Demonstration-based-NER
Good Examples Make A Faster Learner Simple Demonstration-based Learning for Low-resource NER
南加州大学,ACL 2022,代码。
Recent advances in prompt-based learning have shown strong results on few-shot text classification by using cloze-style templates. Similar attempts have been made on named entity recognition (NER) which manually design templates to predict entity types for every text span in a sentence. However, such methods may suffer from error propagation induced by entity span detection, high cost due to enumeration of all possible text spans, and omission of inter-dependencies among token labels in a sentence. Here we present a simple demonstration-based learning method for NER, which lets the input be prefaced by task demonstrations for in-context learning. We perform a systematic study on demonstration strategy regarding what to include (entity examples, with or without surrounding context), how to select the examples, and what templates to use. Results on in-domain learning and domain adaptation show that the model’s performance in low-resource settings can be largely improved with a suitable demonstration strategy (e.g., 4-17% improvement on 25 train instances). We also find that good demonstration can save many labeled examples and consistency in demonstration contributes to better performance.
作者试了几种为NER任务设计的demonstrations检索和对应的模板构造方法,只不过是在bert-base上进行的实验。
作者的方法图:
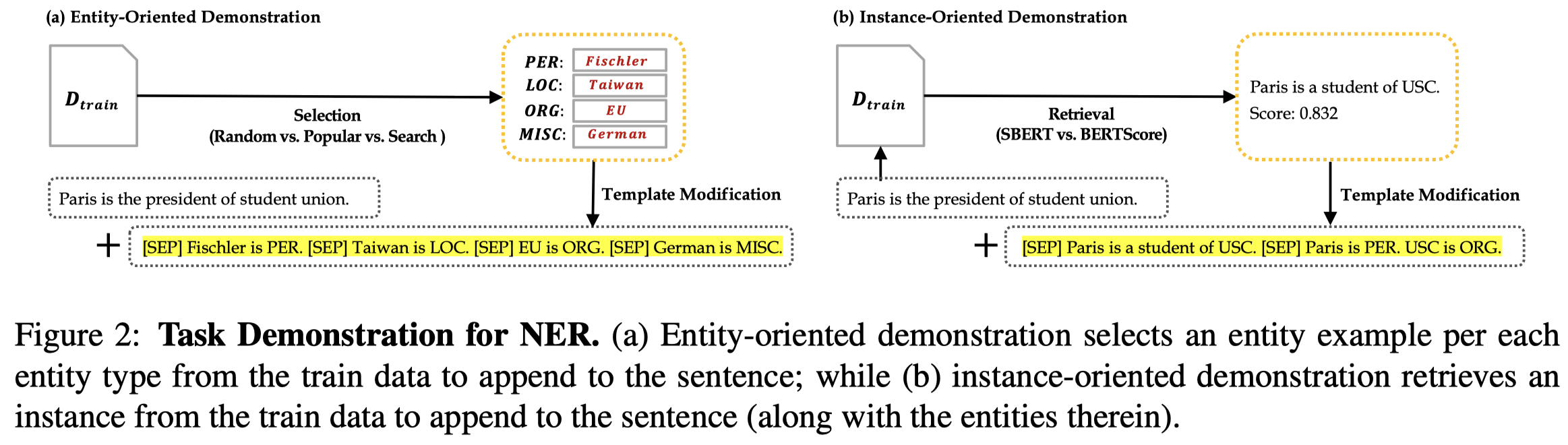
作者提了2种检索NER demonstrations的方法:
- Entity-oriented:就是以实体为核心进行检索,包括简单的3种方式:
- random:每一类entity type中,从训练集所有的对应实体进行检索(动态的)
- popular:每一类entity type中,选择出现次数最多top-k的对应实体(静态的)
- search:每一类entity type中,选择出现次数最多top-k的对应实体,grid search可能的实体组合,然后在验证集上找到效果最好哦的那种组合(静态的)
- Instance-oriented:以查询的当前句子为核心,进行检索,计算和其它训练集中句子的相似度,包括2种相似度计算方法:
- SBERT:计算两个句子编码后CLS token embedding的余弦相似度(动态的)
- BERTScore:两个句子不同token之间的相似度的和(动态的)
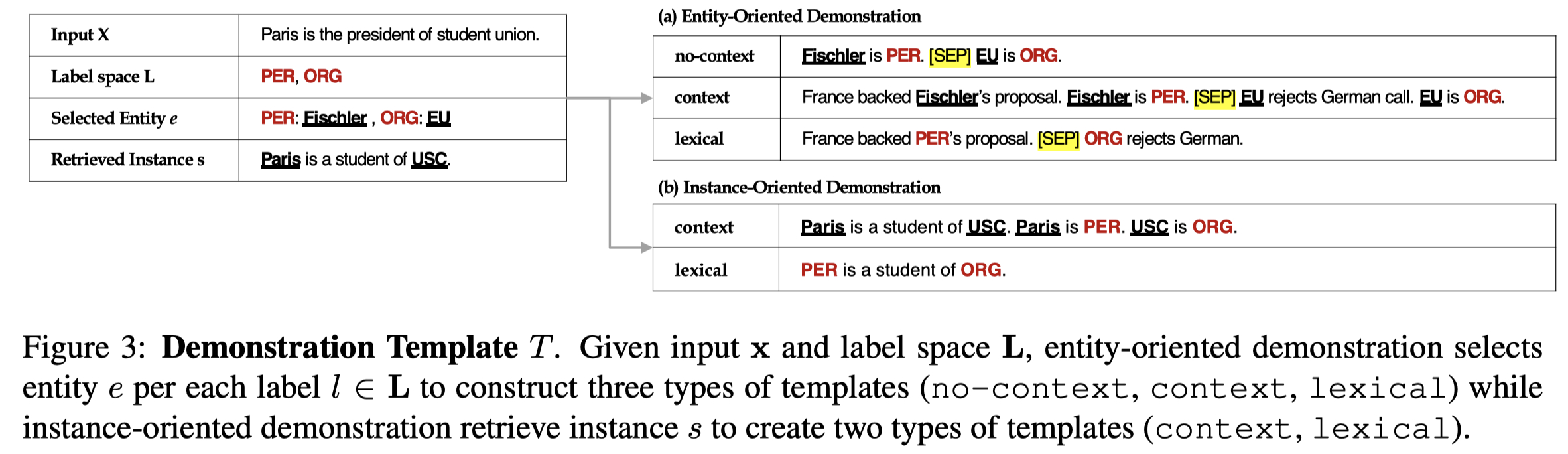
在找到了训练集中的demonstration之后,怎么样构造模板,作者提了3种方式:
- no-context:没有训练样例里面的句子,只保留实体,“entity is type."
- context:保留对应的句子,再加上“entity is type."的描述
- lexical:把原来句子中的entity替换为对应的entity type。这样获取能够直接捕获到不同label之间的对应关系
demonstration模板示例:
实验部分是基于bert-base-cased去做的。把找到的demonstrations拼接到要查询的query text前面,用bert编码以后的embedding过一个CRF,就得到了NER序列标注。
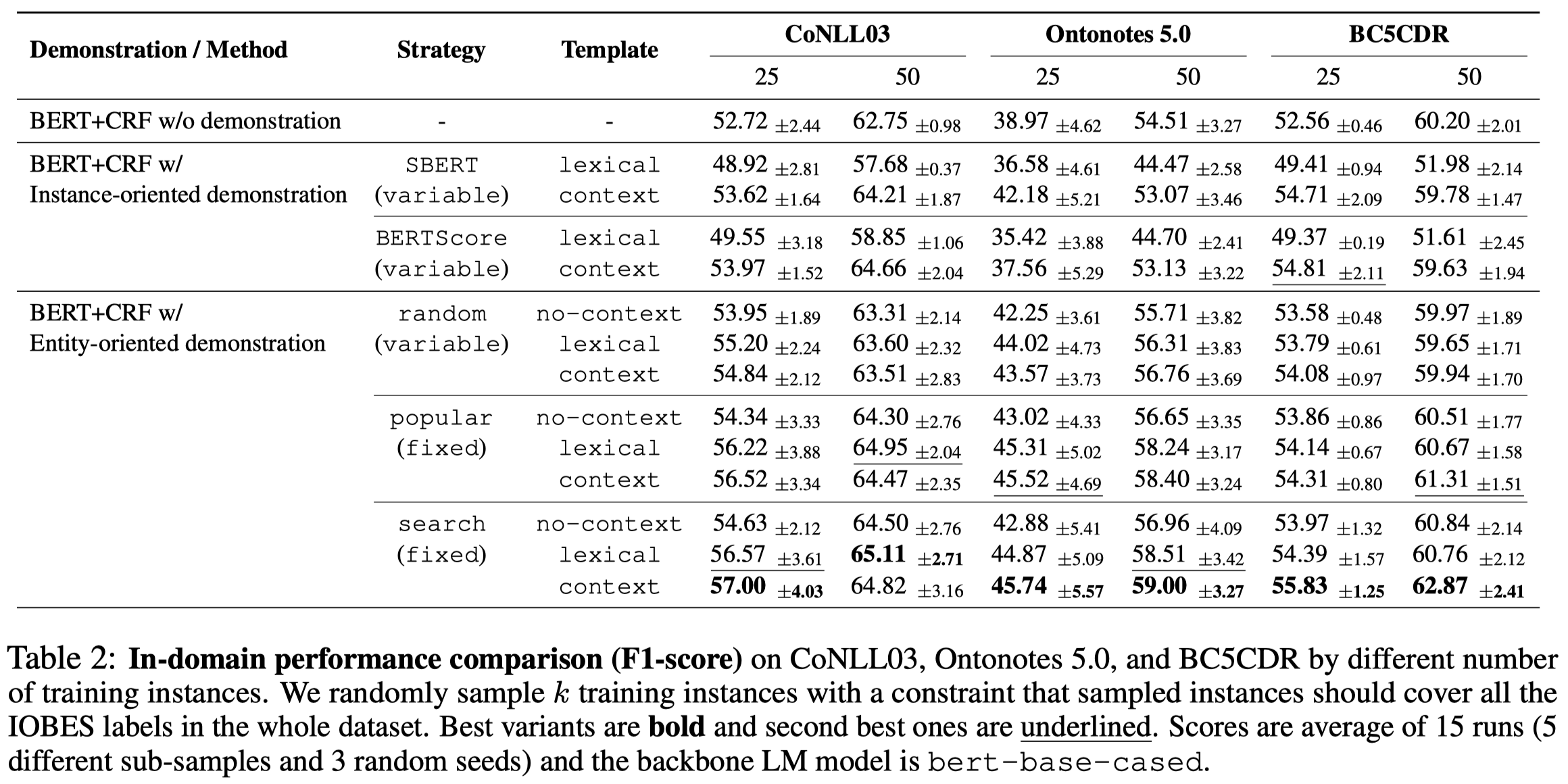
效果最好的,就是在验证集上进行评估,选择保留context。只不过作者这里只利用到了相似度计算,没有像现有的上下文学习方法利用kNN去做检索。