KGAT
KGAT: Knowledge Graph Attention Network for Recommendation
在结合了知识图谱之后,就形成了一个关系更加丰富的graph neural network,使用GNN的方法来进行最后的预测。这篇论文就是在结合了知识图谱的基础上使用作者之前(2019)发表的neural graph collaborative filtering(ngcf)算法。理解了ngcf这篇论文就很好理解。
1. 现在结合知识图谱的推荐存在的问题
1.1 知识图谱出现解决的问题
推荐算法中的协同过滤考虑的根据某个用户的历史数据,寻找可能兴趣相投的群体,来推荐物品。比如在下图中,要给用户推荐物品,那么但从交互的物品来看,都与有交互,那么就可以认为是兴趣相投的用户,根据他们的历史数据来给推荐物品。但如果表示某部电影,的导演也是这部电影的演员,与之间是存在属性上的联系的,这种联系是单纯协同过滤无法解决的。
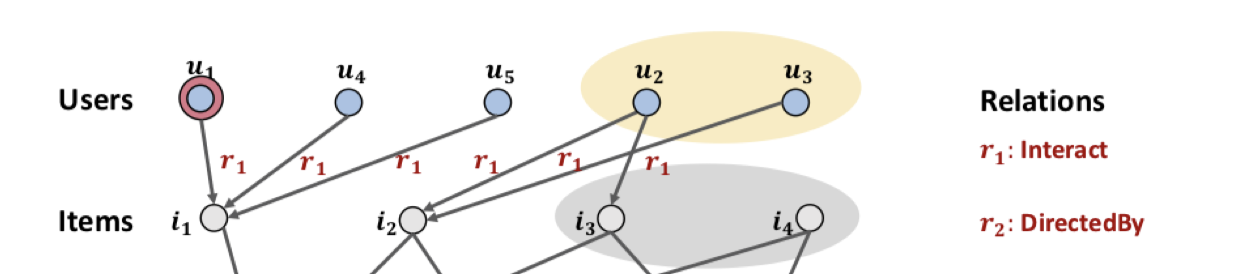
为了解决这个问题,加入知识图谱(knowledge graph),形成了下面的结构。
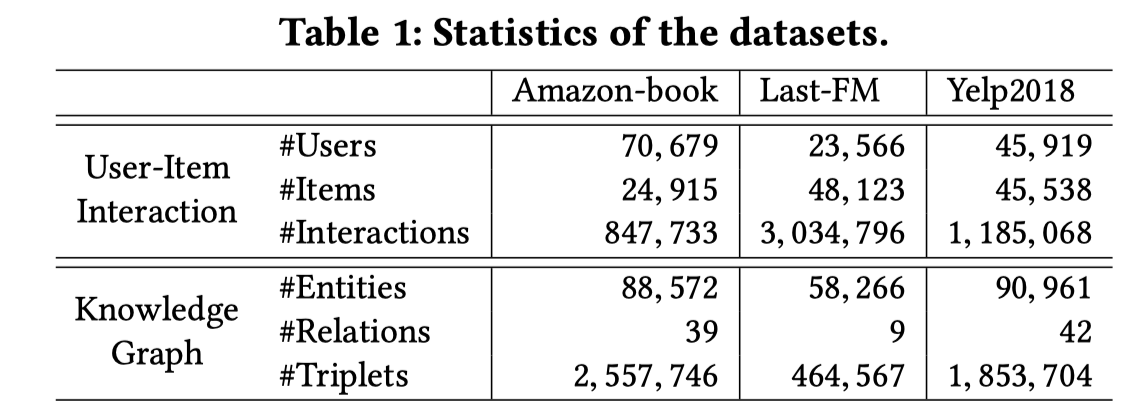
在这样的图中,与就关联起来了。同样给推荐物品,就能够找到更多的相似用户来进行推荐。
考虑之前的用户和物品交互矩阵,矩阵当中只存在一种关系,就是用户和物品的交互,并且物品和物品之间是没有直接交互的,如果结合了知识图谱,物品和物品之间就出现了直接的关系,增加了新的实体,矩阵中的关系也就由一个变为了多个。
在这样的条件下,就可以继续利用GNN来进行propagation。
1.2 使用GNN的思路
在结合了知识图谱之后,就形成了一个关系更加丰富的graph neural network,使用GNN的方法来进行最后的预测。这篇论文就是在结合了知识图谱的基础上使用作者之前(2019)发表的neural graph collaborative filtering(ngcf)算法。理解了ngcf这篇论文就很好理解。
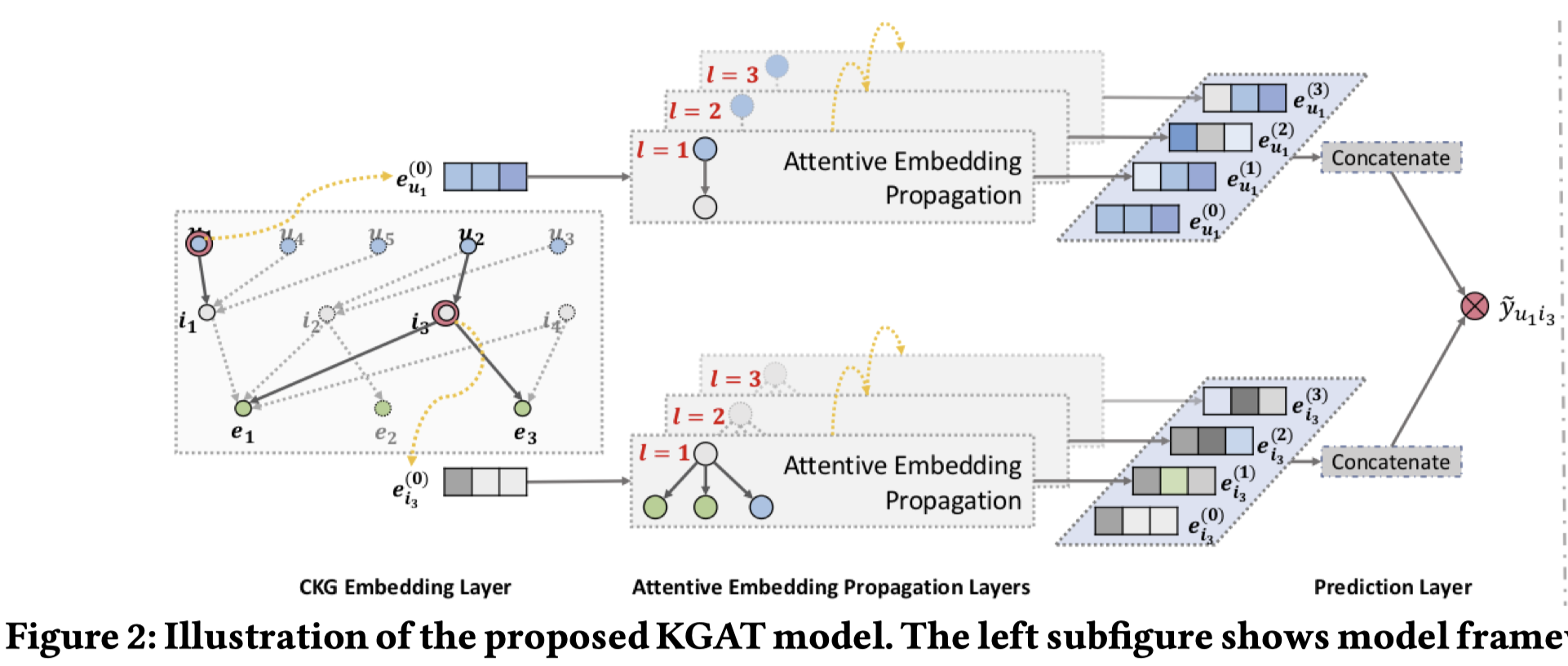
2 模型结构
主要包括三层:
- Embedding layer
- Attentive embedding propaggation layer
- Prediction layer
2.1 Embedding layer
对于用户-物品可以表示为, \[ G_1 = \{(u, y_{ui}, i)|u\in U, i\in I, y_{ui}=1\} \] 知识图谱使用下面的三元组来表示, \[ G_2 = \{(h, r, t)|h,t\in \epsilon , r\in R\} \] 这样整个结构也就都成为了一个三元组, \[ G = \{(h, r, t)|h,t\in \epsilon^{'} , r\in R^{'}\} \] 在新的结构当中,由于每一个物品都对应到了知识图谱中的实体。所以现在的矩阵变为了\(N用户\times\ M^{'}实体\)。
在embeding layer这一层,存在一个loss,知识图谱embeding表示的loss。论文里使用了TransR,来获得知识图谱的embeding。
TransR的原理是实体使用d维embeding,关系表示使用k为embeding,一个连接\(<h, r, t>\)在数学上的含义可以是h投影到关系r的k维空间上,加上r的k维表示,得到t的k维投影: \[ W_re_h+e_r\approx W_re_t,\\ e_h, e_t\in R^d, e_r\in R^k, W_r\in R^{k\times d} \] \(W_r\)是关系r的转换矩阵。这个等式两边越接近越好,这样可以定义一个相似性得分的函数: \[ g(h,r,t)={\lVert W_re_h+e_r-W_re_t \rVert}^2_2 \] 在整个的矩阵上,对于有关系的\(<h, t>\)score越小越好,对于没有关系的\(<h, t^{'}>\)score越大越好。
因此可以得到一个损失函数: \[ L_{KG}=\sum_{(h,r,t,t^{'})}{-ln\sigma (g(h,r,t^{'})-g(h,r,t)) } \] 在论文的代码实现当中,对于每一个head,取了1个positive,1个negative来计算loss。
2.2 Attentive Embeding Propagation Layers
实质是在ngcf上加上了attention机制。
对于一个实体\(h\),对于和 \(h\) 有关系 \(r\) 的集合 \(N_h=\{ (h,r,t)|(h,r,t)\in G \}\) 使用propagation: \[ e_{N_h}=\sum_{(h,r,t)\in N_h} \pi (h,r,t)e_t \] Attention: \[ \pi (h,r,t)=(W_re_t)^Ttanh(W_re_h+e_r) \\ \pi (h,r,t)=\frac{exp(\pi (h,r,t))}{\sum_{(h,r^{'},t^{'})\in N_h} \pi (h,r,t)e_t} \] 理解:
\(W_re_t\)是实体\(e_t\)在关系\(r\)空间内的投影,\(W_re_h+e_r\)是\(e_h\)投影到关系\(r\)的k维空间上,加上r的k维表示。如果这两个embeding点积越大,表示这两个向量越相似,对应的权重应该更大。
之后的propagation和aggregation具体方式参考ngcf。
2.3 训练方式
具体的,在训练之前,因为加入知识图谱相当于增加了新的物品,增加了大量的待训练参数,为了加快训练过程,首先利用BPR-MF的方式预训练好用户、物品的embeding,之后再进行kgat的训练。
在训练的时候,在一个epoch里,
- 分batch(1024)训练完embeding propagation,更新所有实体的embeding
- 分batch‘(2048)训练TransR,更新关系的转换矩阵
- 更新attentive embeding
3 Experiments
研究问题:
- KGAT和其它模型的比较
- KGAT不同模型设置对结果的影响
- KGAT对于用户偏好解释性的影响
可以发现,这三个问题与NGCF中探究的问题一致。
数据集:
可以发现,如果加入知识图谱,物品的数量就会极大的增加,这也是为什么建议预训练好用户和物品的embeding。
评估指标: \[ recall@K,\ ndcg@K,\ K=20 \] 超参数设置:
- embeding size:64
- batch size:1024
- early stopping
- KGAT layer size:[64, 32, 16]
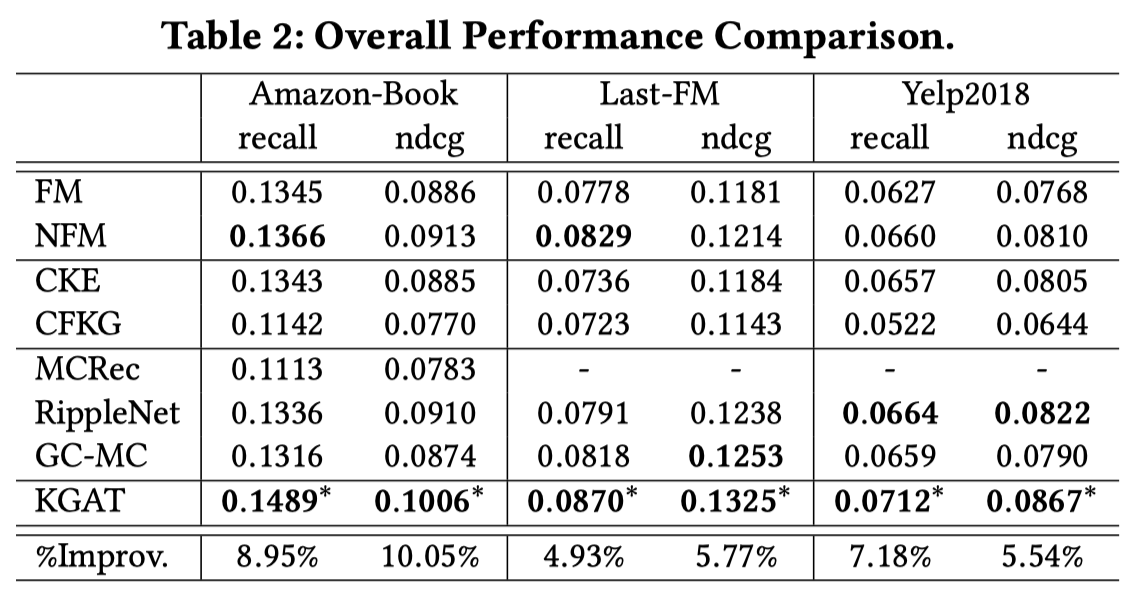
比较结果:
效果比较:
不同模型结构设置的影响:

对于用户偏好的解释:

从这张图上可以看出来通过加入知识图谱,获得了更多的额外信息。
4 总结
加入知识图谱导致了更加丰富的物品信息
缺点:
在知识图谱中,存在一些常见的属性,例如图4中的English,这些属性有很多物品都具备,但是在attention的计算中,attention的计算仅在当前用户的交互实体下进行,没有考虑全局的情况。