EEGA
Joint Multimodal Entity-Relation Extraction Based on Edge-enhanced Graph Alignment Network and Word-pair Relation Tagging
EEGA,https://github.com/YuanLi95/EEGA-for-JMERE,AAAI 2023,联合MNER和MRE。
首个提出将MNER和MRE联合训练的方法,作者将text和image表示为两个graph,然后除了进行visual object和textual entity的对齐,还进行了object-object relation和entity-entity relation的对齐。
Multimodal named entity recognition (MNER) and multimodal relation extraction (MRE) are two fundamental subtasks in the multimodal knowledge graph construction task. However, the existing methods usually handle two tasks independently, which ignores the bidirectional interaction between them. This paper is the first to propose jointly performing MNER and MRE as a joint multimodal entity-relation extraction task (JMERE). Besides, the current MNER and MRE models only consider aligning the visual objects with textual entities in visual and textual graphs but ignore the entity-entity relationships and object-object relationships. To address the above challenges, we propose an edge-enhanced graph alignment network and a word-pair relation tagging (EEGA) for JMERE task. Specifically, we first design a word-pair relation tagging to exploit the bidirectional interaction between MNER and MRE and avoid the error propagation. Then, we propose an edge-enhanced graph alignment network to enhance the JMERE task by aligning nodes and edges in the cross-graph. Compared with previous methods, the proposed method can leverage the edge information to auxiliary alignment between objects and entities and find the correlations between entity-entity relationships and object-object relationships. Experiments are conducted to show the effectiveness of our model.
1. Introduction
作者首次提出了多模态实体-关系联合抽取任务JMERE(joint multimodal entity-relation extraction),NER任务和RE任务进行交互能够相互辅助提升预测效果。

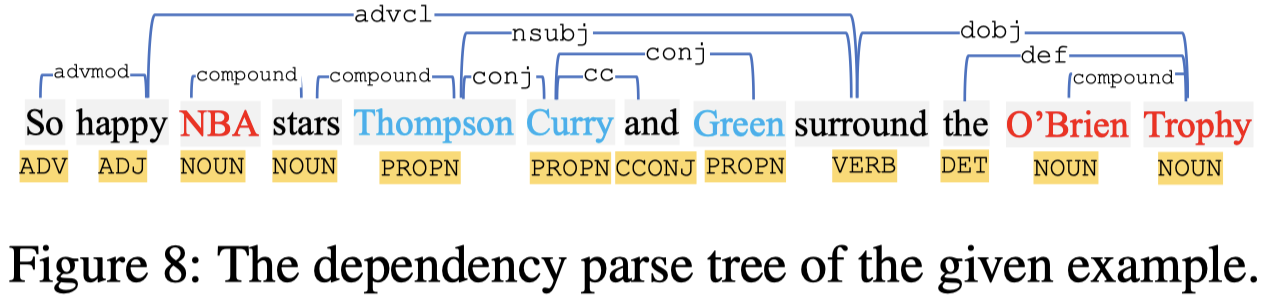
作者提出,在进行多模态信息抽取的时候,除了会类似于之前的论文要考虑object-entity的对齐,还应该考虑object-object relation和entity-entity relation的对齐。比如在上面的例子中,如果我们能够识别出image中的多个人object,那么可以辅助预测Thompson,Curry和Green可能是人;另外如果还能够知道image中的man_0和trophy的关系是holding,如果可以把holding对应到要预测的实体Thompson和O’Brien Trophy之间的关系可能是awarded。
如果把文本和实体都对应到两个graph上,就是除了要考虑node和node的对齐,还要考虑edge到edge的对齐:
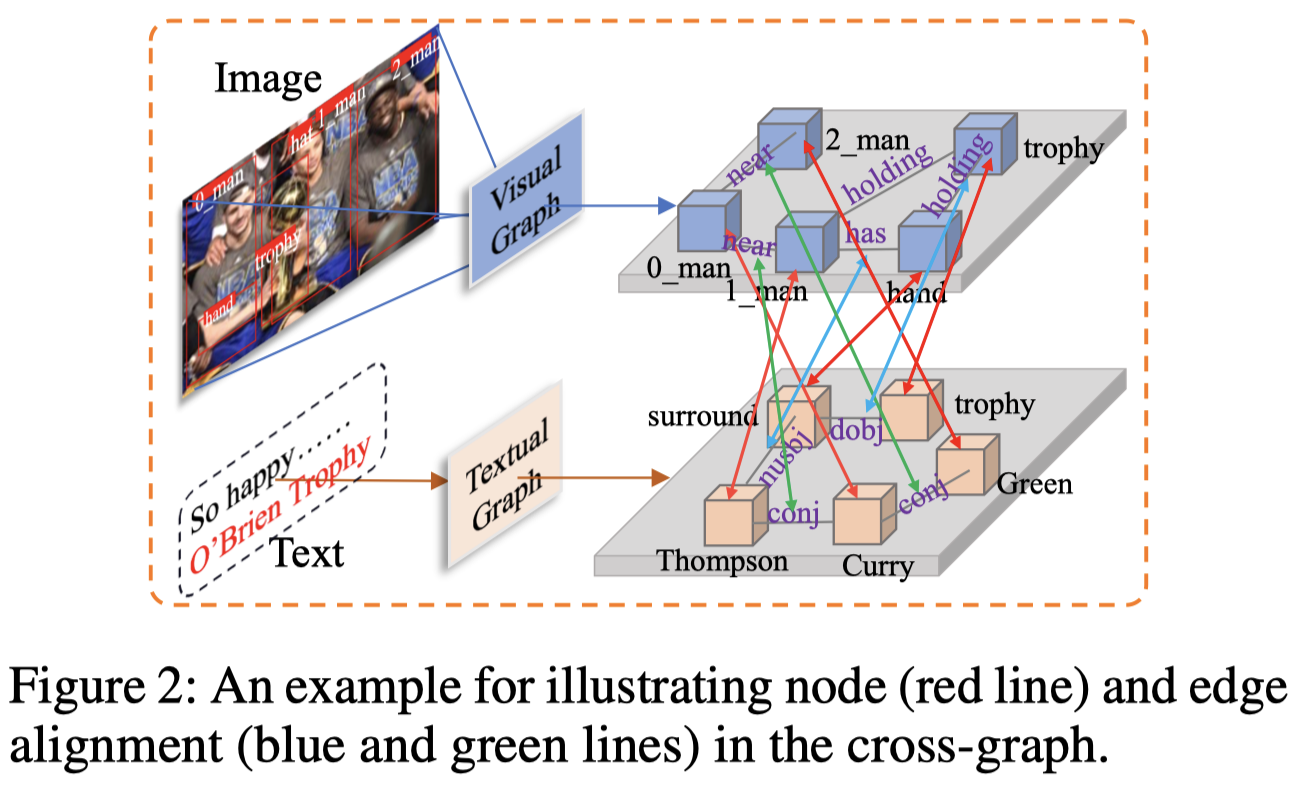
另外,考虑到如果直接拼接MNER和MRE方法形成一个pipeline的话,可能会出现error propagation的情况,也就是MNER的错误输出会导致MRE的进一步错误预测(Joint multi-modal aspect-sentiment analysis with auxiliary cross-modal relation detection. EMNLP 2021),作者提出了一个word-pair relation tagging的方法实现同时实现NER和RE(目前不清楚是不是有很多联合抽取模型都是使用了相似的方法):
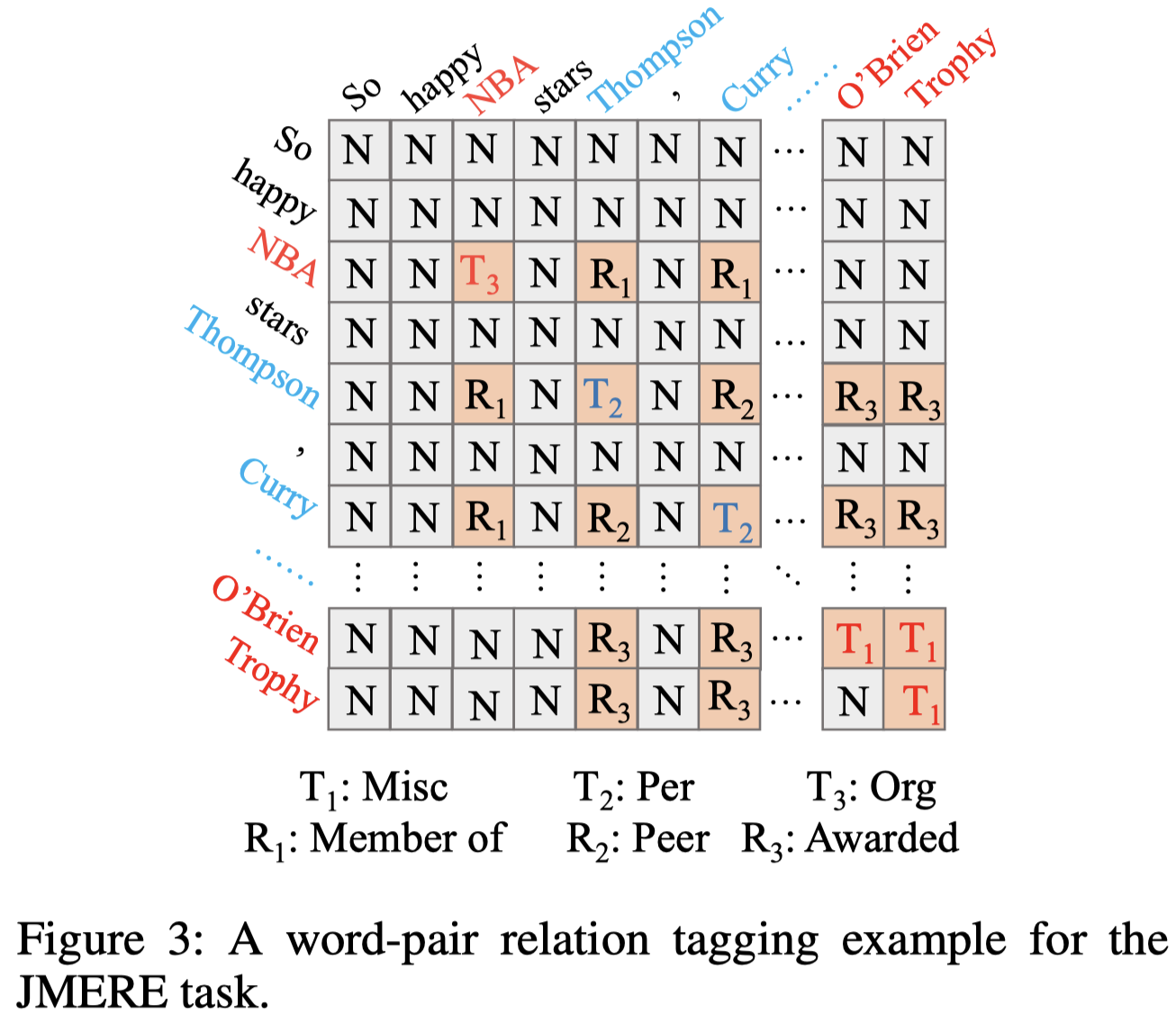
2. Method
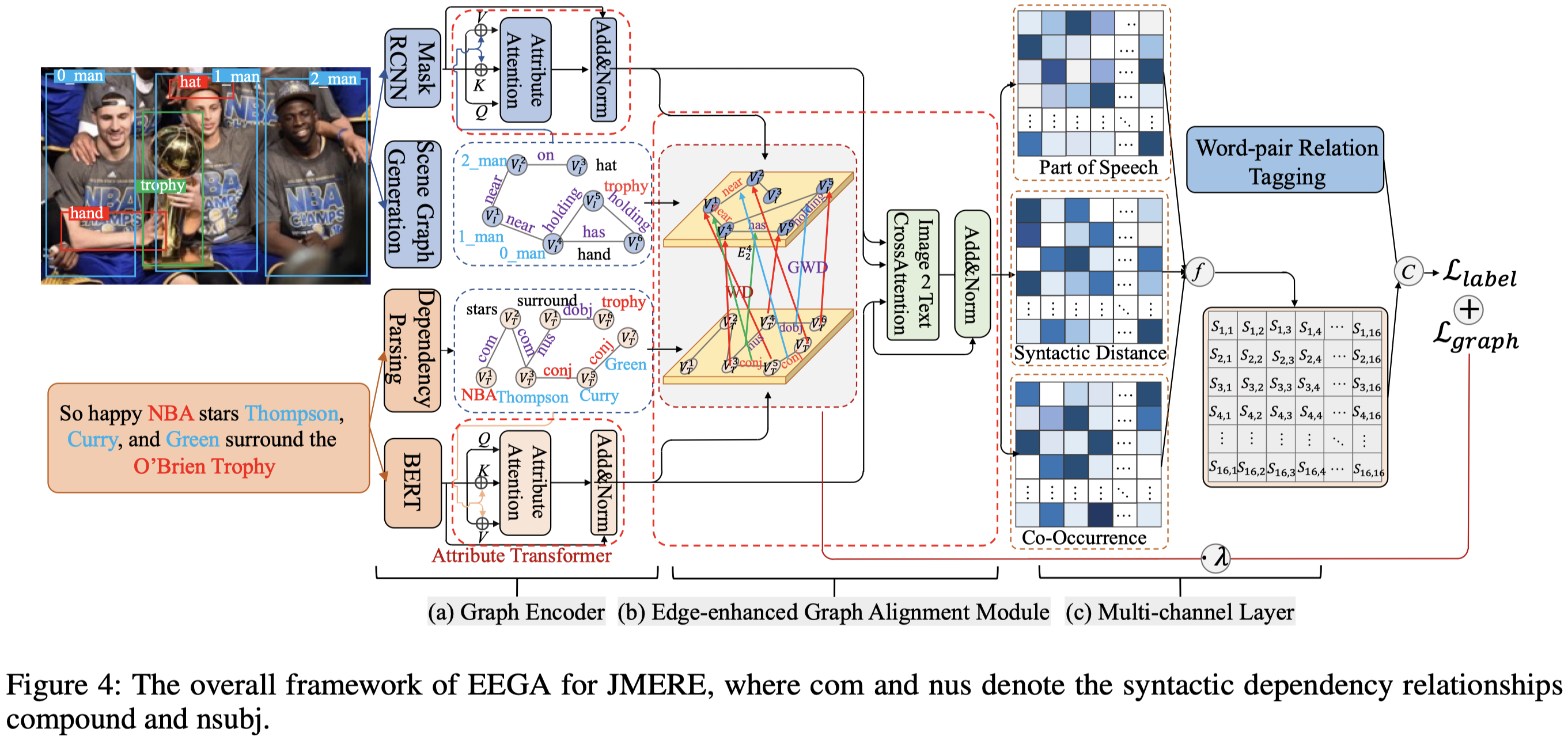
2.1 Graph Encoder
2.1.1 Textual Graph
使用语法依赖解析工具将text解析为语法依赖树,形成一个textual graph。每个node使用BERT学习到的embedding作为初始表征;每个edge也有自己的可训练embedding。
2.1.2 Visual Graph
使用Mask-RCNN作为视觉特征导出器,然后构造场景图scene graph(Unbiased scene graph generation from biased training. CVPR 2020),只保留top-k的objects。每个node使用Mask-RCNN导出的视觉embedding作为初始表征;每个edge也有自己的可训练embedding。
2.1.3 Attribute Transformer
作者进一步提出使用Transformer把edge information融合到token/object表征上,使用edge embedding作为key和value:
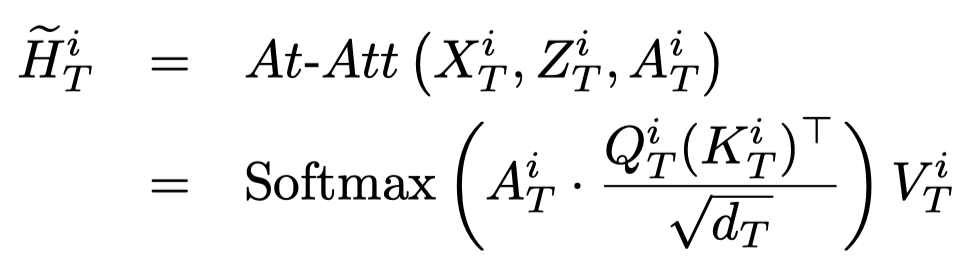
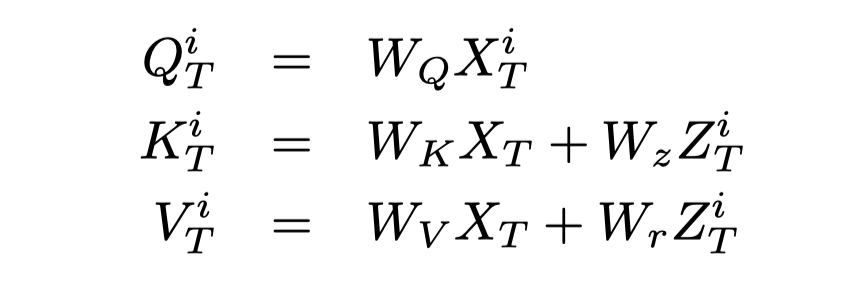
其中的\(A_T^i\in R^{1\times n}\)表示的是第\(i\)-th token的邻接矩阵,\(Z_T^i\in R^{n\times d_{zT}}\)表示的是对应的edge embedding。之后再经过FFN和layer normalization。最后得到的token embedding matrix记为\(H_T\)。
在视觉侧,也有相同结构,不同参数的attribute Transformer。最后得到的object embedding matrix记为\(H_I\)。
2.2 Edge-enhanced Graph Alignment Module
接下来,希望对两个graph的node和edge进行对齐。
2.2.1 Edge-enhanced Graph Optimal Transport
作者借鉴了在迁移学习中出现的optimal transport method进行对齐。使用了两种距离度量方法:
- Wasserstein Distance (WD) (Peyr´e, Cuturi et al. 2019) for node matching (the red lines)
- Gromov-Wasserstein Distance (GWD) (Peyr´e, Cuturi, and Solomon 2016) for edge matching(the blue and green lines)
WD:
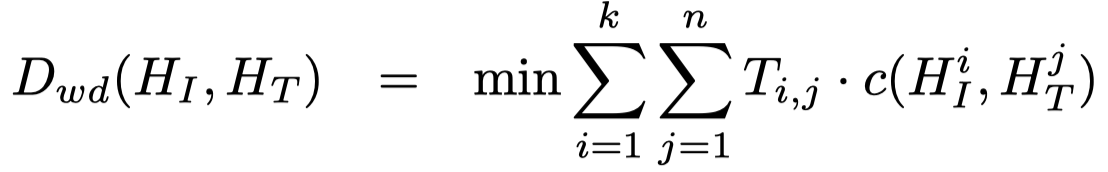
其中\(T_{ij}\)表示从\(i\rightarrow j\)所需的代价,而\(c()\)是cosine距离函数:
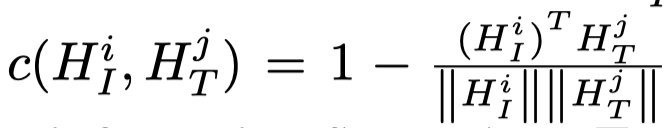
GWD:
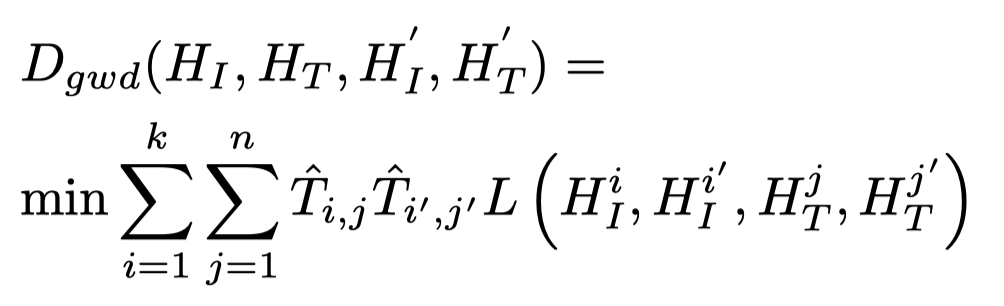
其中,\(H_I^\prime,H_T^\prime\)表示邻接节点集合。\(L()\)函数用来度量两个graph的edge之间的距离: \[ L(H_I^i,H_I^{i\prime},H_T^i,H_T^{i\prime})=||c(H_I^i,H_I^{i\prime})-c(H_T^i,H_T^{i\prime})|| \] 之后,使用下面的loss函数优化对齐的效果:
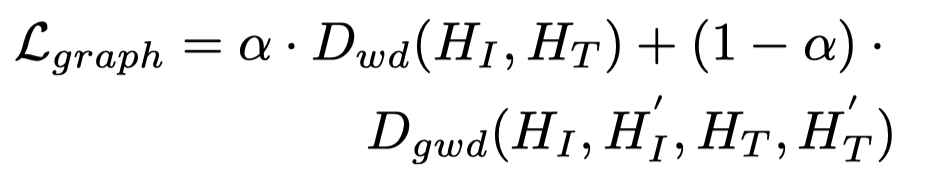
2.2.2 Image2text attention
使用Transformer,将对齐后的视觉信息融合到文本表征中:
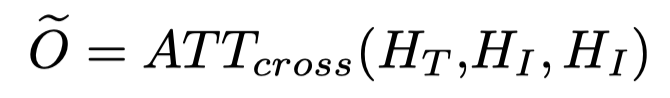
2.3 Multi-channel Layer
作者还额外的使用了三种文本的特征来辅助word-pair \((w_i,w_j)\)的关系预测:
Part of Speech (Pos):使用spaCy导出Pos特征,参考下图,把word-pair的词性向量相加作为Pos特征;
Syntactic Distance (Sd):使用word-pair之间的相对语法距离,参考下图:
Word Co-occurrences matrix (Co):使用PMI(Point-wise Mutual Information)衡量两个word在整个语料中的correlation;
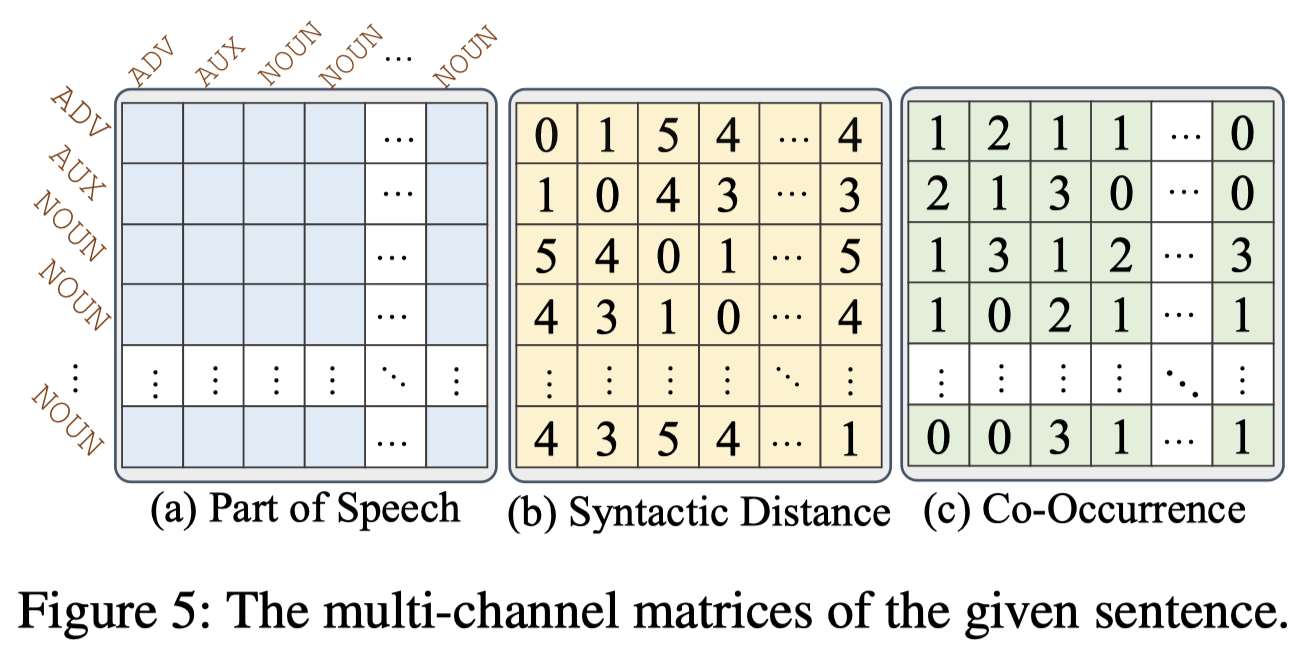
这三个矩阵被用来进一步学习文本的表征,对于每个矩阵,对于\(i-th\) word使用W-GCN聚合来自其它文本的信息:
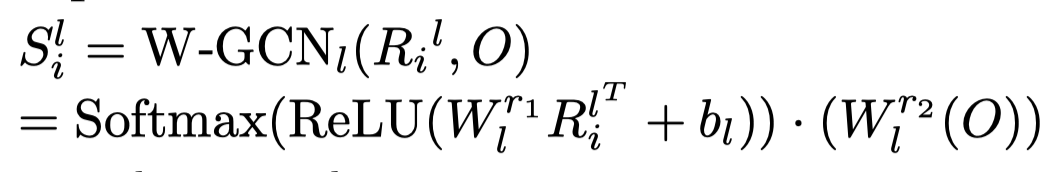
三个矩阵的结果进行拼接:
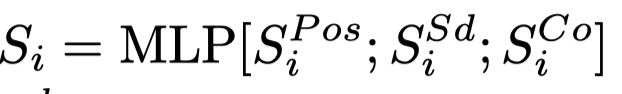
然后获得\(w_i,w_j\)的最终表征:
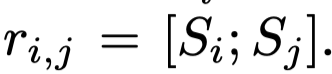
预测:
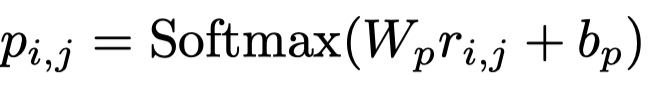
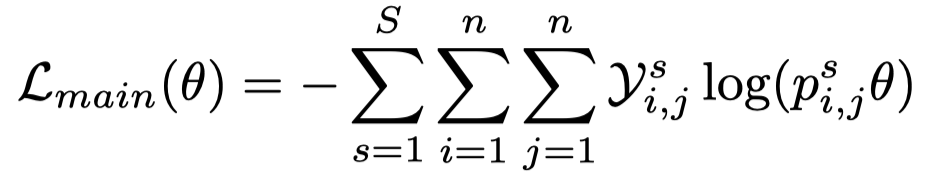
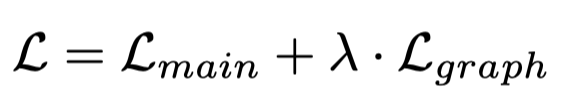
3 Experiment
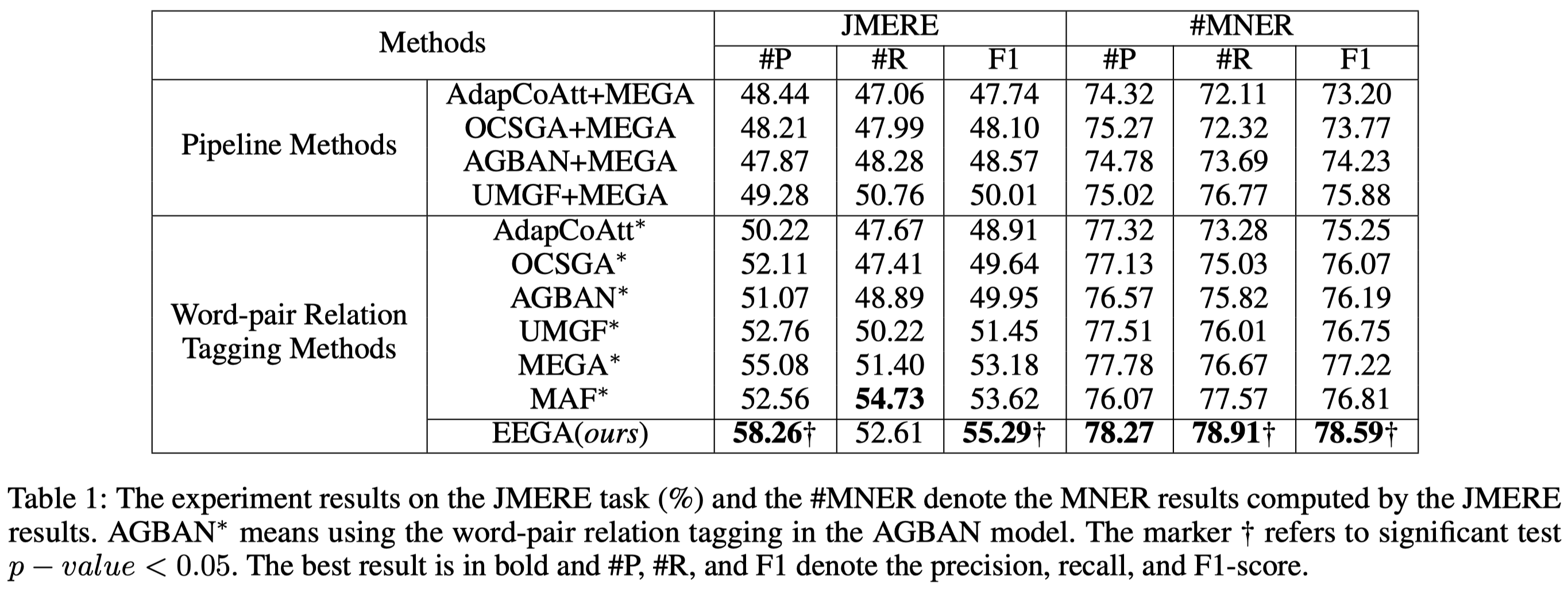
这里的数据集JMERE,是作者联合了MNRE数据集和MNER(推测应该是Twitter-2015)取交集之后的结果: