TRC_Dataset
Categorizing and Inferring the Relationship between the Text and Image of Twitter Posts
ACL 2019,代码,彭博社
Text in social media posts is frequently accompanied by images in order to provide content, supply context, or to express feelings. This paper studies how the meaning of the entire tweet is composed through the relationship between its textual content and its image. We build and release a data set of image tweets annotated with four classes which express whether the text or the image provides additional information to the other modality. We show that by combining the text and image information, we can build a machine learning approach that accurately distinguishes between the relationship types. Further, we derive insights into how these relationships are materialized through text and image content analysis and how they are impacted by user demographic traits. These methods can be used in several downstream applications including pre-training image tagging models, collecting distantly supervised data for image captioning, and can be directly used in end-user applications to optimize screen estate.
作者对tweet的文本和图像之间的关系进行了定性与定量的分析,提出了文本和图像之间存在两个维度的关系:
- 文本内容是否在图像中表示(Text is represented / Text is not represented),关注文本和图像之间是否存在信息的重叠overlap
- 图像内容是否增加了tweet的语义(Image adds / Image does not add),关注图像的语义在整个tweet语义的作用,关注图像能否提供文本之外的信息
作者创建了基于Twitter数据的文本-图像分类数据集TRC(Text-image relation classification)
1. Introduction
问题:图像在tweet中是一个很重要的角色,很大一部分的tweet都会带有图像,并且根据2016年的一个调查(What 1 Million Tweets Taught Us About How People Tweet Successfully. 2016)发现拥有图片的tweet的参与度是没有图像的tweet的两倍。但是没有研究讨论post的文本内容是如何和图像信息相关的。
方案:作者从两个维度描述tweet上文本和图像信息的关系:

- 对于a和b,图像增加了文本内容。a的图像通过提供更多的解释信息,b的图像通过提供更加明确的上下文情景理解文本内容
- 对于c和d,图像没有增加文本内容。c的图像仅仅是文本的重复表示,d的图像是一个网络meme,甚至与文本内容无关。
- 对于a和c,文本和图像的信息有重叠。
- 对于b和d,文本和图像的信息没有重叠。
2. Categorizing Text-Image Relationships
判断文本内容和图像内容是否有重叠的几个依据(Text task):
- 文本内容在图像中进行了表示,有信息重叠(Text is represented):部分或者全部的文本在图像中进行了表示
- 文本内容在图像中没有进行表示(Text is not represented):
- 没有文本单词在图像中有对应
- 文本是对于图像内容的评论
- 文本是对于图像内容的feeling
- 文本仅仅是指向了图像内容
- 文本与图像无关
判断图像是否能够拓展文本语义(Image task):
- 图像能够拓展文本语义
- 图像中包括了其它额外的文本
- 图像描绘了增加文本内容的其它信息
- 图像描绘了文本中引用的实体
- 图像没有拓展文本语义:图像没有描绘任何文本内容之外的信息
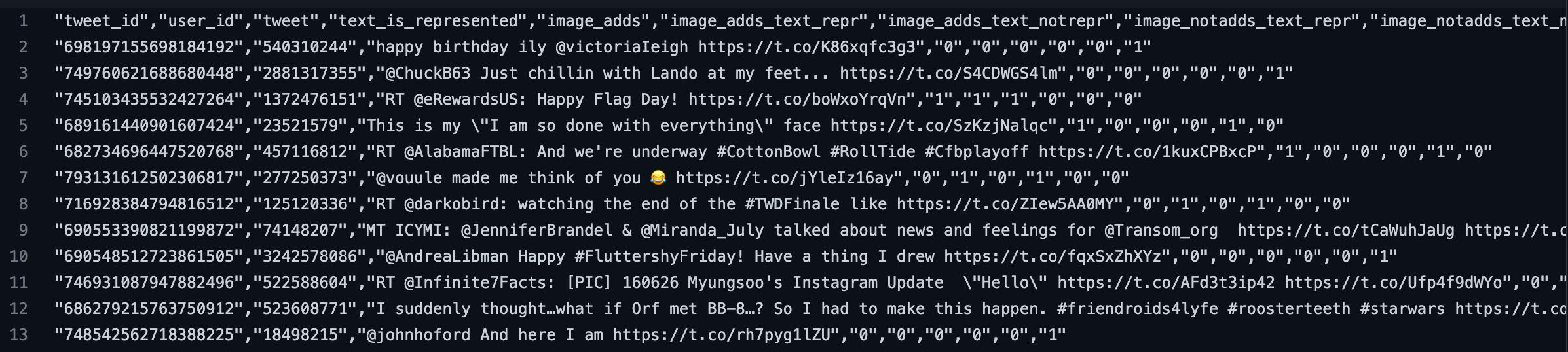
3. Data Set
数据采样来源是从一个已知用户个人信息的列表中(Beyond Binary Labels: Political Ideology Prediction of Twitter Users. ACL 2017),随机选择他们发布的tweet:
- 只采样2016年的tweet,避免随着时间用户发布tweet可能的改变
- 过滤掉所有的非英语tweet
- 只选择美国的用户,避免文化差异
最终获得了2263个用户发布的4471个tweet。
在CrowdFlower上通过众包进行标注,最终的统计结果如下,来自RpBERT论文:

5. Predicting Text-Image Relationship
使用80%训练,20%测试,作者使用了一系列的方法进行判断:
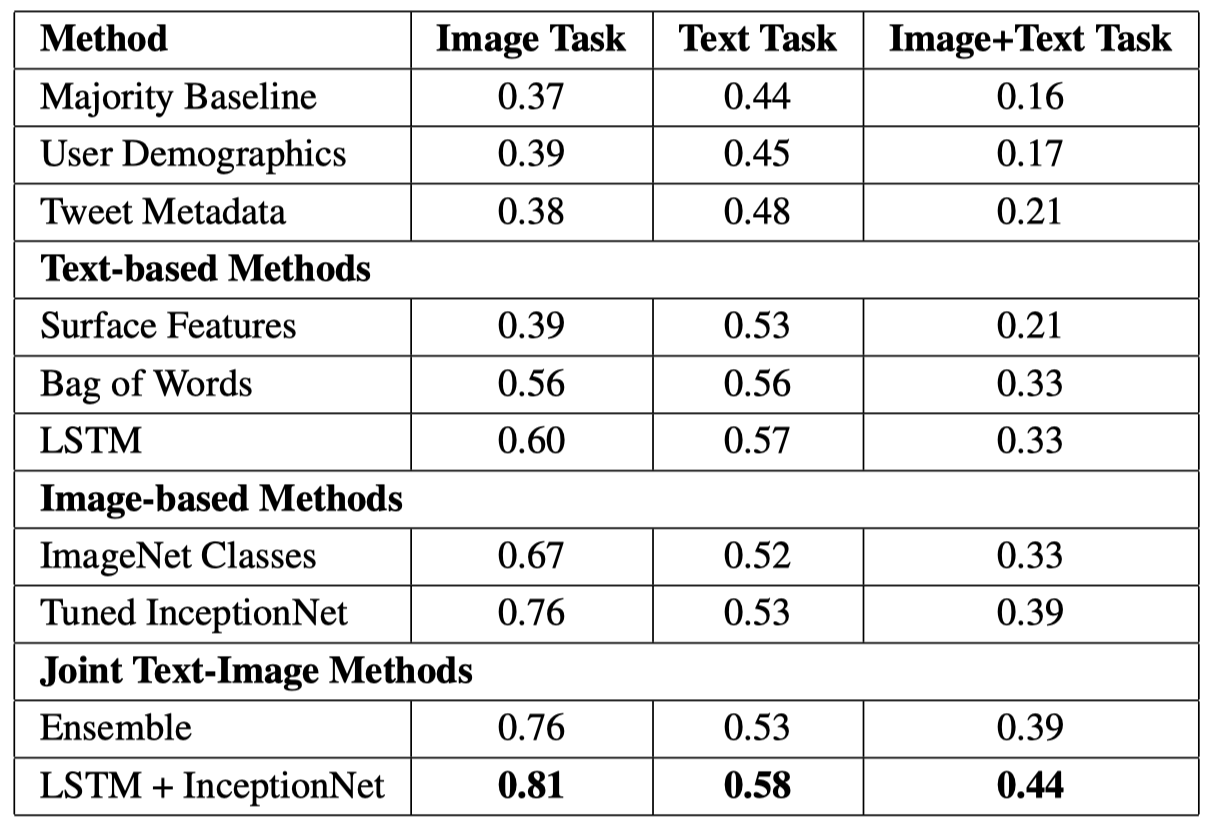
结果发现同时使用文本和图像的方法,更能够准确的判断出来text-image的关系。
6. Analysis
作者使用用户的人口特征、tweet metadata(如账号的follow人数、tweet是否是reply等)以及文本,进行了综合的分析(使用Pearson correlation)。
结果发现用户的特征中,年龄和text-image的关系比较大,而其他的特征关系较弱。年龄大的喜欢发送和文本内容有重叠的tweet,年龄较小的用户喜欢发送和文本内容无关的tweet(比如一个表情包meme)。
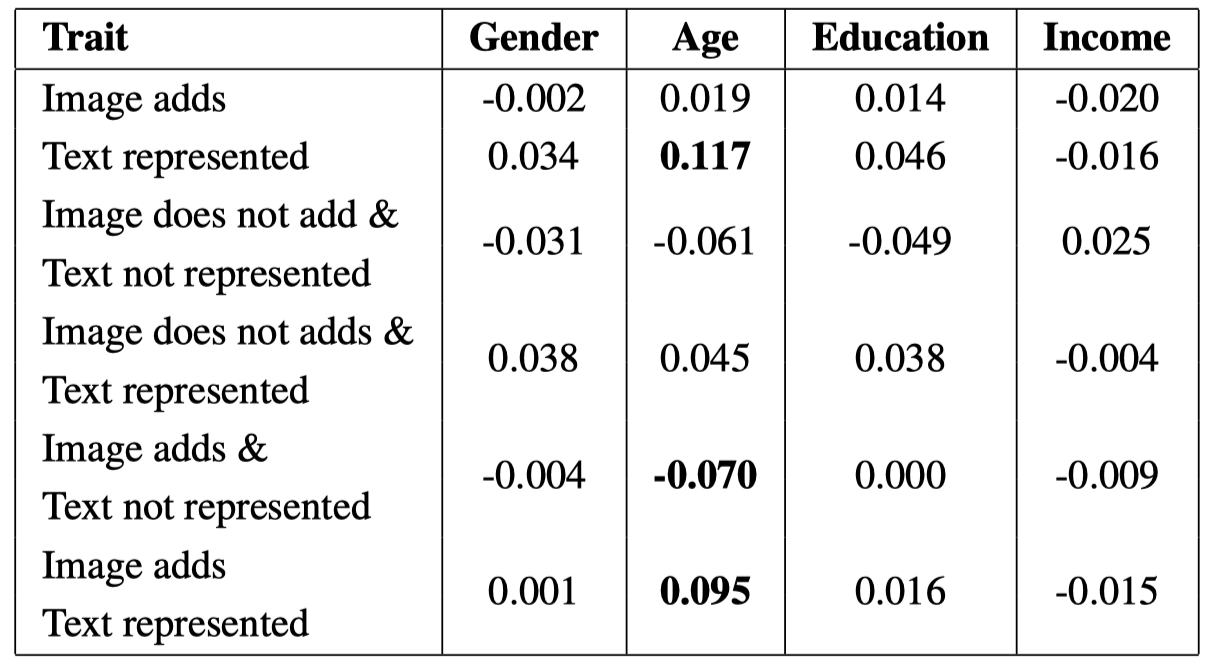
作者发现tweet metadata和text-image关系没有显著关联。
对文本进行分析,发现某些特定文本词和text-image关系有关联:
