MMKG-survey-fudan
Multi-Modal Knowledge Graph Construction and Application: A Survey
复旦大学计算机系在2022年出的关于MMKG的综述,主要针对图片和语言组成的MMKG,从construction和application两个方面进行描述。
Recent years have witnessed the resurgence of knowledge engineering which is featured by the fast growth of knowledge graphs. However, most of existing knowledge graphs are represented with pure symbols, which hurts the machine’s capability to understand the real world. The multi-modalization of knowledge graphs is an inevitable key step towards the realization of human-level machine intelligence. The results of this endeavor are Multi-modal Knowledge Graphs (MMKGs). In this survey on MMKGs constructed by texts and images, we first give definitions of MMKGs, followed with the preliminaries on multi-modal tasks and techniques. We then systematically review the challenges, progresses and opportunities on the construction and application of MMKGs respectively, with detailed analyses of the strength and weakness of different solutions. We finalize this survey with open research problems relevant to MMKGs.
1 Introduction
首先我们已经拥有了很多不同领域的知识图谱:
- 常识知识图谱common sense knowledge:Cyc, ConceptNet
- 语言知识图谱lexical knowledge:WordNet, BabelNet
- 百科式知识图谱encyclopedia knowledge:Freebase, DBpedia, YAGO , WikiData, CN-Dbpedia
- 分类学知识图谱taxonomic knowledge:Probase
- 地理知识图谱geographic knowledge:GeoNames
但是大多数这些KG仅仅是用纯符号pure symbols表示的,这实际上很大程度限制了机器描述和理解现实世界的能力。单纯的符号表达的信息不够充分。比如dog这个词,我们知道现实的狗拥有远比dog这个单词表达含义丰富的信息。因此我们需要把symbolic链接到non-symbolic experiences。
it is necessary to ground symbols to corresponding images, sound and video data and map symbols to their corresponding referents with meanings in the physical world, enabling machines to generate similar “experiences” like a real human [12].
从另外的方面讲,很多的应用比如关系抽取、视觉问答等任务都需要知识图谱拥有更多模态信息去进行推理。
2 Definitions and Preliminaries
在这个survey中,作者把KG的属性attribute和关系relation做了区分,虽然都是三元组形式。作者使用谓词predicate同时描述属性和关系。
作者把现存的主要的MMKG分为了两类:A-MMKG和N-MMKG(没搞懂为什么简称N)
A-MMKG:multimodal data (images in this survey) as particular attribute values of entities or concepts. 指image仅仅是作为实体的一个属性存在,image之间不存在更多的语义联系。举例如下图:
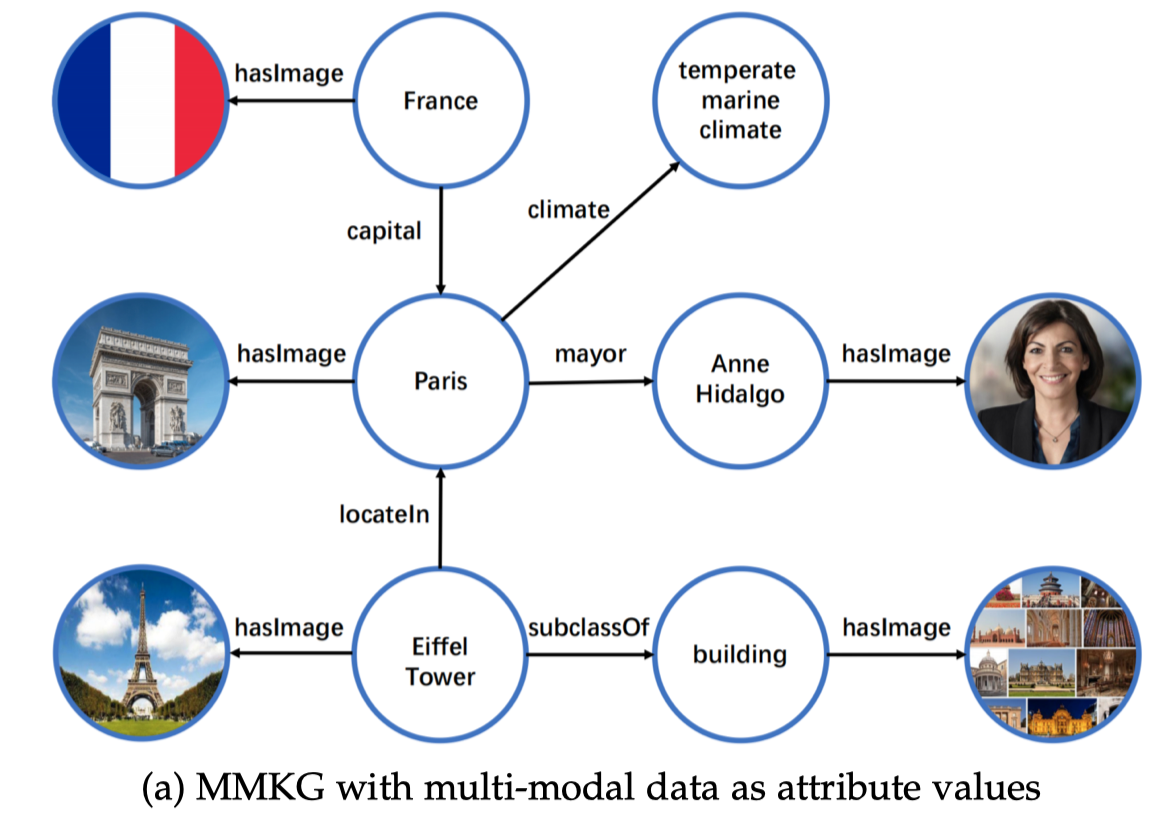
N-MMKG:multi-modal data as entities in KGs. image作为新的实体,因此image之间存在互相的语义联系。举例如下:
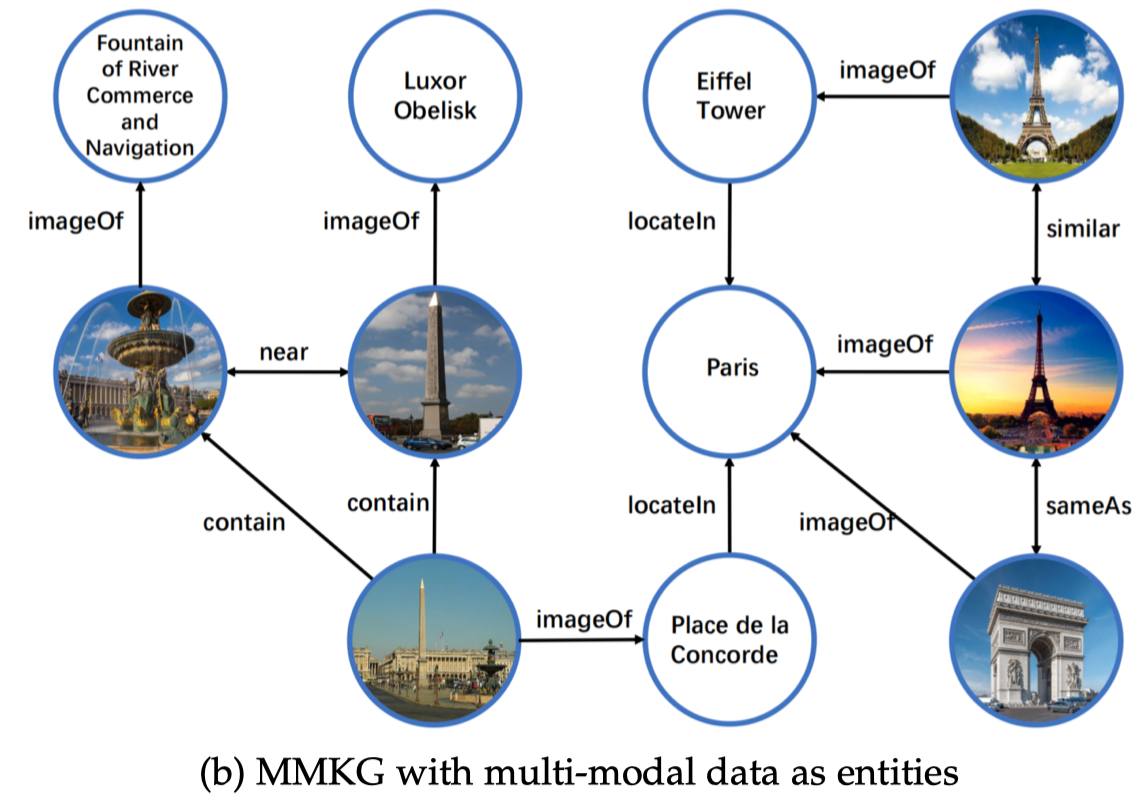
对于N-MMKG来说,不同image之间可以存在关系:

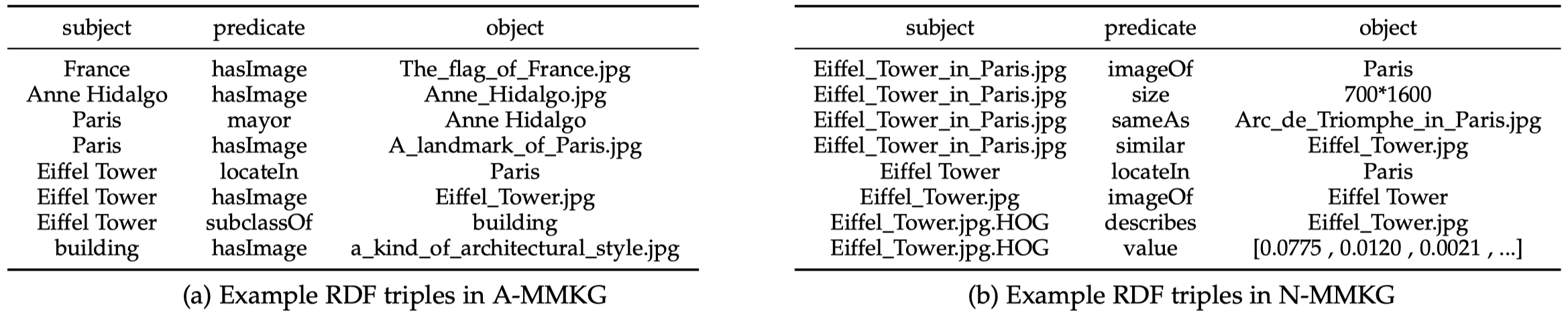
除此之外,在N-MMKG当中对于image还常常会保存它的一些简要的image descriptors,比如Gray Histogram Descriptor (GHD)、Histogram of Oriented Gradients Descriptor (HOG)、Color Layout Descriptor (CLD)等。下面是A-MMKG和N-MMKG中对于image是如何表示的示例:
目前在各个multimodal tasks领域内都已经有很大的进展,但是引入MMKG可以进一步带来更多的好处:
- MMKG provides sufficient background knowledge to enrich the representation of entities and concepts, especially for the long-tail ones. (Knowledge aware semantic concept expansion for image-text matching. IJCAI 2019)
- MMKG enables the understanding of unseen objects in images. (Describing natural images containing novel objects with knowledge guided assitance. arXiv 2017)
- MMKG enables multi-modal reasoning. (Okvqa: A visual question answering benchmark requiring external knowledge. IEEE Conference on Computer Vision and Pattern Recognition 2019)
- MMKG usually provides multi-modal data as additional features to bridge the information gaps in some NLP tasks. (Adaptive co-attention network for named entity recognition in tweets. AAAI 2018)
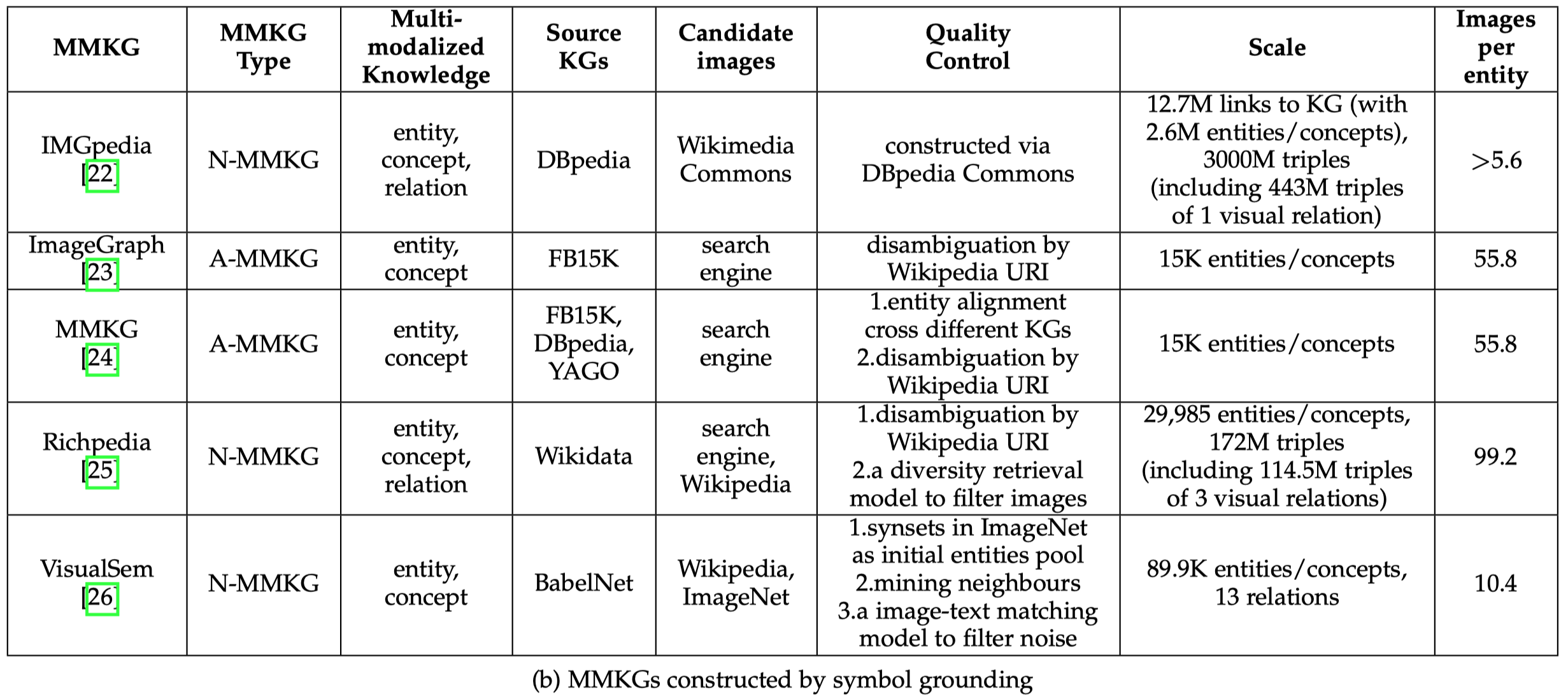
下面的图是目前几个主流的MMKG:
3 Construction
构造MMKG的关键是能够把原始KG中的symbolic knowledge关联到对应的image。有两种不同方向的方法,一个是从image出发,把image关联到symbols上;一个是从symbols出发,关联到相应的image。
3.1 From Images to Symbols: Labeling Images
在CV界已经出现了很多的image labeling方法,正好使用与把images和KG中的symbols关联起来。下面是几个有名的image-based的visual knowledge extraction系统:
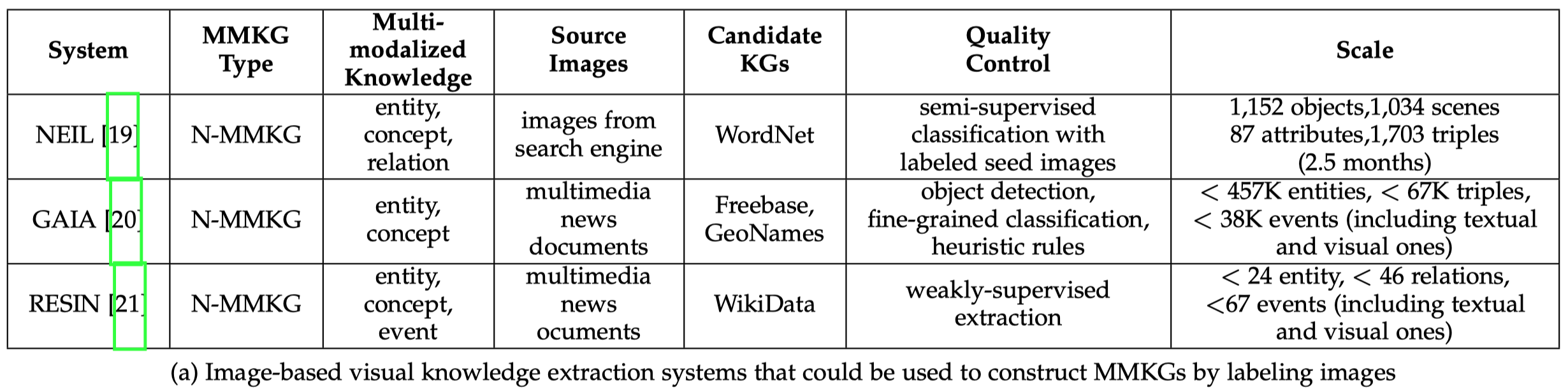
From Images to Symbols,把图片和符号对应起来,隐含的假设是我已经拥有了一大堆相关图片,并不需要额外去寻找。这个或许适用于某个特定的项目里,我拥有了项目相关的很多图片,这些图片的领域性非常强,在外界很难找得到,也不需要继续寻找了。那么接下来我要做的就是把图片对应到文字上。
根据导出的knowledge的不同,可以分为visual entity/concept extraction、visual relation extraction和visual event extraction。下面先介绍视觉实体导出。
3.1.1 Visual Entity/Concept Extraction
Visual entity (or concept) extraction aims to detect and locate target visual objects in images, and then label these objects with entity (or concept) symbols in KG.
先识别image上的不同object,然后再关联到KG的实体上。
Challenges. 这一task面临的最大挑战是有合适的标注数据集。一般的CV数据集对于KG来说粒度太粗,entity表现在image上可能是更小的区域/单元。
这一方向的方法主要可分为两类:object recognition方法和visual grounding方法。前者是通过识别image上的object;后者是通过把caption中的phrase对应到image上最相关的区域。
Object Recognition Methods
基于object recognition的方法首先通过提前训练好多个不同的目标探测器,让这些目标探测器到图像上分别探测不同的objects;之后由于可能对于同一实体,会产生多个不同的探测出来的objects(比如由于位置、姿势等不同很多探测出来的objects实际上指的是同一个entity)。因此通常又会使用聚类的办法找出最具代表性的object作为visual entity。
基于object recognition的方法是有监督的方法,它需要大量具有bounding box的image数据,提前训练好的多个探测器以及提前定义好的可以获取的实体/概念。因此,它实际上很难应付具有大量实体的KG,比如拥有数十亿实体的KG。(试想一下对于每个实体都需要训练一个探测器并且准备好数据集)
Visual Grounding Methods
接下来,更加实际的采取visual grounding的方法,我们需要一种方法能够同时识别出大量的、不同的objects。首先,从Web(比如新闻网站)上可以较为容易的获得大量的image-caption pairs,接下来我们要做的就是把caption中的phrase在image上的对应region找出来。这就是一个弱监督学习问题。
在实现的时候,我们通常会直接找找出在图像中和word对应的pixels:

当前有基于注意力的方法(Gaia: A fine-grained multimedia knowledge extraction system. ACL 2020)和基于重要性的方法(Cross-media structured common space for multimedia event extraction. ArXiv 2020):
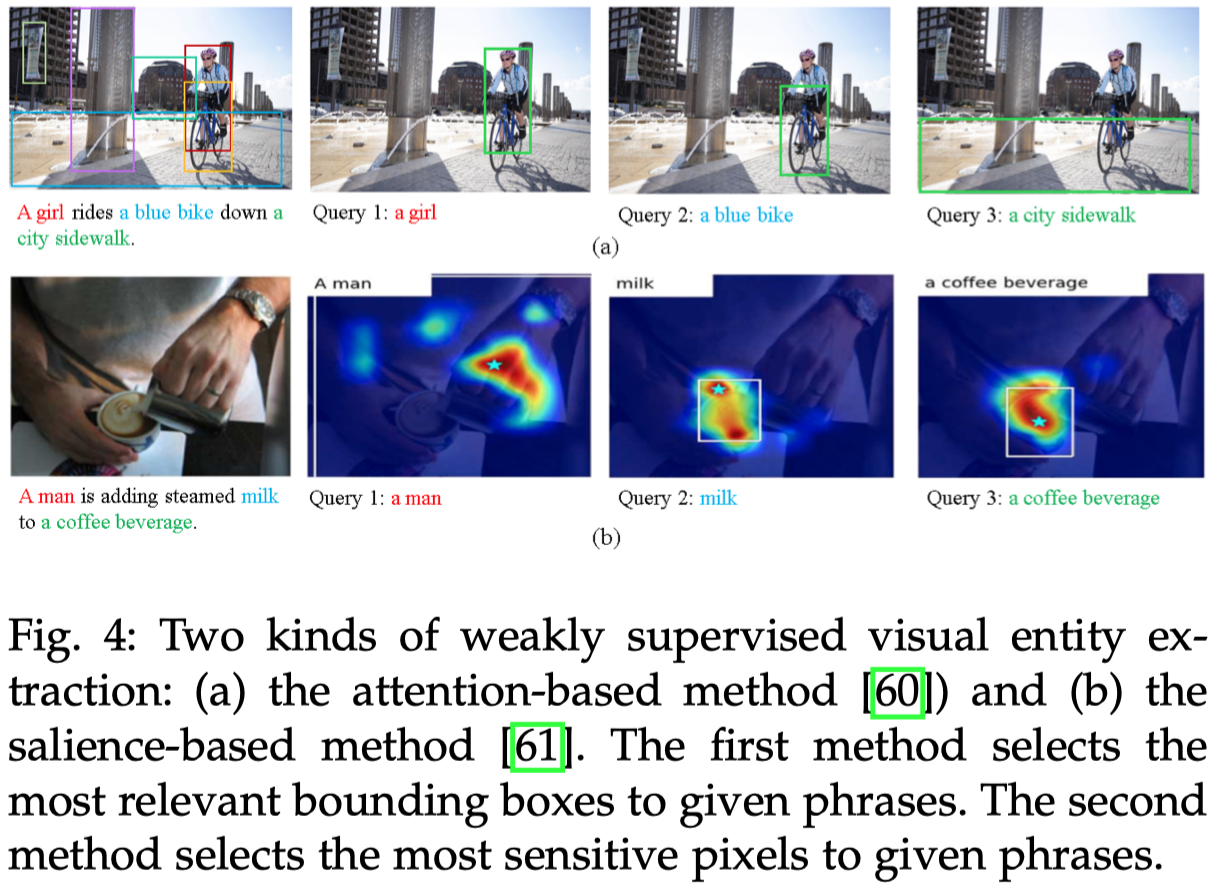
尽管visual grounding方法不再需要人工画bounding boxes,但是由于可能存在错误匹配的情况,所以仍然需要辅助人工验证。比如visual grounding出来的visual entities可能在语义层次上是不一致的,例如troops可能会匹配到一个有几个人穿着军队服装的images上;Ukraine (country)可能会匹配到一个乌克兰国旗的图片上。尽管它们都是有关联的,但是并不等价,我们不能直接进行把图片和实体关联到一起。
Opportunities. 另外,作者提出基于预训练的language model已经表现出了很强的visual object segmentation能力,利用这样的模型或许可以很大程度地减轻标注visual objects的工作量,从而辅助构造MMKG。下面是ViLT的实例:

3.1.2 Visual Relation Extraction
视觉关系抽取的定义:
Visual relation extraction aims at identifying semantic relations among detected visual entities (or concepts) in images, and then labeling them with the relations in KGs. (Neil: Extracting visual knowledge from web data. ICCV 2016)
Challenges. 在CV界对于探测到的objects的关系探测已经有了很多的研究。但是原来CV中对一个图片上的objects关系的推测都是很简单的,语义层级较弱,不能用在KG里。比如CV方法预测的是(person, standing on, beach),构建MMKG需要更general的semantic relations。
现有的方法主流是两种:rule-based relation extraction和statistic-based relation extraction。除此之外,也有一些研究关注long-tail relation和fine-grained relation。
Rule-based Relation Extraction
基于规则的关系导出方法需要人工定义好标准。比如通过识别出来的objects的label和它们的bounding box之前的相对位置,可以推测它们之间的可能的relation。比如在NEIL方法中探测出来的关系类型(Neil: Extracting visual knowledge from web data. ICCV 2016):
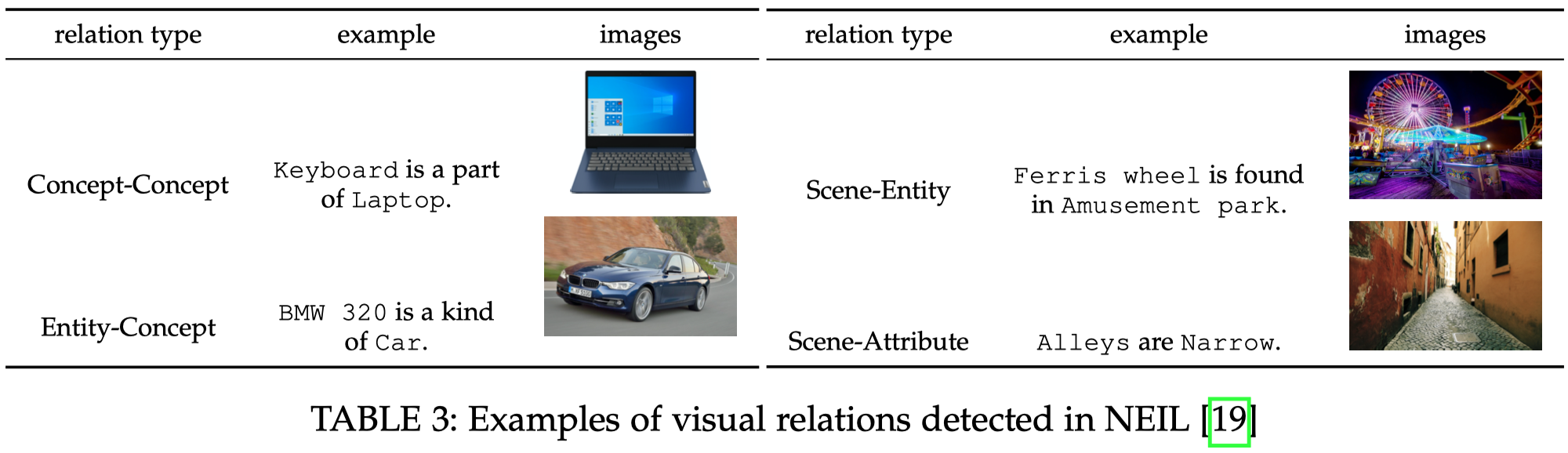
比如一个探测到的wheel对象的bounding box总是包含在car对象的bounding box里,结合wheel属于entity,car属于concept,依据定义好的rules,我们推测wheel和car的relation是\(kind\ of\)。
这种做法准确度比较高,但是需要大量人工,不适应大规模MMKG。
Statistic-based General Relation Extraction
基于统计的关系导出方法就是通过编码特征,然后通过分类模型预测relation。比起基于规则的关系导出,这种做法更”自动“,也更”黑“。
一些研究发现,预测关系是非常依赖于头尾实体的类型的;但是实体并不依赖于关系的类型(Neural motifs: Scene graph parsing with global context. CVPR 2018)。那么就有研究尝试把language model的先验知识加到objects的label中,从而提高关系预测性能(Visual relationship detection with language priors. ECCV 2016., Visual translation embedding network for visual relation detection. CVPR 2017)。
另外,也有研究工作尝试建模探测到的objects之间的graph structure信息(Scene graph generation by iterative message passing. CVPR 2017,Graph r-cnn for scene graph generation. ECCV 2018)。
Long-tail and Fine-grained Relation Extraction
Long-tail relations:关系导出中,由于不同relation对应的sample数量是非常悬殊的,因此可能导致模型倾向于预测有更多sample数量的relation。为了解决这一问题,[Learning to compose dynamic tree structures for visual contexts. CVPR 2019]提出了一个新的评估指标,先计算出每个relation的指标,然后再平均,这样long-tail relation能预测效果就能够在指标上得到体现。还有基于对比学习(Large-scale visual relationship understanding. AAAI 2019)、少次学习(One-shot learning for long-tail visual relation detection。 AAAI 2020)和迁移学习的方法(Memory-based network for scene graph with unbalanced relations. ACM-MM 2020)。
Fine-grained Relation:fine-grained relation是long-tail relations的一种。研究者认为很多的预测long-tail relation的方法实际上不能更进一步分辨fine-grained relation。比如关系\(on\)可以被长尾分布方法预测出来,但是关系\(on/sit,\ on/walk,\ on/lay\)就没法区分出来了(Unbiased scene graph generation from biased training. CVPR 2020)。
Opportunities. 作者提出了这一方向存在的两个挑战。(1)Visual Knowledge Relation Judgement. 第一个问题是识别出来的visual triples不能够直接作为visual knowledge使用,特别是很多的visual triples仅仅是对于images场景的描述。(2)Relation Detection based on Reasoning. 第二个问题是对于关系的预测缺乏推理过程,我们需要能够自动总结这样的推理链。
3.1.3 Visual Event Extraction
在一般的,基于文本的事件图谱构建过程中,对于事件(event)的探测,核心有两步,一是通过发现关键的触发词(trigger)判断事件的类型;二是判断在这个时间中的关键元素(argument)并判断它们的角色(argument role),比如时间/地点/任务。
事件图谱和事理图谱有所区别,经过调研,事理图谱是哈工大社会计算与信息检索研究中心提出的,可参考[事理图谱,下一代知识图谱]进一步进行了解。事件图谱更多是事理图谱的一个初级阶段,不包含本体。
Challenges. 作者认为这一领域的挑战包括:(1)通常事件的抽取需要提前定义好不同事件类型的schema,不适用大规模事件抽取,如何能够从visual patterns中自动挖掘出事件schema?(2)如何从image/videos中抽取出visual事件元素?
当前visual event extraction工作集中在两方面:visual event schema mining和visual event arguments extraction。
Visual Event Schema Mining
在CV领域有个很相似的任务叫做场景识别(situation recognition task),这个任务会识别一个图片表示的主要事件以及相应的元素,存在几个标注好的数据集,如SituNet(Situation recognition: Visual semantic role labeling for image understanding. CVPR 2016)和SWiG(Grounded situation recognition. ECCV 2020)。
同样的,如果要导出大量的事件,不能够期望人工标注。借助于大量的image-caption pairs,可以辅助进行事件抽取(Improving event extraction via multimodal integration. ACM-MM 2017)。
Visual Event Arguments Extraction
事件元素的抽取就是对相关事件的images,识别不同argument role对应的visual objects。这里需要注意的是,我们需要确保visual arguments之间的关系和text arguments之间的关系是一致的。因此还需要对齐。(Cross-media structured common space for multimedia event extraction. arXiv 2020)
作者提到,实际上对于visual事件的抽取,更加合理且前景广阔的场景是从video中抽取。一个video可能包含了多个不同的事件,单一帧上的事件元素会关联到不同时间帧上的事件元素,因此是一个更加复杂的task。
visual event extraction还是一个在初期阶段的领域。
3.2 From Symbols to Images: Symbol Grounding
Symbol grounding符号定位指的是把传统KG中的元素定位到multimodal data。
Symbol grounding refers to the process of finding proper multi-modal data items such as images to denote a symbol knowledge exists in a traditional KG.
和image到symbol不同,这里我需要自己找对应的图片,因此是symbol到image。
symbol grounding方法是目前主流的MMKG构造方法,大多数见到的MMKG都是使用这种方式构建的。
3.2.1 Entity Grounding
Entity grounding aims to ground entities in KGs to their corresponding multi-modal data such as images, videos and audios. (The symbol grounding problem. 1990)
Challenges. 两个关键问题:(1)如何找到足够数量且高质量的图片?(2)如何选择最符合实体的图片?
两种主要的方法:(1) from online encyclopedia (such as Wikipedia);(2)from the Internet through Web search engines.
From Online Encyclopedia
网上的百科,通常是一篇article描述一个entity。把article里的图片都拿过来,就变成了entity的对应图片了。并且这样的图片通常和实体相关性很高,难度也比较低。下面以维基百科为例说明这种方法可能存在的问题。
但是基于维基百科搭建MMKG存在3个问题:1. 每个实体对应的图像太少,比如在维基百科中,一个实体的平均图片仅有1.16;2. 维基百科中出现的图片和期望的实体仅仅是相关(relevant),而不是确切的指向该实体(exactly refered to),比如北京动物园文章里的图片包括了动物、建筑等,但都不是直接指向北京动物园;3. 使用维基百科搭建的MMKG的覆盖率有限,比如80%的维基百科文章没有图片,只有超过8.6%的文章有超过2张图片,并且维基百科涉及的实体数量也不一定覆盖所有的实体。
From Search Engines
为了提高MMKG的覆盖率,另一种简单有效的方法是直接用搜索引擎寻找相应的图片,然后以排在前面的照片作为候选。这种做法无疑很大程度提高了覆盖率,但是它的图片相关性不一定足够高,图片的噪音可能也比较大,还可能出现很多个非常相似的图片。
比如我们希望寻找实体Bank相关的图片,如果直接用Bank去搜,可能会找到River Bank相关的照片,但是我们实际是希望找到Commercial Bank。很多的方法研究如何清洗候选的图片,比如通过拓展查询语句(Imagenet: A large-scale hierarchical image database. CVPR 2009)。另一方面,我们期望search到的图片,除了能够符合目标实体外,还能够能够充分反应实体不同方面的(diversity),具有较好的多样性(Richpedia: a large-scale, comprehensive multi-modal knowledge graph. Big Data Research 2020)。
事实上,上面的两种方法通常会一起使用之后作为搭建MMKG的主要手段(Richpedia: a large-scale, comprehensive multi-modal knowledge graph. Big Data Research 2020)。
Opportunities. 作者提出两个在entity grounding方向的挑战:(1)实体会对应到不同的图片,哪些图片是最具有代表性的?(2)作者提出一个很有趣也很难的新task,叫做multiple grounding。作者认为事实上每个实体在实际中有不同的方面,不同的图片应该对应到这些不同的方面中去。这个想法实际上是把hasImage这个关系,进一步细分到不同的fine-grained relations上。比如下面的例子:

想法很好,但是从哪里找这么多质量高的图片呢?
3.2.2 Concept Grounding
Concept grounding aims to find representative, discriminative and diverse images for visual concepts.
Challenges. 虽然concept grounding和entity grounding有很多的相似之处,但是面临新的挑战。我们可以把概念分为可以可视化的concept和不可可视化concept两种。对于visualizable concepts存在的问题是,它可能对应了很多不同的图片,怎么样选择期望的图片,比如Princess这个概念,它可以联系到迪士尼公主、古代公主等等,怎么样选择合理的图片?对于non-visualizable concepts来说,我们较难直接定位到符合的图片,比如irreligionist无宗教信仰者就很难直接可视化。
这一方向的主要工作包括:
Visualization Concept Judgment
The task aims to automatically judge visualizable concepts and is a new task to be solved.
判断概念是否能够被可视化的新task。[Towards fairer datasets: Filtering and balancing the distribution of the people subtree in the imagenet hierarchy.] 研究发现只有12.8%的Person相关概念可以被较好的可视化。比如Rock star容易可视化,Job candidate就不太容易可视化。
为了自动判断一个概念是否能够被可视化,[80 million tiny images: A large data set for nonparametric object and scene of singapore. ] 就移除了所有的抽象概念,仅仅保留非抽象概念。但也不是所有的抽象词都无法可视化,比如Anger这个概念是可以定位到人发火的图片的。另外的方法是使用谷歌搜索引擎,如果搜索出来的图片结果比web结果多,那这个概念就可能是可以可视化的(Graph-based clustering and ranking for diversified image search.)。
Representative Image Selection
这个任务主要是选择合适的图片。
The task essentially aims to re-rank the images according to their representativeness.
首先我们希望选择的图片足够有代表性,主流方法采用聚类算法,然后认为一个image在它所位于的cluster中越靠近中心,这个image在这个cluster中就越具有代表性(Representative image selection from image dataset.)。
还有的方法把image的caption和tag也加入到判断过程中来(A joint optimization model for image summarization based on image content and tags. AAAI 2014)。
Image Diversification
我们还希望选择的图片有足够的多样性,
The task requires the images which concepts are grounded to should balance diverse and relevant.
尽可能从不同类的image clusters中选择,而不是反复从一个cluster中选择图片(Towards a relevant and diverse search of social images. IEEE Trans. MM 2010)。
这一方向的方法大多只是关注text-image检索,但是搜集到的图片中可能同样蕴含着偏见bias,比如对gender、age、race的偏见。
Opportunities. concept grounding还是属于新生的领域,还有很多问题需要解决。
Abstract Concept Grounding:抽象概念很难可视化,但是很多概念还是可以关联/定位到某些场景的。比如提到\(Love\)这个概念,事实上它可能关联到baby/cute/newborn, dog/pet, heart/red/valentine, beach/sea/couple, sky/cloud/sunset, flower/rose等单词(Computing iconic summaries of general visual concepts. 2008)。
Gerunds Concept Grounding:动名词的可视化很大程度依赖于对人的姿态的判断(Zero-shot learning via visual abstraction. ECCV 2014)。
Non-visualizable Concept Grounding via Entity Grounding:一个概念可能很难可视化,但是可以通过它的对应实体,来寻找符合的图片。比如拿爱因斯坦实体的照片作为物理学家概念的图片:

但是这种方法很难决定什么是typical的图片,比如为什么我们会使用爱因斯坦而不是其他物理学家的图片。
3.2.3 Relation Grounding
关系定位主要指寻找能够表达特定relation的image。
Relation grounding is to find images from an image data corpus or the Internet that could represent a particular relation.
输入可以是具有这个relation的多个triples,输出就是预期的图片。
Challenges. 当使用三元组进行查询的时候,找到的图片常常会过于和头尾实体相关,而不是和关系本身相关。
目前主要的研究都是针对spatial relation或者action relation。那这样看来,在KG更常见的更多的语义relation很难找到符合的图片。
Text-Image Matching
把text和image都表示为同一表达空间下的向量,然后计算相似性。[Visual relations augmented cross-modal retrieval. 2020]方法使用GNN来学习visual relation。也有方法使用预训练方法[Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning. arXiv 2020]。
Graph Matching
接下来有的研究方法尝试能够更加显式地进行relation和objects的匹配。比如[Cross-modal scene graph matching for relationship-aware image-text retrieval. 2020]方法就是通过描述的语法结构和图片上对象的依赖关系结构进行graph match(Crossmodal scene graph matching for relationship-aware image-text retrieval. IEEE/CVF 2020):
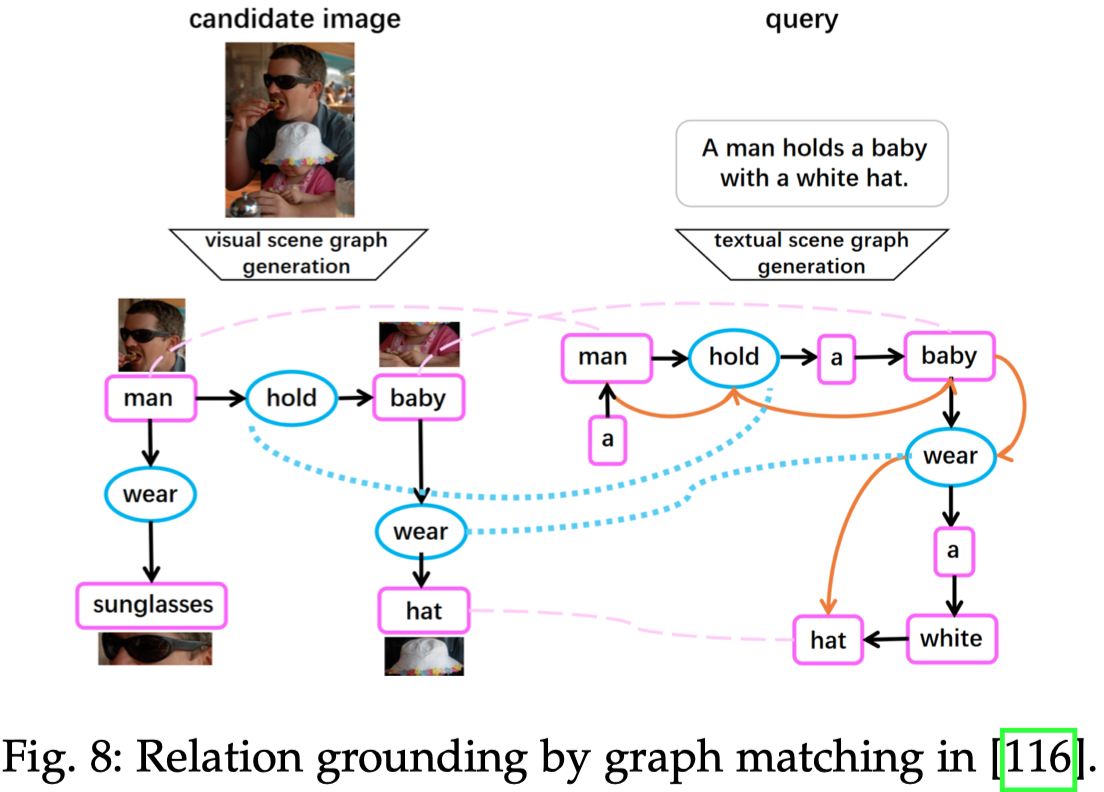
Opportunities. 作者提出能否把除了空间关系和行为关系以外的关系也进行可视化?个人认为很难,因为首先人工都很难标注。
4 Application
4.1 In-MMKG Applications
知识图谱本身就有knowledge,我们当然可以直接基于符号进行推理。但是难用,也不好与主流的DL方法结合。
在编码MMKG的图像信息时,通常还是直接使用visual encoder的编码器的hidden state,很少利用其它visual features比如Gray Histogram Descriptor (GHD),Histogram of Oriented Gradients Descriptor (HOG),Color Layout Descriptor (CLD)等。
下面是MMKG的一些主要应用和benchmark datasets:
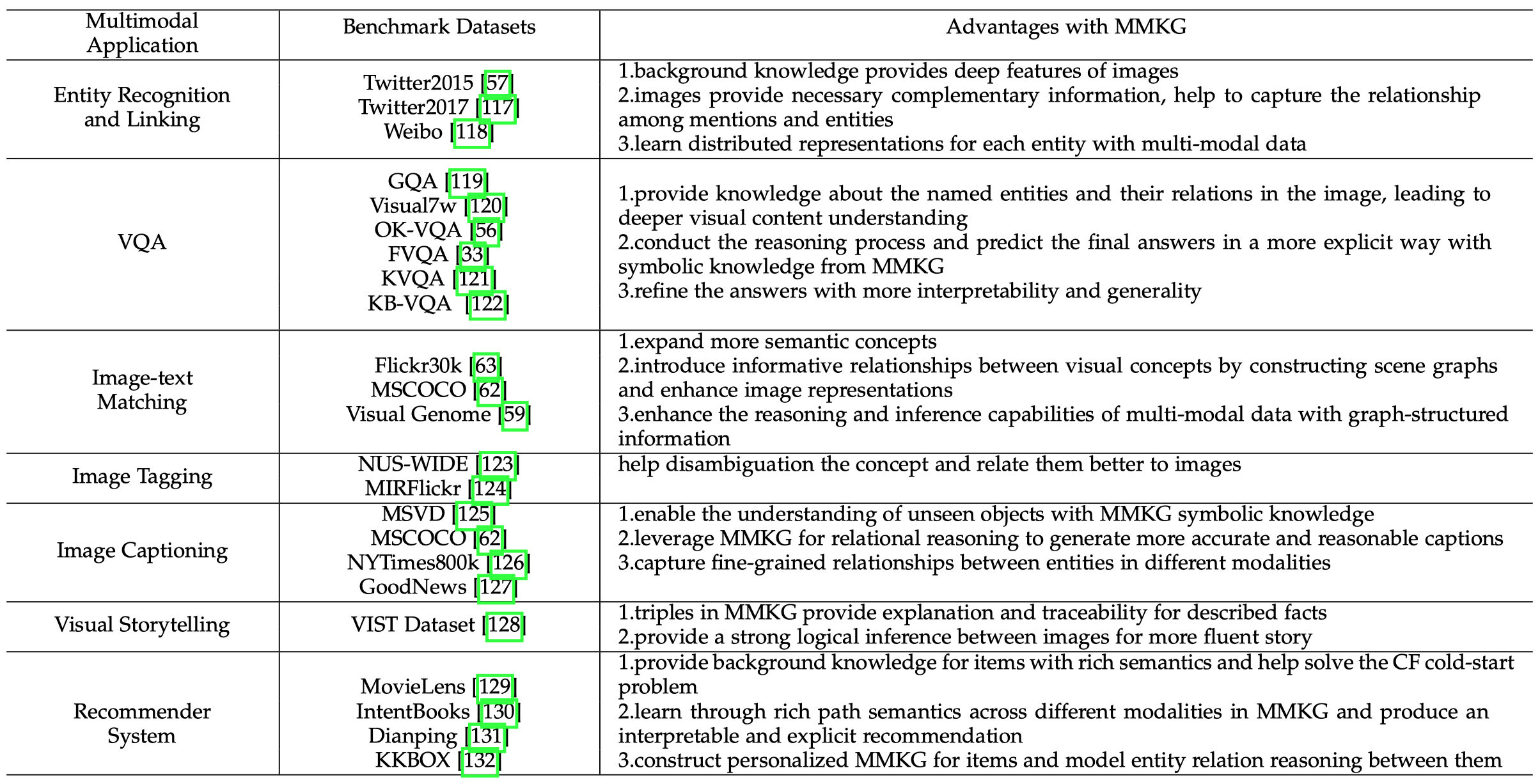
4.1.1 Link Prediction
预测头尾实体或者预测关系。
来想一个关键问题,Visual信息对预测实体有帮助吗? 比如设想某个relation对应的尾实体通常具备某种共通的视觉特征,头实体也具备某种共通的视觉特征,这种视觉特征可以辅助预测,并且无法被单纯的文本描述。比如spouse两边表现出来的应该都是人形,而不是动物。
再比如,Person的图像可以提供信息,用来判断age等profession(Embedding multimodal relational data for knowledge base completion)。
4.1.2 Triple Classification
直接判断一个给定的三元组是不是成立的,可以看做是KG补全的一种形式。具体的工作参见论文。
4.1.3 Entity Classification
判断实体属于哪一类?同样可以看做是一种特殊的链路预测,预测关系\(IsA\),候选项是MMKG中的concepts。
4.1.4 Entity Alignment
MMKG实体对齐。具体相关工作看论文。这里提一个有意思的想法,[Mmkg: Multi-modal knowledge graphs. ESWC 2019]把MMKG对齐也看做了是一个链路预测任务\(<h?,sameAs,t>\)或者\(<h,sameAs,t?>\)只不过是这里的头尾实体不在同一个MMKG中。
4.2 Out-of-MMKG Applications
在MMKG以外的应用当然有很多,包括:
- Multi-modal Entity Recognition and Linking:给定一段文本和相应的图片,识别出描绘的实体(Adaptive co-attention network for named entity recognition in tweets. AAAI 2018)
- Visual Question Answering:针对图片提问。由于需要对于detected objects实现复杂的推理过程,因此引入MMKG进行辅助推理(Okvqa: A visual question answering benchmark requiring external knowledge. CVPR 2019)。
- Image-Text Matching:是一个非常关键的基础的task,判断image-text pair的相似程度。引入MMKG来获得更多的信息,对image和text有更多的理解,从而提升预测效果(Knowledge aware semantic concept expansion for image-text matching. IJCAI 2019)。
- Multi-modal Generation Tasks
- Image Tagging:引入增强对图像的理解(Enhancing the quality of image tagging using a visio-textual knowledge base. IEEE Trans. MM 2019)
- Image Captioning:引入MMKG生成更加准确和合理的caption(Relational reasoning using prior knowledge for visual captioning. arXiv 2019)
- Visual Storytelling:给定连续的图片序列,然后讲故事。引入MMKG来更好的寻找不同图片中的对象的关系,并且能够获得额外的训练集意外的知识(“Knowledge-enriched visual storytelling. AAAI 2020)
- Multi-modal Recommender System:买东西的时候我们当然会很关注视觉信息,并且视觉信息很难用文本充分描述出来,引入MMKG提升推荐性能(Multi-modal knowledgeaware reinforcement learning network for explainable recommendation. Knowledge-Based Systems 2021)
5 Open Problems
5.1 Complex Symbolic Knowledge Grounding
在前面介绍了entity、concept和relation的grounding方法。一方面这些方向都有自身的挑战,比如abstract concept找不到;relation也不好找。
另一方面,如果我们拓展下思维,大多数的MMKG仅仅是实体找到了对应图片,但并不是KG中所有的knowledge都找到了图片。比如一个path或者subgraph也找不到符合的图片,而这样的信息往往在某些任务中是可用的。比如对于实体Trump,他的妻子的照片,儿子的照片和女儿的照片都可以结合到一起成为一个subgraph,这样的subgraph可以对应到一个他们全家福的照片上。
作者把这样的task叫做multiple relational grounding,这无疑是一个很难的任务。
5.2 Quality Control
MMKG本身也存在质量问题,比如errors、missing facts和outdated facts。举例,对于long-tail的entity来说,它就可能会对应到不相符的照片上,因为可能在Web上就没有符合的图片。
MMKG除了一般KG可能存在的问题外,还由于引入图像带来了新的问题:
一个实体的图片可能会和另外的很相关的实体图片混合在一起。比如下图:

鳄鱼鸟的照片就经常出现鳄鱼,如果鳄鱼本身也是一个实体的话,这样就可能出现了信息的混合。
越是出名的照片越有可能出现。比如上图中刘慈欣的《漫步地球》在搜索引擎上找到的照片总是另一本书《黑暗森林》的照片。
一些抽闲的概念很可能对应到错误的照片上。比如上图中的发怒arrogance实体对应到了错误的图片。
为了解决上述问题,可能需要对视觉信息进行更多分析,结合背景信息综合判断。
5.3 Efficiency
在构建MMKG时,因为要处理多模态的数据,往往需要大量的时间。比如NEIL(Neil: Extracting visual knowledge from web data. ICCV 2013)就花了350K的CPU hours处理了2273个objects的400K图像实例,这当然没法处理可能拥有上亿乃至数十亿实体的大规模KG。
另一个是对于在线实时的MMKG应用算法,大多数的算法无法适应实时场景。