IKRL
Image-embodied Knowledge Representation Learning
清华大学2017年发表在IJCAI上的paper,IKRL,应该是第一个把图像信息注入到KGE中的方法。
基于TransE的思想,为不同的entity学习一个额外的image embedding,然后image embedding和原来的entity embedding通过\(h+r\approx t\)评估三元组是否成立。
Entity images could provide significant visual information for knowledge representation learning. Most conventional methods learn knowledge representations merely from structured triples, ignoring rich visual information extracted from entity images. In this paper, we propose a novel Imageembodied Knowledge Representation Learning model (IKRL), where knowledge representations are learned with both triple facts and images. More specifically, we first construct representations for all images of an entity with a neural image encoder. These image representations are then integrated into an aggregated image-based representation via an attention-based method. We evaluate our IKRL models on knowledge graph completion and triple classification. Experimental results demonstrate that our models outperform all baselines on both tasks, which indicates the significance of visual information for knowledge representations and the capability of our models in learning knowledge representations with images.
1 Introduction
作者首先举了一个例子来说明图片包含了能够辅助建模KGE:

关系\(has\ part\)是一个spatial relation,它在图像体现的信息就比单纯在文本上要丰富,与action relation一样都比较适合可视化。但是要注意有很多的relation是很难可视化的,单纯在图像上也不太好进行推测,除非图像本身包含了明确的信息。比如关系\(spouse\),我们无法单纯从两个男女的照片上判断是不是配偶,但如果有两个人结婚的照片,我们就可以推测他们是配偶。
2 Method
作者的方法:
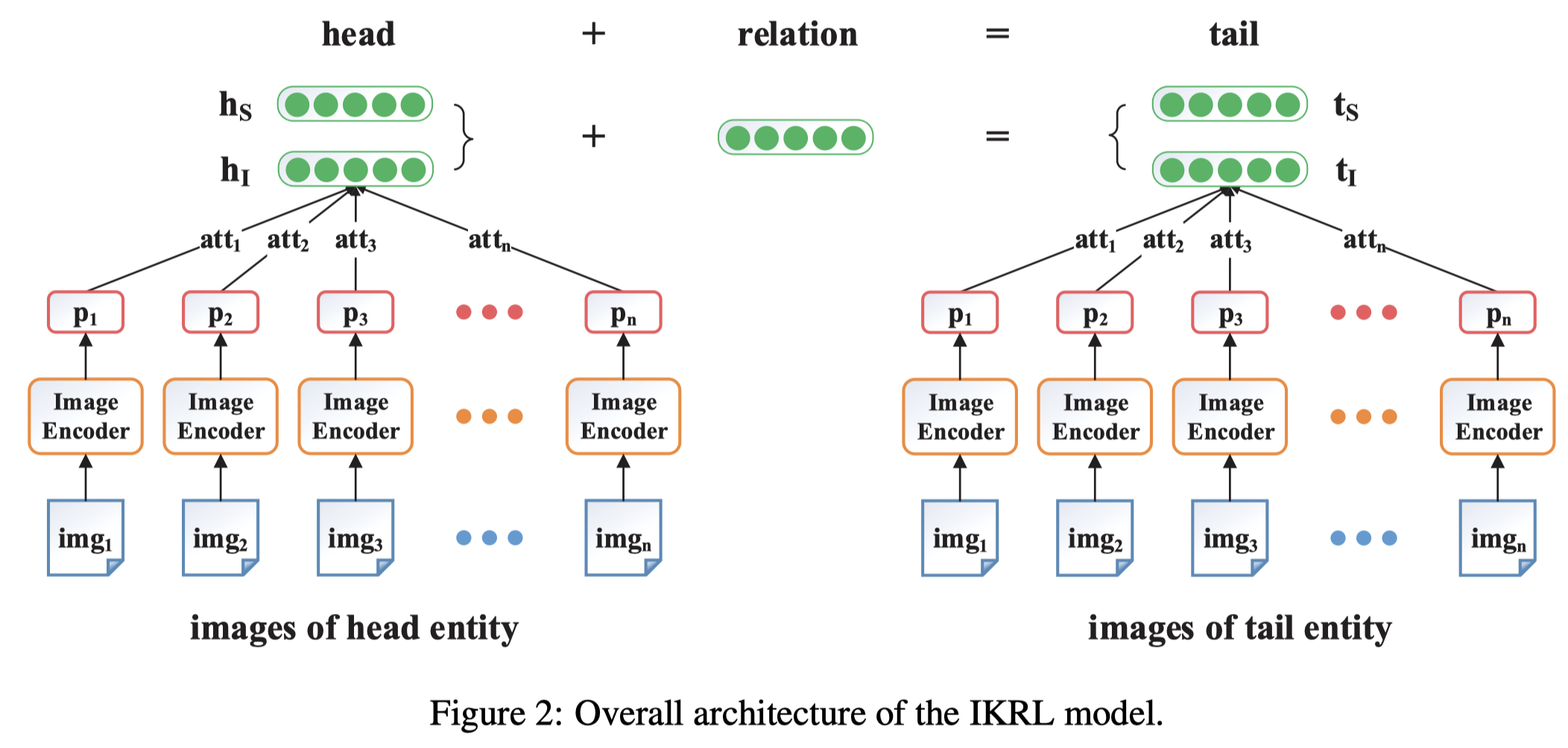
主要就是多了一个image embedding \(e_I\),在获得了image embedding后,进行translation-based的推测:
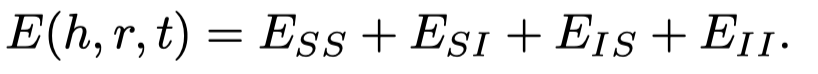
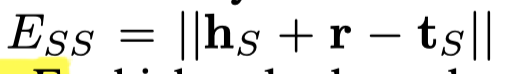
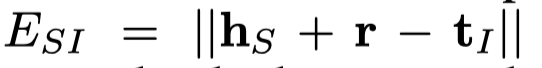

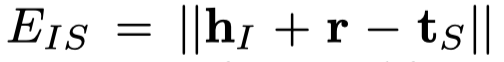
如何获得image embedding?作者通过AlexNet(5卷积层+2全连接层)获得image representation,然后投影至entity space:
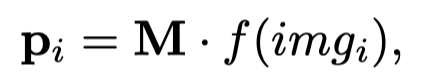
然后结合注意力聚合:
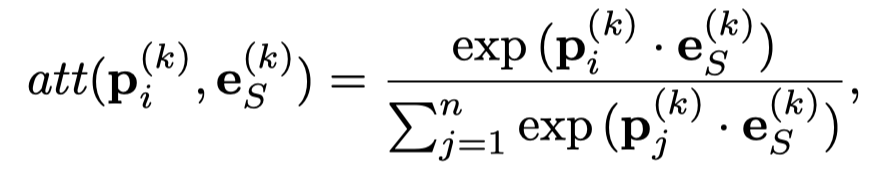
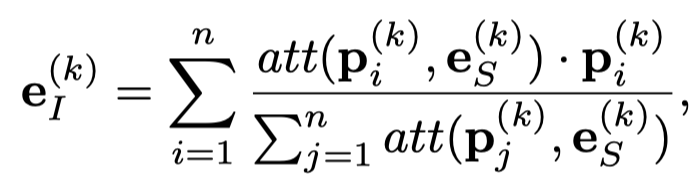
3 Experiments
值得一提的是,作者构造了一个新的数据集WN9-IMG,可惜的是效果已经要做到顶了。
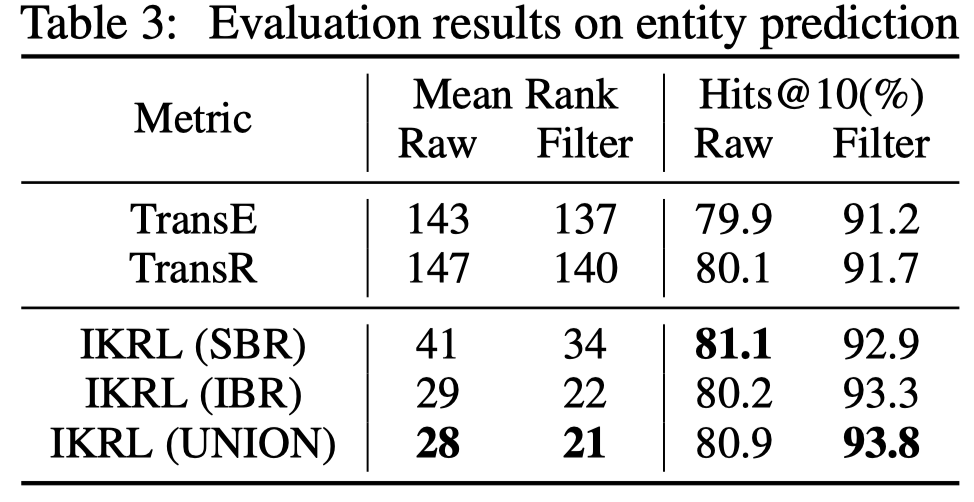
链路预测结果:
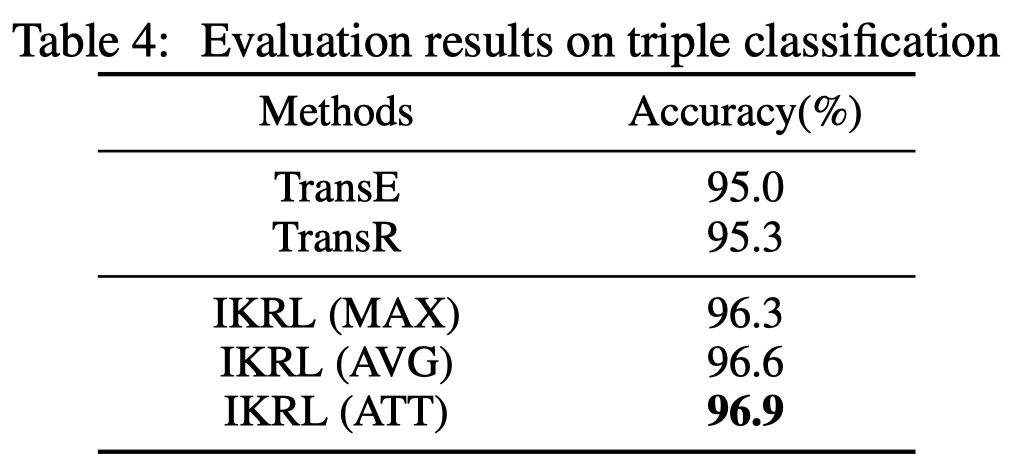
三元组分类结果(判断三元组是否成立),通过计算\(||h+r-t||\)是否高于阈值\(\delta_r\),\(\delta_r\)是一个可训练参数,通过评估在验证集下的效果进行更新:
Conclusion
一个比较简单直接的基于TransE的MM KGE方法,把图像信息注入到实体表示中。有以下缺点:
- 以image为单位进行attention过于粗糙,明显会带来大量的noise;并且从作者的实验来看,attention效果不够显著。
- 没有融合text information,算不上真正的多模态(不把单纯的三元组看做是一种模态的话)。
- 实际上学习到的image embedding也没有真正的融合到entity embedding中,仅仅独立存在着作为预测效果的一部分。entity embedding只是被用来评估那个image embedding更重要而已。