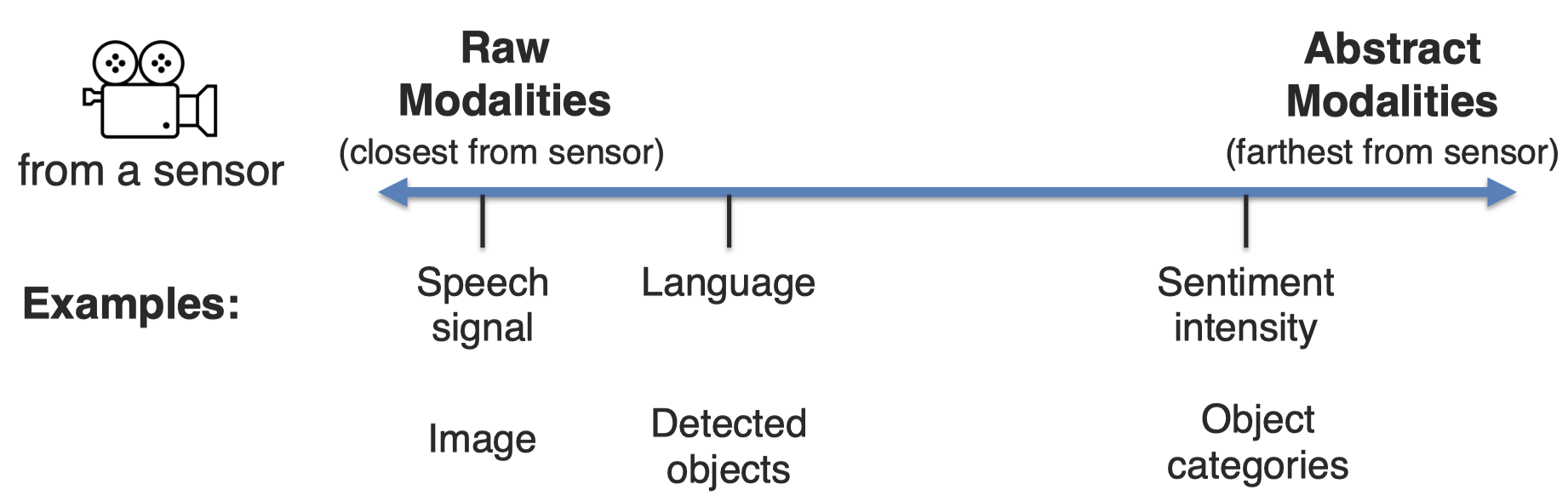
从这个角度出发,我研究的KG,本身就已经是经过人类处理之后的模态,已经较为抽象,脱离了一开始的原始形式。
什么是多模态Multimodal?
词典上的定义:
Multimodal: with multiple modalities.
研究人员的定义:
Multimodal is the science of heterogeneous and interconnected data.
核心解决两个问题:不同模态的差异性和不同模态如何联系到一起。
不同模态表示的信息,通常是异质的heterogeneous。并且,如果是更抽象的模态,表示的信息会更加趋同。(这么一想,或许这是为什么我们会尝试利用神经网络,在高层进行模态信息的融合,而不是在低层)
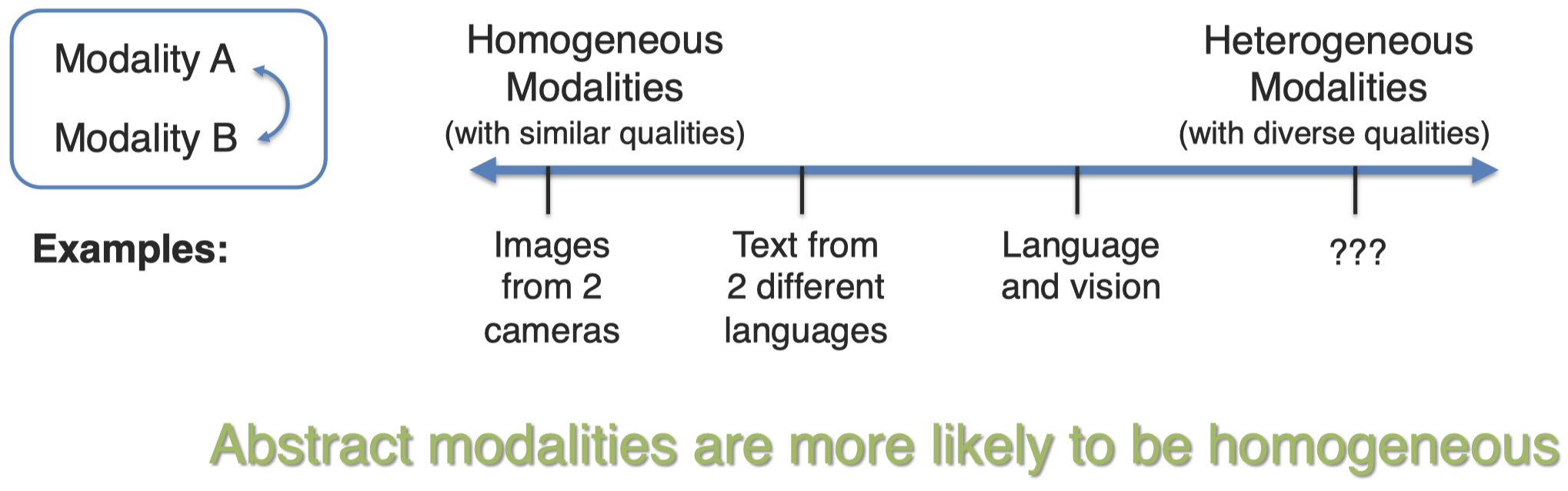
两个在不同角度拍摄的照相机,它们的结果当然是相近的(但肯定因为角度不同有所区别);两个来自不同语言的文本,差异性就会比较大;而语言和视觉之间的差异就更大了。
不同模态信息可能存在差异的几个维度实例:

比如结构上的差异、表达空间的差异(例如speech通常是连续的)、信息表现的特征、特征的粒度、数据的噪音、模态是否和任务相关等等方面。
模态的元素之间通常是如何关联到一起的,对于关联到一起的元素,我们如何让它们之间进行交互?这个通常是多模态学习需要解决的关键核心问题。
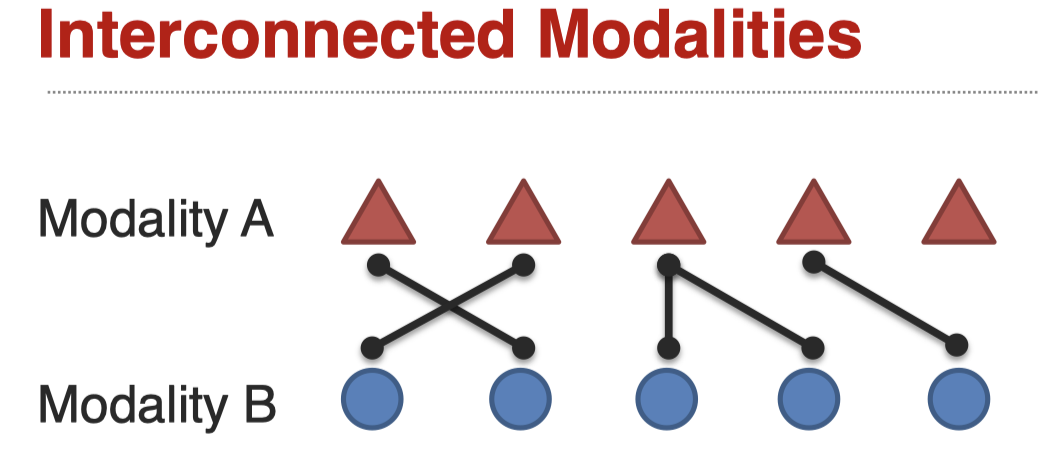


不同模态交互,可能存在的情况举例:
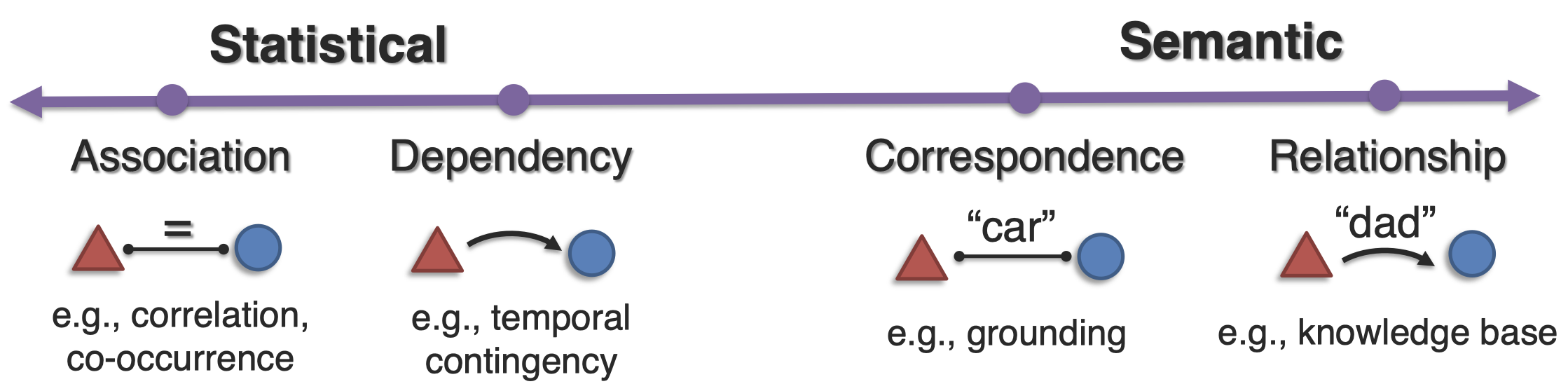
从统计角度看,两个不同模态元素经常同时出现;某个模态经常依赖于另外模态的元素(时间/空间);从语义角度看,两个模态元素都是在描述统一事物;或者两个模态元素之间存在语义联系。
接下来,对于关联的多模态元素,出现不同特征/信号的时候,可能出现什么样的结果?
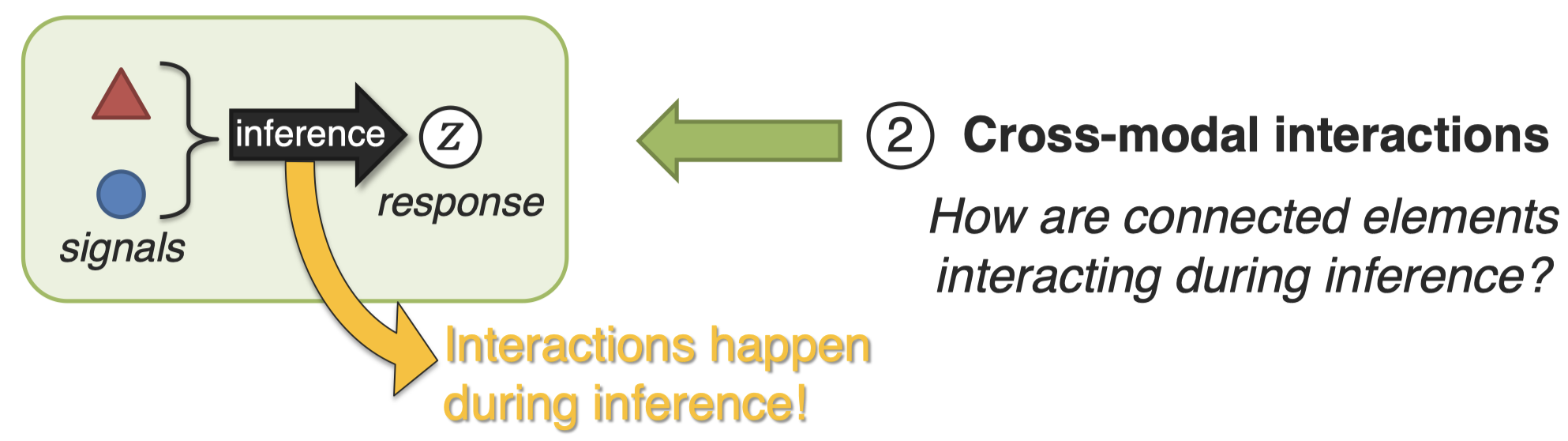
举例:
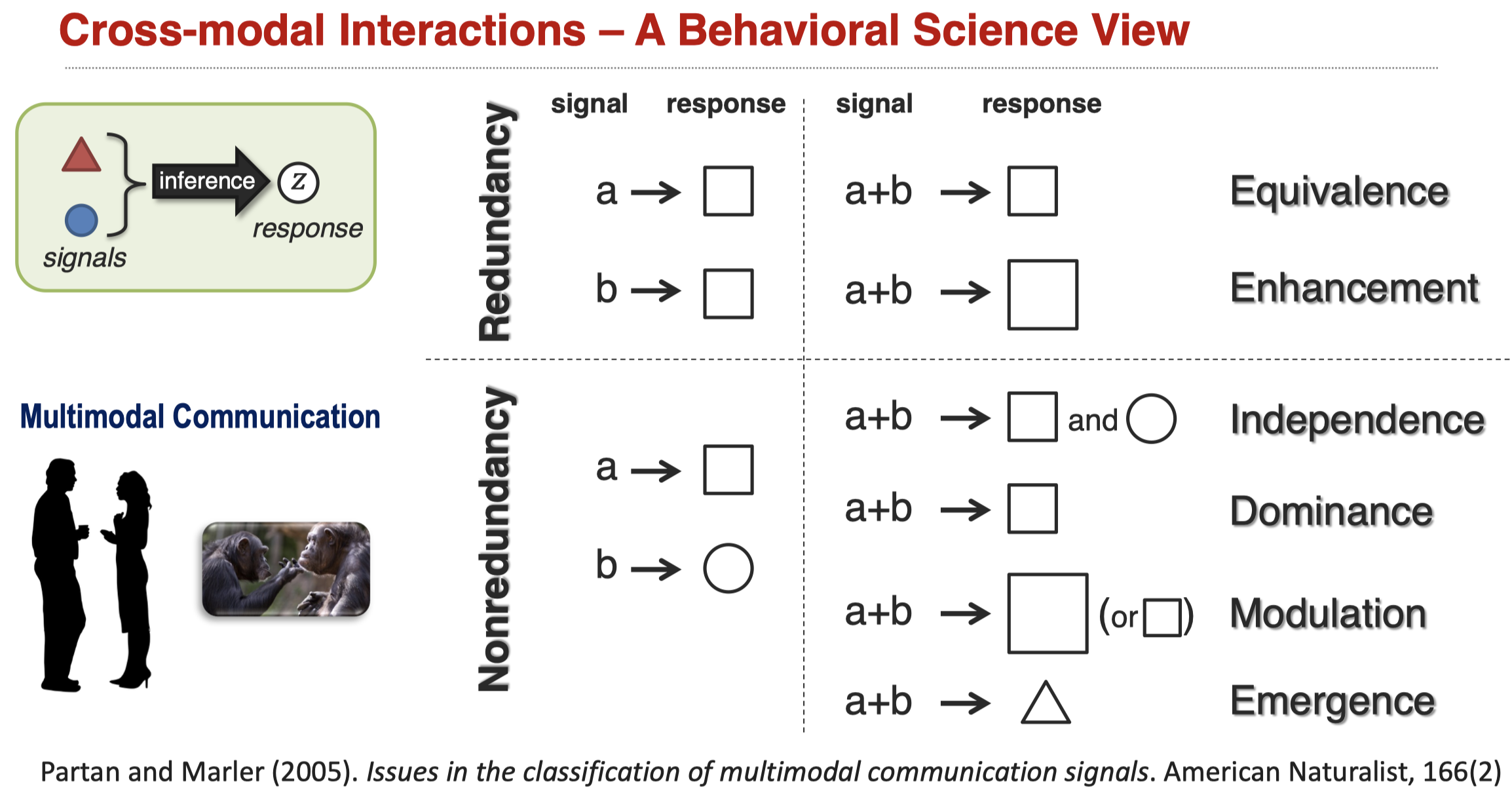
比如在上面的图中,不同模态出现了不同的信号,有不同的响应。不同模态响应同时作用下,可能出现响应的增强/互补、响应不变、响应倾向于某个模态、或者是出现新的响应形式。
对于不同模态元素的交互,通常可以从以下几个维度考虑:

多模态研究历史

一开始的时候,研究人员从社会学的角度,研究不同模态之间的联系,比如David McNeill研究了手势和语言之间的联系,认为语言是speech的必要组成部分。

随后,出现了基于计算的研究
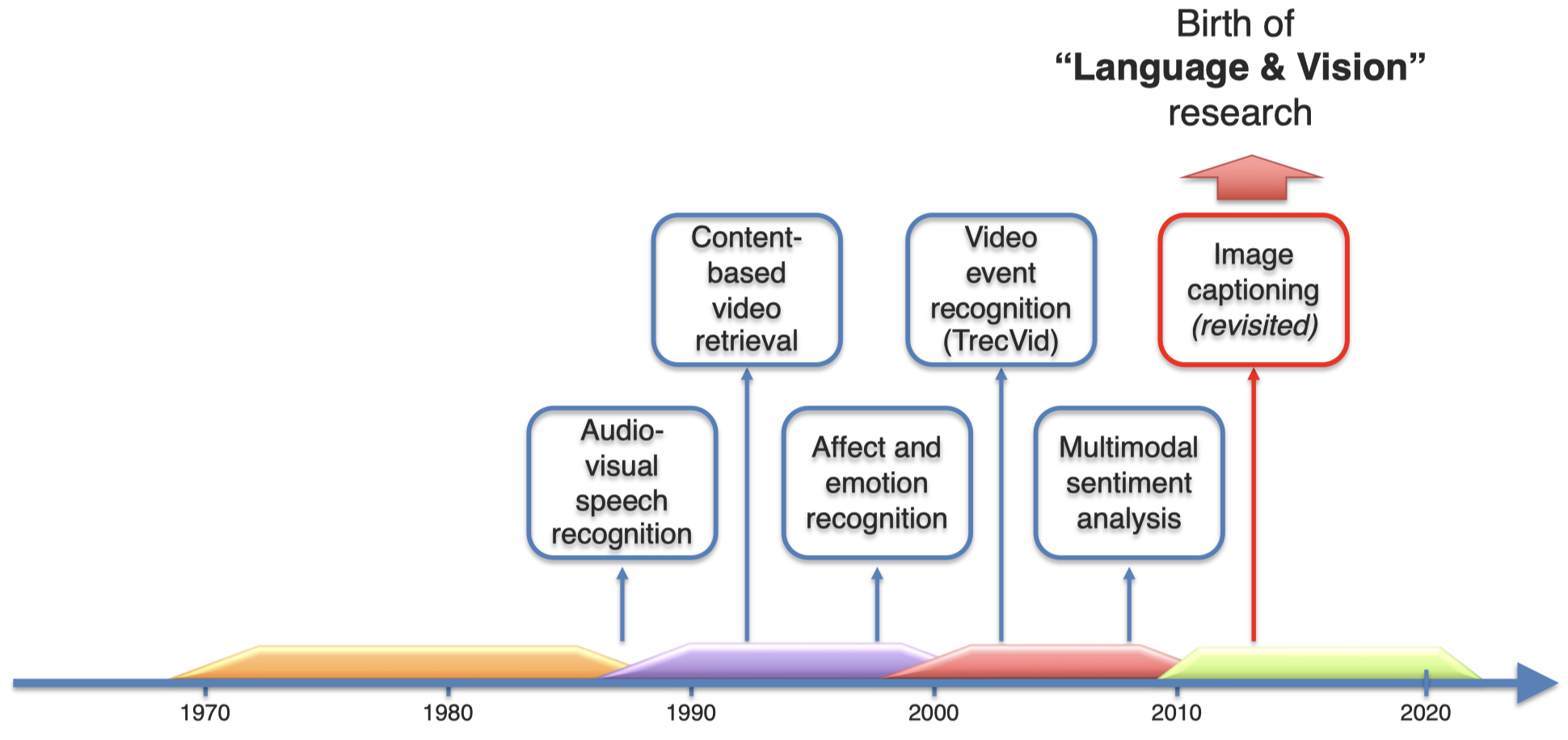
由于在nlp方向,人们能够把token表示为向量,例如word2vec;在cv方向,人们同样能够适应cnn把image的object表示为向量。人们通过这种方法,让文本和图像之间表现出了更多的homogeneous。
在过去的五年中,利用深度学习,出现了大量的不同模态之间的研究方向
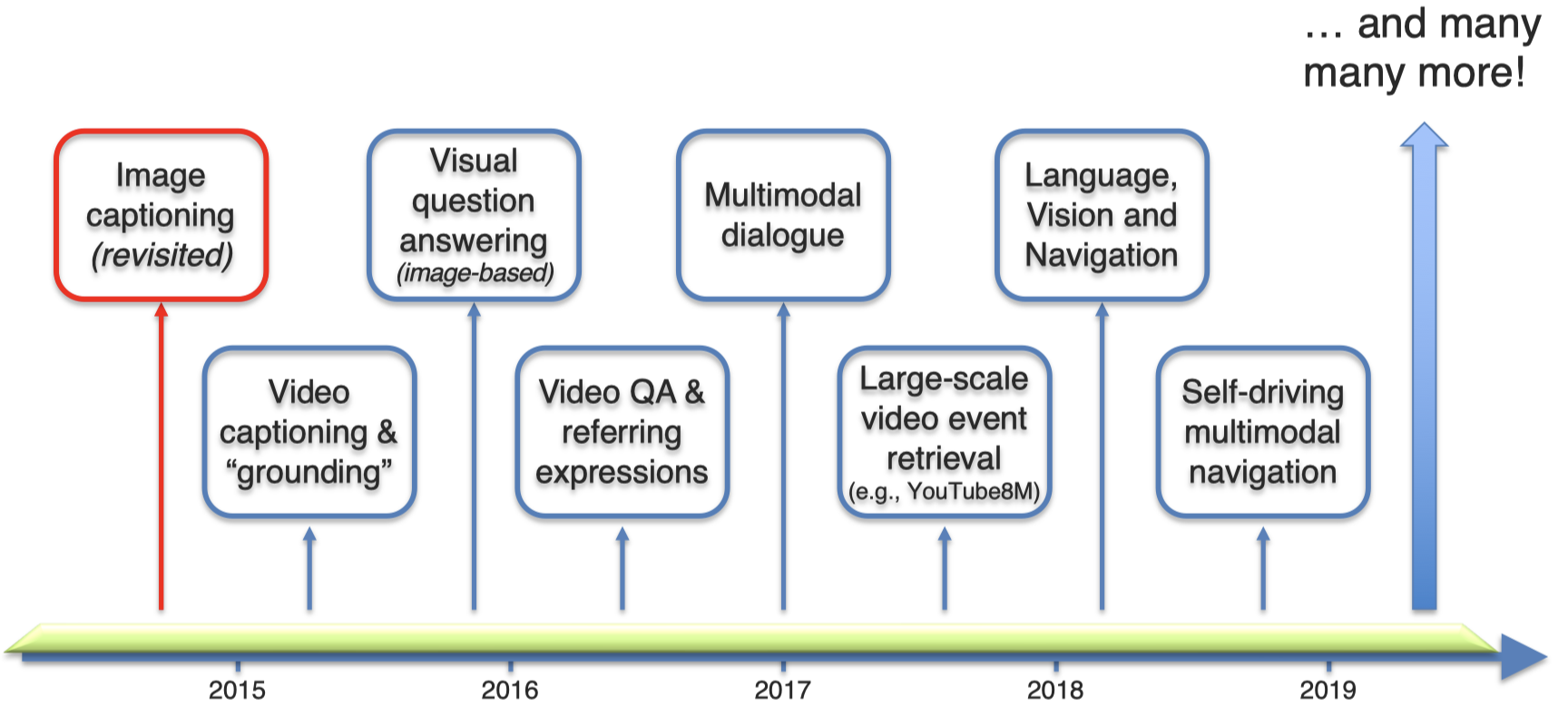
多模态机器学习
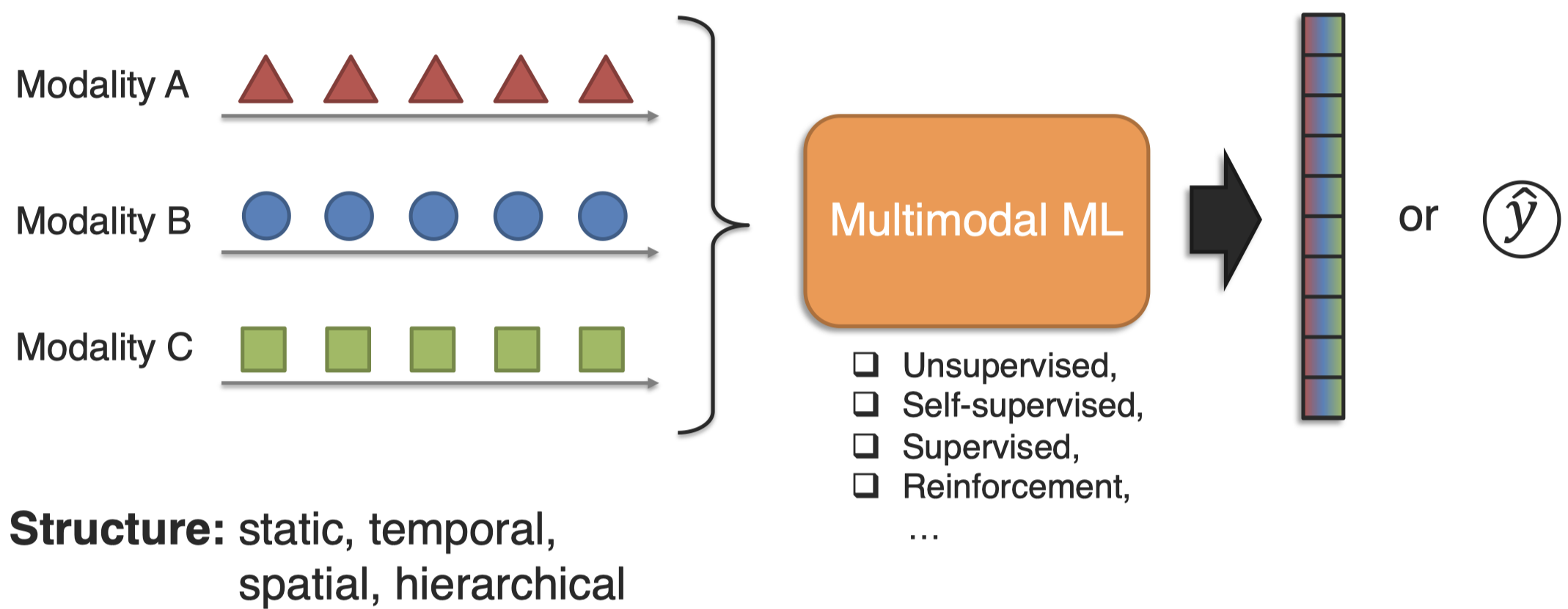
什么是多模态机器学习?
Multimodal Machine Learning (MML) is the study of computer algorithms that learn and improve through the use and experience of data from multiple modalities
什么是多模态人工智能?
Multimodal Artificial Intelligence (MAI) studies computer agents able to demonstrate intelligence capabilities such as understanding, reasoning and planning, through multimodal experiences, and data
Tutorial作者认为multimodal AI是multimodal ML的超集。
在multimodal问题中,需要面临解决的6个核心challenge。
- Representation
Learning representations that reflect cross-modal interactions between individual elements, across different modalities.
如何表示不同模态的信息,如何表示不同模态中的单个element?这个问题几乎是multimodal learning中最基本也最核心的问题。可能存在以下几种情况:
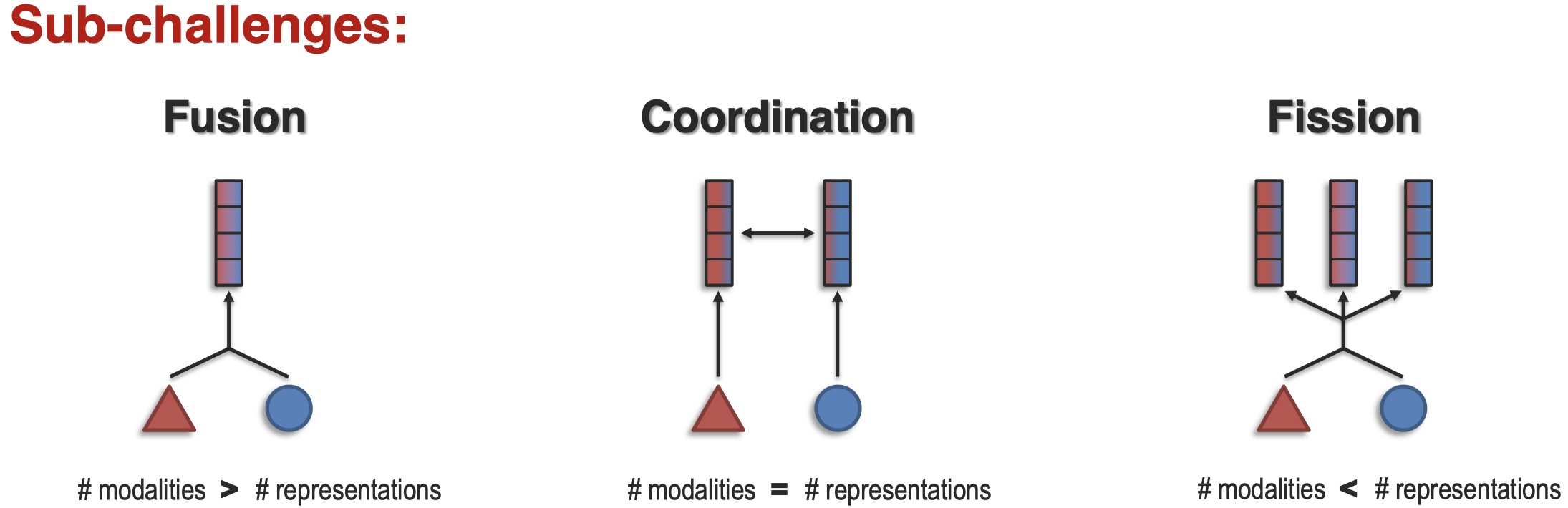
fusion表示原始的模态信息,之后被融合到一个representation space中;coordination指不同模态始终有独立的表示空间;fission表示先融合,之后分裂到不同的空间中;
- Alignment
Identifying and modeling cross-modal connections between all elements of multiple modalities, building from the data structure.
对于不同模态中的所有element,如何发现它们之间存在的联系,并且利用这样的关联?
模态内部很可能存在内部的结构,不同模态元素之间也可能存在显式的连接,同时,利用representation,也可能找到潜在的关联。

- Reasoning
Combining knowledge, usually through multiple inferential steps, exploiting multimodal alignment and problem structure.
如何结合knowledge,进行推理?
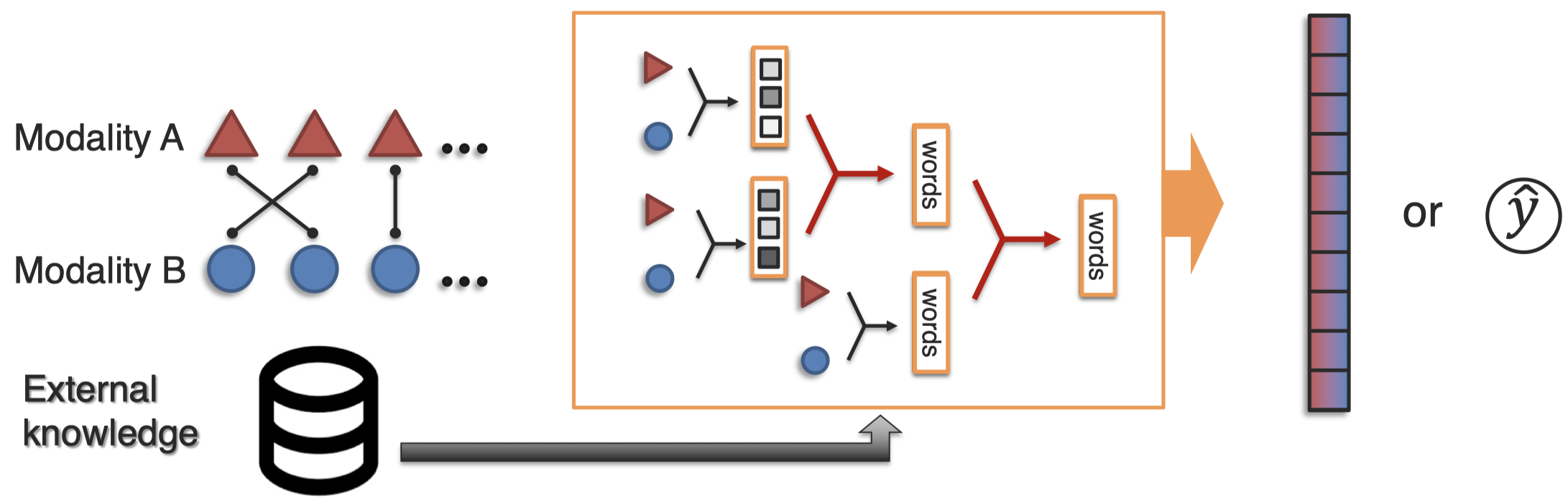
几个sub-challenge:
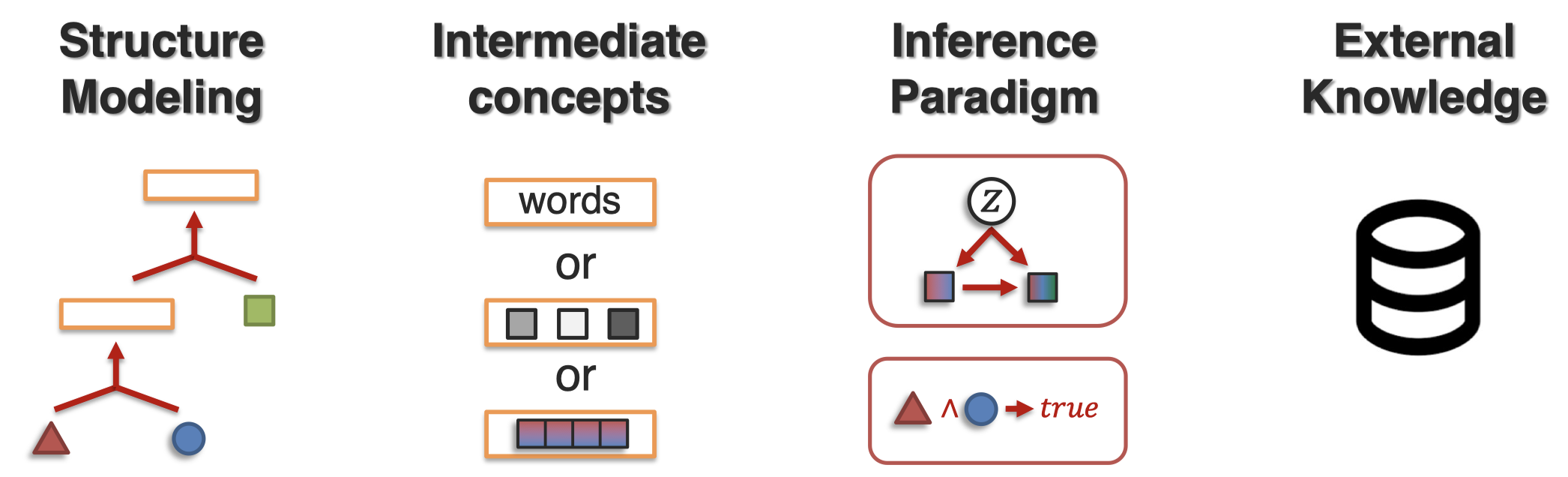
如何从结构上融合knowledge?如何定义或者使用中间概念?如何设计推理模式?如何利用外部knowledge(例如commonsense knowledge)进行推理?
- Generation
Learning a generative process to produce raw modalities that reflects cross-modal interactions, structure and coherence.
generation可能存在几个不同的challenge:
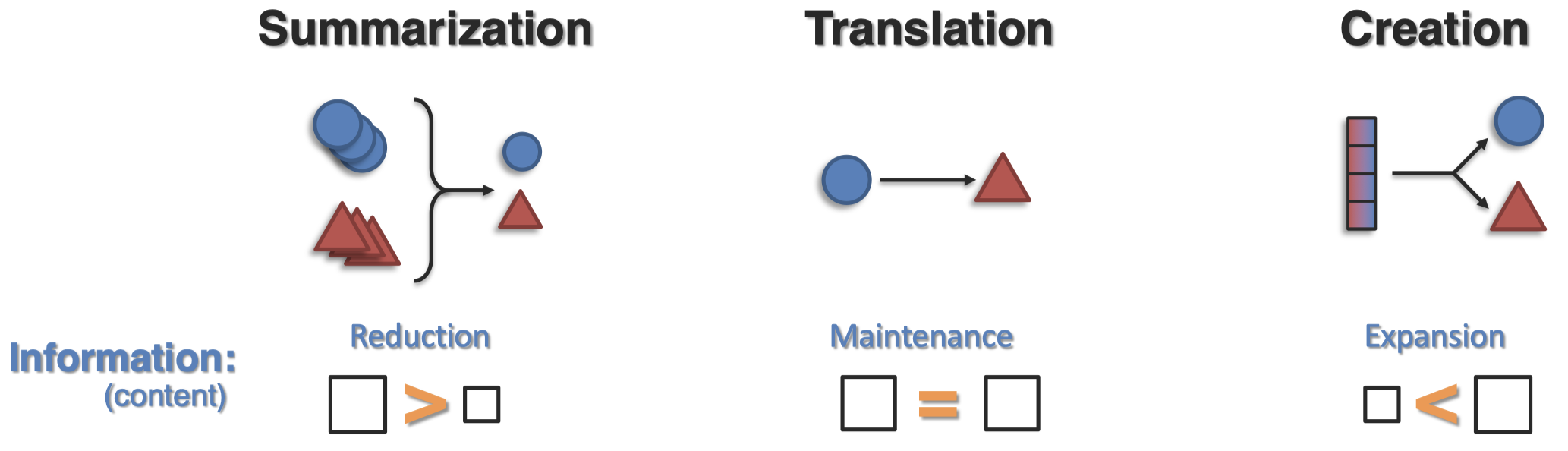
summarization期望进行信息缩减;translation期望信息不丢失;creation可能是最难的,它期望获得信息的拓展,能够应用到新的模态中。
- Transference
Transfer knowledge between modalities, usually to help the target modality which may be noisy or with limited resources.
对于目标modality,如何利用来自其它模态的信息?来自其它模态的信息可能是有限的,也可能是noisy的。
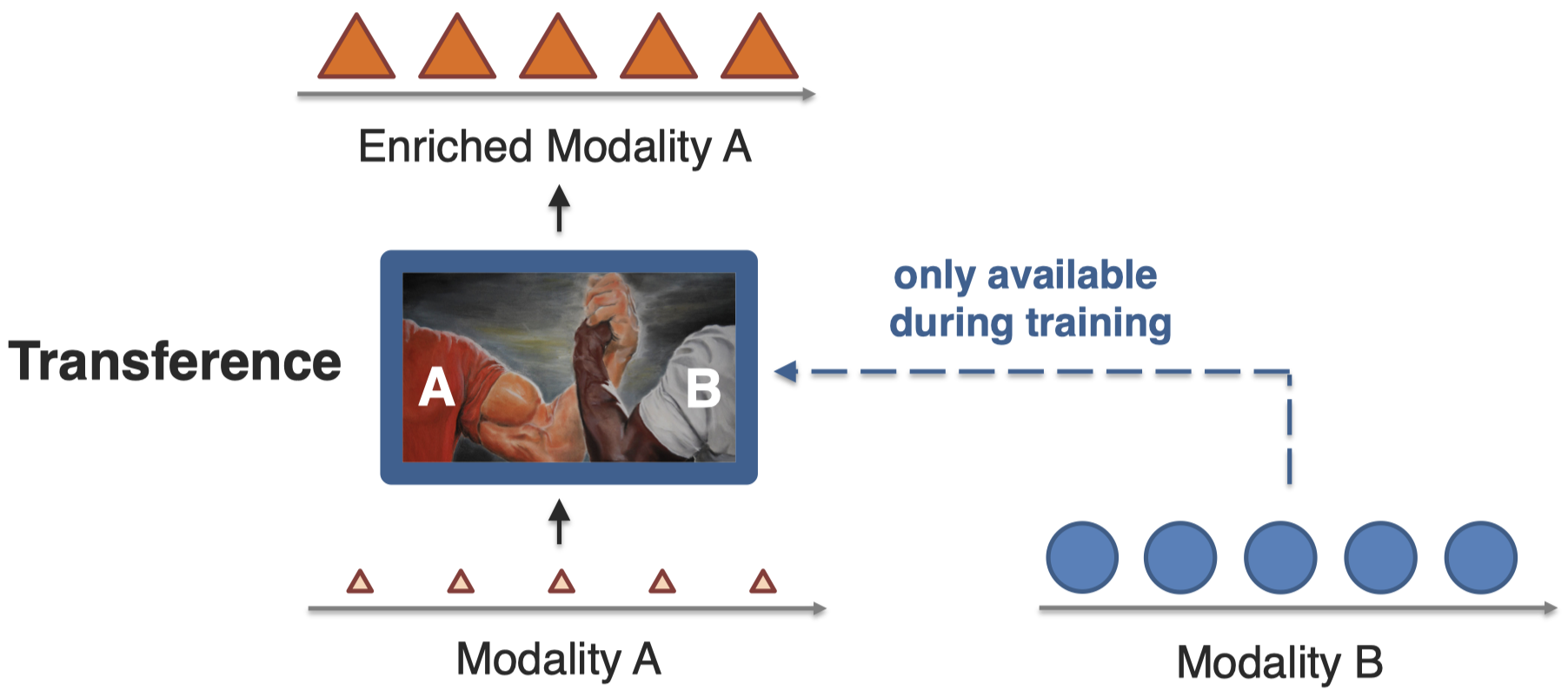
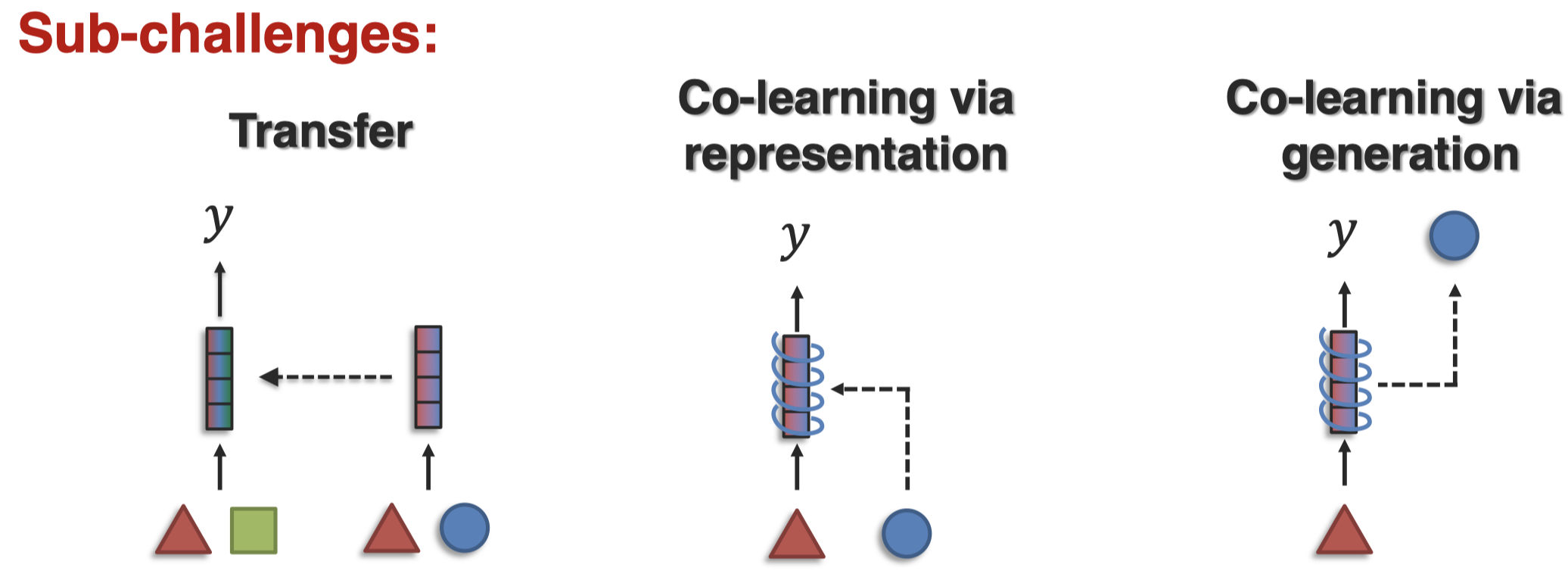
transfer指不同的模型学习不同模态,如何把不同模态的信息迁移到目标模态;co-learning是指使用同一个模型同时处理不同模态;
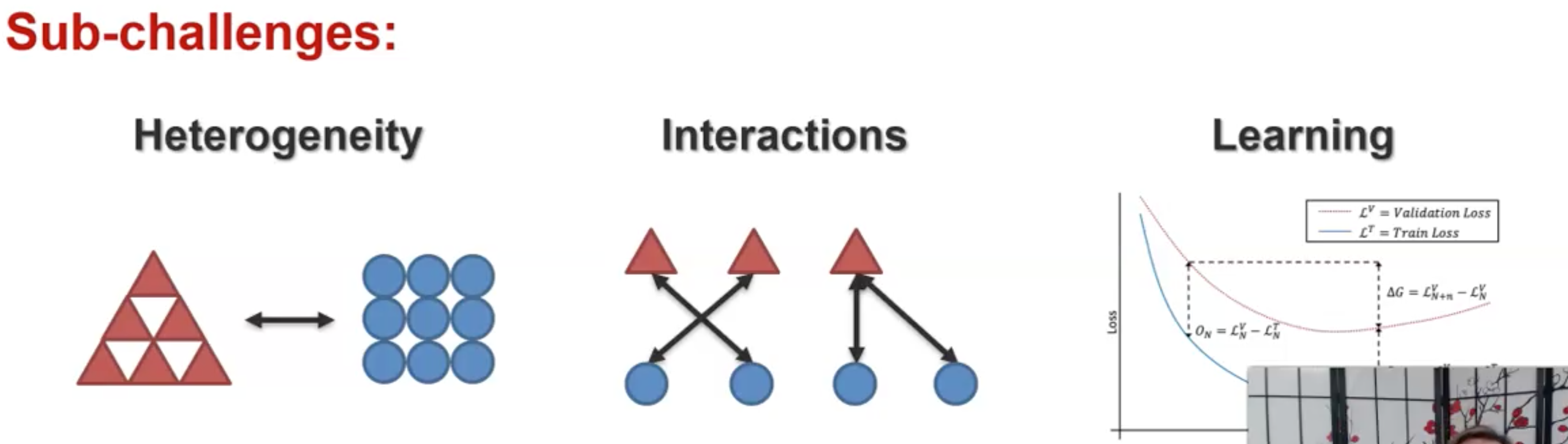
- Quantification
Empirical and theoretical study to better understand heterogeneity, cross-modal interactions and the multimodal learning process.
对多模态学习进行理论上的分析。如何理解heterogeneity?如何理解interaction?以及如何理解multimodal learning的过程?
以上的六个core challenge实际是关联在一起的。
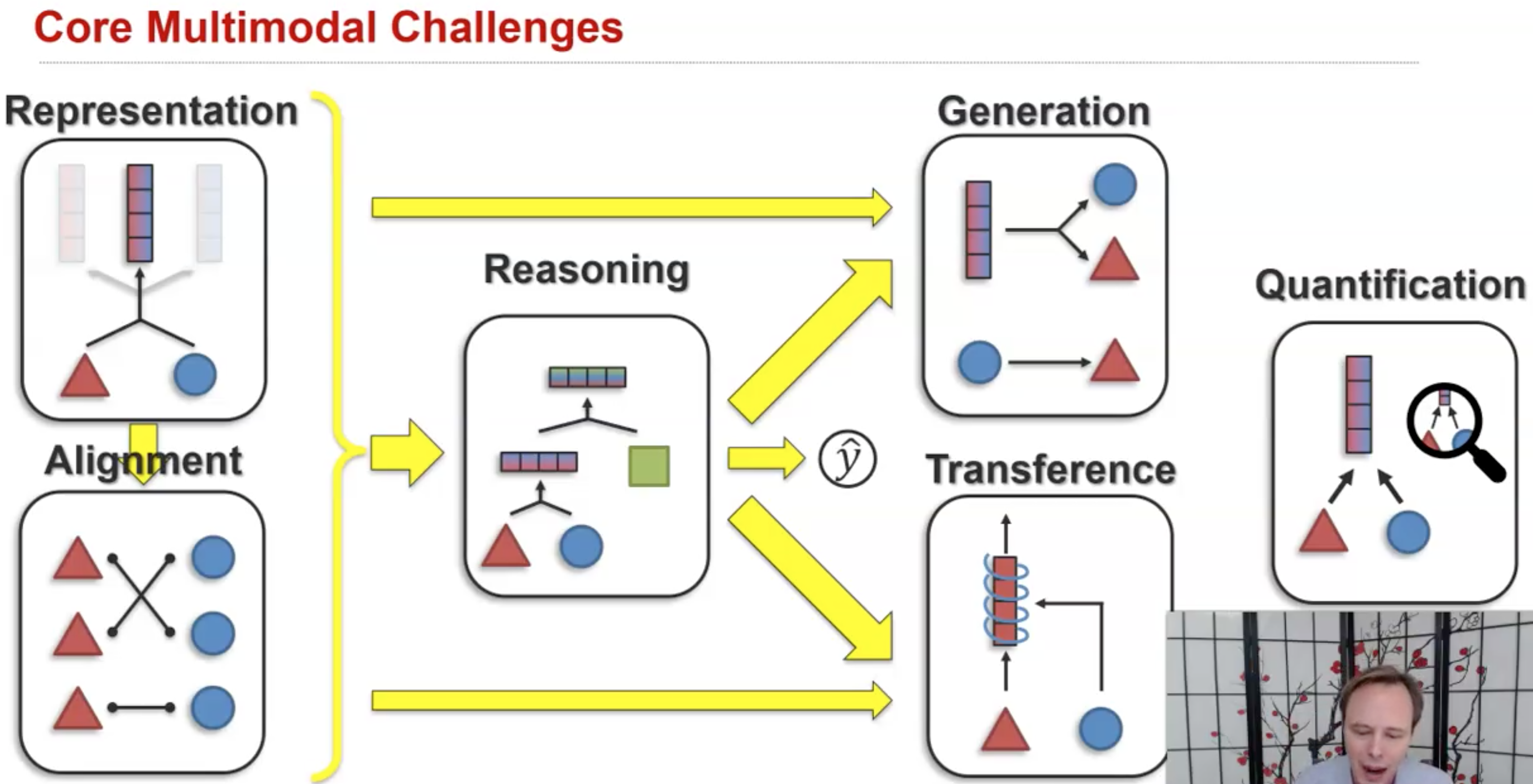
首先,我们需要考虑如何表示不同模态的信息,是分别在独立的空间中进行学习,还是在联合空间下进行学习;其次,我们需要考虑如何发现多模态元素的关联;在前两步基础上,我们才可以进行目标推理,如何设计合理的结构,处理heterogeneity和interaction,对预测目标采用合理的步骤进行推理;同样的,我们可以进行模态生成,完成模态转换、summarization等任务;我们还可以进行模态的迁移,让其它模态辅助、增强目标模态的预测,它和模态生成的区别是,模态生成的输入不包括要预测的模态;最后,我们需要理论上对multimodal learning的支撑。