MetaNER
Learning In-context Learning for Named Entity Recognition
ACL 2023,中科院,代码。
Named entity recognition in real-world applications suffers from the diversity of entity types, the emergence of new entity types, and the lack of high-quality annotations. To address the above problems, this paper proposes an in-context learning-based NER approach, which can effectively inject in-context NER ability into PLMs and recognize entities of novel types on-the-fly using only a few demonstrative instances. Specifically, we model PLMs as a meta-function λ instruction, demonstrations, text .M 1 , and a new entity extractor can be implicitly constructed by applying new instruction and demonstrations to PLMs, i.e., (λ.M)(instruction, demonstrations) → F where F will be a new entity extractor, i.e., F: text → entities. To inject the above in-context NER ability into PLMs, we propose a meta-function pre-training algorithm, which pre-trains PLMs by comparing the (instruction, demonstration)-initialized extractor with a surrogate golden extractor. Experimental results on 4 few-shot NER datasets show that our method can effectively inject in-context NER ability into PLMs and significantly outperforms the PLMs+fine-tuning counterparts.
作者提出了一种让小参数量的预训练语言模型学会针对NER任务的in-context learning的方法。
1. Introduction
少次NER任务的出现就是为了解决实体类型多样、新实体类型和高质量标注缺乏的问题。现有的少次NER方法包括fine-tuning-based和metric-based methods。
- The main drawbacks of fine-tuning-based methods are that re-training is often expensive (especially for large-scale models) and new entity types cannot be addressed on-the-fly.
- Metric-based methods are limited to the matching architectures and are sensitive to domain shift since they do not fully explore the information of target domain.
因此作者提出了让PLM模型学会ICL,根据新出现的样例学会抽取新的实体类型。(这一问题事实上LLM已经学会了,不需要额外的训练。这篇论文的重点在于如何让小的模型学会针对特定任务的上下文学习能力)。
2. Method
作者针对NER任务构造的ICL模板:

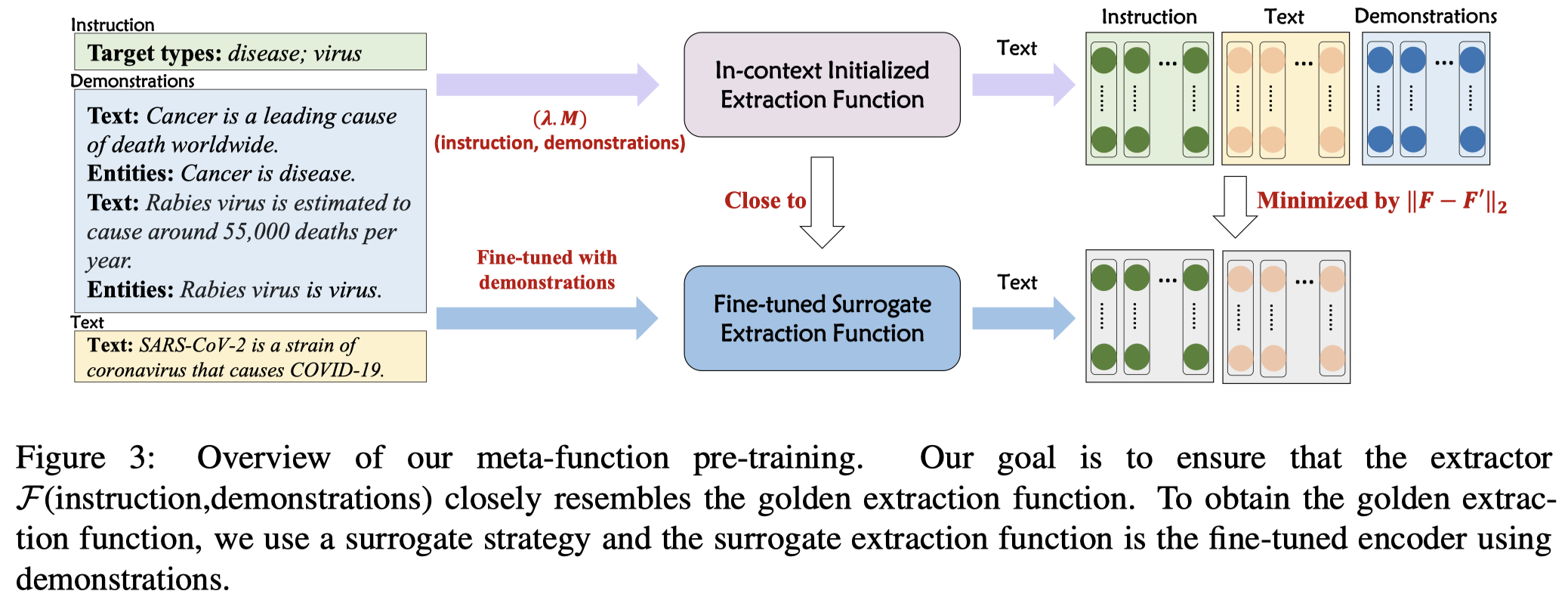
为了让PLM能够根据demonstrations学会抽取新的实体类型,作者提出了Meta-Function Pre-training for In-Context NER。
重点在于如何让PLM能够学会从demonstrations学习特征,然后能够抽取新的实体类型是重点。如果我们已知了理想的实体抽取函数,那我们只需要最小化PLM的上下文学习的输出和理想的实体抽取函数之间的差距即可。但是这样的理想函数并不存在。
因此,作者使用一个在demonstrations上进行参数更新的抽取模型作为替代(a surrogate extractor)。具体来说,在给定instruction \(I\), demonstration \(D\)和text \(T\)的情况下。先让PLM进行编码,获取到 \(I\), \(T\)的特征:
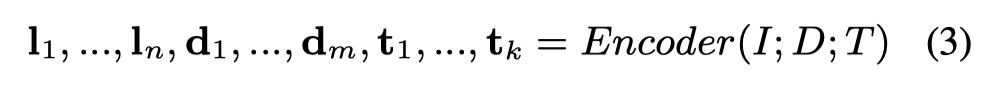
instruction \(I\)里包括了新的实体类型信息,text \(T\)包含了待抽取的文本信息。作者拿这两种feature去和一个经过了demonstrations训练后的模型,编码的特征靠拢:
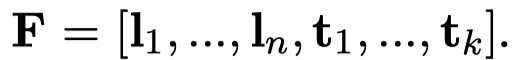
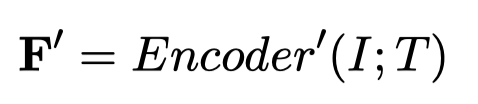

注意一下,这里的\(Encoder^\prime\)是拷贝了原来的encoder之后,进行梯度更新之后的编码器,不会影响原来的encoder。
仅仅是学习如何进行上下文学习是不够的,更重要的是我们要学会识别实体。因此作者还有一个loss是针对实体识别进行优化的。不过作者是用语言模型的loss来构造实体抽取的loss:
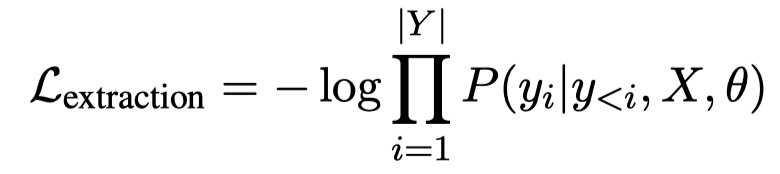
作者除了一般的信息抽取任务的形式,还提出了一种Pseudo Extraction Language Modeling Task。因为有实体标注的数据和没有实体标注数据之间的比例差距很大。因此作者想办法从一般的句子中也能够仿照NER任务构造出未标注来。比如:
instruction="Target types:
demonstrations="Text: [MASK1] is cool and I really [MASK2] it [MASK3]. Entities: [MASK1] is
text=“Text: I do not like it.”
要预测的输出output是”like is
将语言mask建模和span-based NER任务进行了统一。
3. Experiments
预训练的数据是通过对齐Wikipedia和Wikidata进行构造的。
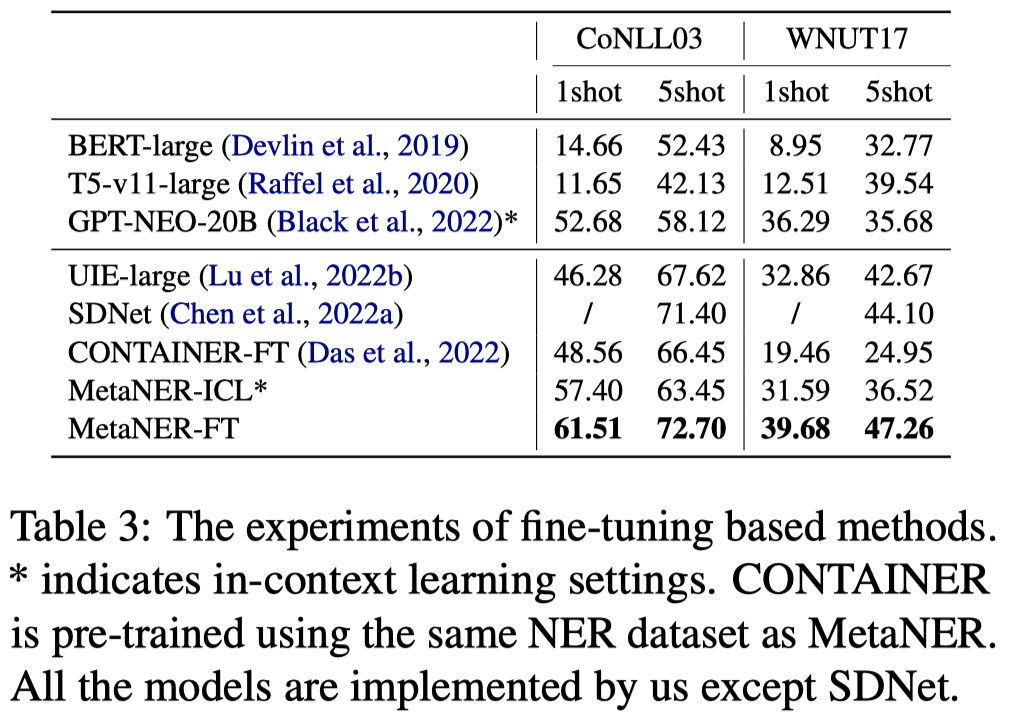
测试结果(没有在对应NER数据集上进行训练):
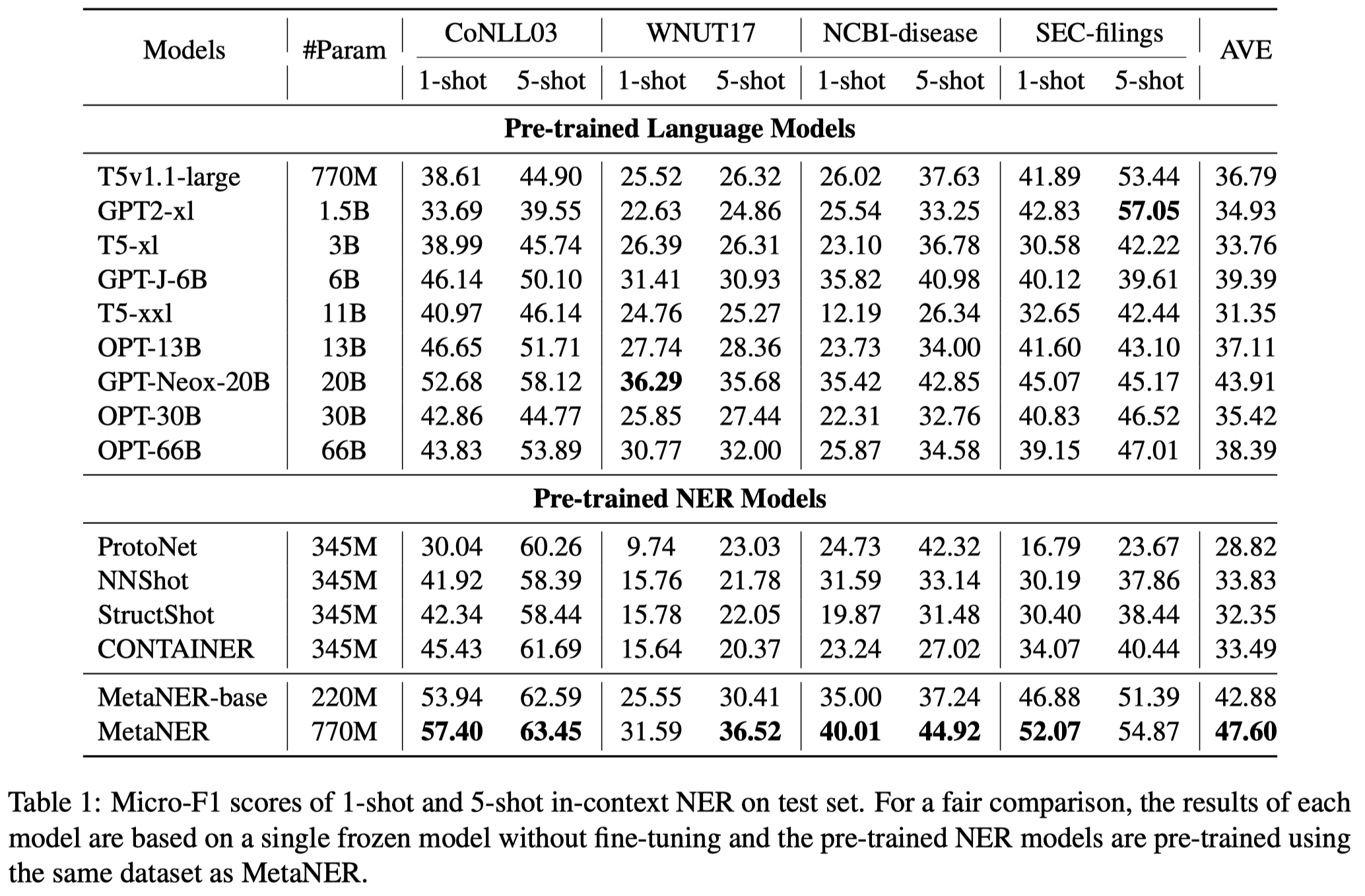
效果还是比不过直接在NER数据集上进行训练,好处是可以处理新出现的实体类型,更有实际意义: