when-how-paraphrase-NER
When and how to paraphrase for named entity recognition?
ACL 2023
While paraphrasing is a promising approach for data augmentation in classification tasks, its effect on named entity recognition (NER) is not investigated systematically due to the difficulty of span-level label preservation. In this paper, we utilize simple strategies to annotate entity spans in generations and compare established and novel methods of paraphrasing in NLP such as back translation, specialized encoder-decoder models such as Pegasus, and GPT-3 variants for their effectiveness in improving downstream performance for NER across different levels of gold annotations and paraphrasing strength on 5 datasets. We thoroughly explore the influence of paraphrasers, dynamics between paraphrasing strength and gold dataset size on the NER performance with visualizations and statistical testing. We find that the choice of the paraphraser greatly impacts NER performance, with one of the larger GPT-3 variants exceedingly capable of generating high quality paraphrases, yielding statistically significant improvements in NER performance with increasing paraphrasing strength, while other paraphrasers show more mixed results. Additionally, inline auto annotations generated by larger GPT-3 are strictly better than heuristic based annotations. We also find diminishing benefits of paraphrasing as gold annotations increase for most datasets. Furthermore, while most paraphrasers promote entity memorization in NER, the proposed GPT-3 configuration performs most favorably among the compared paraphrasers when tested on unseen entities, with memorization reducing further with paraphrasing strength. Finally, we explore mention replacement using GPT-3, which provides additional benefits over base paraphrasing for specific datasets.
系统的分析了不同设置,不同的模型,用改写sentence的方式来做NER任务的data augmentation。
Datasets and Paraphrasers
作者选择了5个不同领域的NER数据集。
作者先对比两个已有的Paraphrasers工具:
- 基于Back-translation(BT):For our experiments we use pre-trained English-German and German-English models (∼738M parameters) available from Huggingface model hub via Tiedemann and Thottingal (2020) and the model architecture used is BART (Lewis et al., 2019).
- 基于PEGASUS:We use an off-the-shelf version of PEGASUS fine-tuned for paraphrasing released on Huggingface model hub. 3
然后,作者利用两个GPT-3模型:text-ada-001 (∼350M parameters), and text-davinci-002 (∼175B parameters)。使用的temperature为0.8。
采用了两种prompt,一种是没有指定保留entity label的;一种是指定改写后的句子要保留entity mention和label的:
Prompt A:


Prompt B:

对于改写后的句子,需要经过处理。首先是使用原来的entity mention进行case insensitive exact match标注entity span label。然后要过滤掉一些明显错误的句子:
- remove paraphrases for gold sentences shorter than 15 characters
- remove paraphrases that are a duplicate of the gold sentence or of another paraphrase
- remove paraphrases that generation contains an entity not present in entity space of the dataset
对于不同改写方法的能力,除了可以用训练实验性能来评估外,作者还从两个方面进行评估:
- entity preservation:有多少原来句子中的entity mention会准确的出现在改写后的句子里?自动计算entity recall
- paraphrase quality:人工给改写后的句子质量打分,既要多样性,又要preserving the meaning faithfully 保持原来句子的语义
评估结果:
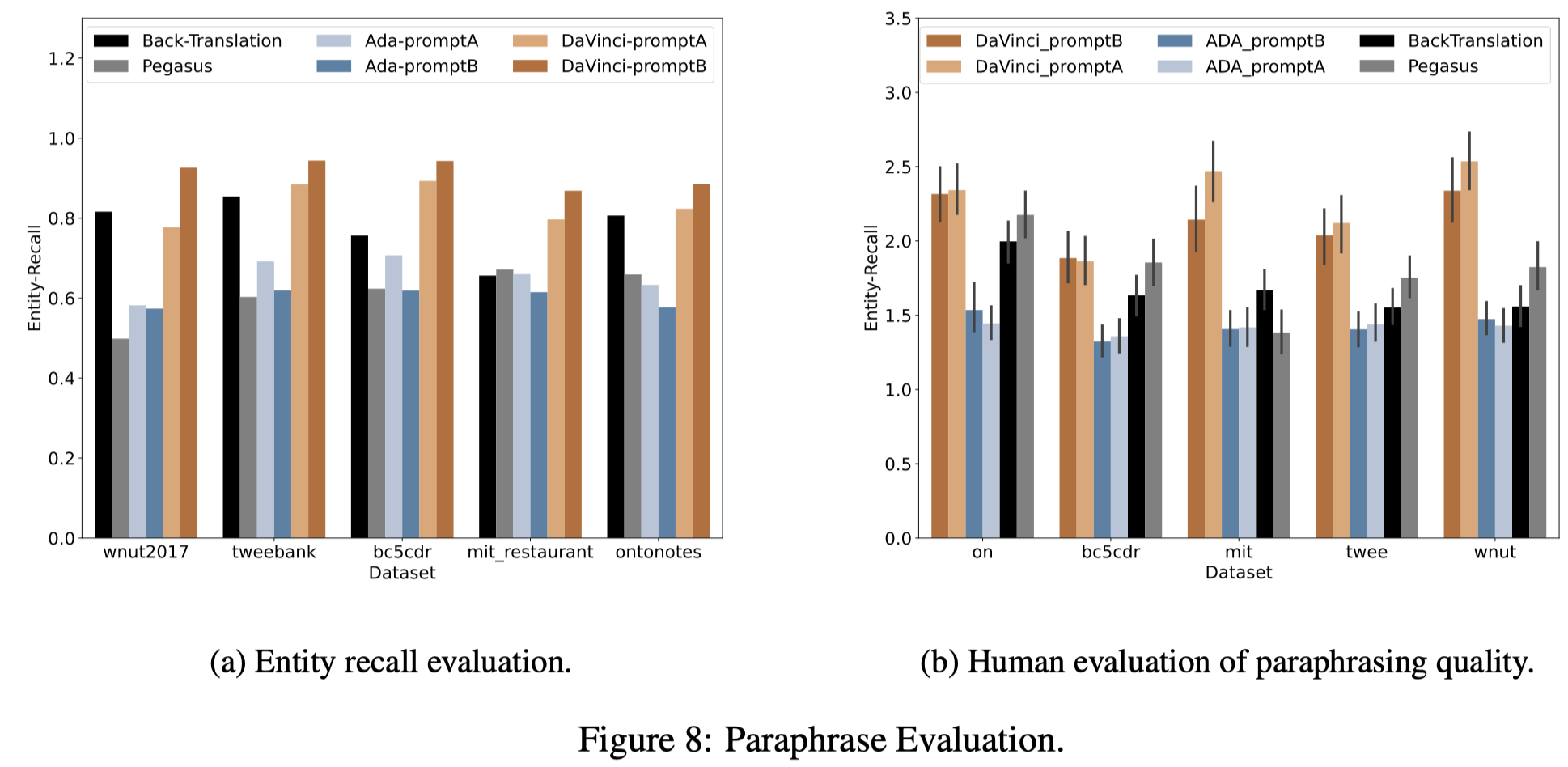
综合来看,基于GPT-3的改写能力是最好的。
Experiments
Using gold & paraphrasing data for training NER
Experimental setup
同时使用原有的gold data和改写后的data进行训练。下面是一些基础的实验设置:
- the corresponding dataset is used to fine-tune a distilbert-base-cased base (66M parameters) model (Sanh et al., 2019)
- 作者详细对比了两种不同的data占比:
- gold ratio (G-ratio) what percentage of gold data is used in a particular configuration 是指gold samples占全部training set的比例,\(G=0.01\)表示使用\(1\)%的原有所有训练样本作为gold data。
- paraphrase ratio (P-ratio) what is the ratio of number of paraphrases compared to number of gold samples 是指gold samples的倍数,\(P=0.25\)表示改写的数据是gold data的\(1/4\),\(P=0.0\)代表不经过改写。
然后,为了调查训练好的NER模型的性能的变化受哪些因素影响。作者使用一些简单的统计特征,基于线性回归分析这些特征是否会导致NER F1指标的变化:
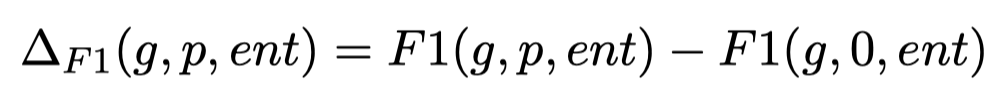
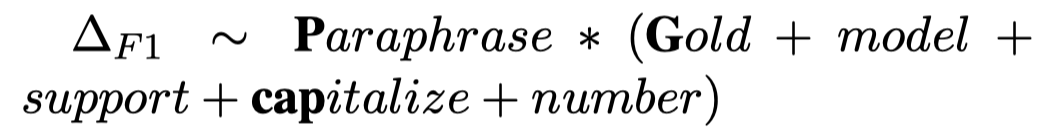
Results
先来看不同改写方法的效果。下面图中:
- 一个方格表示一种改写方法
- 方格里的数值score的计算:如果某个方法在1个数据集上通过改写数据增强方法获得了效果提升,那么\(score+1\)。如果效果下降,\(score-1\)。一共有5个实验dataset,所以最低是\(-5\),最高是\(+5\)。
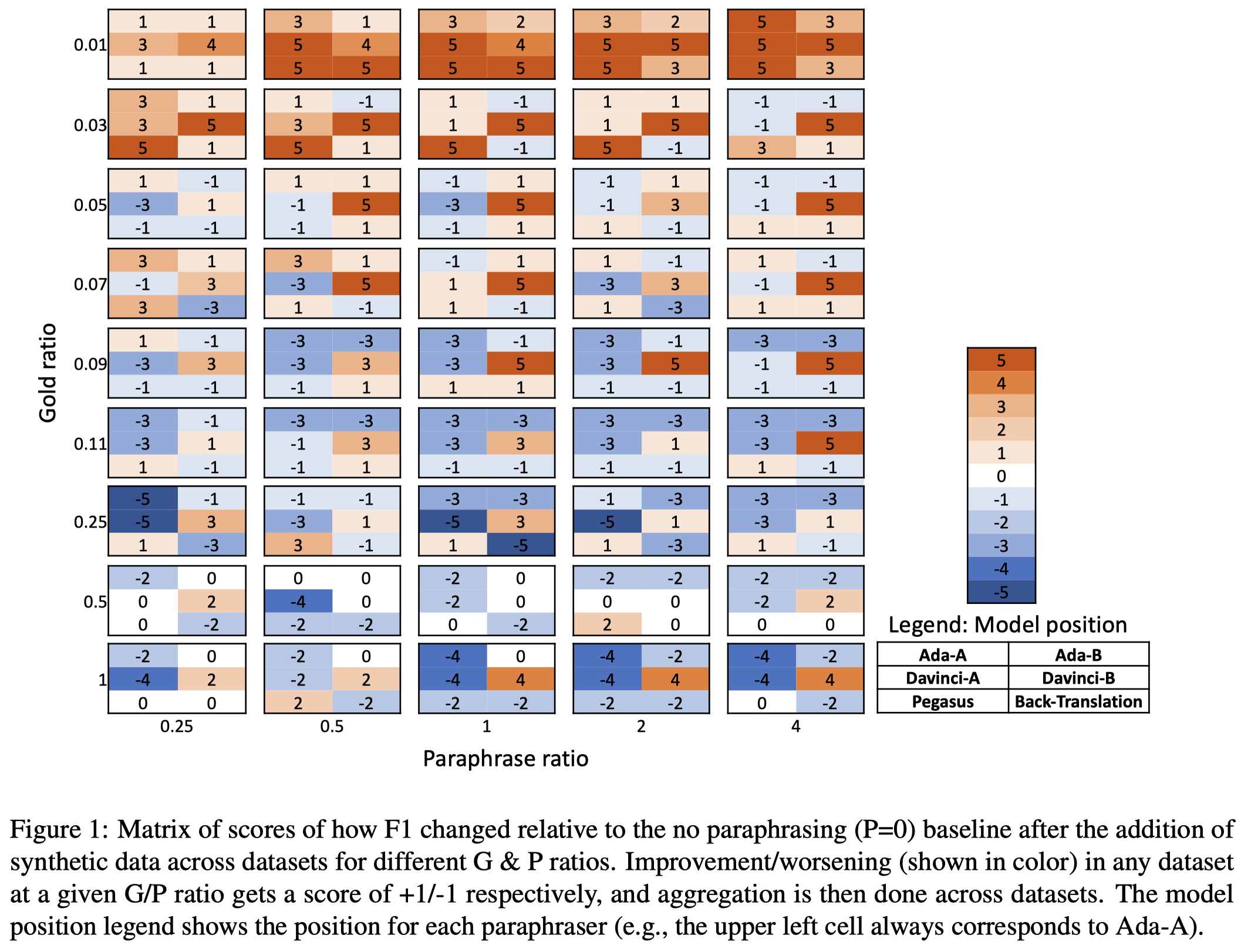
观察:
- GPT-3 DaV-B consistently outperforms, or matches other paraphrasers and is a safe default choice for paraphrasing across domains. GPT-3总是有效果的,可以考虑总是使用GPT-3来改写句子
- 数据增强在low-resource的情况下比较有效;当NER gold data逐渐增加的情况下,数据增强的效果逐渐减小
线性回归分析的结果:
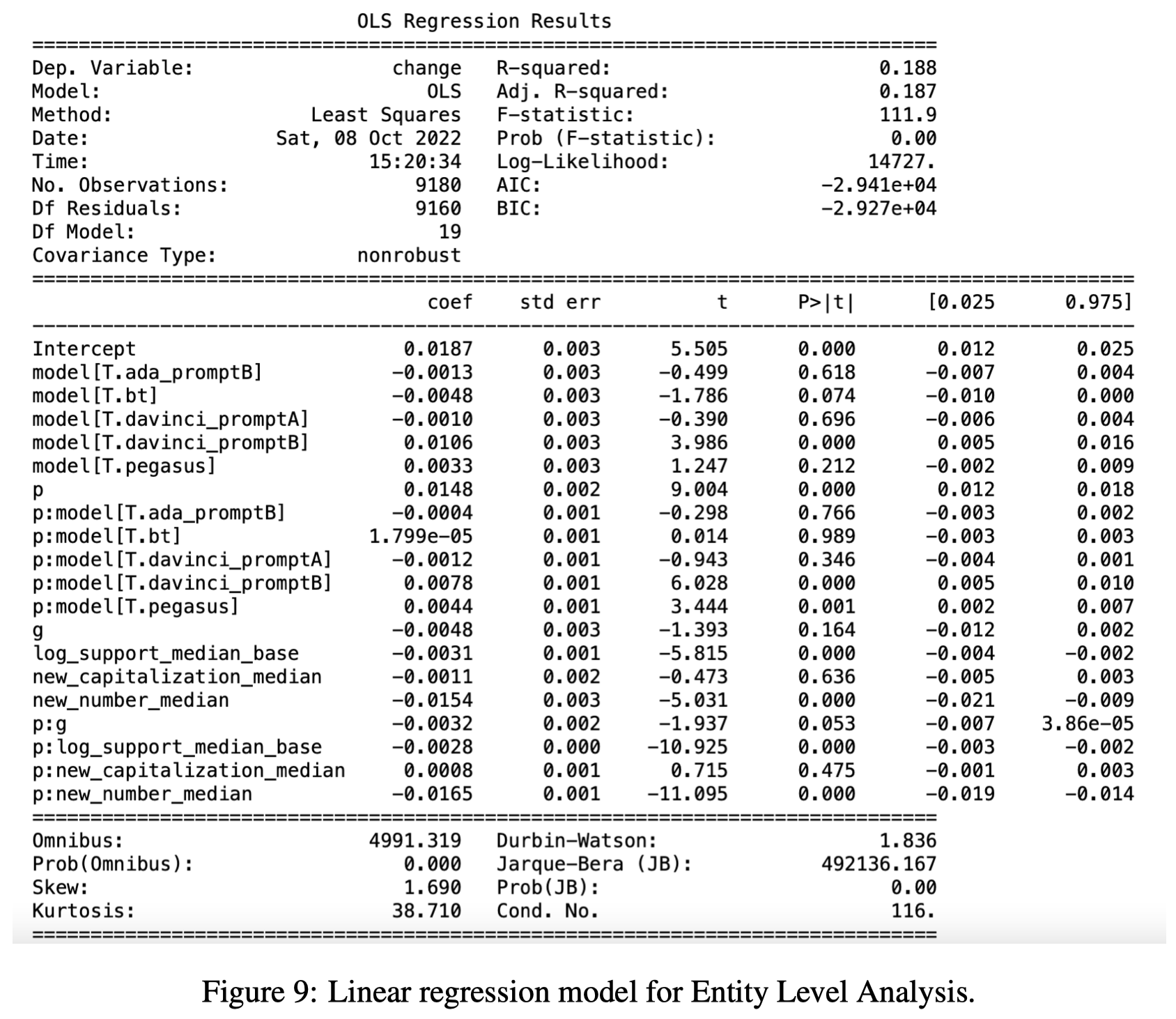
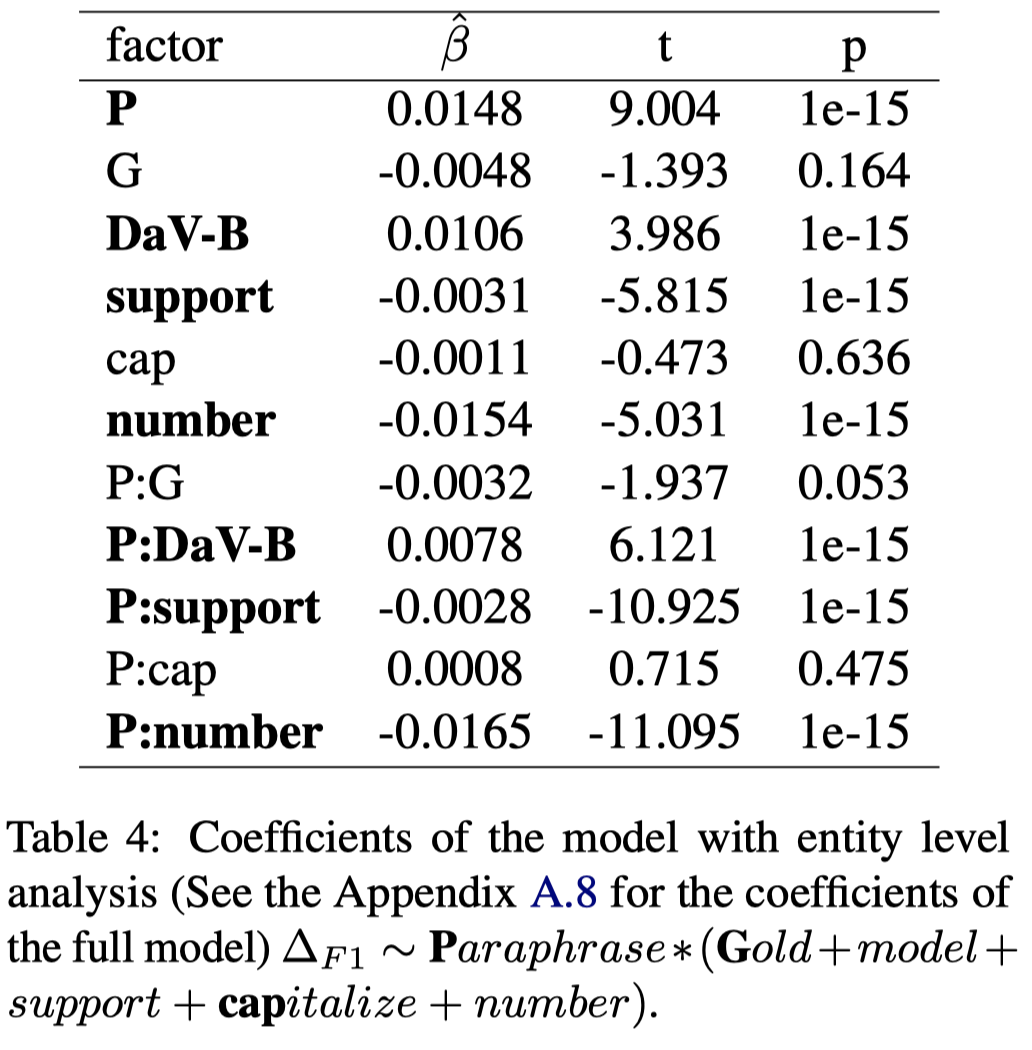
观察:
- Table 4中\(P\)表示gold rate,而\(P\)的影响系数\(\hat{\beta}=0.0148>0\),\(P\)和生成数据的比值\(G\)的交互变量\(P:G\)的影响系数\(\hat{\beta}=-0.0032<0\)。这说明更多的改写后生成的data能够有效的提升模型效果。但是当有更多gold data的时候,这种提升的趋势有一定程度的减弱;
- 有更少样例的entity class更容易从基于改写的数据增强策略中收益;
- 越长的entity mention有可能越难被预测,改写数据增强带来的提升越小;
- 大小写这种surface level的feature,对最终效果的变化没有特别大的影响;
Using only paraphrases for training NER
完全使用生成的数据来训练一个NER模型来评估生成数据的质量。
使用原来的测试集进行测试,测试结果发现还是GPT-3效果最好:
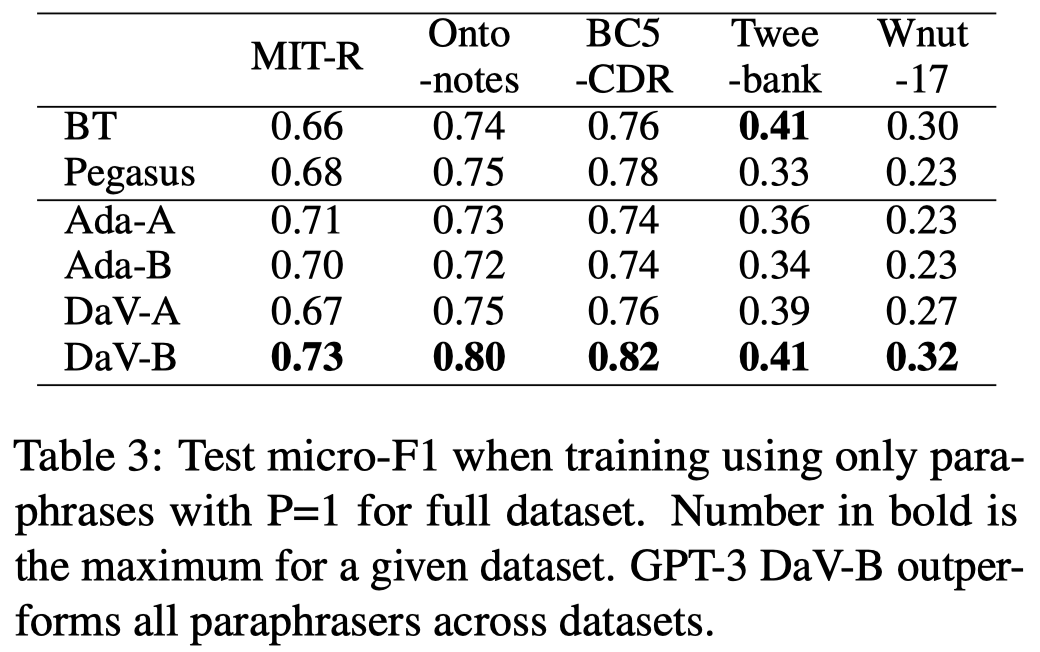
Entity Memorization
作者关注数据增强可能带来的一个问题Entity Memorization。即目前基于改写的数据增强方法,没有改变entity mention,生成的data中出现了entity的重复。因此作者想检查模型是不是直接记住了entity和它对应的label,而不是学会从feature推测label。
如果是记忆,那么model意味着模型走了捷径shortcut learning [Shortcut learning in deep neural networks. Nature 2020],那么此时model应该无法准确处理没有见过的entity。
因此,作者又进行了在test set中,不同entity type里,没有在训练集里出现过的entity作为新的测试集unseen entity (UE) test sets。
作者认为,如果entity memorization现象加重了,那么在UE测试集里,model的指标F1会出现下降:
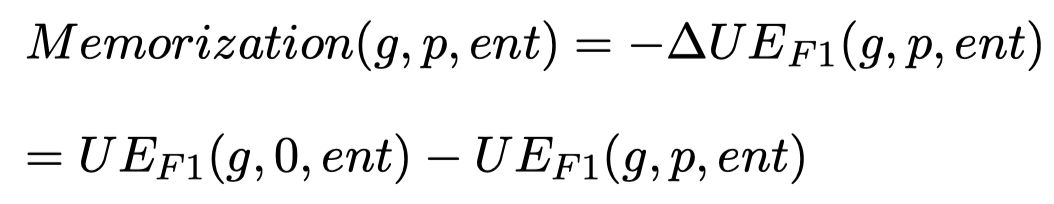
和前面类似,作者同样基于线性回归分析对这一现象出现的原因进行了调研。
Results

观察:
GPT-3 Davichi相对来说能够缓解模型Entity Memorization问题
对于有很多样例的entity class,改写可能加重了对相应entity的记忆
带有数字的entity似乎更加容易被model记住
为了缓解entity memorization问题,作者提出了一种解决方法Mention replacement(MR)。那就是不要重复entity mention,用GPT生成新的entity mention,然后去替换生成句子中的entity mention:
In particular, for every entity mention in the gold set, we prompt GPT-3 DaVinci model to generate entity mentions that are similar to the gold entity mention, while also providing a phrase level definition of the entity type being replaced.
使用到的prompt:


进行了entity mention后的效果:
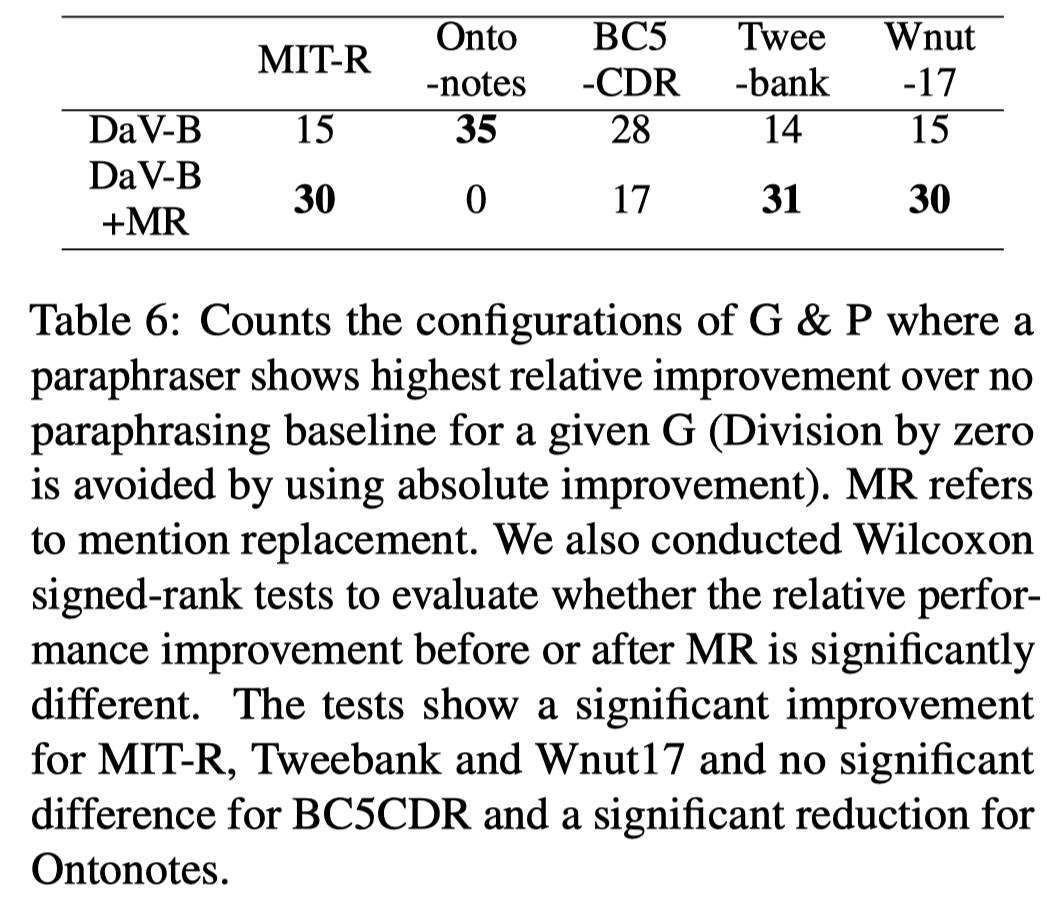
不是所有数据集上,直接替换entity mention都是有效果的。