PromptMNER
PromptMNER: Prompt-Based Entity-Related Visual Clue Extraction and Integration for Multimodal Named Entity Recognition
复旦大学计算机科学学院,上海数据科学重点实验室,DASFAA 2022
作者提出了一种利用prompt来更好的导出实体相关的视觉特征的方法。
Multimodal named entity recognition (MNER) is an emerging task that incorporates visual and textual inputs to detect named entities and predicts their corresponding entity types. However, existing MNER methods often fail to capture certain entity-related but textloosely-related visual clues from the image, which may introduce taskirrelevant noises or even errors. To address this problem, we propose to utilize entity-related prompts for extracting proper visual clues with a pre-trained vision-language model. To better integrate different modalities and address the popular semantic gap problem, we further propose a modality-aware attention mechanism for better cross-modal fusion. Experimental results on two benchmarks show that our MNER approach outperforms the state-of-the-art MNER approaches with a large margin.
作者主要是提出了在图像中,对于MNER任务来说,更加重要的是entity-related的视觉特征,而单纯的text-related的视觉特征是和entity以外的文本关联,可能包括了更多的噪音。
为了解决这一问题,作者设计了entity-related prompts,通过利用pretrained vision-language model来判断不同prompt和图像之间的匹配程度,进而选择合适的prompt来作为entity-related的视觉特征。
Method
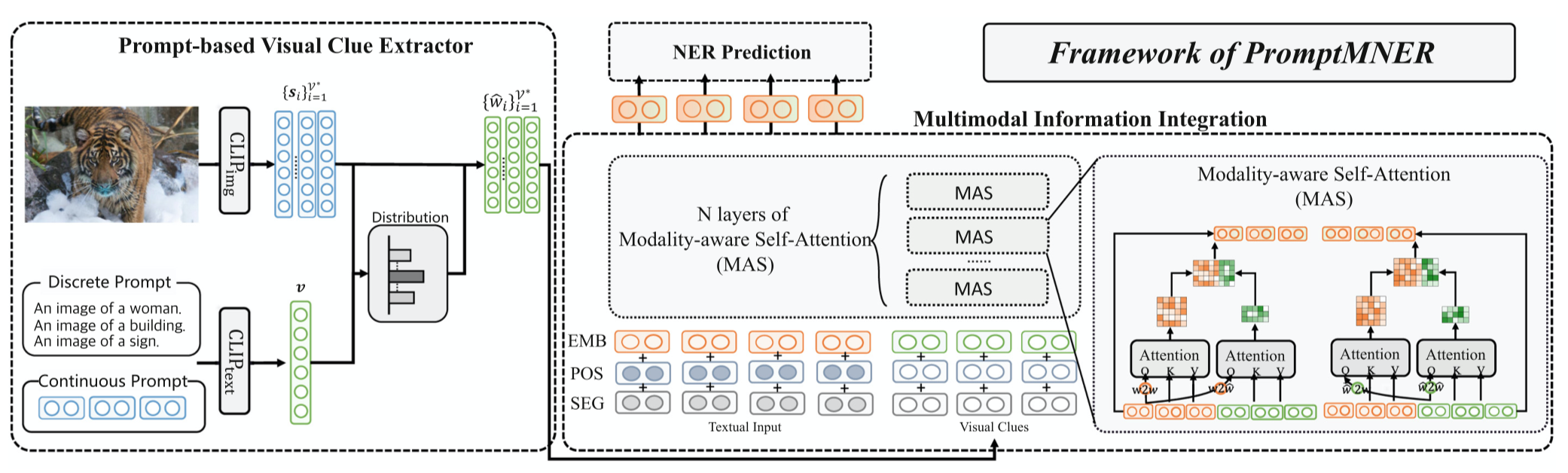
作者定义的prompt形式是\(P_i = \mbox{an image of }[w_i]\),\(w_i\)可以是discrete的word/phrase,也可以是continuous的embedding。
discrete的\(w_i\)来源如下:
- NER的所有实体标签,如person, location, organization
- 从Related Words中和实体标签相关的词,如person的关联词有people, someone, individual, worker, child
- 专家定义的实体标签,如person的人工定义的词有player, pants, hat, suit, group of people, team
因为想要找到所有合适的word描述图像内容是不实际的,因此作者也是用了continuous prompts作为补充,也就是定义没有现实意义的embedding直接作为\(w_i\)。作者发现定义100个continuous prompt达到了最好的效果。
为了确定哪个prompt是最好的描述了图像信息,作者使用CLIP对图像和prompt分别进行编码,然后计算匹配度:

\(<s_i,v>\)是表示余弦相似度。\(s_i\)是\(i\)-th prompt的embedding,\(v\)是图像信息。计算出来的匹配程度与prompt embedding相乘作为找到的视觉特征:
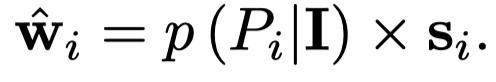
聚合的时候使用了跨模态注意力,这里看图即可,不再赘述。
最后使用基于span的NER分类器:
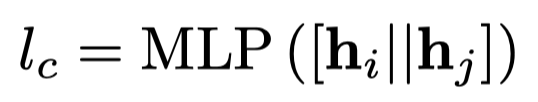
\(i,j\)表示的token \(i\)到token \(j\)的序列,把序列的头尾token embedding拿出来进行分类,\(\{\mbox{person, location, organization, misc, not entity}\}\)。
Experiment
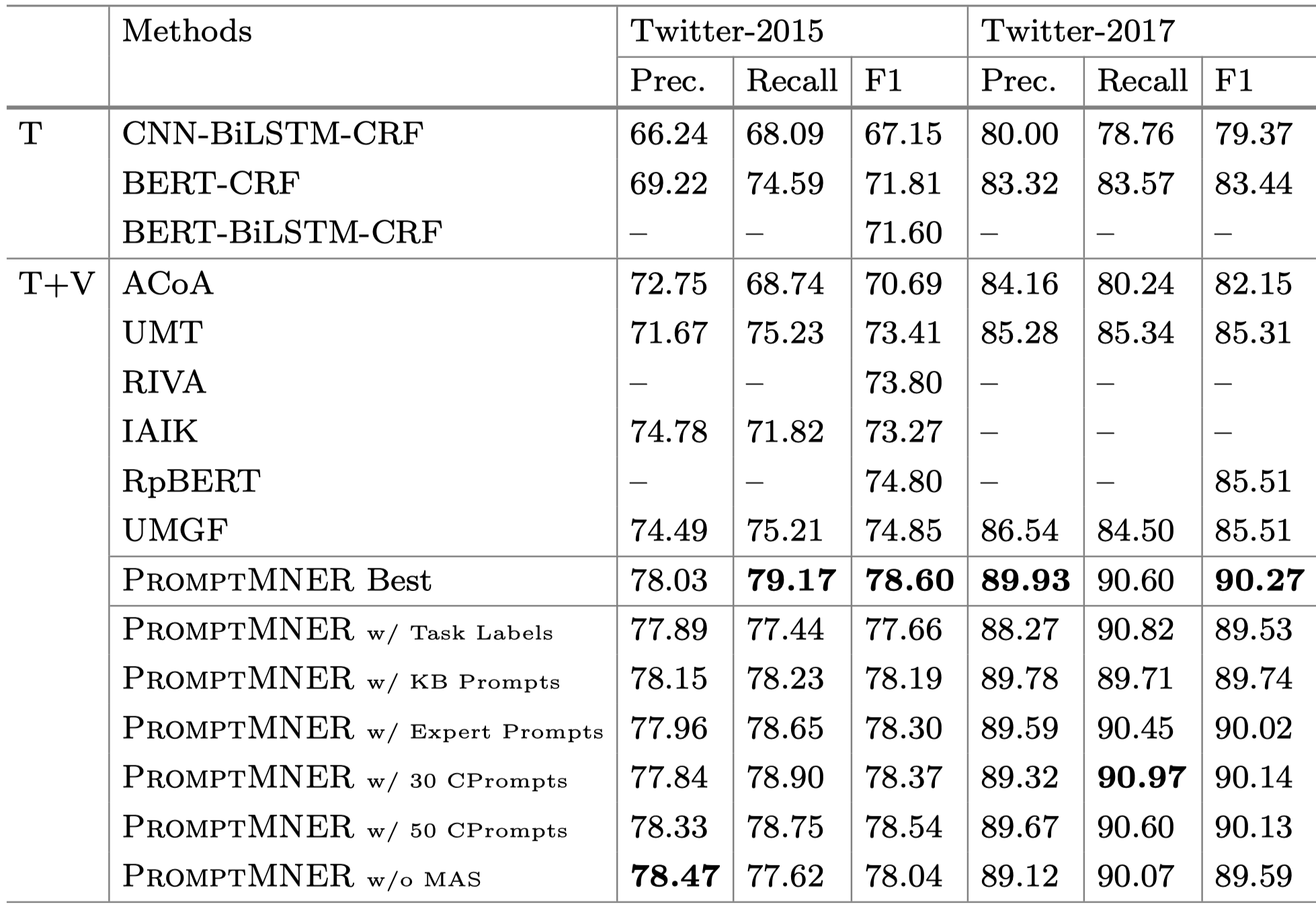
效果上来看还是可以的。