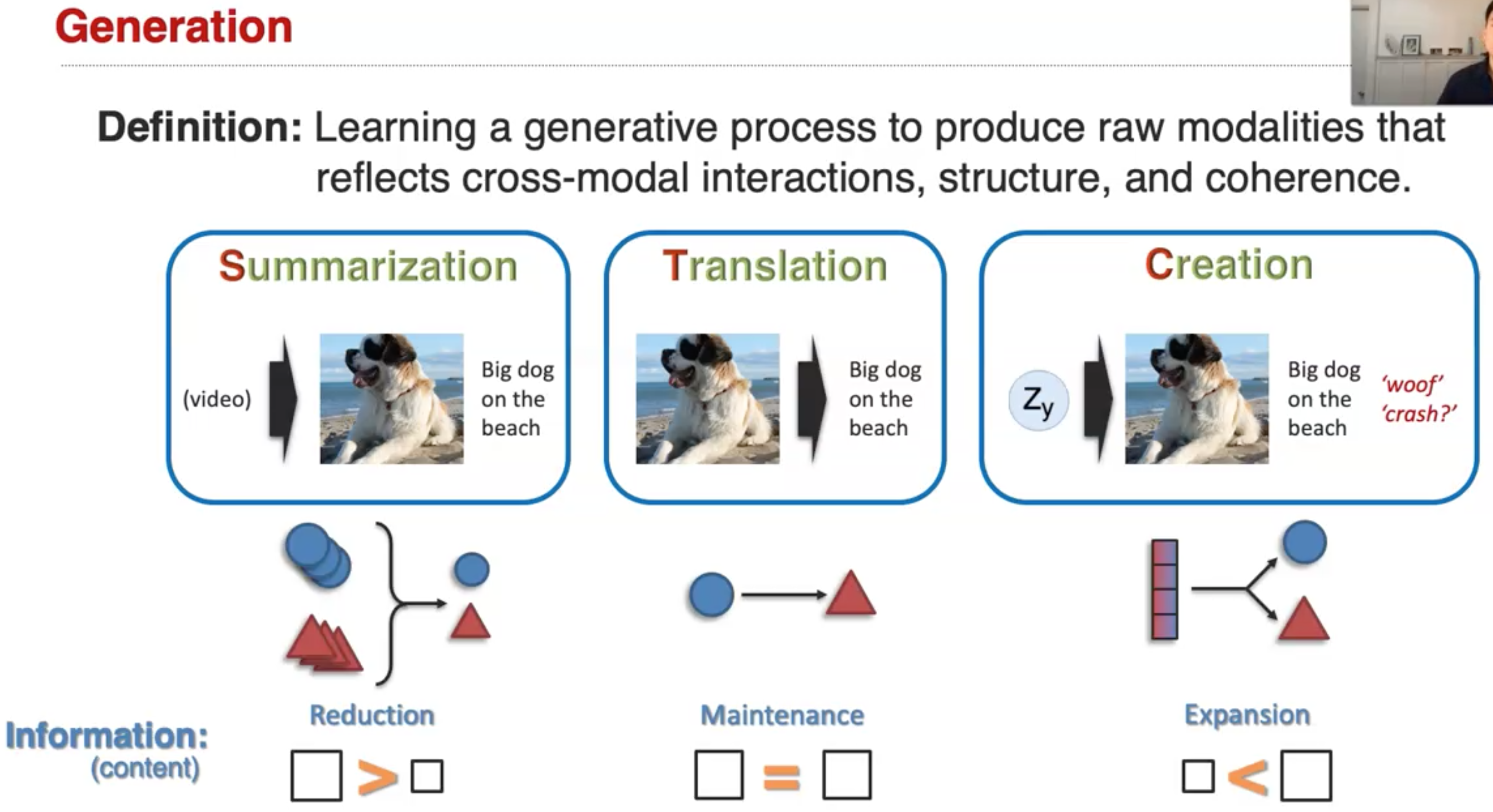
IKRL
Image-embodied Knowledge Representation Learning
清华大学2017年发表在IJCAI上的paper,IKRL,应该是第一个把图像信息注入到KGE中的方法。
基于TransE的思想,为不同的entity学习一个额外的image embedding,然后image embedding和原来的entity embedding通过\(h+r\approx t\)评估三元组是否成立。
Entity images could provide significant visual information for knowledge representation learning. Most conventional methods learn knowledge representations merely from structured triples, ignoring rich visual information extracted from entity images. In this paper, we propose a novel Imageembodied Knowledge Representation Learning model (IKRL), where knowledge representations are learned with both triple facts and images. More specifically, we first construct representations for all images of an entity with a neural image encoder. These image representations are then integrated into an aggregated image-based representation via an attention-based method. We evaluate our IKRL models on knowledge graph completion and triple classification. Experimental results demonstrate that our models outperform all baselines on both tasks, which indicates the significance of visual information for knowledge representations and the capability of our models in learning knowledge representations with images.