MKGformer
Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion
SIGIR 2022,代码,Zhejiang University。
作者提出了一种基于Transformer的能够适用于不同多模态知识图谱预测任务的方法,MKGformer。对于不同的预测任务,作者通过定义输入数据和输出数据拥有相同的格式,从而到达不改变模型结构,还能够同时用于不同预测任务;其次,作者提出了一种在text和image模态之间,进行multi-level混合的Transformer结构。
作者在多模态KG补全、多模态关系抽取和多模态命名实体识别三个任务的有监督学习和低资源学习的场景上进行了实验。
Multimodal Knowledge Graphs (MKGs), which organize visualtext factual knowledge, have recently been successfully applied to tasks such as information retrieval, question answering, and recommendation system. Since most MKGs are far from complete, extensive knowledge graph completion studies have been proposed focusing on the multimodal entity, relation extraction and link prediction. However, different tasks and modalities require changes to the model architecture, and not all images/objects are relevant to text input, which hinders the applicability to diverse real-world scenarios. In this paper, we propose a hybrid transformer with multi-level fusion to address those issues. Specifically, we leverage a hybrid transformer architecture with unified input-output for diverse multimodal knowledge graph completion tasks. Moreover, we propose multi-level fusion, which integrates visual and text representation via coarse-grained prefix-guided interaction and fine-grained correlation-aware fusion modules. We conduct extensive experiments to validate that our MKGformer can obtain SOTA performance on four datasets of multimodal link prediction, multimodal RE, and multimodal NER.
1 Introduction
作者认为目前的多模态KGC任务存在以下问题:
- Architecture universality:不同的KGC任务,对于不同模态需要设计不同的编码器,从而限制了模型的通用性和易用性。
- Modality contradiction:大多的multimodal KGC的方法很大程度上忽略了图像信息可能带来的噪音问题,因为在多模态KG中,一个实体可能会关联到多个不同的image,实际上只有部分的图像信息可能才是所需的。
为了解决上述问题,作者提出了:
- 之前有研究者发现,预训练模型能够在Transformer的self-attention层和feed-forward层激活和输入数据相关的knowledge。因此,作者尝试基于Transformer架构,同时学习textual和visual的信息。
- 作者提出的MKGformer,有两个核心结构,prefix-guided interaction module (PGI)和correlation-aware fusion module (CAF)。前者用于pre-reduce不同模态的heterogeneity,后者用来进一步降低模型对于irrelevant image/text的错误敏感性。
2 Approach
总体结构:
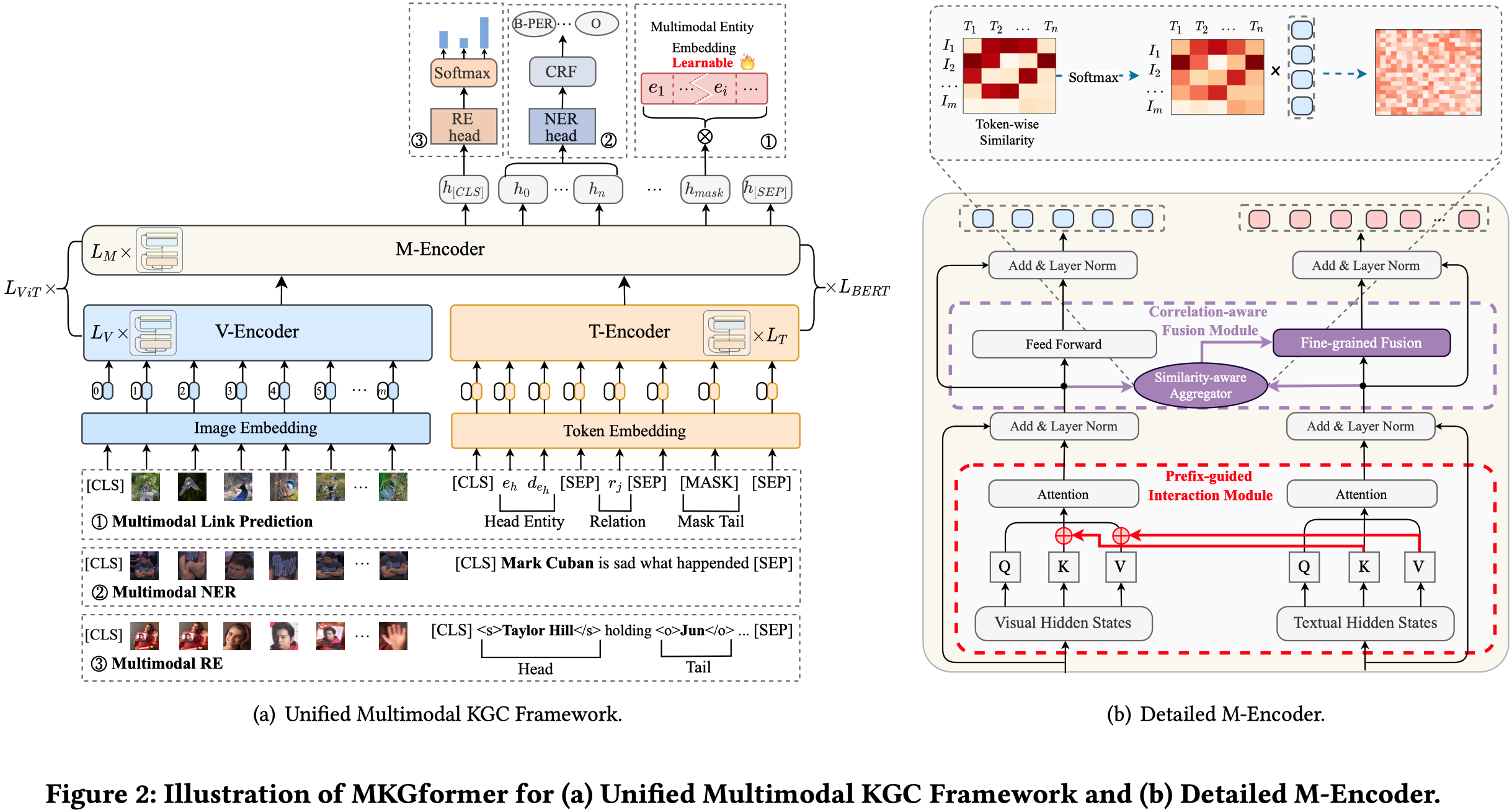
2.1 Unified Multimodal KGC Framework
对于文本,使用BERT进行编码(T-Encoder);对于图像,使用ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)进行编码(V-Encoder)。先分别独立进行几层的学习之后,在最后\(M\)层,利用作者提出的M-Encoder进行模态混合。需要注意的是,这里的M-Encoder并不是额外的层,而是作者在BERT和ViT的架构基础上,直接进行了改进,让不同模态模型之间能够进行信息流通。
模型对于输入和输入数据格式的变形,首先是有三个预测任务:
Multimodal Link Prediction is the most popular task for multimodal KGC, which focuses on predicting the tail entity given the head entity and the query relation, denoted by \((𝑒_ℎ ,𝑟, ?)\). 预测未知fact。多模态带来的新条件是,每个实体可能拥有多个image \(I_h\)。
Multimodal Relation Extraction aims at linking relation mentions from text to a canonical relation type in a knowledge graph. 给定一段描述文本\(T\),已知其中的头尾实体\((e_h,e_t)\),预测实体间的关系\(r\)。多模态带来的新条件是,描述文本有对应的image \(I\)。
Multimodal Named Entity Recognition is the task of extracting named entities from text sequences and corresponding images. 从一个token序列中\(T=\{w_1,\dots,w_n\}\),预测对应的标签序列\(y={y_1,\dots,y_n}\)。多模态带来的条件是,描述文本有对应的image \(I\)。
对于输入数据和预测数据的变形:
对于多模态链路预测,作者首先设计了特别的一步操作,Image-text Incorporated Entity Modeling,具体而言,在保持整个模型参数不动的情况下,只训练学习新出现的entity embedding。这样是的文本信息和视觉信息都能够融合到entity embedding上。对于实体\(e_i\)关联的图像,输入到V-Encoder;对于实体\(e_i\)的文本描述\(d_{e_i}=(w_1,\dots,w_n)\),改造为:

然后预测\([mask]\)是实体\(e_i\)的概率。
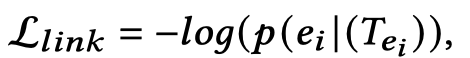
随后,正式开始预测missing entity,将\((𝑒_ℎ ,𝑟, ?)\)变形为:

对于多模态命名实体识别,作者利用CRF函数(Neural Architectures for Named Entity Recognition.)进行预测(这个没看过..)
对于多模态关系抽取,作者在原来的文本描述上,加入\([CLS]\) token,最后预测\([CLS]\)是目标关系的概率:

对于MNER和MRE任务,使用A Fast and Accurate One-Stage Approach to Visual Grounding. ICCV 2019 导出前\(m\)个visual objects。
对于MMKGC任务,直接使用整个图像。
2.2 Hybrid Transformer Architecture
首先是原始的Transformer结构,MHA表示多头注意力,FFN表示前馈网络。
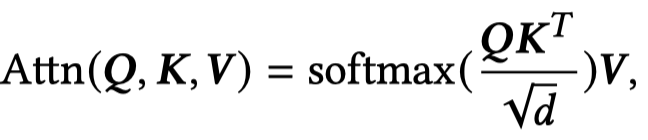
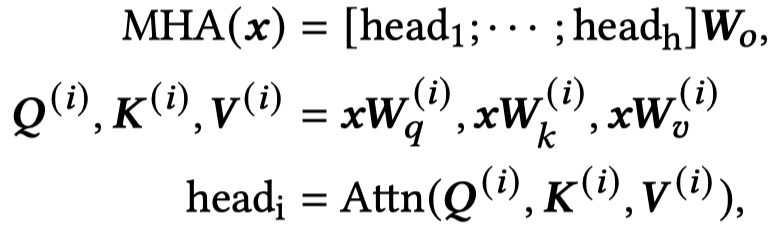
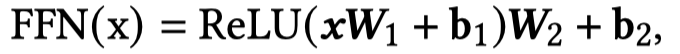
V-Encoder,ViT:
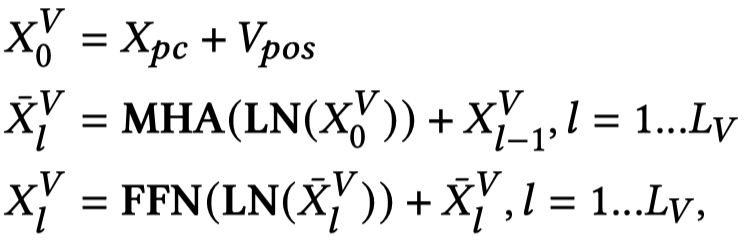
T-Encoder,BERT:
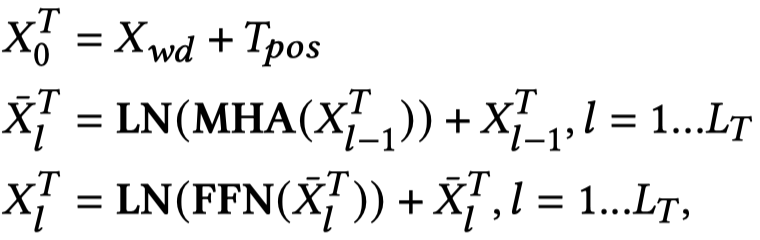
M-Encoder,在V-Encoder和T-Encoder之间,先PGI,再CAF:
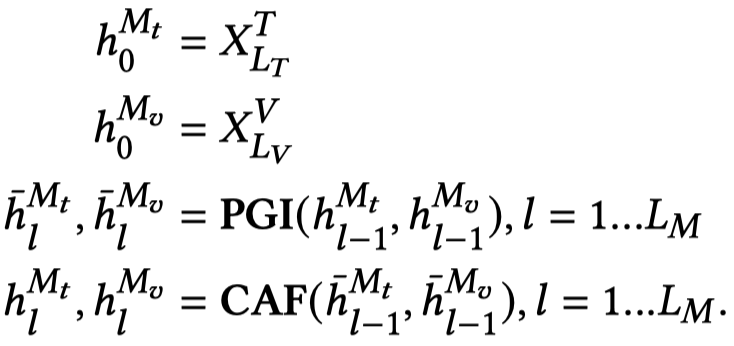
2.3 Insights of M-Encoder
2.3.1 PGI
对于PGI(Prefix-guided Interaction Module),作者是受到了前面研究的影响(Prefix-Tuning: Optimizing Continuous Prompts for Generation和Towards a Unified View of Parameter-Efficient Transfer Learning.)。
作者在自注意力层,让visual Transformer侧考虑聚合textual信息,通过让visual query和textual key,textual value进行操作。实际上是询问当前的patch image和哪些token更接近,然后聚合token embedding。视觉侧的query,文本侧和视觉侧的key,文本侧和视觉侧的value:
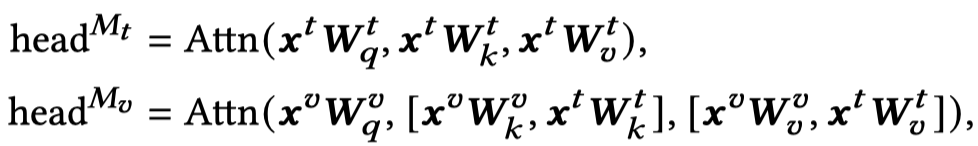
很简单的操作,应该是直接拼接。作者进一步推算公式为:
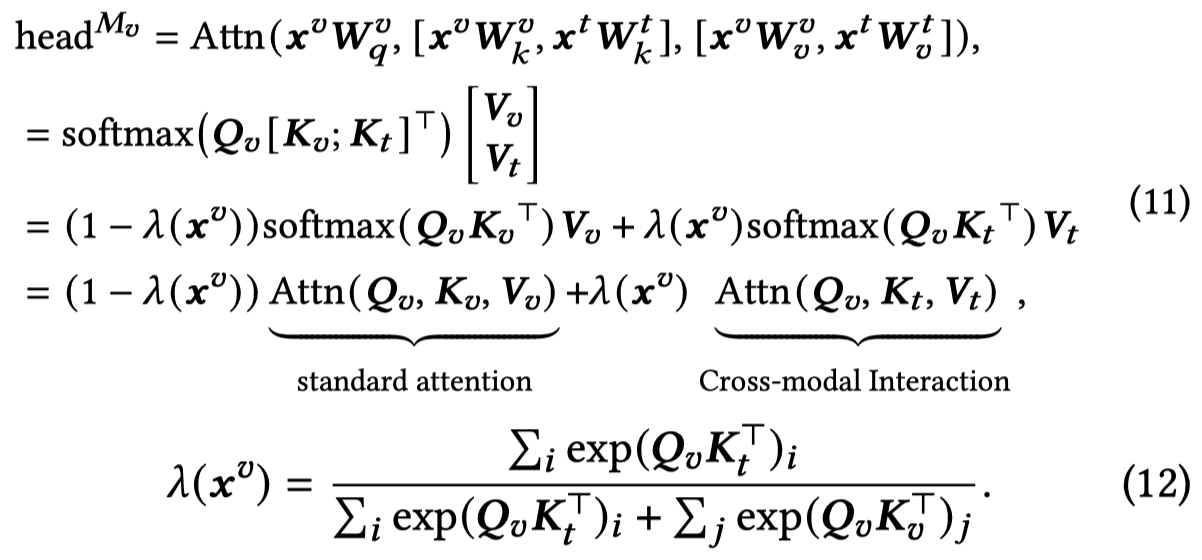
这里我没有直接推算出来。但是从作者推算出的可以看出来,实质上它是降低了原来单纯的visual attention,增加了文本-图像的跨模态注意力。
2.3.2 CAF
对于CAF(Correlation-aware Fusion Module),作者受到前面研究的影响,之前有人发现Transformer中的FFN层能够学习到task-specific textual pattern(Transformer Feed-Forward Layers Are Key-Value Memories)。因此作者通过计算token embedding和patch embedding之间的相似性矩阵来衡量视觉信息的重要性。
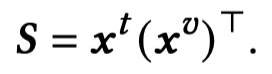
然后聚合视觉信息,文本侧的query,视觉侧的key,视觉侧的value:
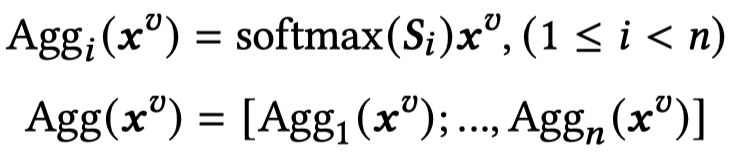
上述过程实际和自注意力的过程是一样的。最后把聚合的视觉信息和原来的文本信息拼接到一起:
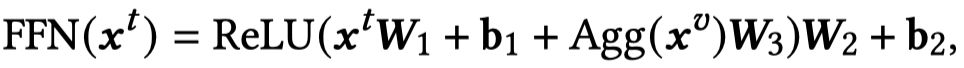
回顾下上述两个过程,作者都是没有直接创建新的layer进行信息融合,而是通过让信息在dual Transformer之间进行流通。因为作者提出图像的信息噪音很大,对自注意力层和全连接层的改造都是围绕这一点来的。先在注意力层让文本信息流通到视觉信息上,让V-Encoder侧能够考虑文本信息,而不是单纯在patch之间聚合信息。试想下,如果让视觉信息流通到文本信息上,那么就意味着视觉的噪音直接加入到了文本侧,不太合适。随后,在全连接层让已经考虑了文本信息的视觉信息,再流通回文本侧,进一步降低视觉噪音。
3 Experiments
3.1 Experimental Setup
数据集:
- 链路预测:WN18-IMG和FB15k-237-IMG,都是原来的数据集的实体分别关联到了10个image。
- 关系抽取:MNRE数据集,人工构造,来源Twitter。
- 命名实体识别:Twitter-2017,包括了2016-2017年间用户的多模态posts。
训练设置:
在所有的情况下,M-Encoder保持3层,基于BERT_base和ViT-B/32。
3.2 Overall Performance
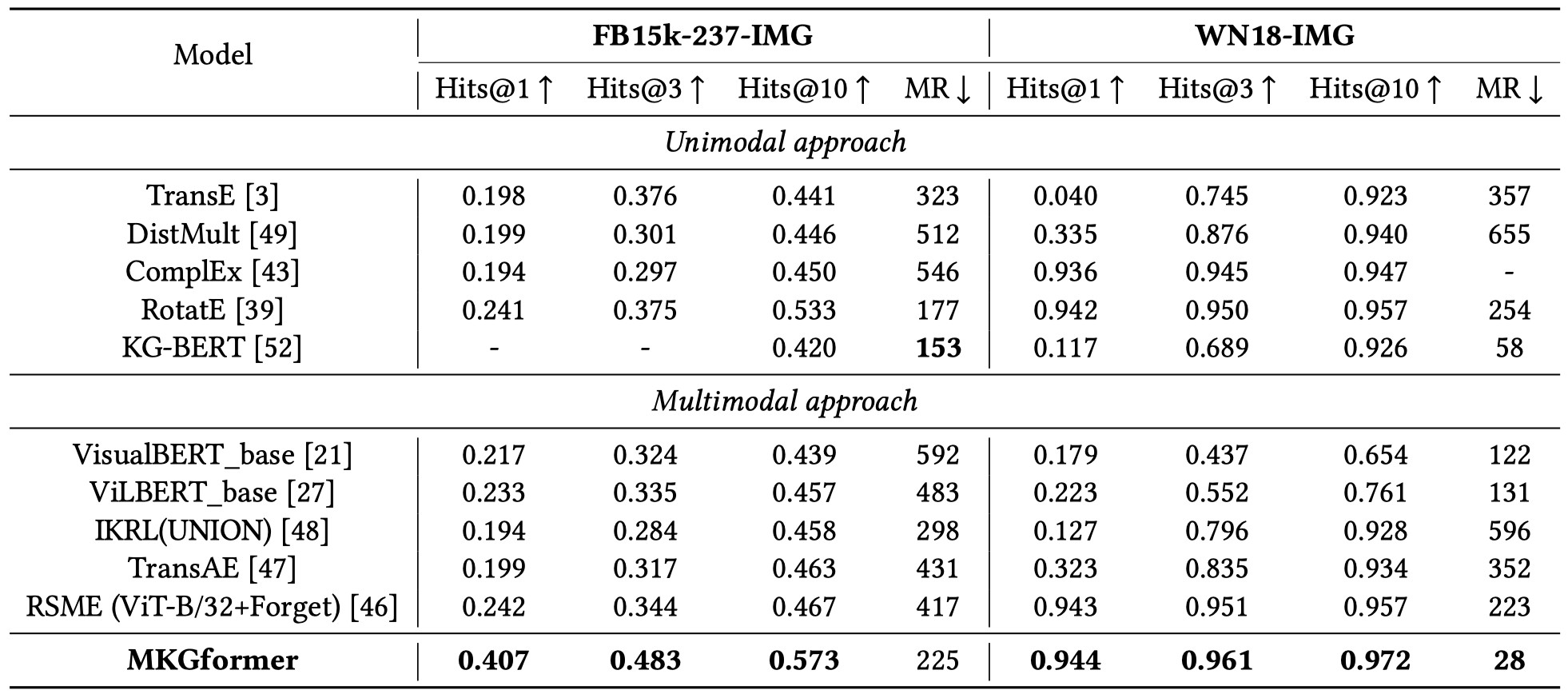
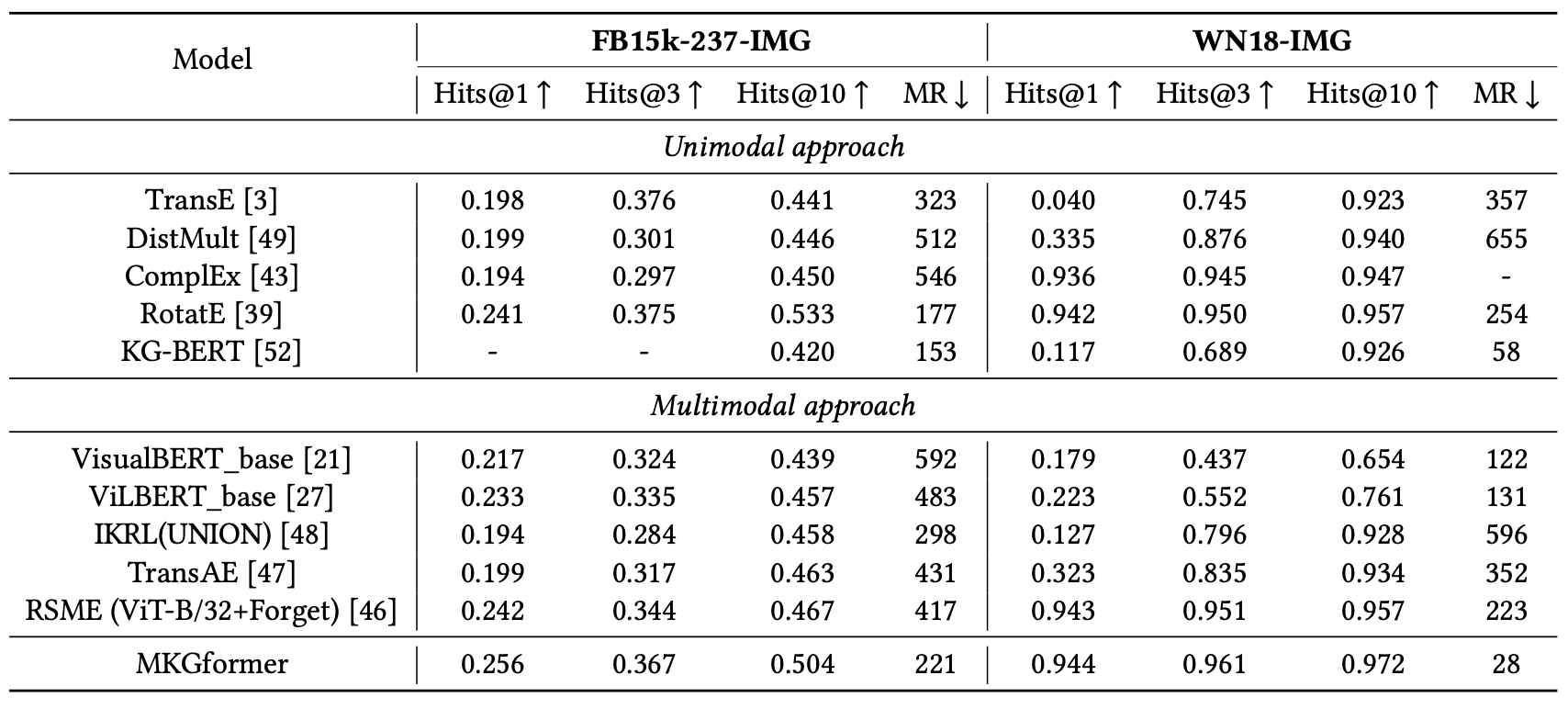
链路预测(作者提到了,原来的论文中对于FB15k-237-IMG的结果由于作者代码对于数据处理错误,因此出现了错误的性能提升,作者在arxiv上上传了更新后的结果):
原论文结果:
更新后的结果,可以看出来结果变化挺大
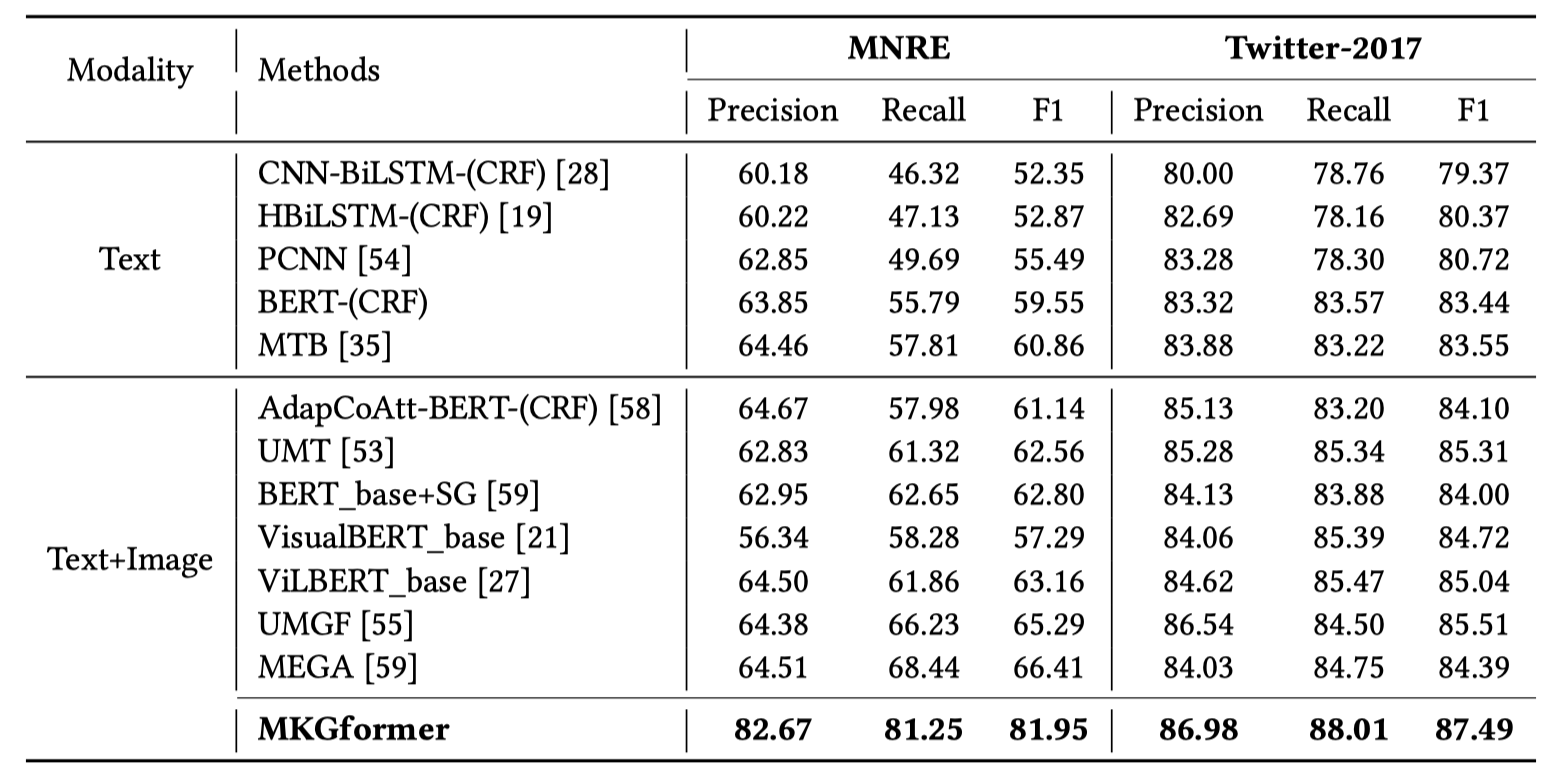
关系抽取和命名实体识别:
3.3 Low-Resource Evaluation
作者认为对文本和图像,使用类似的网络结构进行处理,降低了差异性,在低资源预测任务中这种作用更加突出。在数据量更少的情况下,需要想办法更好的处理数据模态之间的差异性,因此模型对于不同模态的差异性的处理能力可能需要更加突出。
在低资源的设置下,作者发现直接把视觉-语言预训练模型应用到KGC任务上,并没有表现出特别优越的性能。作者认为可能是原来的预训练数据和KGC任务相关性不是特别相关的原因。
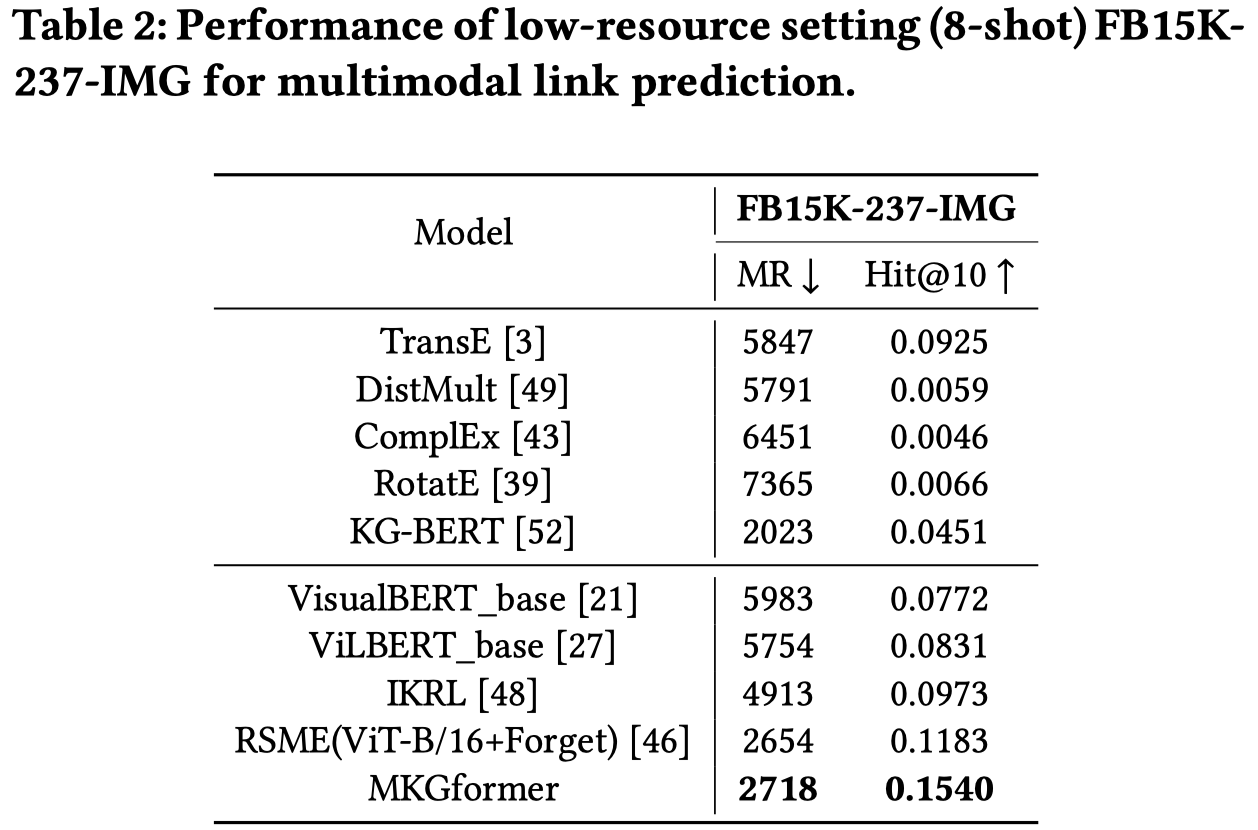
低资源链路预测:
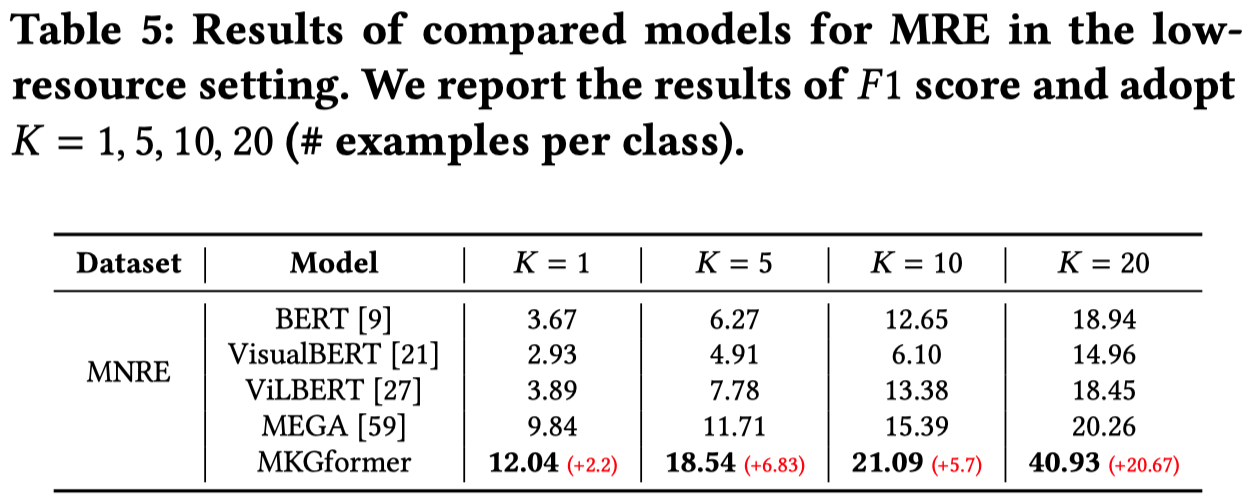
低资源关系抽取:
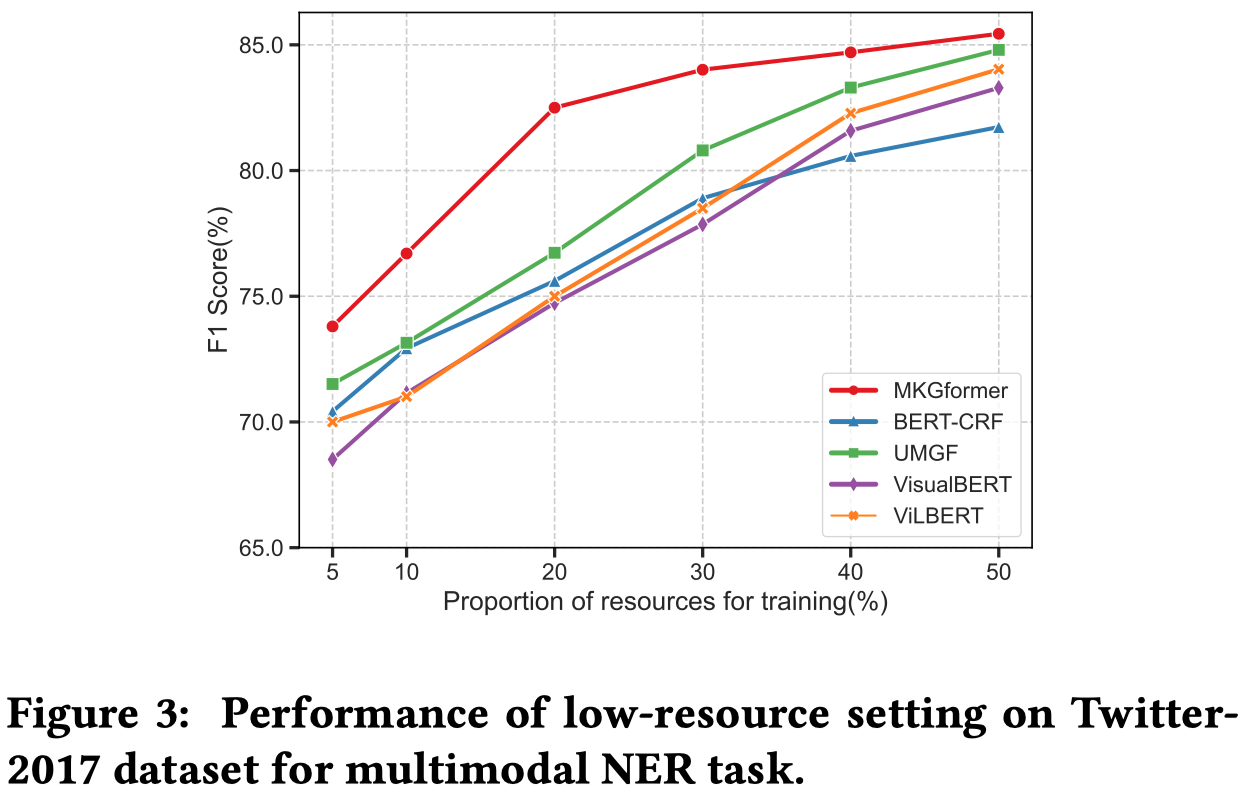
低资源命名实体识别:
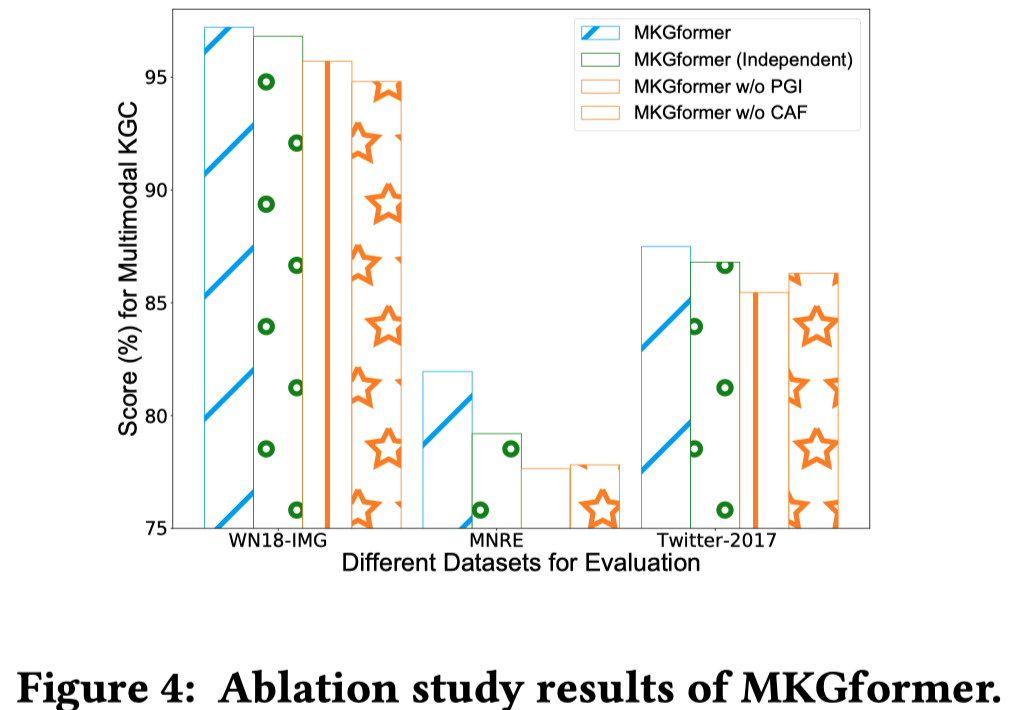
3.4 Ablation Study
3.5 Case Analysis for Image-text Relevance
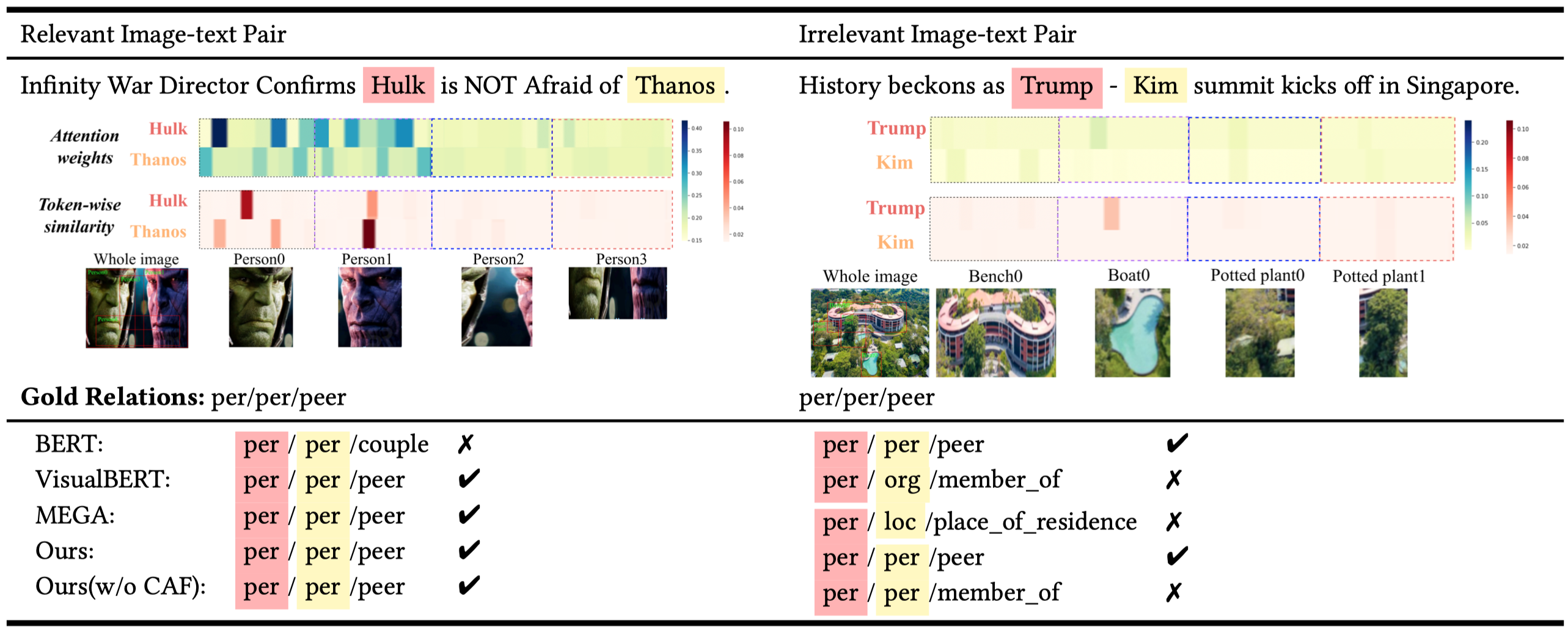
从这个实际案例可以看出,图像确实和整个描述文本是相关的,但是图像不一定能够对应到所需要的实体。并且,一个图像中存在很多不需要的噪音。