MoRe
Named Entity and Relation Extraction with Multi-Modal Retrieval
作者通过text和image检索在Wikipedia上相关的text信息来辅助多模态信息抽取。
上海科技与阿里达摩,EMNLP 2022,代码。
Multi-modal named entity recognition (NER) and relation extraction (RE) aim to leverage relevant image information to improve the performance of NER and RE. Most existing efforts largely focused on directly extracting potentially useful information from images (such as pixel-level features, identified objects, and associated captions). However, such extraction processes may not be knowledge aware, resulting in information that may not be highly relevant. In this paper, we propose a novel Multi-modal Retrieval based framework (MoRe). MoRe contains a text retrieval module and an imagebased retrieval module, which retrieve related knowledge of the input text and image in the knowledge corpus respectively. Next, the retrieval results are sent to the textual and visual models respectively for predictions. Finally, a Mixture of Experts (MoE) module combines the predictions from the two models to make the final decision. Our experiments show that both our textual model and visual model can achieve state-of-the-art performance on four multi-modal NER datasets and one multimodal RE dataset. With MoE, the model performance can be further improved and our analysis demonstrates the benefits of integrating both textual and visual cues for such tasks.
Method
作者的方法图:
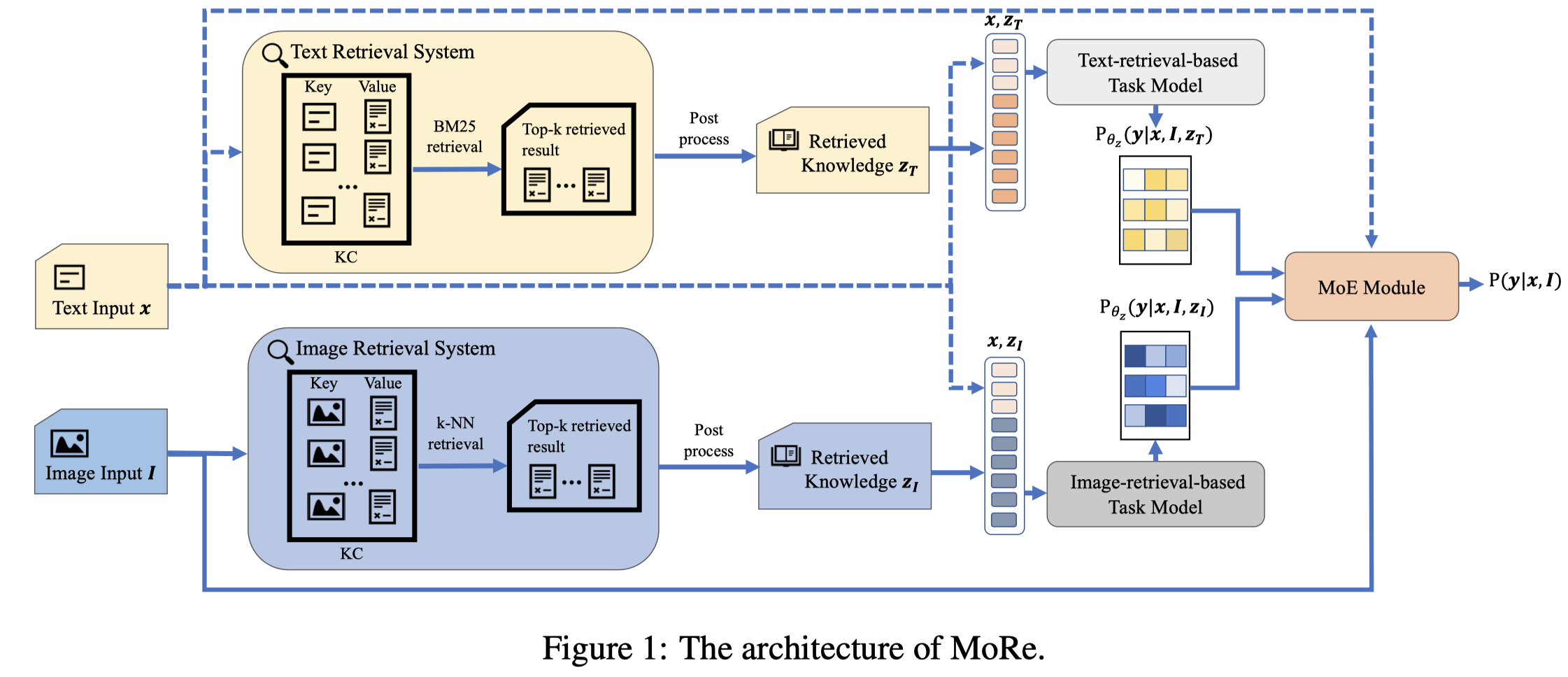
作者从English Wikipedia dump中分别以text和image作为关键进行检索:
具体来说:
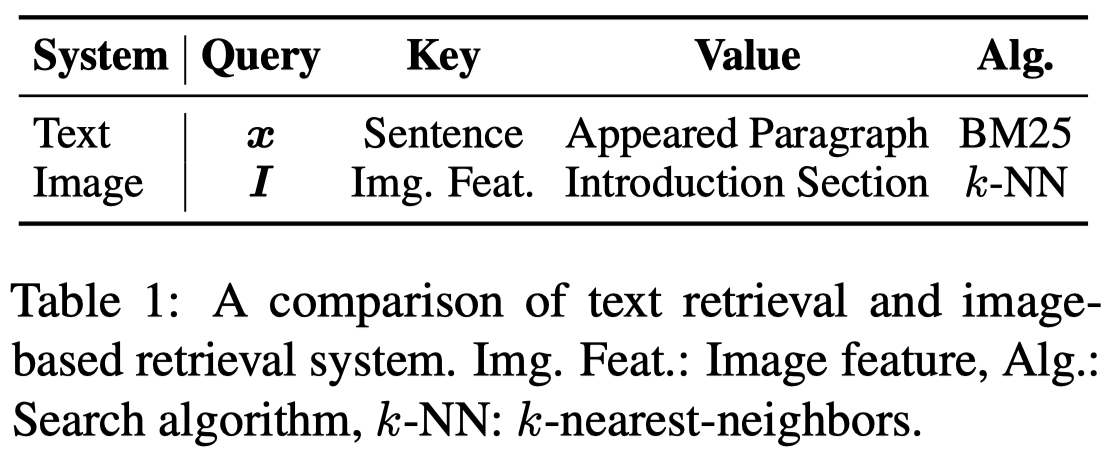
- Textual Retrieval System:待抽取text作为query,使用ElasticSearch,基于BM25算法检索Wikipedia中语义相似的句子(key),然后把包含句子的paragraph返回(value)作为检索结果。
- Image-base Retrieval System:使用ViTB/32 in CLIP将待抽取image和Wikipedia article中的images都编码为vector,然后基于k-NN算法,使用Faiss进行高效搜索。把检索到的article的introduction section返回未做检索结果。
分别检索到top-K(实验中\(K=10\))的结果之后,检索到的结果与原有的待抽取text拼接,分别经过独立的task model输出对于实体或者关系的预测结果。NER任务使用CRF decoder,RE任务使用简单的线性softmax。task model在实验中是XLM-RoBERTa large。
对于两个prediction distributions,作者使用MoE进行混合:
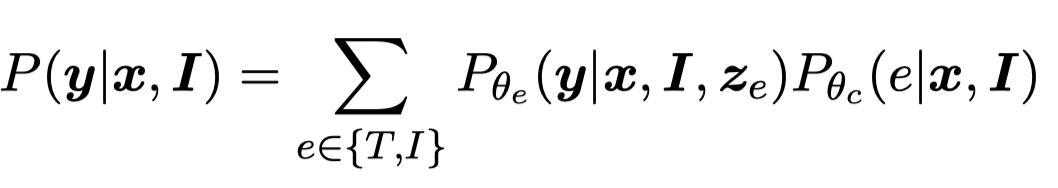
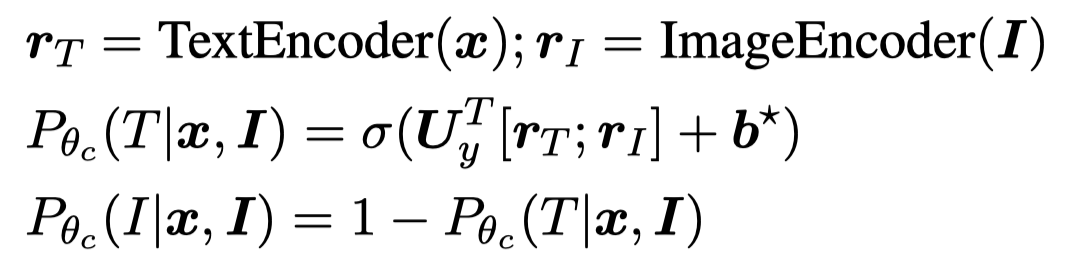
这里的MoE是计算两个prediction distributions的对应权重,然后进行混合。对于NER任务,由于CRF将NER看做是序列标注预测,对应可能的序列集合范围很大。因此作者使用了自己之前在CLNER工作中的方法,将序列标注预测转变为认为不同位置的NER label是互相独立的:
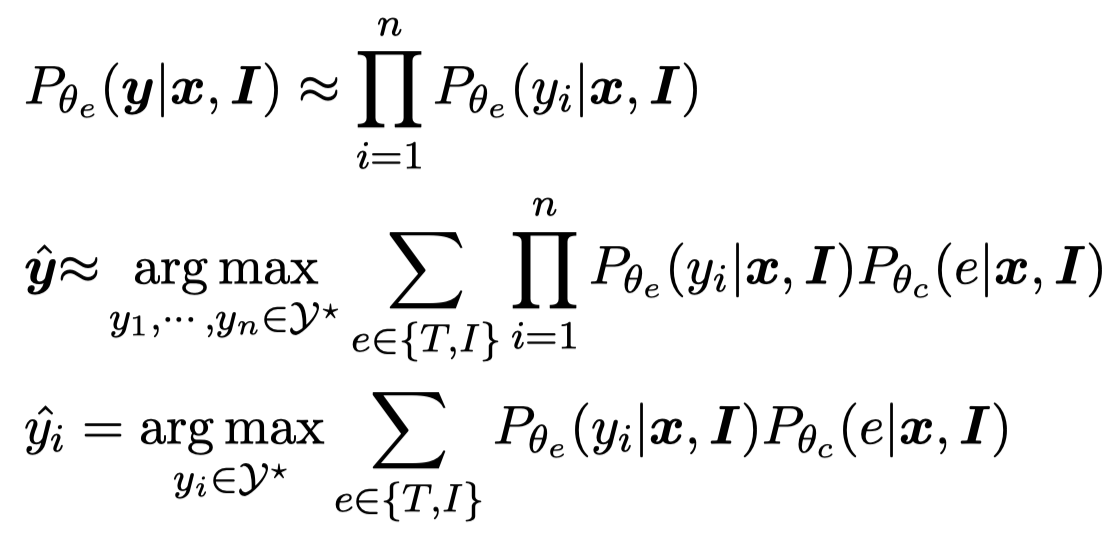
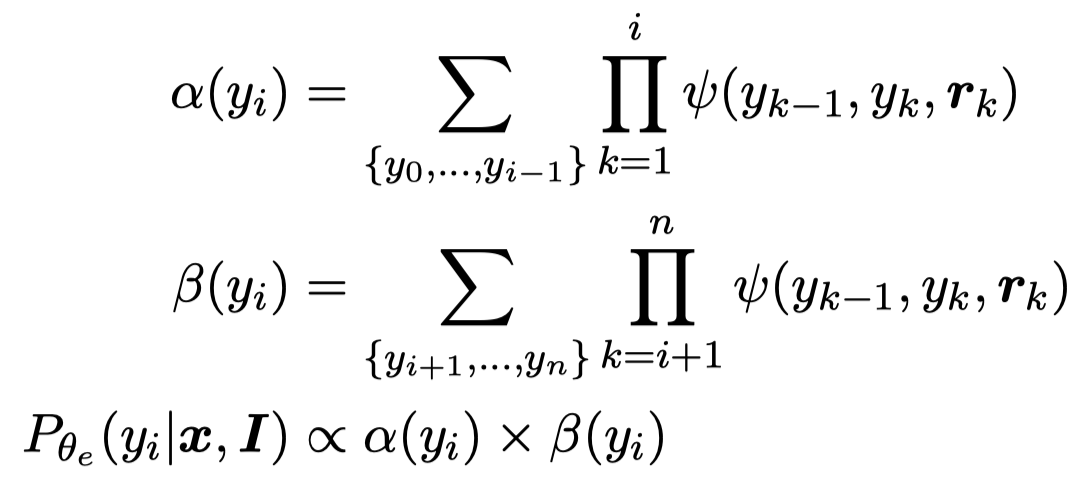
这样最后预测就是让每一个位置上的token的NER label概率最大,而不是让所有token的NER label组合序列的概率最大。
Experiment
主要实验结果:
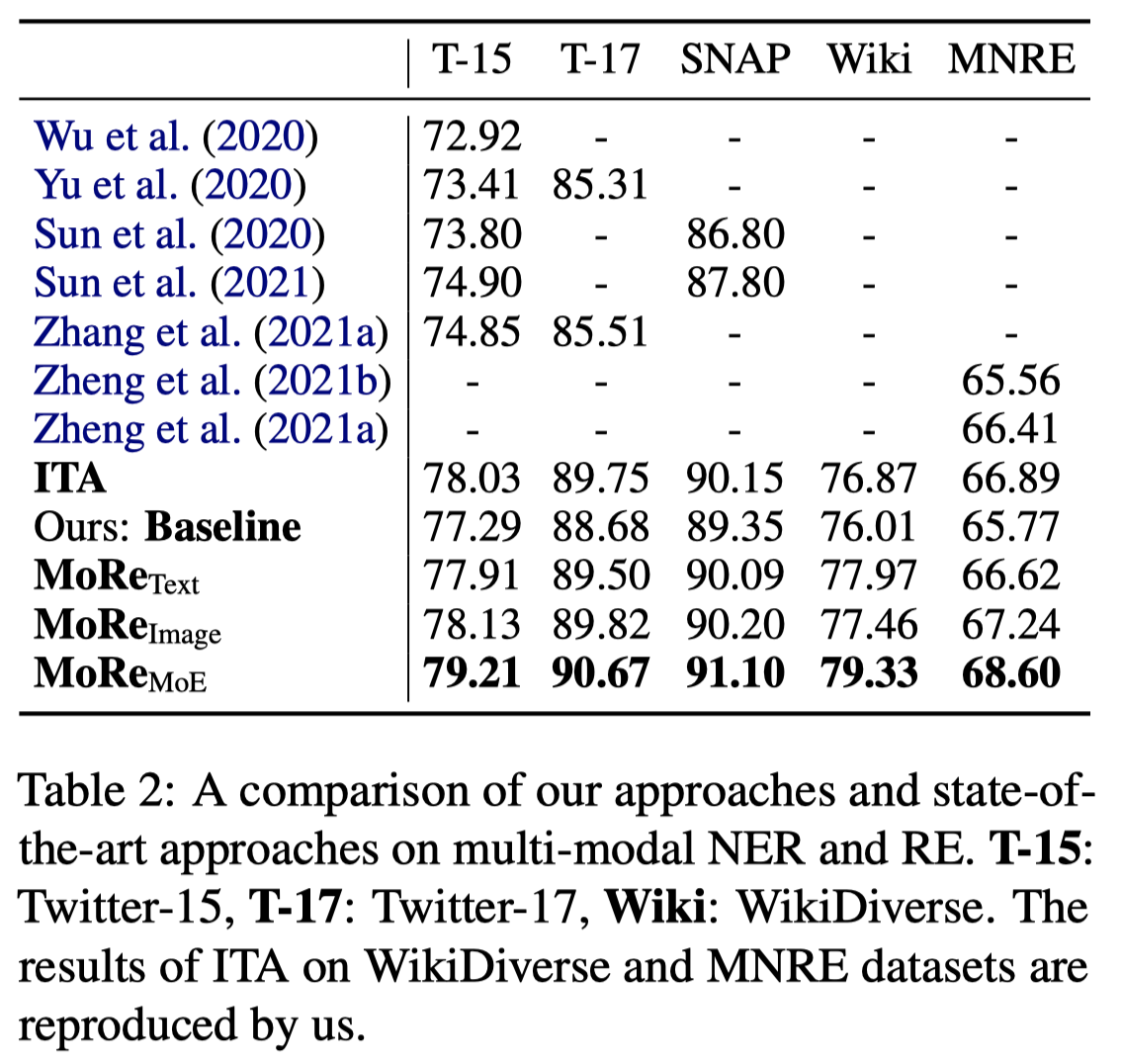
可以看到,如果仅仅是只使用text或image检索,大概带来了1%的提升。通过使用MoE将效果提升到了2%。但是总的效果来看还比不上目前直接使用multimodal representation进行prediction的方法,特别是在MNRE数据集上。
作者MNER任务除了使用最常用的Twitter2015和Twitter2017数据集外,还将WikiDiverse这个multimodal entity linking数据集中对于实体的标注导出来进行预测,这样除了可以对social media domain进行评估外,还可以对News domain进行评估。
The WikiDiverse dataset is a very recent multi-modal entity linking dataset constructed by Wang et al. (2022d) based on Wikinews. The dataset has annotations of entity spans and entity labels. We convert the multi-modal entity linking dataset into a multi-modal NER dataset to further show the effectiveness of MoRe on the news domain.