FewGen-icml2023
FewGen-ICML2023
Recent studies have revealed the intriguing few-shot learning ability of pretrained language models (PLMs): They can quickly adapt to a new task when fine-tuned on a small amount of labeled data formulated as prompts, without requiring abundant task-specific annotations. Despite their promising performance, most existing few-shot approaches that only learn from the small training set still underperform fully supervised training by nontrivial margins. In this work, we study few-shot learning with PLMs from a different perspective: We first tune an autoregressive PLM on the few-shot samples and then use it as a generator to synthesize a large amount of novel training samples which augment the original training set. To encourage the generator to produce label-discriminative samples, we train it via weighted maximum likelihood where the weight of each token is automatically adjusted based on a discriminative meta-learning objective. A classification PLM can then be fine-tuned on both the few-shot and the synthetic samples with regularization for better generalization and stability. Our approach FewGen achieves an overall better result across seven classification tasks of the GLUE benchmark than existing few-shot learning methods, improving no-augmentation methods by 5+ average points, and outperforming augmentation methods by 3+ average points.
Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning. University of Illinois Urbana-Champaign. ICML 2023. Code.
一篇微调语言模型来生成训练数据的工作。主要关注如何学习label-discriminative (/dɪsˈkrɪmɪnətɪv/) samples。
1. Background
1.1 Few-Shot Learning with PLMs
受限于大量有标注数据获取的成本,少次学习一直以来都是深度学习领域关注的核心问题。
Few-shot learning has gained much attention recently due to its minimal resource assumption.
经过预训练阶段的PLM的出现一定程度上缓解了few-shot学习问题。当然,解决少次学习有很多其它思路,比如meta-learning。这里主要讨论的是使用PLM来解决少次学习问题的研究思路。
standard fine-tuning: 我们可以直接加载PLM预训练好的参数,利用预训练过程中被参数化编码的knowledge来更好的执行各类下游任务。但是通常要实现这一目标,我们可能会引入新的额外参数,比如对于分类问题,需要加上新的classification head。为了适应下游任务引入的新参数,一方面对于每个新的任务都需要学习额外的新参数,限制了模型的泛化能力。另一方面,这造成PLM在预训练时的预测模式和微调时的预测模式之间存在差异。
因此,prompt-based approaches方法出现了。它们通过将下游任务转化为natural language prompt这种统一format的形式,把下游任务的预测目标转化为预训练时的objective比如predicting next token,这样就实现了填补预训练阶段和下游任务阶段之间的gap,能够更好的利用/激发PLM在预训练阶段获得的language modeling ability。
沿着这个prompt-based approaches来进行downstream tasks思路有很多探究工作,比如:
- 利用task prompt/将训练数据作为in-context demonstrations来finetune PLM(自然语言的、discrete/hard prompt)
- 之后有工作尝试通过gradient-based searching (Shin et al., 2020)或parameterizing prompts as continuous learnable embeddings (Lester et al., 2021; Zhang et al., 2022; Zhong et al., 2021)实现自动获取prompt(数值的、continuous/soft prompt)
在PLM参数比较小的情况下,微调PLM是主要的利用PLM的方法。但是随着PLM参数量的不断增加,PLM的能力基本上不断增强,也就是large language model。一方面是微调PLM的成本越来越大、隐私、商业PLM不开源等问题;另一方面是即便不微调,很多任务也可以直接通过巧妙的调用PLM来解决(ICL、CoT等)。目前大多涉及到用大规模参数PLM解决各种下游任务是工作是不微调PLM的。
这篇工作不讨论这种几十B、上百B参数量的PLM,还是基于在PLM处在一个相对可以接受的参数量的情况下。上面提到的prompt-based approaches方法训练出来的model,和有大量labeled data训练出来的model的性能比起来仍然有很大差距。
1.2 Data Augmentation
因此,有另外一种思路是不直接fine-tuning PLM on few-shot samples,而是尝试让PLM构造更多的训练数据。这就是data augmentation。
Data augmentation methods aim to create similar samples to the existing ones so that the enlarged training set can benefit model generalization.
data augmentation方法在各个领域都有很多的研究。比如在CV领域,通过旋转、翻折、裁剪等简单的方法可以创建更多的image samples。这里主要关注在NLP领域的数据增强。基本的发展思路有:
- 基于规则的方法:利用人工设计的规则如同义词替换、随机插入token等获得新的text samples [EDA: Easy data augmentation techniques for boosting performance on text classification tasks. 2019]。但是这种方法一方面会降低原来text的fluency;一方面可能会破坏text原本的semantic。
- 基于PLM生成式的方法:将PLM在下游任务的少量labeled samples上进行训练,以学习label-conditioned generation probability。
这篇工作沿着基于PLM生成式的方法来进行数据增强。
1.3 Controlled Text Generation
The goal of controlled text generation is to generate textual contents of desired semantics, styles or attributes.
可控文本生成是对于PLM输出的控制。要达到这一点有不同的方法:
- During pretraining: control codes (Keskar et al., 2019) can be used as explicit guidance for training the model to generate domain/attributespecific texts; fine-tuning PLMs with attribute-specific data can also grant high-level control (e.g., certain topics or sentiments (Ziegler et al., 2019)), fine-grained control (e.g., specific words or phrases (Chan et al., 2021)) or both (Khalifa et al., 2021);
- at inference time: control over desired attributes can also be enforced without updating the PLM parameters (Dathathri et al., 2020; Krause et al., 2021; Kumar et al., 2021; Liu et al., 2021a; Pascual et al., 2021; Yang & Klein, 2021).
利用PLM,让PLM能够根据不同label生成期望的data,也是一种可控text生成。
2. Introduction
Issue: 之前的微调PLM进行数据生成的方法,没有显式地建模不同label之间的区别,可能导致在生成相似label对应的训练数据时,生成数据的质量难以保证。
Soluation: 作者认为在生成的时候,应该考虑token对于label的独特性。
3. Method
作者提出的方法的总体结构图:
3.1 Preliminaries
假定存在\(L\)个label,每个类型有\(K\)个训练数据,\(K\)是一个很小的值,如\(K=16\)。组成了训练集\(D_{train} = \{(\mathbf{x}, y)_i\}\)。其中,\(\mathbf{x} = [x_1,x_2,\dots,x_n]\)表示长度为\(n\)个tokens的text。类似的,还有\(D_{dev}\)和\(D_{test}\)。
我们要在训练集上训练一个data generator,\(G_{\mathbf{\theta}}\),来构造新的数据,所有新的生成数据构成了新的数据集合\(D_{gen}=\{ (\tilde{\mathbf{x}},\tilde{y})_i \}\)。
我们用\(C_\phi\)表示训练出来执行downstream task的分类器模型。
之前常见的训练数据生成器的方法是利用autoregressive PLM \(G_{\mathbf{\theta}}\)在\(D_{train}\)上按照maximum likelihood generation loss:
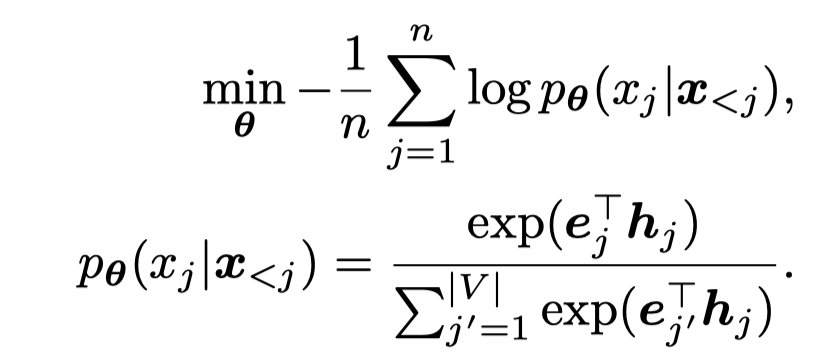
其中,\(\mathbf{h}_j\)表示是对于第\(j\)个位置PLM编码输出的embedding,\(\mathbf{e}_{j}\)表示正确的原来token \(j\)的token embedding,一共有\(V\)个候选token。期望正确token的输出概率\(p_\theta\)最大。训练结束后,就可以利用\(G_\theta\)按照学习到的概率不断采样新的tokens,获得新的生成数据。
但是如果直接在一个很小的训练集上,更新所有的PLM参数\(\mathbf{\theta}\)是不必要的。作者这里是利用prefix-tuning的方法,固定model整体的参数,只更新prefix vectors \(\mathbf{\theta}_p\),即最后学习到的data generator是\(G_{\mathbf{\theta}_p}\)。
3.2 Label-Discriminative Text Generator Tuning
对于带有label的任务来说,能够让生成的数据和label匹配是必要的。不同的label对应的数据可能有自己特有的pattern。而要学习conditional text generation probability \(p(\mathbf{x}|y_l)\)。最直接的方法是针对不同的label \(l\)有自己的参数\(\mathbf{\theta}_{p_l}\),直接优化generative likelihood:
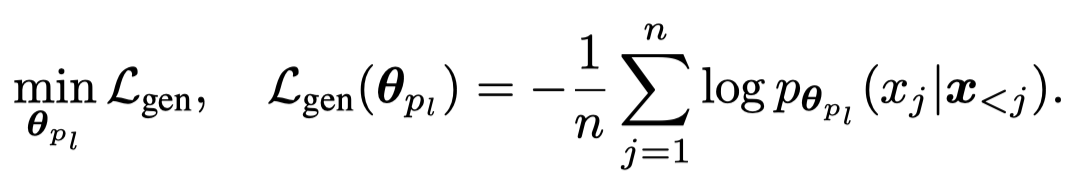
上面的方法没有考虑到label discriminativeness (/dɪˈskrɪmənətɪv/) \(p(y_l|\mathbf{x})\)也就是期望被downstream能够学习到的到的真实/理想分布。最理想的情况下,是期望生成的新数据:
- \(y_l\)是正确的
- 理论上,一个有足够能力的task model,可以根据\(\mathbf{x}\)非常confidence/明确的输出\(y_l\)
如果生成的数据从理论上/让人类去判断,根据\(\mathbf{x}\)既可以被分类为\(y_1\),又可以被分类为\(y_2\),很明显这个不是我们期望的理想数据。
对于很多challenging NLP tasks,是存在不同label之间有很相似的distributions的,不同label之间的差别很微妙。比如对于一个movie review:a movie where the ending feels like a cop-out,根据最后的cop-out可以判断这个是一个negative review(认为这个电影的结尾是个逃避式的结尾,比如作者选择了一种非常简单没法让人满意的方式结束了剧情,对于很多情节没有交代清楚);但如果仅仅是调整下最后的表达,换为revelation,就变为了一个positive review(认为电影的结尾有新意,出乎人的意料)。
为了评估label-discriminativeness,作者定义了一个新的loss,也就是某个text token \(j\),在使用label \(l\)时的对应参数 \(\mathbf{\theta}_p\)的情况下出现的概率和使用其它labels的对应参数时生成的概率的比值:
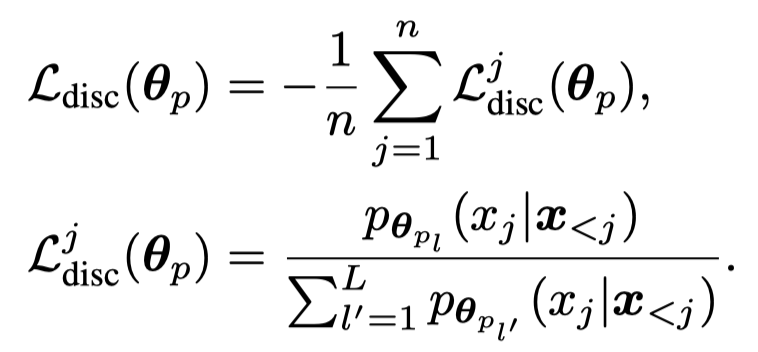
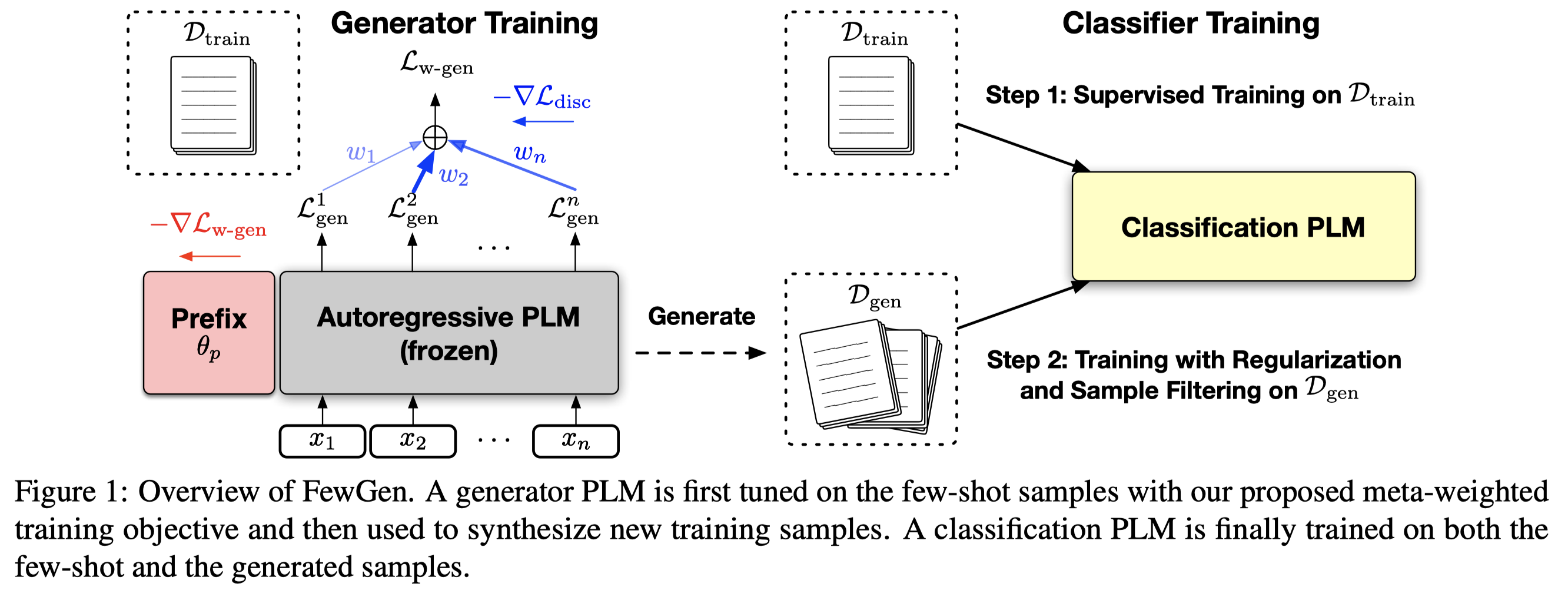
作者观察到,如果仅仅是优化前面的生成式的loss \(\mathcal{L}_{gen}\),label-discriminative loss \(\mathcal{L}_{disc}\)甚至是在增加的:
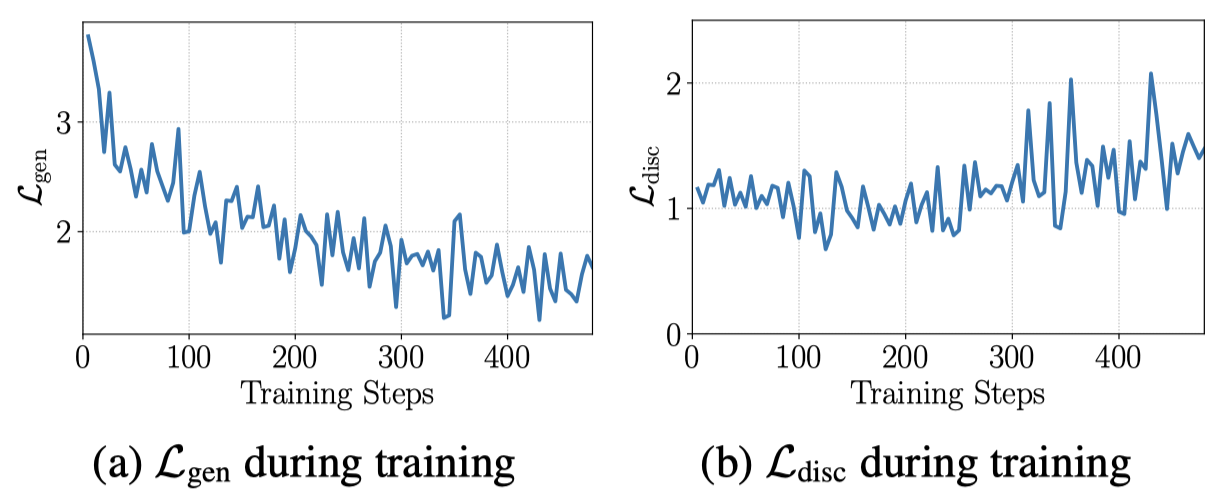
对于这个现象的解释是,在优化生成式loss的过程中,每个token对于最后的loss有相同的loss weight \(1\)。而大多数的token是label-indiscriminate,那么优化\(\mathcal{L}_{gen}\)只需要让大多数的token,在无论输入参数\(\mathbf{\theta}_{p_l}\)的情况下,都进行输出。就能够让\(\mathcal{L}_{gen}\)在全局上越来越小。例如输入a movie,接下来的that在输入任意\(\mathbf{\theta}_{p_l}\)的情况下,出现概率都差不多。让更多的token出现概率不会随着输入参数\(\mathbf{\theta}_{p_l}\)变化,可能是让\(\mathcal{L}_{gen}\)不断减小的较优解。
那么如何让PLM学会针对不同的label,生成的data有区别呢?
最直接的做法是同时优化label-discriminative loss \(\mathcal{L}_{disc}\)。但这么做可能不会带来理想的结果,可能会让PLM倾向于对每个位置上的tokens都针对不同label用独特的描述。但是想到the这些词实际上是不需要随着label变化的。
也就是说我们需要让PLM能够学会将不同的token区分出来,关注到其中是label-discriminative的tokens。我们可以给每个token赋予不同的loss weight \(w_j\),如果一个位置上的token是label-discriminative的,那么就增大它的loss weight \(w_j\)。这样实现让PLM在优化生成loss的时候,要更多的关注根据当前输入的label参数\(\mathbf{\theta}_{p_l}\)和输出的label-discriminative的对应。比如输入的label是negative,输出的关键token是cop-out这样的词;输入的label是positive,输出的关键token是revelation这样的词。再比如如果出现bad/good这样的word,很明显也应该关注。

\(w_j\)是随着不同的text变化的,要想提前人工设定好是不实际的。那么就需要某种方法来自动学习\(w_j\)。
首先,如果让\(w_j\)看做是一个可学习的参数,赋值给输入的\(\mathbf{x}\)上的不同tokens,然后通过优化上面的\(\mathcal{L}_{w-gen}\)学习不同的token loss weight。但这意味着我们需要给每个训练数据的每一个token都学习一个参数\(w_j\)。虽然这种做法可以实现,但很明显这种做法很笨拙,并且仅仅在样本量非常小的情况下可以应用。
作者的做法是借鉴了meta-learning的思想,将这个优化问题看做是bi-level optimization问题。
对于generator要优化的参数,还是通过optimize生成loss来获得:
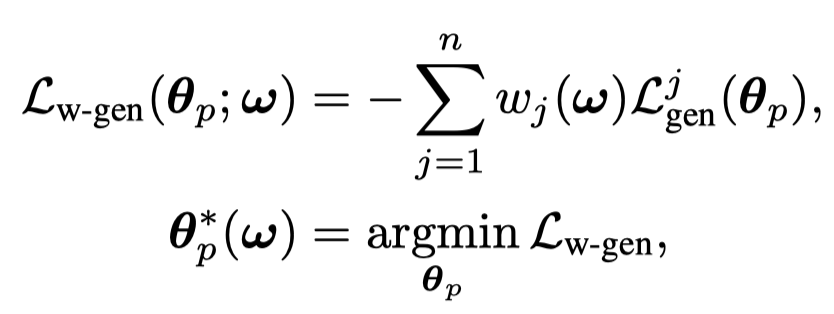
这里每个token的loss weight是通过\(w_j(\mathbf{\omega})\)函数计算得到的,它是一个带有softmax的feedforward network,输入是每个token计算得到的discriminative loss \(\mathcal{L}_{disc}^j\): \[ g_{\mathbf{\omega}} (\mathcal{L}_{disc}^j) = FFN(\mathcal{L}_{disc}^j) \\ w_j(\mathbf{\omega}) = \frac{exp(g_{\mathbf{\omega}} (\mathcal{L}_{disc}^j))}{\sum_{j^\prime = 1}^n exp(g_{\mathbf{\omega}} (\mathcal{L}_{disc}^{j^\prime}))} \] 这样输入的一个text不同位置的所有token的loss weight和是\(1\)。
对于要优化的weighting parameters \(\omega\)是通过优化outer objective \(\mathcal{L}_{disc}\):
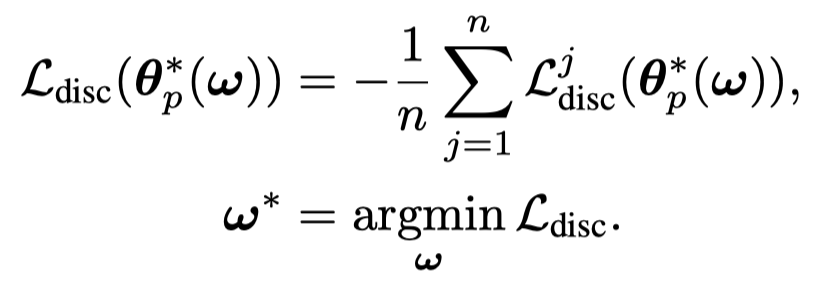
具体的优化过程是两者迭代的进行优化:

步骤:
- 采样一个batch集合\(\mathcal{B}\)
- 根据上一个优化步骤得到的\(\omega\)计算不同token的weight,然后优化生成loss,生成一个暂时的更新后的生成器参数\(\mathbf{\hat{\theta}}_p^{(t)}\);
- 根据\(\mathbf{\hat{\theta}}_p^{(t)}\),计算不同位置的\(\mathcal{L}_{disc}^j\),优化weighting network parameters \(\omega\),获得\(\omega^{(t+1)}\);
- 用新的\(\omega^{(t+1)}\)计算不同token的weight,优化生成loss,获得新的生成器参数\(\mathbf_p^{(t+1)}\);
我们可以计算一下,在优化两个loss的情况下,对应的新的参数更新:
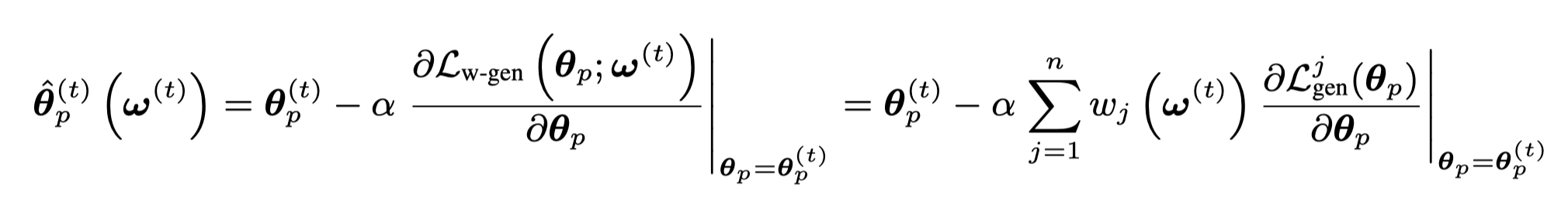
上面的优化过程中,\(w_j\)越大,对于最后参数更新的影响也越大,新的参数\(\theta_p\)更会朝着能够使得\(w_j\)比较大的token的生成loss减小的梯度方向进行优化。
对于\(\omega\)的更新:
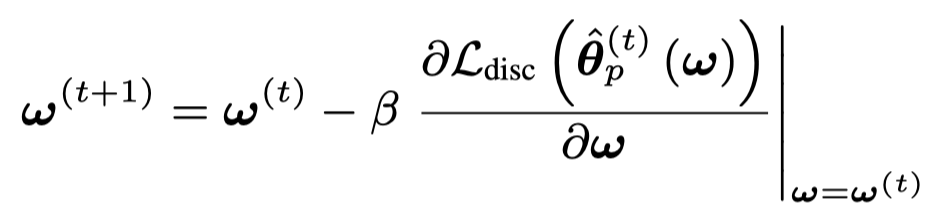
后面这一项继续展开:
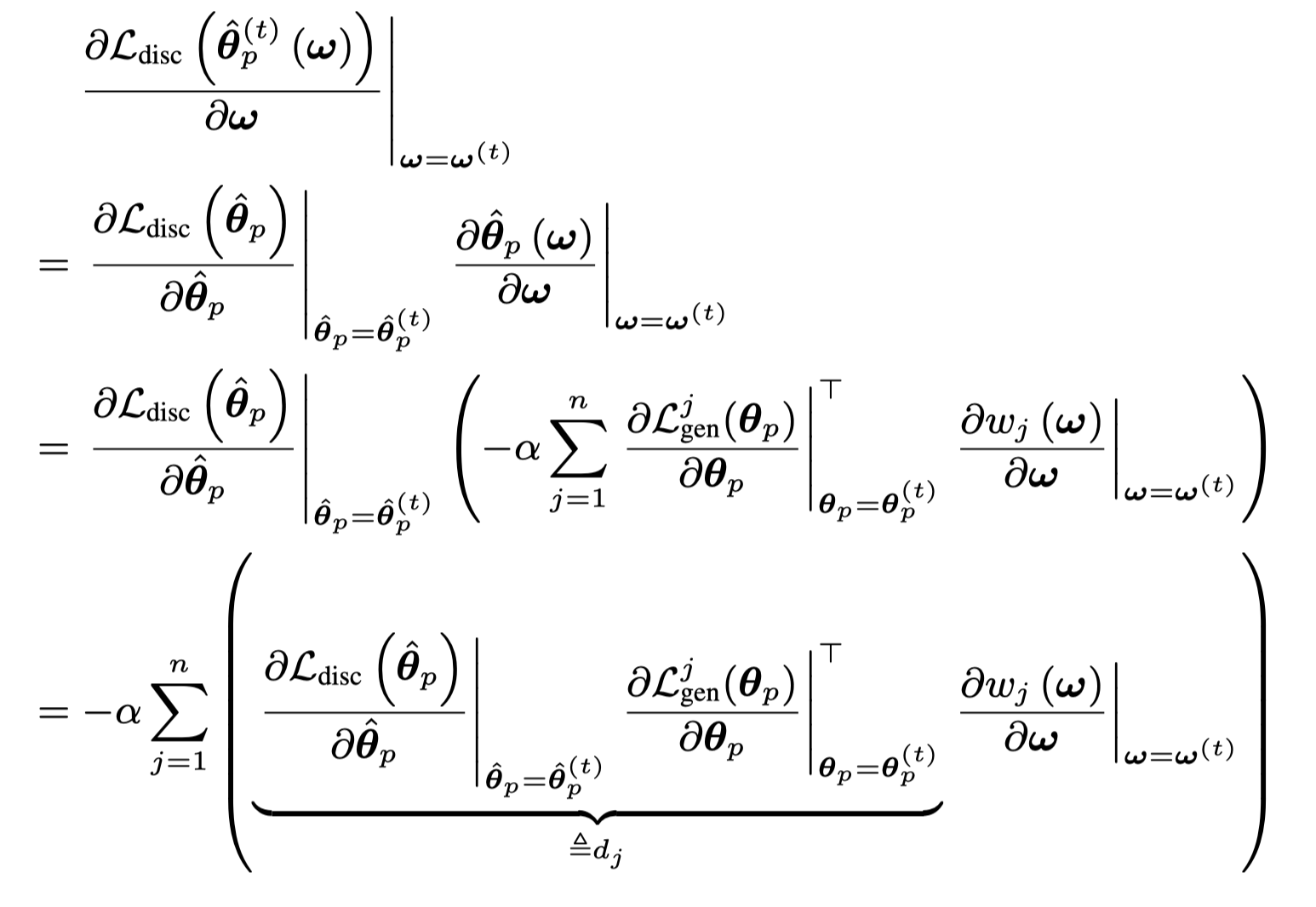
也就是说:
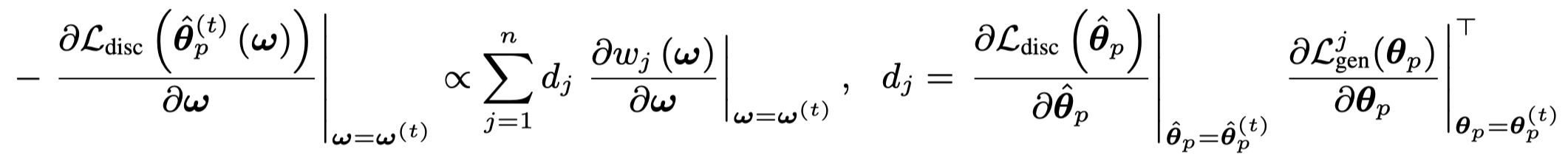
\[ \mathbf{\omega}^{t+1} = \mathbf{\omega}^{t} + \alpha \beta \sum_{j=1}^n d_j \frac{\partial{w_j(\mathbf{\omega})}}{\partial{\mathbf{\omega}}} \]
\(d_j\)代表着优化第\(j\)个token的生成loss和优化discriminative loss对于参数\(\theta_p\)梯度的相似程度。越大越相似,也就是说这个位置上的token,优化它的discriminative loss和generative loss都能够一致的减小。举例,对于前面提到的good/bad这些token,重点针对它们优化generative loss,能够使discriminative loss也减小。可以看出,\(\omega^{t+1}\)最后优化方向会更多朝着\(d_j\)比较大token,增大其\(w_j\)的方向进行优化。
接下来是怎么样训练分类器\(C_\phi\),最大的问题是生成的data里无法避免的会存在错误标注的数据,也就是存在label noise。为了实现这一点,作者使用了一个简单的noise-robust training procedure。首先,先是在\(\mathcal{D}_{train}\)上进行训练。然后在生成的数据集\(\mathcal{D}_{gen}\)上进行训练。
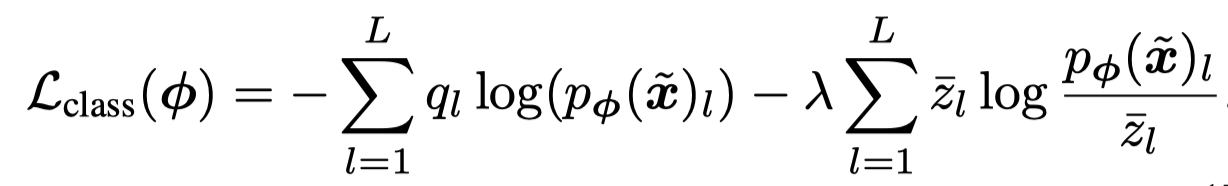
这里的\(q_l = \mathbb{1} (l=\tilde{y}) (1-\epsilon ) + \epsilon/L\),如果\(l=\tilde{y}\),那么\(q_l =1- \epsilon + \epsilon/L = 1-\epsilon (L-1) / L\)。如果\(l\neq\tilde{y}\),那么\(q_l = \epsilon / L\)。label smooth之后,所有的标签和相加仍然是1。
第一项是交叉熵,第二项是针对temporal ensembling的正则项。其中是\(\bar{z}\)是ensembled predictions,\(\hat{z}\)是accumulated model prediction,\(p_\phi\)是current model prediction:
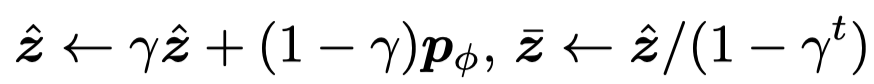
第二项的意思是期望降低当前的预测结果current model prediction \(p_\phi\)和历史累积预测结果\(\bar{z}\)之间的差异。也就是稳定更新参数后的task模型的预测结果与没有更新参数前的预测结果的变化。并且在这个过程中,只有计算出来的累积预测分布大于阈值\(\delta=0.8\)的才会被考虑加入到训练过程中。

4. Experiments
4.1 Experimental Setup
作者在GLUE这个benchmark上进行了实验。
使用CTRL(1.6B)作为data generator,使用RoBERTa-Large(356M)作为downstream task model。
4.2 Results
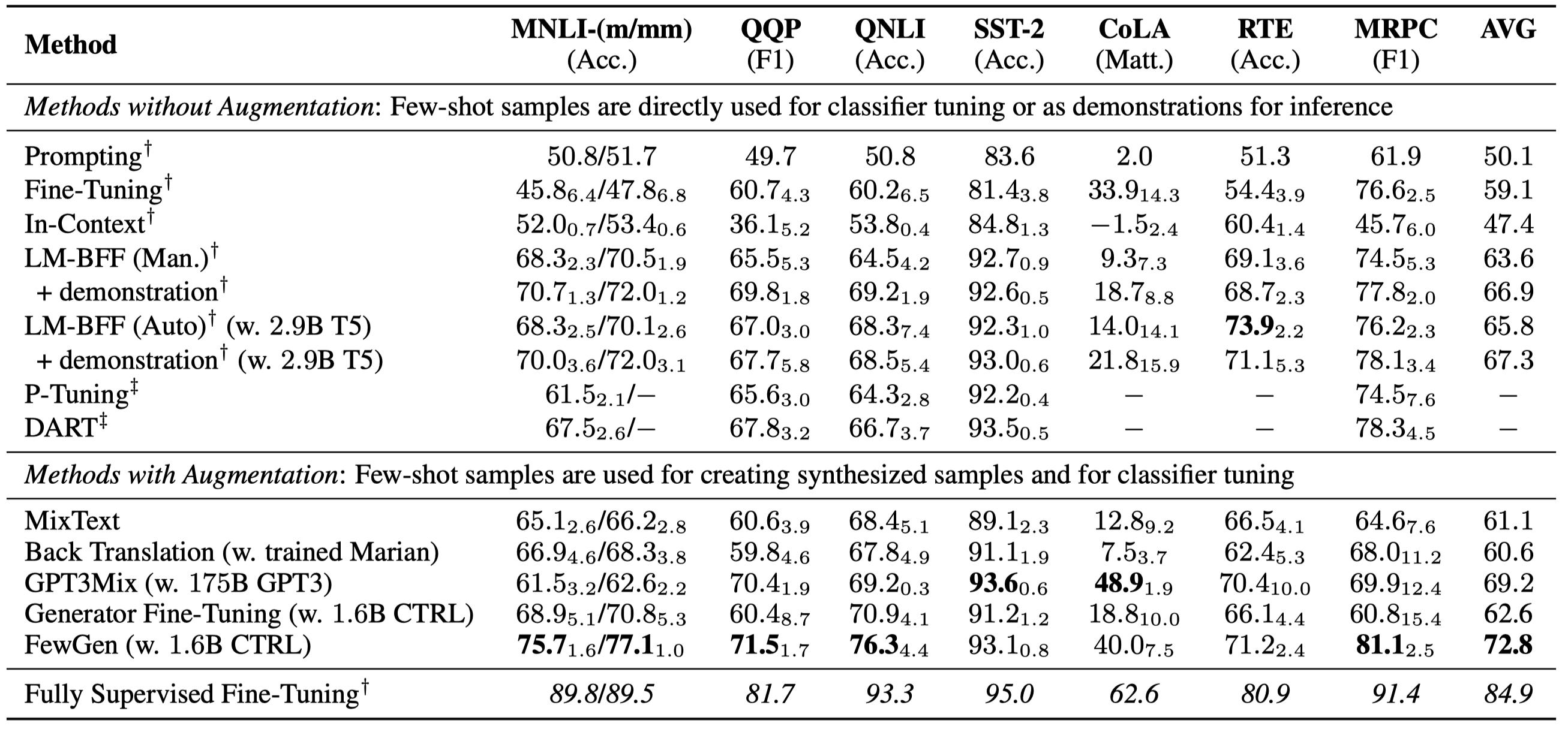
主要实验结果:
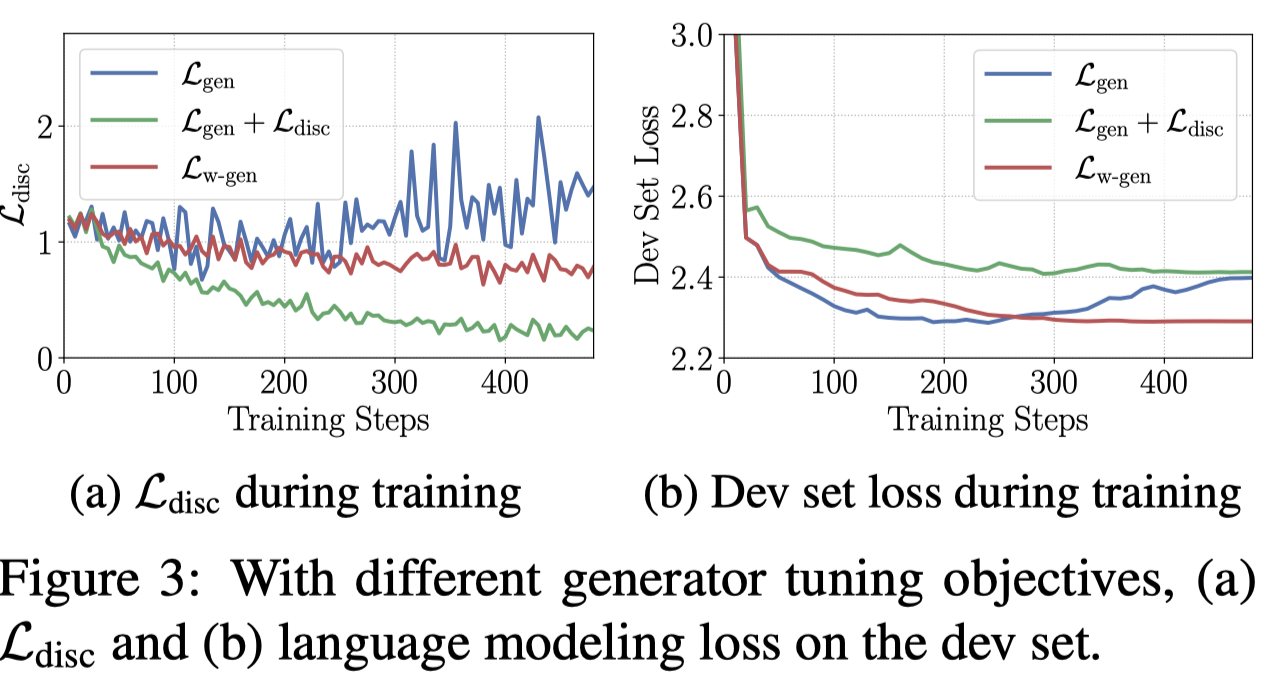
消融实验: