MNRE-dataset
MNRE: A Challenge Multimodal Dataset for Neural Relation Extraction with Visual Evidence in Social Media Posts
MNRE,ICME 2021。作者创建了首个用于multimodal relation extraction的数据集MNRE,地址。
数据来源于Twitter posts,关注点是文本中的上下文信息不够充分时,通过post中的image,来补充上下文信息。
Extracting relations in social media posts is challenging when sentences lack of contexts. However, images related to these sentences can supplement such missing contexts and help to identify relations precisely. To this end, we present a multimodal neural relation extraction dataset (MNRE), consisting of 10000+ sentences on 31 relations derived from Twitter and annotated by crowdworkers. The subject and object entities are recognized by a pretrained NER tool and then filtered by crowdworkers. All the relations are identified manually. One sentence is tagged with one related image. We develop a multimodal relation extraction baseline model and the experimental results show that introducing multimodal information improves relation extraction performance in social media texts. Still, our detailed analysis points out the difficulties of aligning relations in texts and images, which can be addressed for future research. All details and resources about the dataset and baselines are released on https://github.com/thecharm/MNRE.
1. Introduction
relation extraction(RE)是预测一个句子中两个命名实体之间的关系relation。
challenges:之前大多数的RE模型关注的是文本信息很充分的场景下的关系抽取,比如newswire domain。但是,一旦文本很短,并且缺少必要的上下文信息的时候,RE模型效果会出现严重的下降。即便是使用了pretrained modal来进行关系抽取,效果也很糟糕。
solution: 作者认为,对于在推特post这样很可能文本中缺乏足够充分的上下文信息的场景,可以使用image的visual information来补充上下文信息。
比如在下面的图中,如果只有文本,那么可能会判断出来JFK和Obama和Harvard的关系是residence;但是如果能够识别图像中的信息,比如校园、学位帽等,可以判断出来JFK和Obama和Harvard的关系应该是graduated_at。

但是目前并没有这样满足文本+图像的数据集存在,因此作者就希望能够解决这一点,主要贡献如下:
- 创建了在社交媒体posts上的数据集Multimodal dataset for Neural Relation Extraction(MNRE)
- 在MNRE数据集基础上,构建了几个不同的baseline方法
2. MNRE Dataset
2.1 Dataset Collection
数据来源有三个:
- Twitter 2015:有8357个候选实例(指一个完整的post和对应image、named entities和relations)
- Twitter 2017:有4819个候选实例
- Crawled Twitter data:爬取了Twitter 2019年1月到2月的post和对应图片,不限制具体的领域;如果一个post有多张图片,就随机选择一张。最终获取了20000候选实例
2.2 Twitter Name Tagging
使用预训练的NER tagging tool在爬取的Twitter data上标注实体和对应的实体类型entity type。
大多数的RE数据集没有对应的实体类型标注;但是作者认为实体类型是很重要的。
2.3 Human Annotation
众包。让4个受到过良好教育的标注者过滤掉错误标注的句子,并且标注实体之间的关系;
每个标注者需要判断是否能够从text和image中判断出对应的relation;同时,需要给选择的relation打confidence score;
最后,汇总4个标注者的标注结果,根据候选relation的总的confidence score来作为标注的relation。
2.4 Dataset Statistics
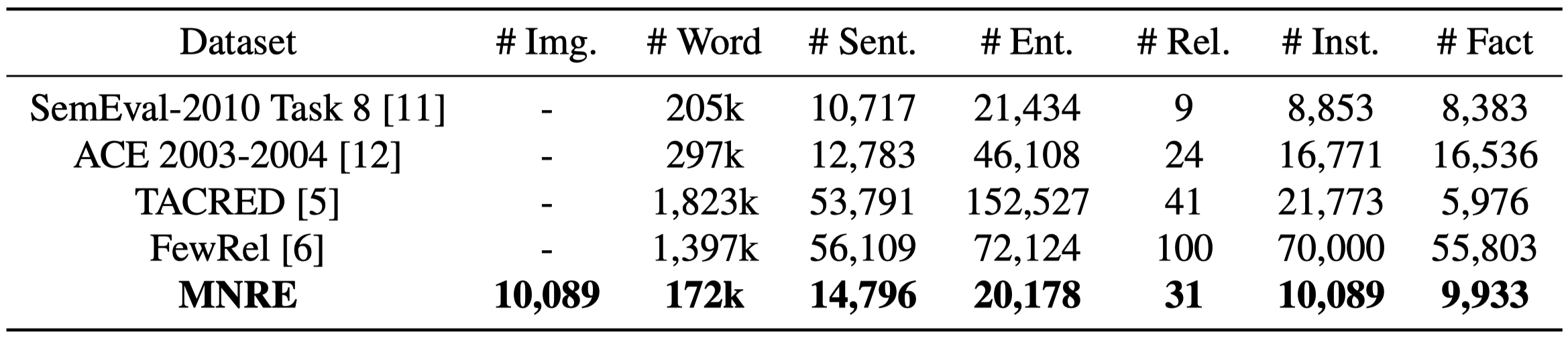
最终包含了10k的实例,31种关系;平均句子的长度是11.62,远远小于之前文本上下文信息丰富的RE数据集中的句子平均长度。 作者在后续更新了数据集,得到了MNRE-2:
2021.6.22 We provide MNRE-2, a refined version which merges several ambigious categories with much more support samples. The original version has been moved to Version-1
MNRE-2的统计: 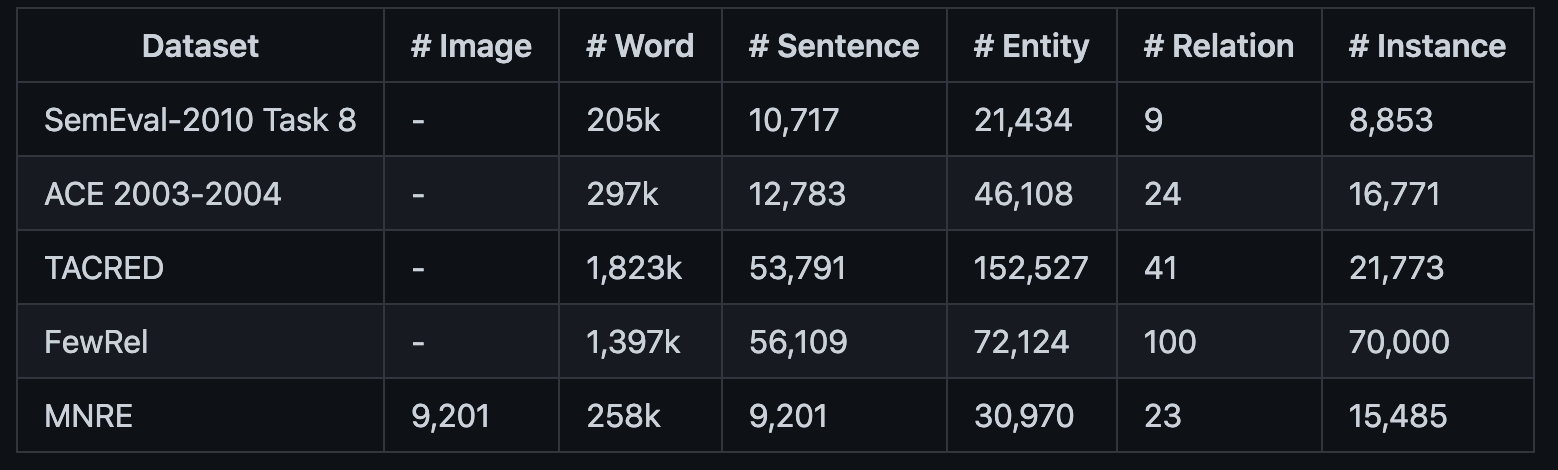
下图是不同关系类型的统计:
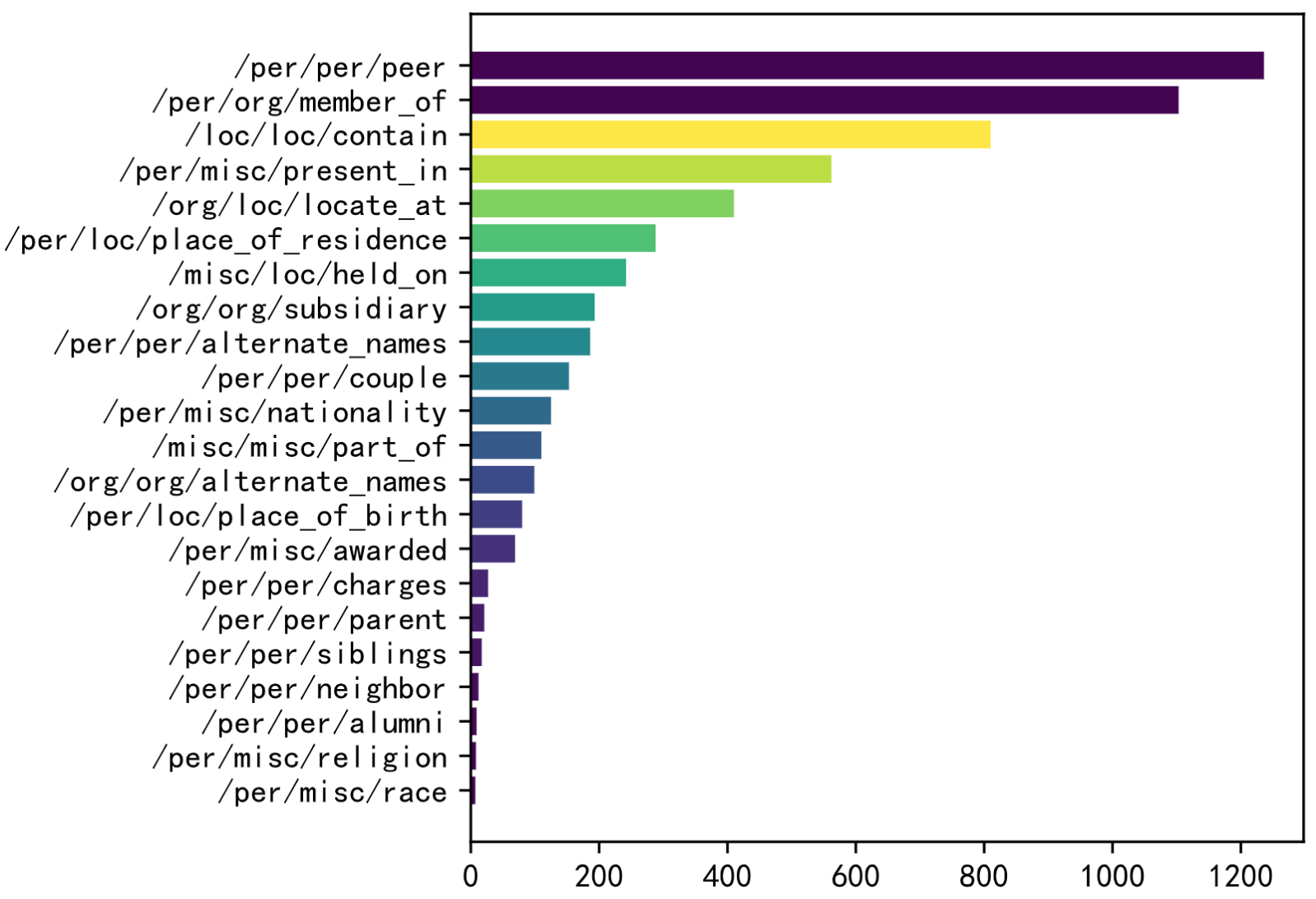
经过检查发现,实际的训练集还包括了关系None。上面的统计图没有展现出None关系的分布。
作者的MNRE-2数据集从32变为了23种关系,发现大部分的关系还是和人相关的。MNRE-2训练集有12247、验证集1624和测试集1614实例。
查看下具体的数据集内容,在一个训练实例中,包括
token:['The', 'latest', 'Arkham', 'Horror', 'LCG', 'deluxe', 'expansion', 'the', 'Circle', 'Undone', 'has', 'been', 'released', ':']h:{'name': 'Circle Undone', 'pos': [8, 10]}t:{'name': 'Arkham Horror LCG', 'pos': [2, 5]},这个Arkham Horror LCG应该是一种卡牌游戏img_id:'twitter_19_31_16_6.jpg',所有的图片下载完后是1.2GB,下图是对应的图片
relation:/misc/misc/part_of

上图是数据集中的实例。可以看到,需要同时结合视觉和文本信息,才能够做出准确的关系预测。
3. Experimental Results
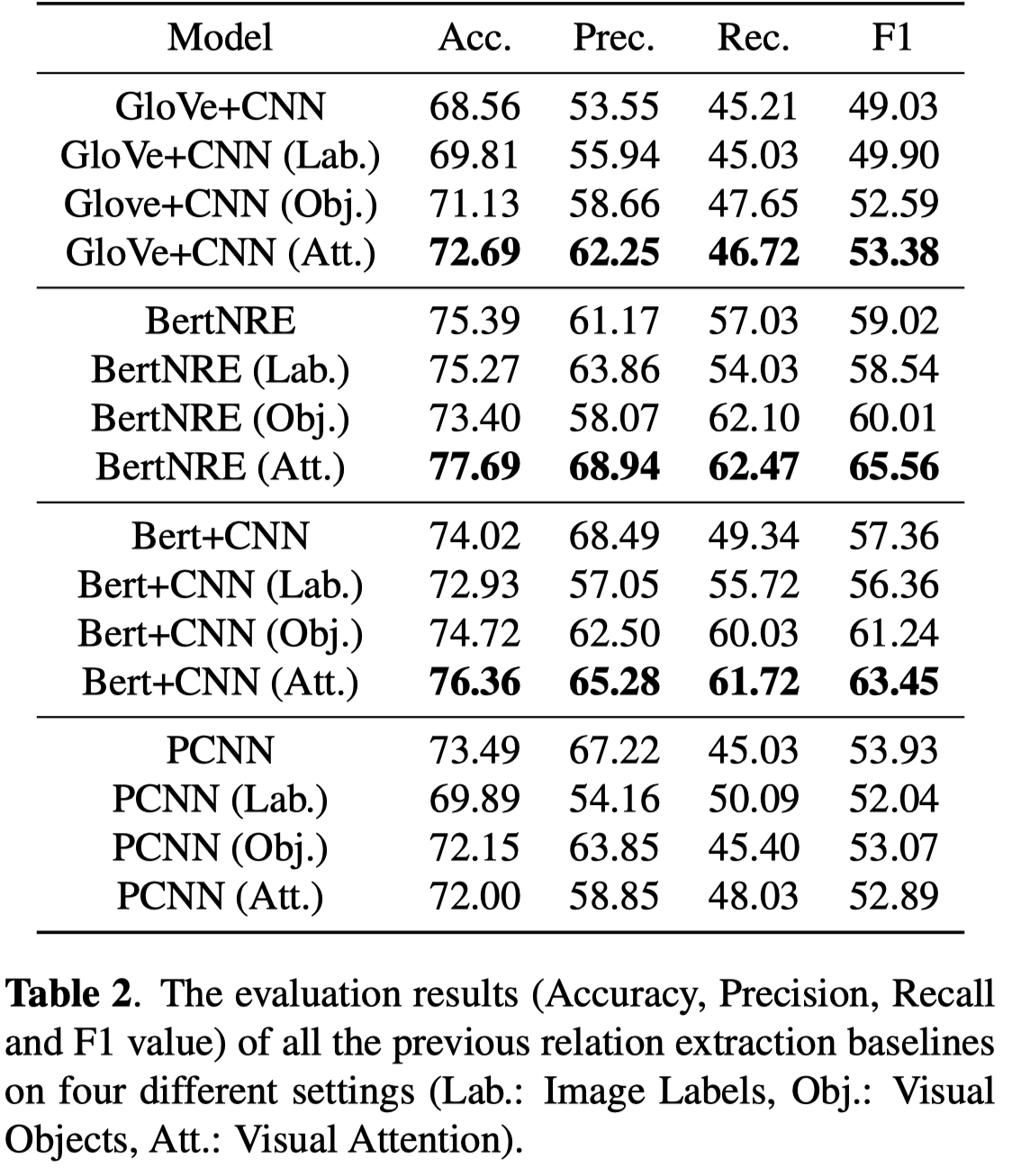
作者试验了几个已有的方法,Glove+CNN、BertNRE、Bert+CNN、PCNN。并且尝试了几种加入视觉信息的方法,包括拼接image label的embedding、拼接通过一个pretrained object detector导出的视觉特征embedding和利用visual-text的bi-linear注意力层。
实验结果:
几个需要引入视觉信息,才能实现正确预测relation的实例:

Thoughts
感觉每个post对应一个image,然后单纯的从图像中抽取视觉信息来辅助关系抽取,所能够获得信息和覆盖范围还是比较受限。可能更理想的还是要有多张图片,从多张关联图片中进行信息抽取;或者说要从单个图片出发,进行信息拓展(图片搜索,寻找更多的相似/关联图片?图片进行场景识别后,转化为text,然后再从文本信息出发进行搜索?)
另外的一个问题是,如果随机检查图像信息和对应的文本,发现有不少的实例还是可能不需要图像信息就能够预测关系的,比如:
token:['(', 'UPDATE', 'CHARA', ')', 'Baejoohyunews', ':', '[', 'PHOTO', ']', '190130', '#', "REDVELVET'REDMARE", ':', 'Japan', 'Arena', 'Tour', 'in', 'Yokohama', "'", 'Day2', 'RVsmtown']h:{'name': 'Japan Arena Tour', 'pos': [13, 16]}t:{'name': 'Yokohama', 'pos': [17, 18]}img_id:twitter_19_31_9_14.jpgrelation:/misc/loc/held_on
实际上通过文本中的单词
in就能够判断出来关系可能是held_on