MM-Transformer-Survey
Multimodal Learning with Transformers: A Survey
2022-06 arxiv
牛津大学学者的一篇多模态Transformer综述,系统的描述了目前多模态Transformer可能注意的不同改进点。
Transformer is a promising neural network learner, and has achieved great success in various machine learning tasks. Thanks to the recent prevalence of multimodal applications and big data, Transformer-based multimodal learning has become a hot topic in AI research. This paper presents a comprehensive survey of Transformer techniques oriented at multimodal data. The main contents of this survey include: (1) a background of multimodal learning, Transformer ecosystem, and the multimodal big data era, (2) a theoretical review of Vanilla Transformer, Vision Transformer, and multimodal Transformers, from a geometrically topological perspective, (3) a review of multimodal Transformer applications, via two important paradigms, i.e., for multimodal pretraining and for specific multimodal tasks, (4) a summary of the common challenges and designs shared by the multimodal Transformer models and applications, and (5) a discussion of open problems and potential research directions for the community.
1. Introduction
我们期待的理想的人工智能具有的能力至少是可以做到人类能够做到的一切,这里就包括了人类感知世界的方式:看、听、摸等。人类使用特定感知器sensor和外界建立特定的交流通道,这种特定交流通道中传递/表达的信息形式我们称作是模态modality,比如语言或视觉:
In general, a modality is often associated with a specific sensor that creates a unique communication channel, such as vision and language.
这篇survey主要是考虑使用Transformer解决多模态任务,Transformer适用于多模态的几点原因:
- 更少的模态特定的假设,比如RNN的序列化输入;CNN的局部迁移不变性,使得Transformer天然的适用于处理更多模态数据
- 对于许多多模态数据来说,可以被轻易的转换成适合于Transformer的序列输入形式
- Transformer的内部结构,比如self-attention,很适合被改造为跨模态交互/多模态融合的形式
有一些其它的survey是从更加广泛的模型来讨论多模态学习:
- Multimodal machine learning: A survey and taxonomy. 2018
- Multimodal intelligence: Representation learning, information fusion, and applications. 2020
- Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions. 2022
2. Background
多模态学习(multimodal machine learning,MML)并不是一个新词,从20世纪80年代开始就有人研究视觉听觉语音识别(Integration of acoustic and visual speech signals using neural networks. 1989)。在深度学习时代,随着Transformer模型的出现,算力的急速增长,多模态数据集规模的不断增加共同促进多模态学习进步。
更多背景请参考论文内容
3. Multimodal Transformers
3.1 Multimodal Input
对于任意模态数据,要输入到Transformer通常是做两步:
tokenize the input
select an embedding space to represent the tokens
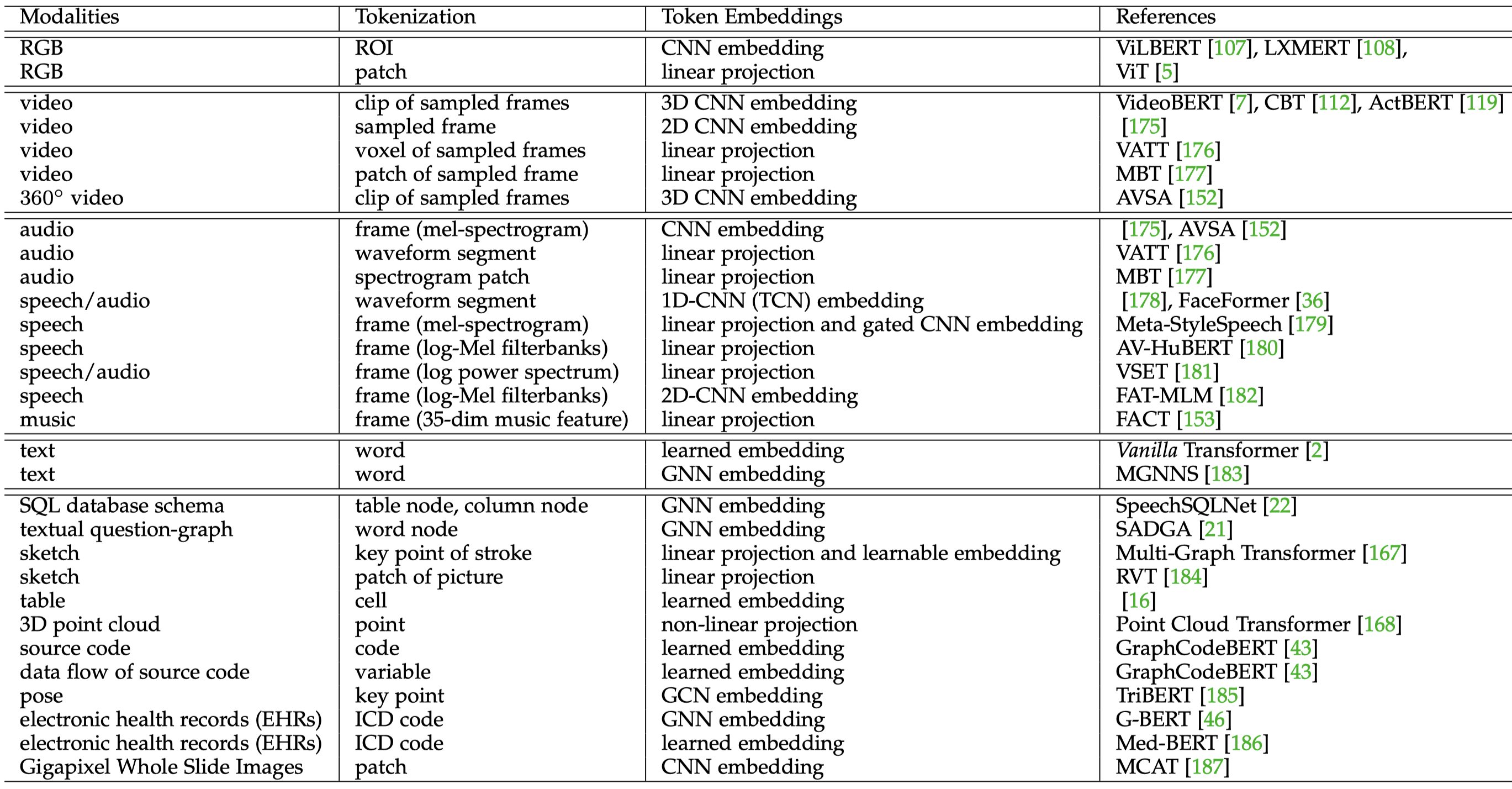
对于单模态数据,我们有不同的方法实现tokenization和选择合适的token embedding。比如对于image,我们可以选择ROI作为tokens,然后CNN导出的feature作为token embedding;可以选择将image划分成不同的patch,每个patch经过linear projection之后作为token embedding;也可以选择将image上的不同object作为tokens,使用GNN学习场景图的特征作为token embedding(Multimodal sentiment detection based on multi-channel graph neural networks. 2021)。
下面的表格是总结的一些多模态tokens处理的方法:
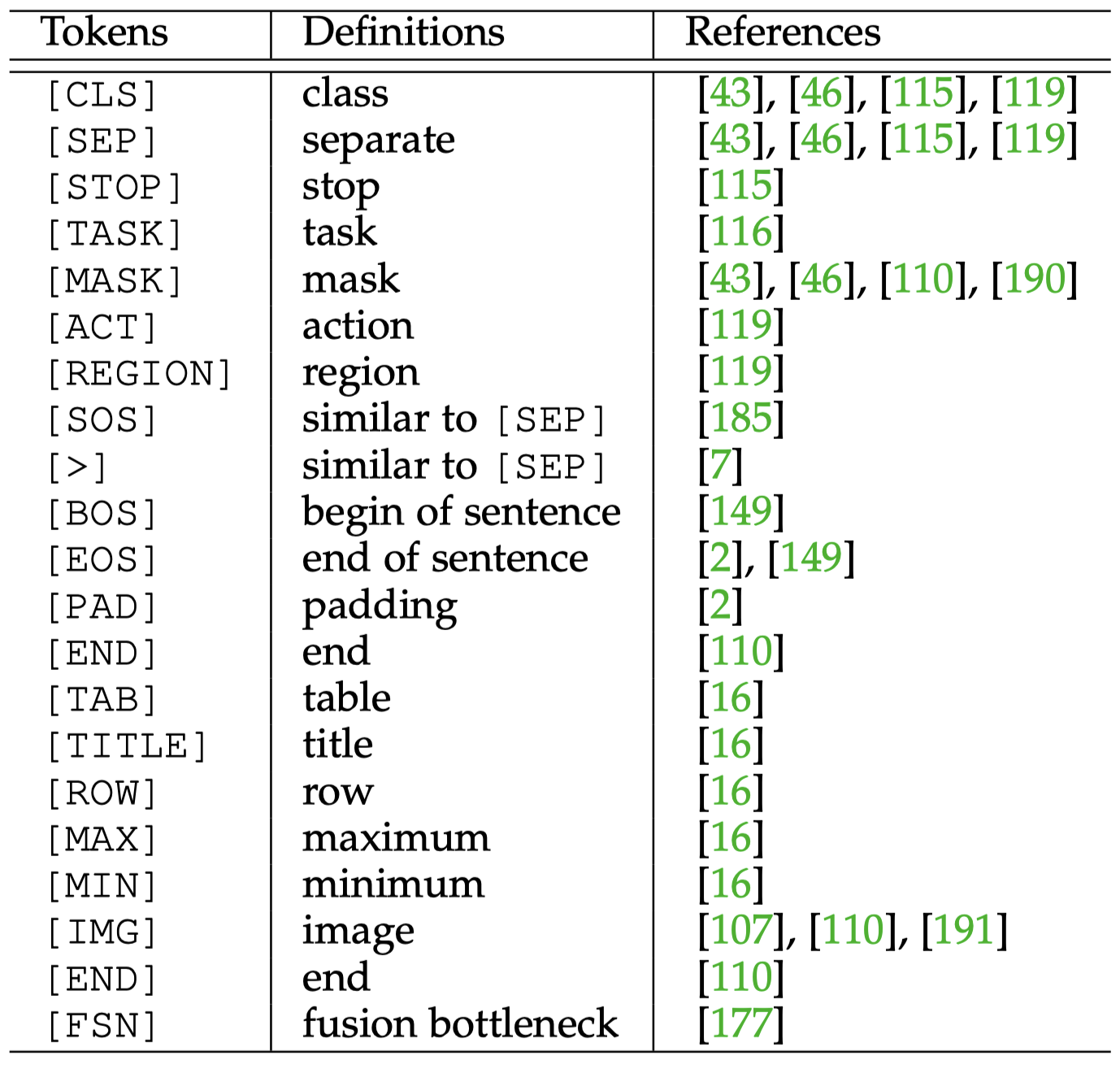
通常还会加入一些special tokens,用来服务一些特定的目的:
在实践中,人们常常会在embedding层选择融合不同的信息,属于early-fusion的一种。最常见的方式就是在每个位置的token上直接加上不同的信息。比如在原始的Transformer中,token embedding会加上position embedding;VL-BERT选择“linguistic token embedding \(\oplus\) full image visual feature embedding”;InterBERT选择在ROI的embedding加入位置信息,“ROI embedding \(\oplus\) location embedding”。
3.2 Self-Attention Variants in Multimodal Context
接下来讨论用于多模态的self-attention变体。
下面是作者总结的变体:
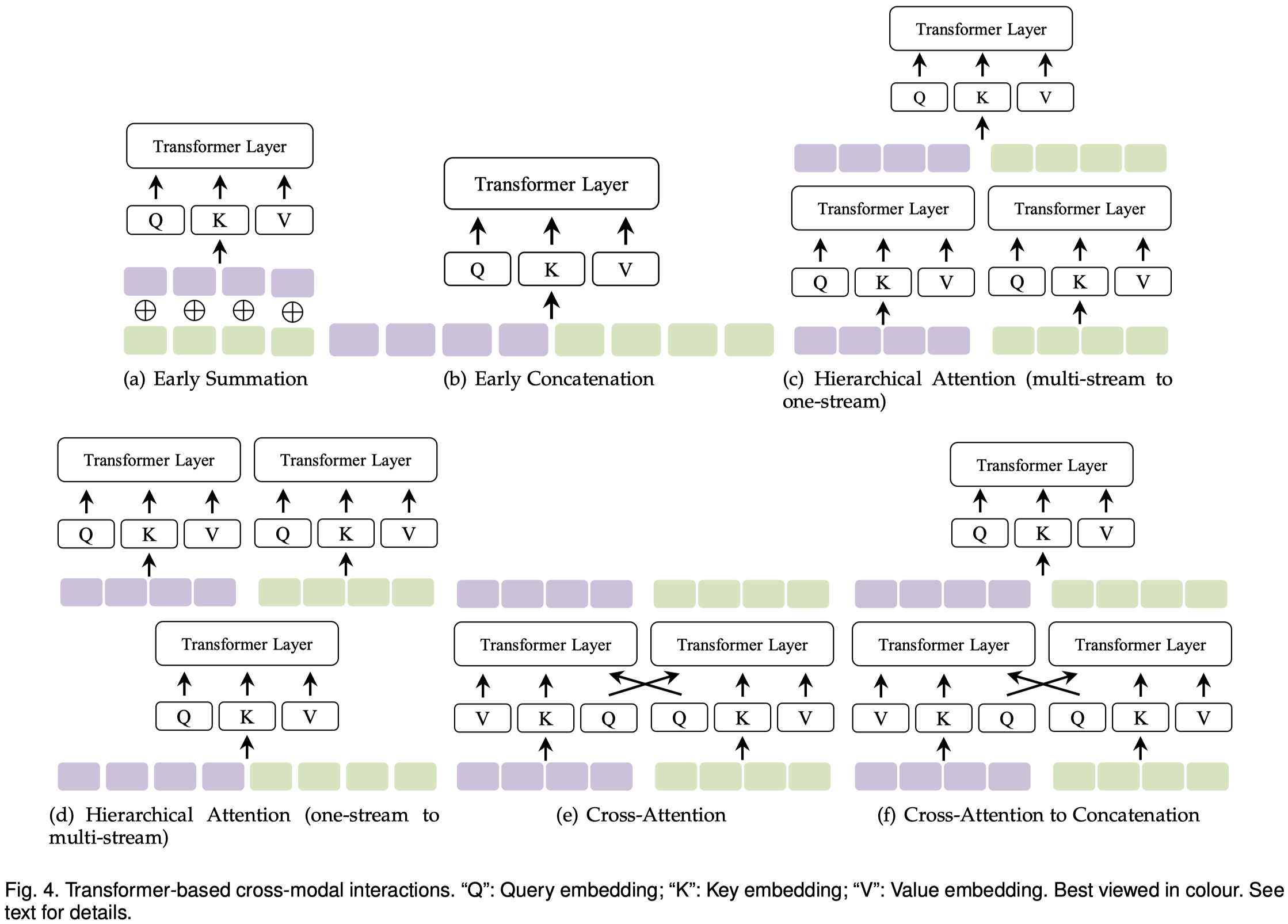
Early summation
在embedding layer对于两个模态的token embedding直接进行element-wise summing:

其中的\(Z_{(A)}\)和\(Z_{(B)}\)表示是来自两个模态的token embedding matrix;\(\alpha\)和\(\beta\)是两个人工定义的权重;\(TF\)表示Transformer layer/block。
这样做的好处是不会增加计算量。
坏处是\(\alpha\)和\(\beta\)需要人工选择,并且直接相加两个模态的embedding,显得过于粗暴了。
Early Concatenation
不是相加,而是直接拼接两个模态的token序列,组成新的序列输入到Transformer:
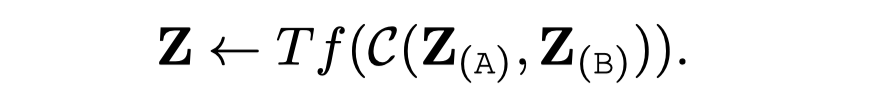
这种做法使得一个模态的token embedding可以直接以其它模态的token embedding作为context进行学习。这种做法也叫做“all-attention”。
坏处是更大的输入序列长度,当然会增加计算复杂度。
Hierarchical Attention (multi-stream to one-stream)
每个模态各自有Transformer,然后拼接到一起输入到一个统一的Transformer:

这种做法是late fusion的一种;也可以看做是一种特殊的early concatenation(在输入到真正的多模态Transformer之前,先使用单模态Transformer对token embedding进行了编码)。
Hierarchical Attention (one-stream to multi-stream)
和前面的相反,首先使用一个统一的Transformer处理多模态数据,然后每个模态再有自己独立的Transformer:
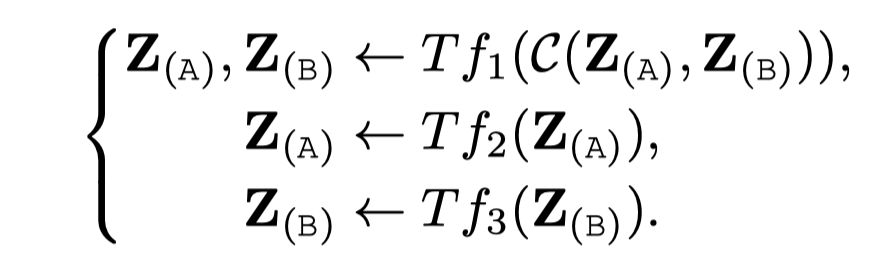
这种做法的一个例子是InterBERT。
Cross-Attention
很常见也非常自然的想法,每个模态都有Transformer,但是内部Transformer的query是来自于其它模块:
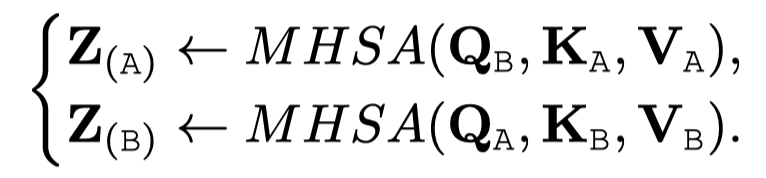
这种做法叫做cross attention或者co-attention,是VilBERT方法首次提出(Vilbert: Pretraining taskagnostic visiolinguistic representations for vision-and-language tasks. 2019)。这种做法能够将其它模型的信息引入到当前模态,也没有增加Transformer的输入token序列长度,但是它丢失了全局上下文,也就是不能够像前面的all-attention一样,同时考虑所有模态的token embedding。
Cross-Attention to Concatenation
另外一个变种就是在co-attention之后,使用拼接或者另外的Transformer来继续处理。这样同样可以捕获多个模态的global context。
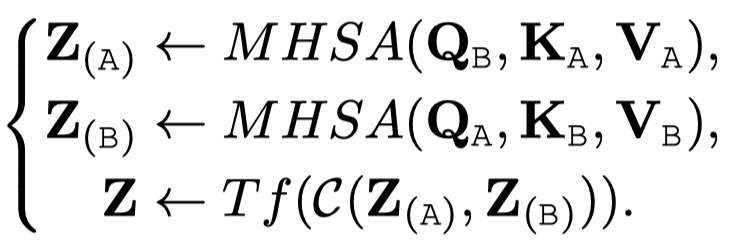
4 Transformers for Multimodal Pretraining
4.1 Task-Agnostic Multimodal Pretraining
对于任务无关的预训练Transformer模型,存在以下的几个现状/趋势:
- Vision-language pretraining (VLP)是有最多研究的方向,包括了image+language,video+language。
- VLP模型有两种组合方式:two-stage方式,(如LXMERT,VilBERT,VL-BERT等)使用了object detector(如Faster R-CNN)。end-end方式(如Pixel-BERT,SOHO,KD-VLP等)没有使用额外的object detector。
- 大多数都是以自监督self-supervised的方式进行训练,但是这种训练方法非常依赖于大量提前对齐的多模态数据作为跨模态监督。比如最常用的image-text pairs,instructional videos(比如教做饭的视频,其中的图像和文本更可能是对齐的)。这种数据实际上也不是很好获得,更多现实情况下可能是weakly-aligned或者unaligned的多模态数据。当然目前也出现了一些弱对齐/无对齐的多模态数据进行预训练的工作(Product1m: Towards weakly supervised instance-level product retrieval via cross-modal pretraining ICCV 21,Simvlm: Simple visual language model pretraining with weak supervision 21,Zero-shot text-to-image generation 21)
另外一个很重要的点是如何设计pretext task。pretext task起源于CV领域,可以翻译为前置任务/代理任务/预训练任务;它一般是比较泛化的,能够潜在的对一系列下游任务有帮助的辅助任务。通常是某种自监督学习任务,比如masked language modelling (MLM)、masked object classification (MOC)、image rotation等等。
单纯的从任务角度讲,这些pretext task可以分为是单模态预测任务和多模态预测任务。但要注意的是,单模态预测任务实际上很可能涉及到利用多模态信息,这和具体模型训练时的信息编码策略有关。
从motivation的角度讲,pretext task可以分为masking、describing、matching和ordering,如:
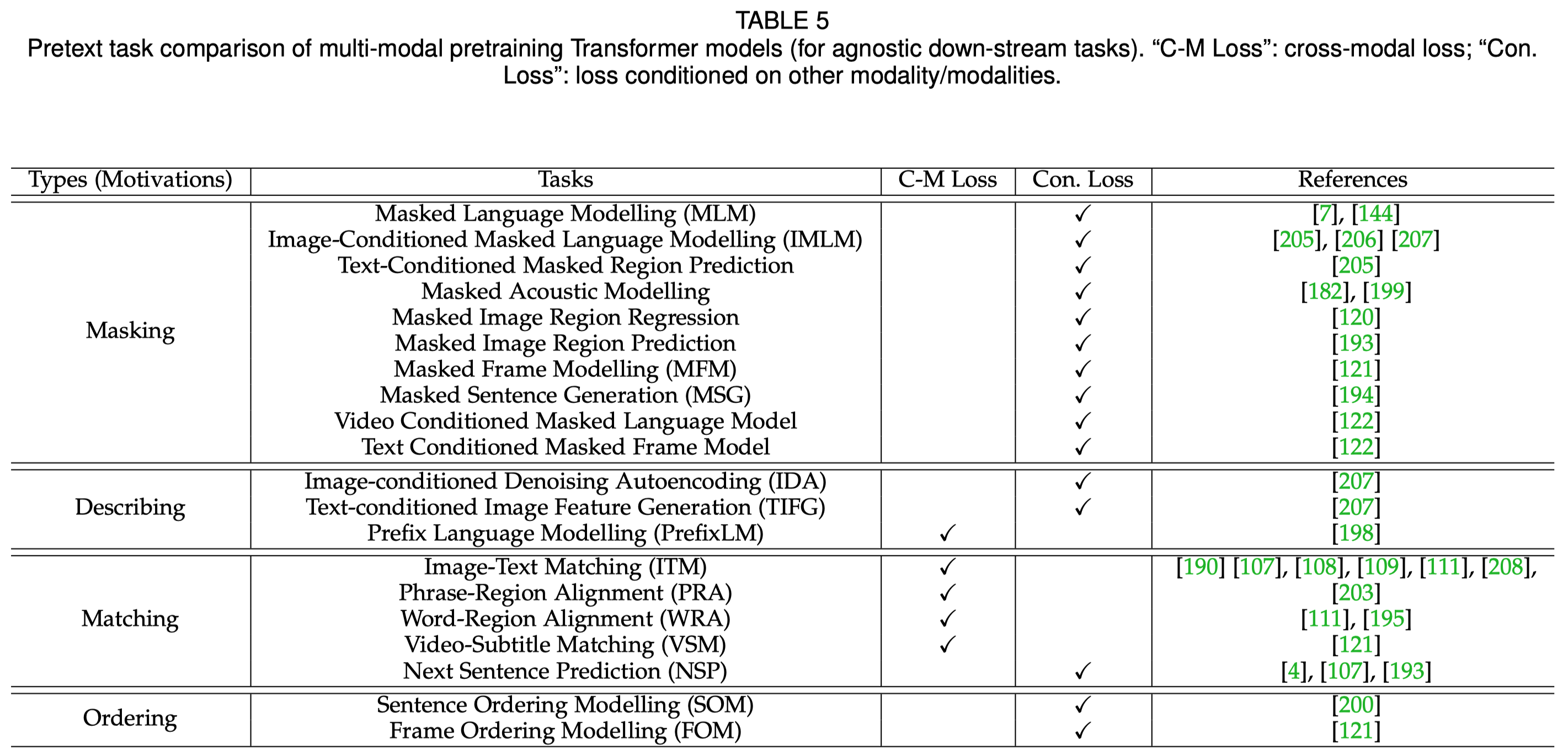
尽管目前多模态预训练Transformer方法已经取得了很大的进展,比如VLP模型可以在一系列下游的multimodal discriminative tasks达到很好的效果,但是对于生成任务generative tasks不能直接应用。如文献(Xgpt: Cross-modal generative pretraining for image captioning 21)中指出,VideoBERT和CBT都需要额外训练一个解码器才能够完成video captioning任务。
另外,如何设计合适的pretext task也是个重点。多任务学习和对抗学习都被研究用来提升预训练效果(12-in1: Multi-task vision and language representation learning CVPR 20,Product1m: Towards weakly supervised instance-level product retrieval via cross-modal pretraining. ICCV 21),然而多个pretext任务如何平衡?如何设计pretext,越复杂的就越好吗?
4.2 Task-Specific Multimodal Pretraining
也有很多的研究工作是针对特定领域/任务的预训练,这是因为上述的通用预训练模型有些情况下(如预训练语料领域不重叠/结构不能够充分捕获领域特征/预训练任务设计不合适等)很难直接应用到特定领域。此类特定领域/问题/任务包括:
- vision and language navigation:需要做sequential decision
- generative task:一般的VLP模型无法无缝的适用于生成任务
- programming:需要考虑代码结构
- health
- fashion domain
4.3 Transformers for Specific Multimodal Tasks
Multimodal Transformer结构当然也可以直接用于特定的多模态任务,具体不展开。
5 Challenges and Designs
5.1 Fusion
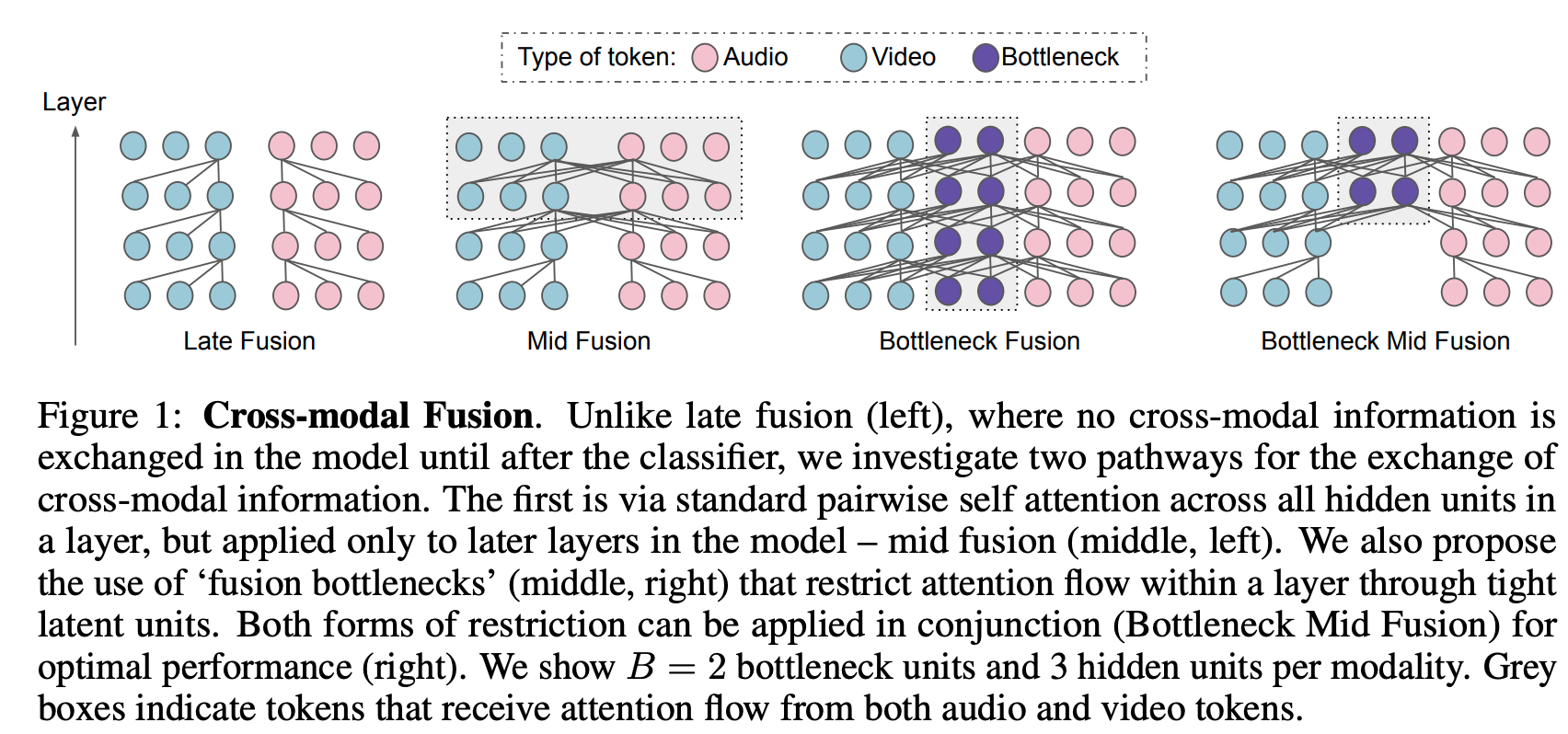
按照阶段,fusion可以分为early fusion(input level)、middle fusion(intermediate representation)、late fusion(prediction)。
一个值得注意的方法是bottleneck fusion(Attention Bottlenecks for Multimodal Fusion)
5.2 Alignment
真实的数据常常是多个模态数据同时发生,因此天然存在对齐的模态数据。多模态数据的对齐是最常用的想法就是把多模态数据映射到通用空间下,然后通过对比学习等方法进行优化。除了比较粗粒度的image-text match的问题,还有更加细粒度的对齐任务,比如需要图像上region-level的对齐。
很多下游任务都需要对齐能力,比如visual grounding、text-to-speech等。当使用多任务学习进行训练时,可以看做是一种隐式的task-level的对齐。
5.3 Transferability
可迁移性是multimodal Transformer的另一个挑战,包括以下几个方面:
- 训练数据与实际/测试数据之间的差距,比如如何把在well-aligned cross-modal pairs训练好的模型迁移到weakly-aligned cross-modal pairs。CLIP是一个很好的工作,它通过prompt template来弥补训练和测试之间的差异。
- 过拟合是另一个妨碍迁移性的问题。由于Transformer的建模能力比较强,很容易在训练数据上过拟合。
- 不同任务之间的差异也是需要克服的困难。比如判别任务和生成任务之间的差异,BERT-like的模型不能直接应用在生成任务上。再比如有时候多模态模型需要处理某些模态数据缺失的问题,这种情况下知识蒸馏是一个可能的解决方案。可以用多个单模态Transformer作为teacher,一个多模态Transformer作为student(Towards a unified foundation model: Jointly pre-training transformers on unpaired images and text 21)。
- 跨语言的差异。
5.4 Efficiency
multimodal Transformer的效率问题主要体现在两个互相影响的方面:
- 需要大量训练样本
- 随着输入序列长度的增加,训练时间和显存按照平方级增长
解决的核心方法是减少训练样本或者减少模型参数,目前有以下几种思路来提高效率:
- Knowledge distillation. 通过知识蒸馏,从大的Transformer模型获得小的Transformer模型。
- Simplifying and compressing model. 移除一些模型的模块,比如在VLP模型中移除object detector;权重共享,multimodal Transformer中的部分模型参数可以共享。
- Asymmetrical network structures. 不同的模态给定不同大小的模型部分。
- Improving utilization of training samples. 充分挖掘训练样本的潜在信息。
- Compressing and pruning model. 选择multimodal Transformer的最优子结构。
- Optimizing the complexity of self-attention. 直接优化Transformer的self-attention,比如稀疏注意力。
- Optimizing the complexity of self-attention based multimodal interaction/fusion. 优化多模态交互带来的计算成本,比如bottleneck fusion方法。
- Optimizing other strategies. 其它策略,比如有研究者(Multiview transformers for video recognition 22)提出可以逐步的融合多模态tokens,而不是直接融合所有多模态token。
5.5 Universalness
通用性是当前很多模型主要考虑的问题之一,出现了以下几种体现通用性的思路:
- Unifying the pipelines for both uni-modal and multimodal inputs/tasks. 单模态场景和多模态场景通用,比如上面提到的使用知识蒸馏来增加迁移性。
- Unifying the pipelines for both multimodal understanding and generation. 判别任务和生成任务通用。
- Unifying and converting the tasks themselves. 模型不变,通过改动任务设置让模型在多个任务上通用,比如CLIP。
5.4 Interpretability
可解释性。研究者尝试设计一些探测任务来评估预训练过程中模型到底学习到了什么(Behind the scene: Revealing the secrets of pre-trained vision-and-language models ECCV 20,Probing image language transformers for verb understanding 21)。
6 Discussion and outlook
作者提出了几个开放问题:
- 设计更加通用的多模态架构,不仅仅是在多模态任务上,也要在各个单模态任务上取得最好的效果。常常发现尽管使用了更多的多模态数据,多模态模型在单模态任务上的表现不如单模态模型。为了解决这个问题,可能探究和理解multimodal Transformer背后的原理和机制是比不断尝试新的网络架构更有价值的问题。
- 发现跨模态数据之间的隐式对齐。
- multimodal Transformer的高效学习问题还没有被充分探究,尽管efficient Transformer的各种变体已经出现了很多研究工作。