Transformer
Attention Is All You Need
NIPS 2017
本文提出了一个新的简单的网络结构,Transformer,只依赖于注意力机制。
1 Introduction
RNN等模型已经取得了很大的成功,但是计算循环网络的代价通常会与输入输出序列的符号位置紧密相关。序列的符号位置决定了循环网络中输入的步数,导致很难并行化,就在时间和计算资源(内存)上限制了模型的训练。
注意力机制在sequence modeling 和 transduction models任务上已经取得了很大的成就,但是很少有模型会将注意力机制与RNN联系在一起。
本文就提出了一个新的方法Transformer,避免了循环,相反的是基于注意力机制完全依赖于输入和输出的整体。
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution.
2 Model Architecture
整个Transformer的结构是encoder和decoder的结构,如下图所示。
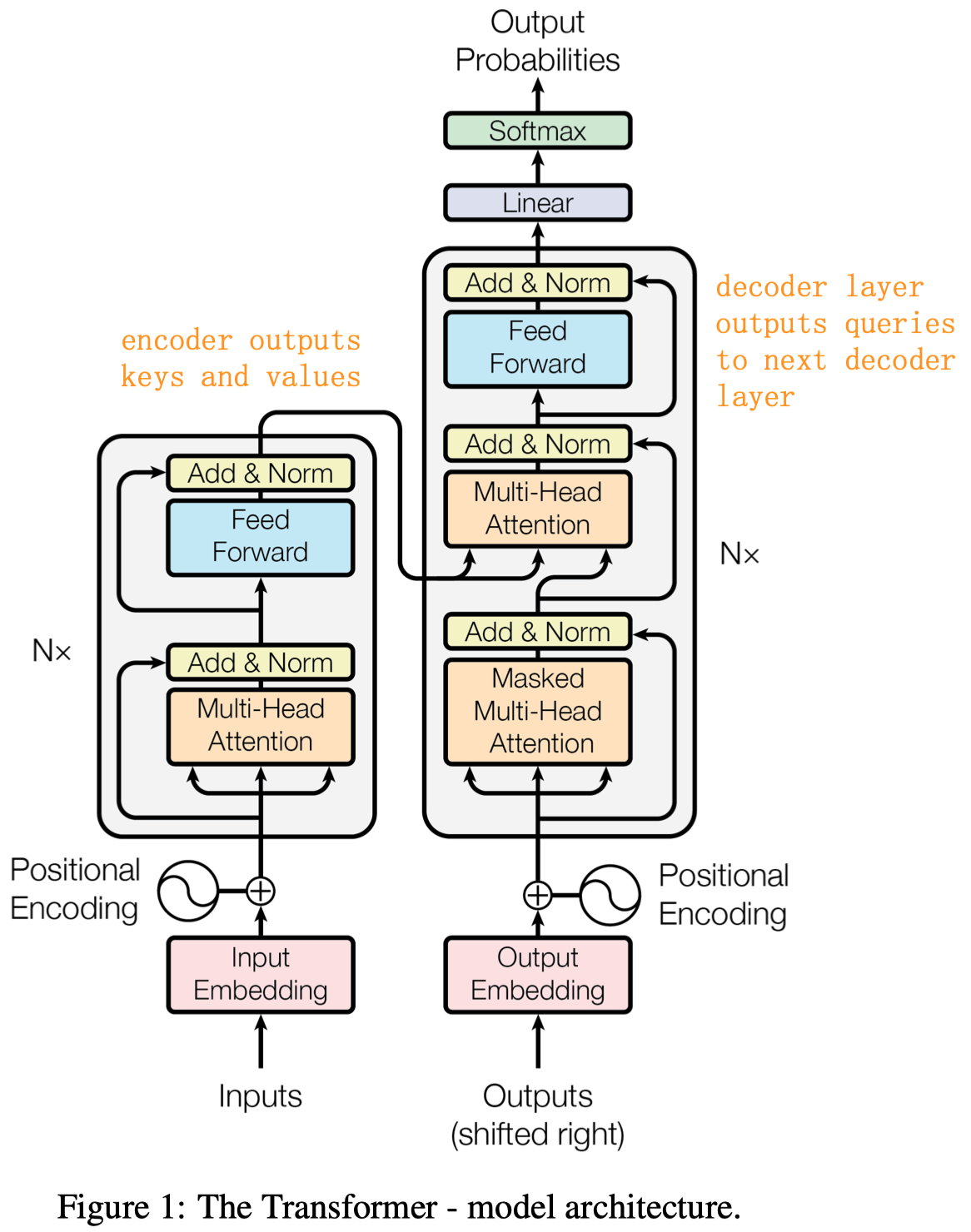
整体堆叠6层encoder,然后经过6层的decoder。6层encoder的最终输入会输入到每一层的decoder中。
每一层encoder包括两个sublayer,一个接受input的输入,然后经过\(h\)个多头注意力,残差加上原来的输入,之后norm(这叫做post-normalization,指layernorm放在残差之后,实际上后来很多工作使用的是pre-normalization,也就是先norm,再经过attention或FFN,最后残差,可参考ViT的结构),第二层经过一个前馈网络,还是残差加上原来的输入,经过norm。encoder的初始输入是全部的原始输入。
每一层的decoder包括三个sublayer,有两个与encoder一样,但是多了一层会接受encoder的输出作为keys和values。decoder的初始输入是\(t-1\)时刻的预测结果以及encoder的输出。
下面详细解析:
2.1 Multi-head attention
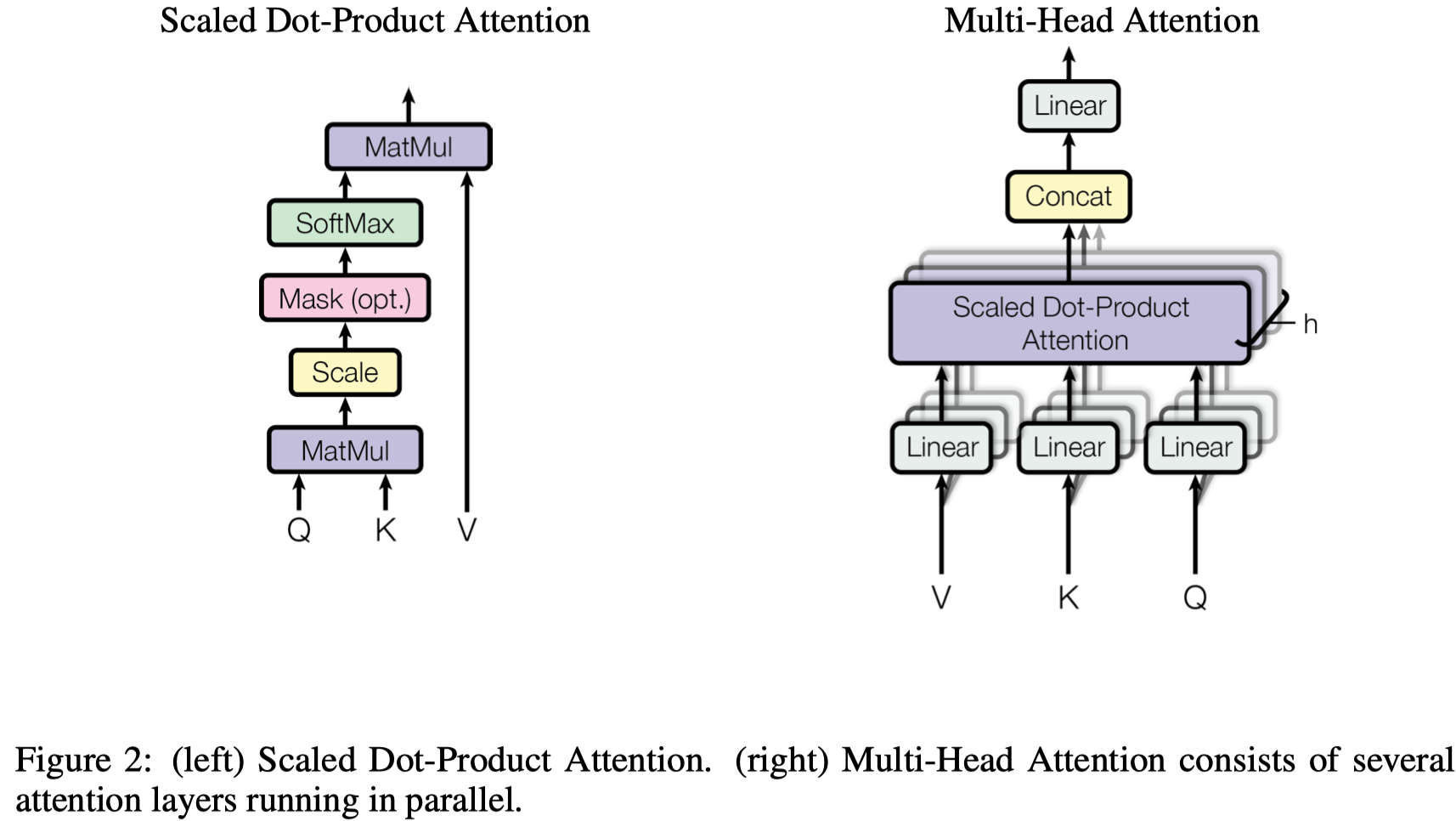
首先计算单个attention,使用query,keys和values来计算。使用query和其它所有embedding的keys计算出权值,然后不同的权值与values相乘求和。querys和keys的维度是\(d_k\),values的维度是\(d_v\)。 \[ Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V \] 需要注意的是其中多了一个常量\(\sqrt{d_k}\),这是因为作者在实验中发现加入除数常量的效果很好,原因可能是因为softmax的输入在值较大的时候梯度会变小,因此加入了一个除数常量减小值。
4 To illustrate why the dot products get large, assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product, \(q\cdot k=\sum^{d_k}_{i=1}q_ik_i\) , has mean 0 and variance\(d_k\) .
除以\(\sqrt{d_k}\)是为了防止在d_k特别大的时候,也就是hidden embedding维度比较大的时候,计算出来的注意力weight呈现出只有一个值非常靠近\(1\),其它值靠近\(0\)的情况,这会导致bp的时候的梯度就很小,几乎是0。
除以\(\sqrt{d_k}\)能够把输入softmax的absolute attention weight的值都scale的小一点; 减低指数函数\(e(\cdot)\)带来的放大效应/马太效应。详细的数学解释可以参考Transformer Networks: A mathematical explanation why scaling the dot products leads to more stable gradients
计算完成单个attention之后,再计算多头注意力,拼接起来之后再乘以一个权值矩阵: \[ MultiHead(Q,K,V)=Concat(head_1,\dots,head_h)W^O \] 在实践中,使用了8个头,每个维度64,一共维度512。每一个头都可以看做是好比CNN中的不同的卷积通道,每个head独立训练,有自己的参数,期望每个head能够学习到不同的pattern。高层和底层、同一层的不同head有可能学习到不同的知识(这一点有相关文章探讨,发现不同注意力层会捕获不同层次的信息,但是每一层的不同head可能只有几个会学习到不同的pattern,比如不同的attention分布)。
decoder的结构与encoder类似,但是它多了一层encoder和decoder。
2.2 self-attention
第一步:对于输入的每一个vector创建3个新的vector, a Query vector, a Key vector, and a Value vector。
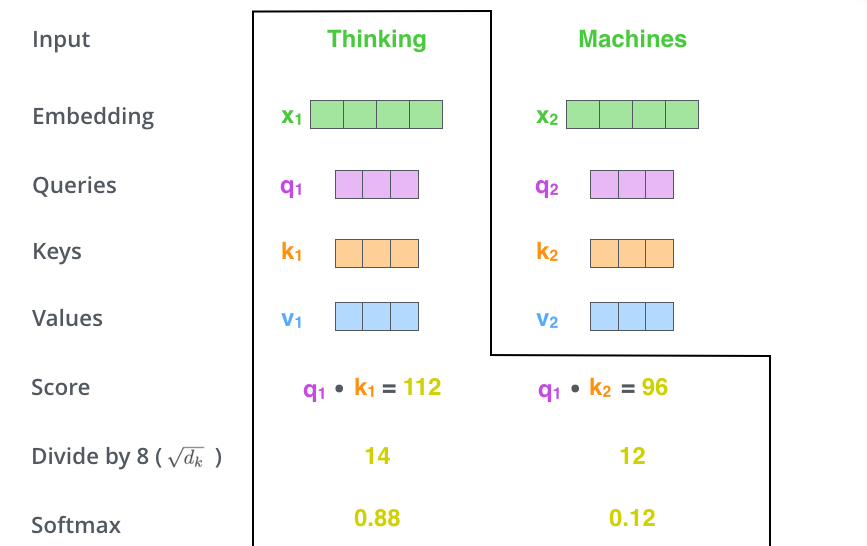
第二步:计算单个的score,比如说计算第一个词Thinking,需要计算整个序列当中所有的vector对于Thinking的vector的重要程度,使用Thinking的query vector和其它所有的key vector做dot product。
![]()
第三步与第四步:实际是归一化socre,相当于产生relative score。
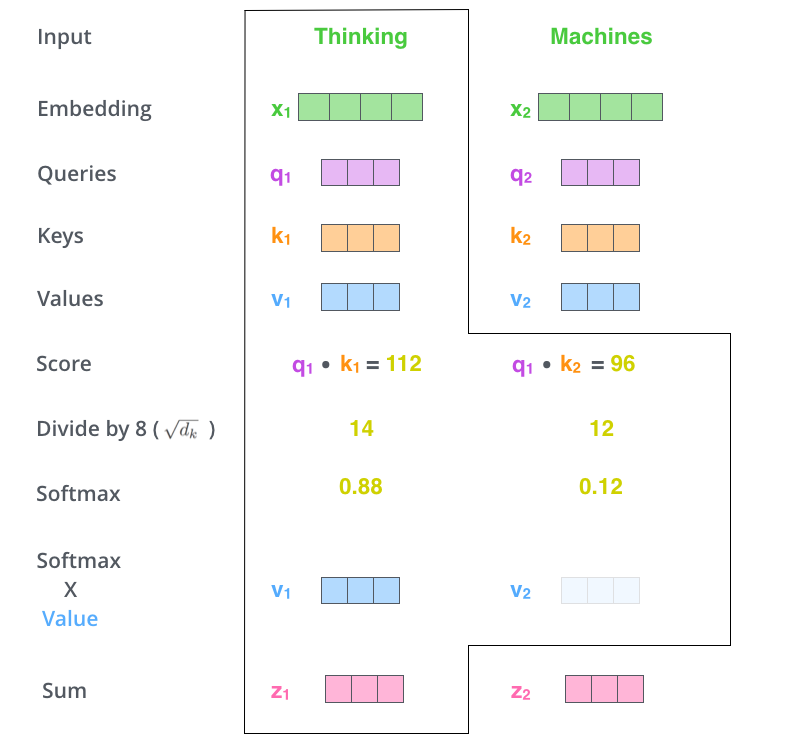
第五步:各个word vector与relative score相乘,求和。这样编码后的某个位置的新的embedding是由前一步所有输入的embedding共同决定的。
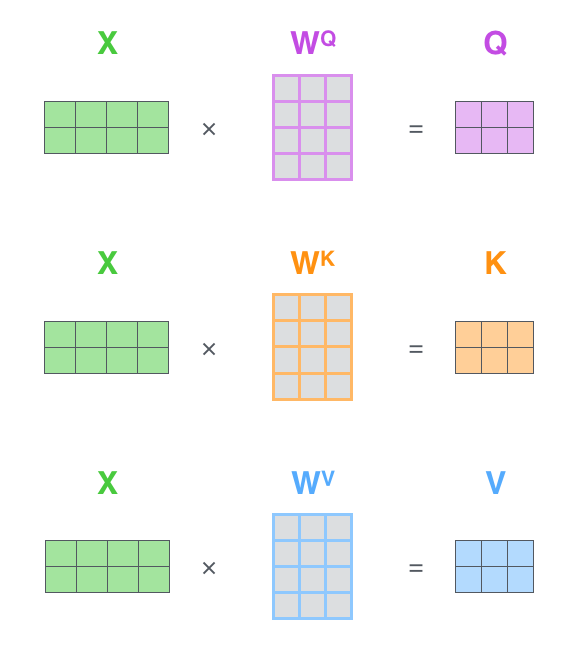
第六步:矩阵形式的实际计算情况
![]()
2.3 Encoder and Decoder
![]()
2.4 The Final Linear and Softmax Layer
decoder的输出,经过一个全连接层,然后得到logits vector,其中每一维度对应一个word;再经过softmax,取出score最大的word。
