FL-MSRE
FL-MSRE: A Few-Shot Learning based Approach to Multimodal Social Relation Extraction
AAAI 2021,代码。
Social relation extraction (SRE for short), which aims to infer the social relation between two people in daily life, has been demonstrated to be of great value in reality. Existing methods for SRE consider extracting social relation only from unimodal information such as text or image, ignoring the high coupling of multimodal information. Moreover, previous studies overlook the serious unbalance distribution on social relations. To address these issues, this paper proposes FL-MSRE, a few-shot learning based approach to extracting social relations from both texts and face images. Considering the lack of multimodal social relation datasets, this paper also presents three multimodal datasets annotated from four classical masterpieces and corresponding TV series. Inspired by the success of BERT, we propose a strong BERT based baseline to extract social relation from text only. FL-MSRE is empirically shown to outperform the baseline significantly. This demonstrates that using face images benefits text-based SRE. Further experiments also show that using two faces from different images achieves similar performance as from the same image. This means that FL-MSRE is suitable for a wide range of SRE applications where the faces of two people can only be collected from different images.
作者在这篇工作中,创建了包括文本和脸部图像的多模态social relation extraction数据集,Dream of the Red Chamber (DRC-TF), Outlaws of the Marsh (OM-TF) and the Four Classic (FC-TF)。红楼梦、水浒传和四大名著数据集,TF指text and face。
并且由于不同social relation的分布差异很大,作者考虑使用少次学习来解决,提出了方法FL-MSRE。
1 Introduction
motivation:之前的social relation extraction主要集中在对单模态信息的处理,忽略了多模态之间信息可能存在高耦合。比如在下图,仅仅通过文本是不能推断Obama和正在拥抱的人的实际关系的。

method:为了能够同时从text和image中导出信息,由于目前没有合适的数据集,作者在Du et al.的从四大名著导出的基于文本数据集基础上进行拓展,通过从翻拍的电视剧中提取对应人物的图像,来预测人物实体之间的关系。同时,鉴于不同relation之间的分布差异巨大,作者考虑使用少次学习来进行关系抽取。
2 Multimodal Social Relation Datasets
构造过程:
- Du et al.等人从中国四大名著的文本中导出了至少包含两个人的句子;
- 作者在此基础上,通过人工标注判断两个人之间是否存在social relation;如果两个人有多种social relation,选择最specific的relation;
- 使用FFmepg删除字幕,删除重复的图片;
- 使用FaceNet选择出至少包括两个人的图片;每个人的脸部被bounding box框出来,并且标注了是哪个角色;
最后,由于有的名著样本量太少,因此分为了三个数据集:Dream of the Red Chamber (DRC-TF), Outlaws of the Marsh (OM-TF) and the Four Classic (FC-TF)。
统计情况:
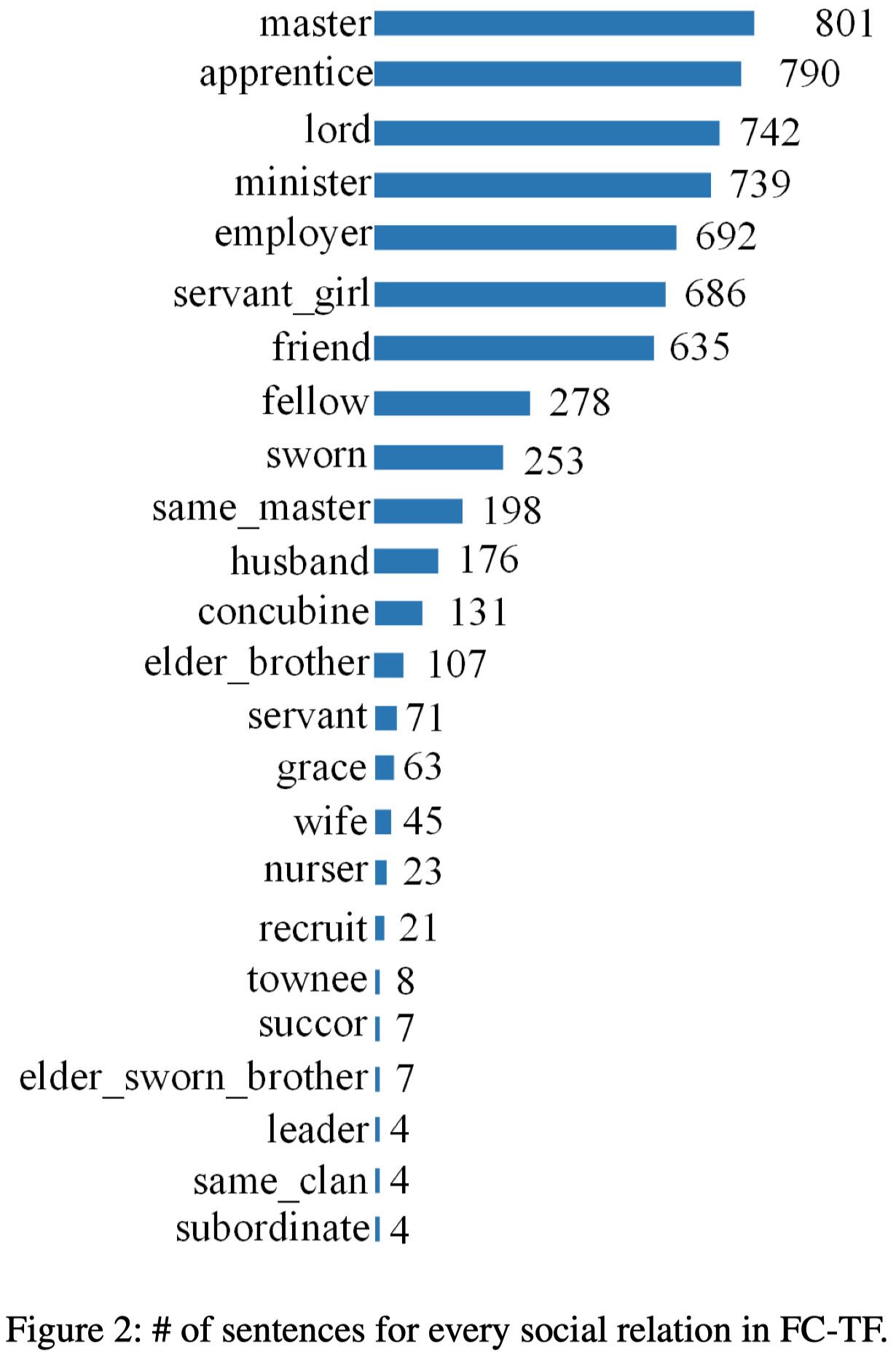
不同关系对应的句子数量:
查看下具体的数据:
Text:
1 | "servant_girl": [ |
Image:
1 | "林黛玉": { |
hlm_EP01_2282.jpg:
