Meta-learning-intro
Meta-Learning: Learning to Learn Fast
这是一篇博客(Meta-Learning: Learning to Learn Fast)的笔记,另外参考了对应的中文博客,简单了解什么是meta-learning。
元学习尝试解决深度学习经常需要大量实例数据才能收敛的问题。我们期望好的元学习模型拥有好的泛化能力和适应能力,能够根据少量的样本就学习到比较合适的信息。
元学习可以解决一类定义好的预测任务,这篇文章主要讨论的是监督学习下的元学习问题。例如让一个图片分类器在训练集中没有猫的情况下,在测试集中能够实现只看到几张猫的图片就能够学会识别猫。
Overview
假设有很多的任务可以学习,我们期望元学习模型能够在整个的任务空间下都达到比较好的效果,即使是遇到了一个新的任务也能够表现不错。比如下面的任务:
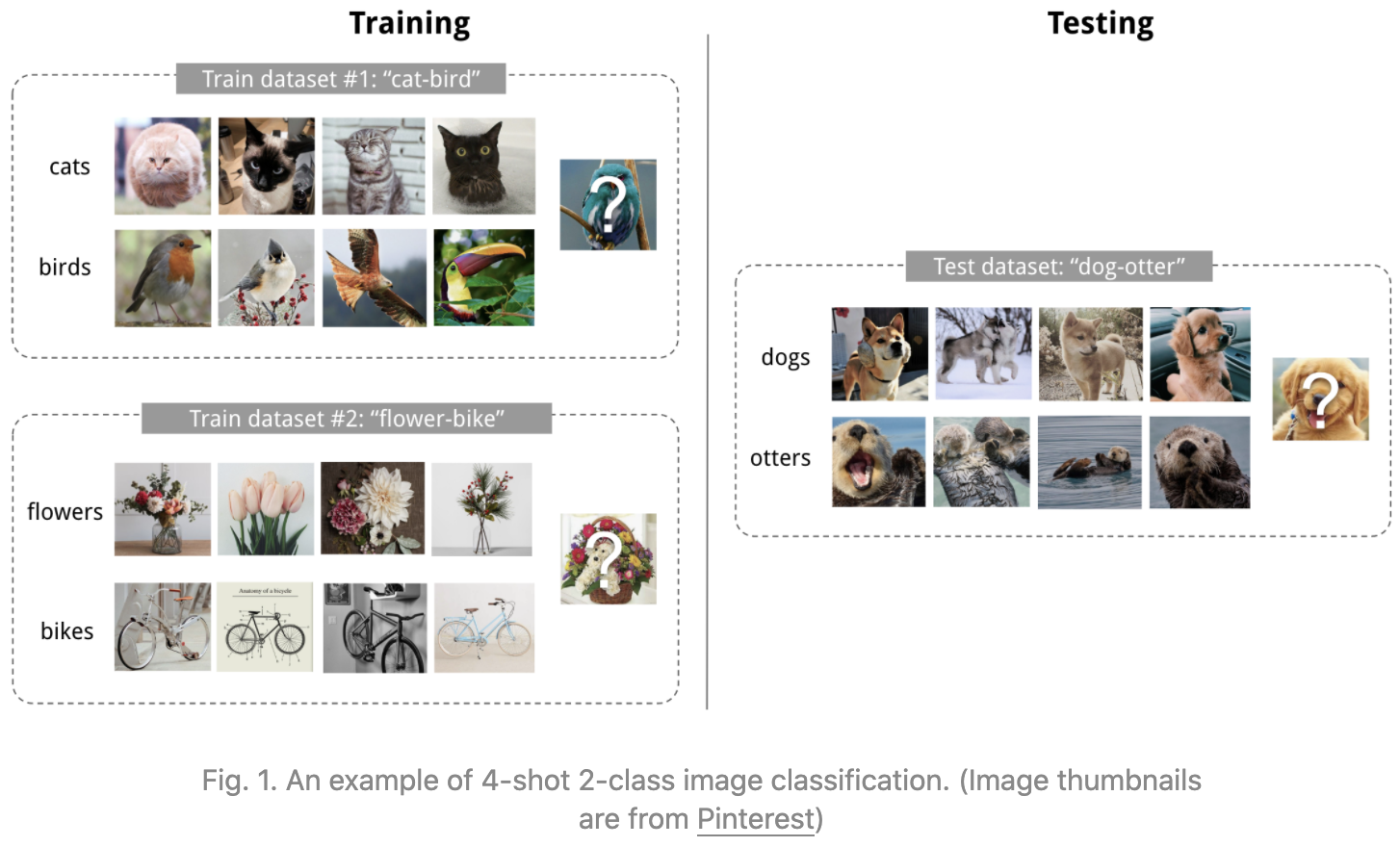
上面的任务是少次学习的一个示例图,它是元学习在监督学习问题的一个实例,一般说明K-shot N-class,是指一个数据集中class包括K个labeled examples。
为了模拟测试集中的推理过程,在训练的时候,会尝试采样一个support set和一个prediction set,support set用来计算一次loss,然后假梯度下降,使用这个假更新后的参数计算模型在prediction set上的loss,计算梯度,使用这时候的梯度才真正的更新原来的梯度。

通过上面的操作,让梯度下降的方向不是当前loss的梯度,而是“往前看了一步”,让梯度朝着更能拟合新的prediction task的方向优化。
接下来介绍三类经典的meta-learning模型。
Metric-Based
基于度量的方法,核心思想是计算新的样本和当前support set中的样本的相似程度,让后让已有的样本提供信息。
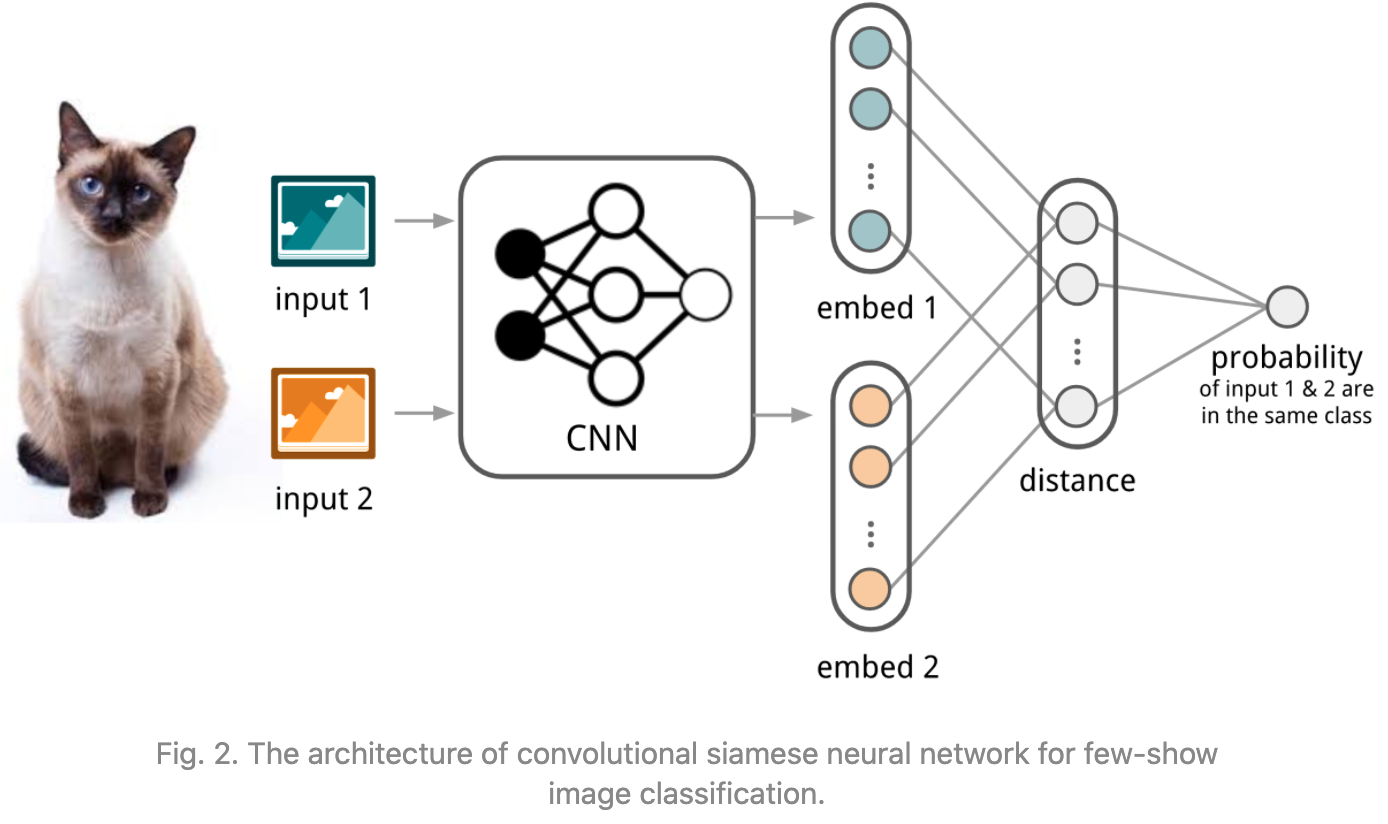
Siamese Neural Networks
Koch, Zemel & Salakhutdinov提出。对于one-shot任务,设计一个CNN网络导出图片特征,然后分辨两个图片对于的embedding的相似程度(使用L1-distance),如果属于同一类就输出1,否则输出0。在测试的时候,让测试样本和support set中所有的图片计算相似度,最相似的那一个图片对应的类就是测试样本的类别。
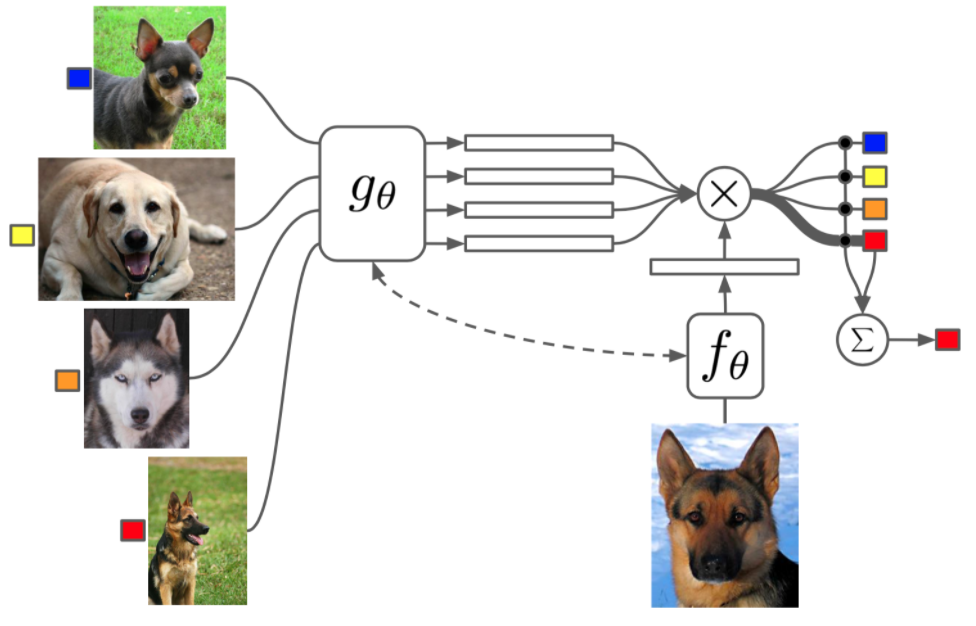
Matching Networks
Vinyals et al., 2016提出。对于K-shot任务,使用下面的方法:
核心公式:
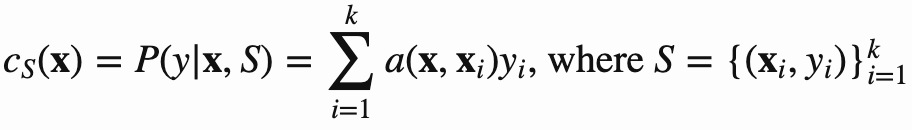
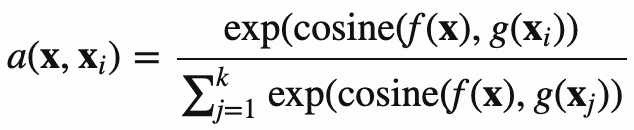
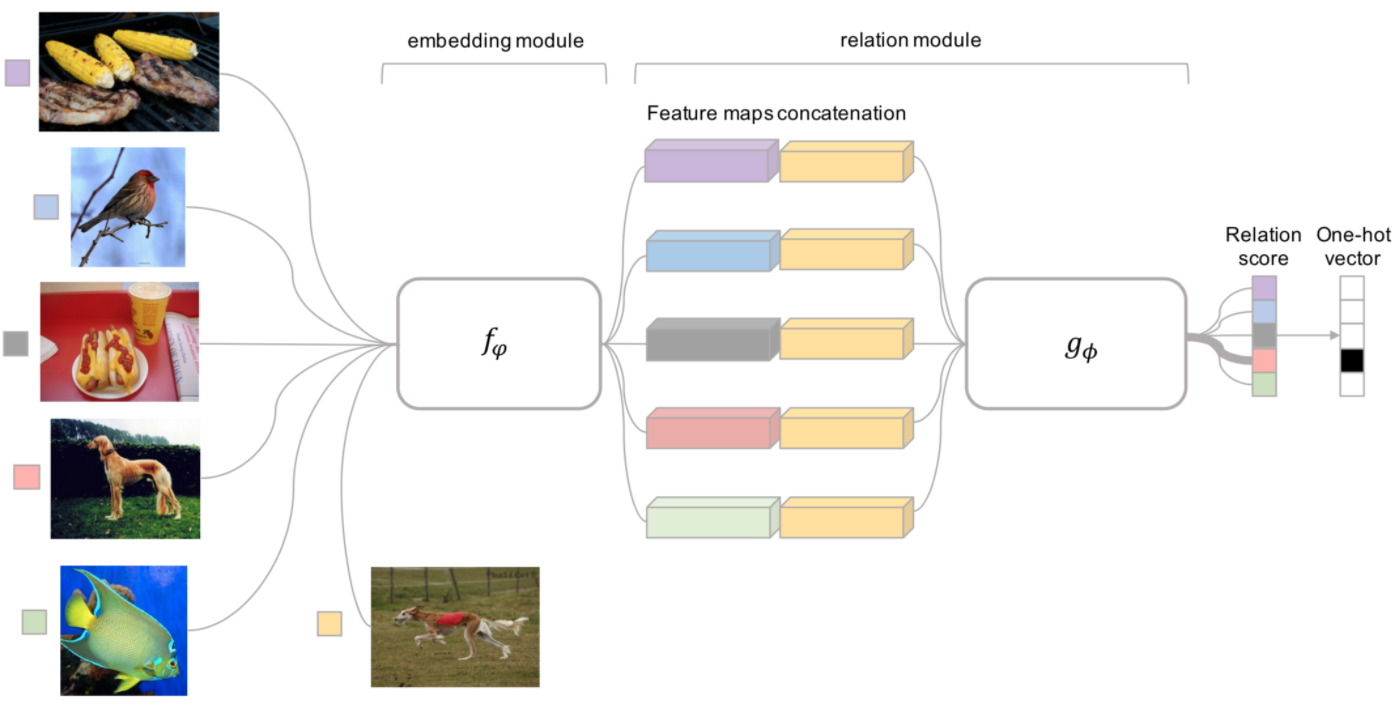
Relation Network
Sung et al., 2018提出。样本的相似度计算是使用一个CNN方法\(g_{\phi}\)来实现的。
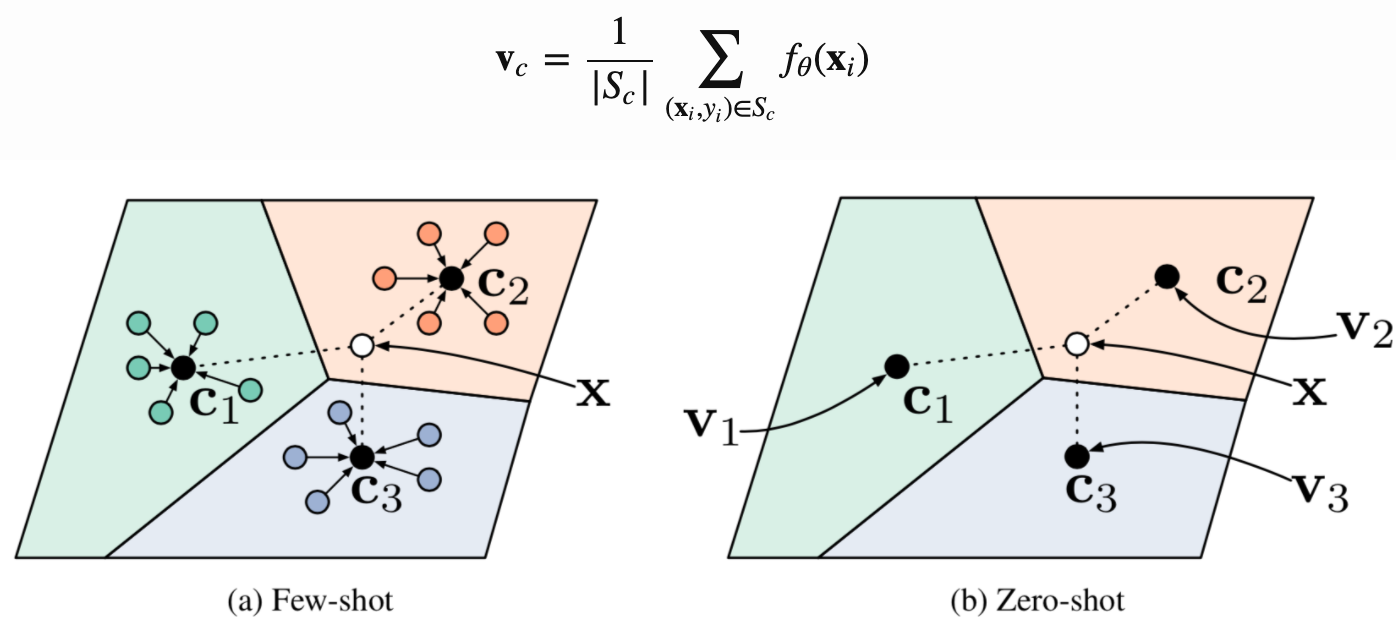
Prototypical Networks
Snell, Swersky & Zemel, 2017提出。
Model-Based
让模型本身拥有快速学习的能力。
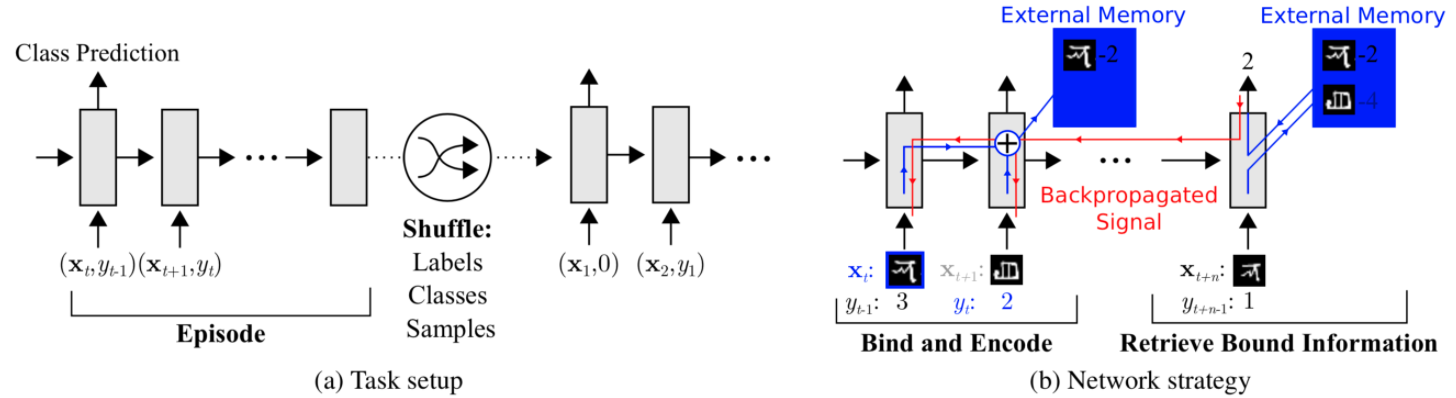
MANN for Meta-Learning
Santoro et al., 2016提出。以NTM模型为基础让拥有外部存储单元的MANN(Memory-Augmented Neural Networks)模型(注意,仅仅是GRU和LSTM这些不属于MANN)适用于元学习。
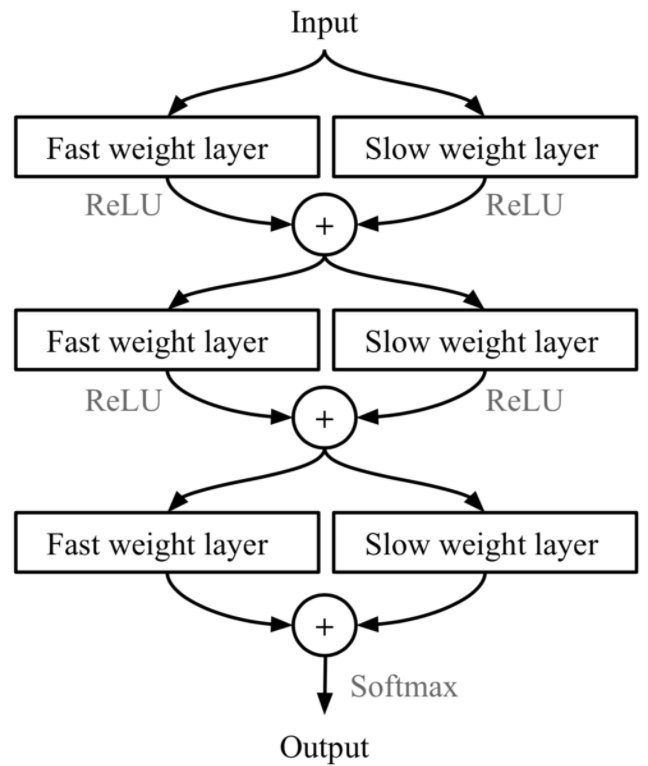
MetaNet
Munkhdalai & Yu, 2017提出。这里的fast weights和slow weights需要进一步了解。
Optimization-Based
不再依赖于具体的模型,而是直接从梯度下降的原理出发进行设计。
LSTM Meta-Learner
适用LSTM来显式建模梯度下降的过程。Ravi & Larochelle (2017)提出。
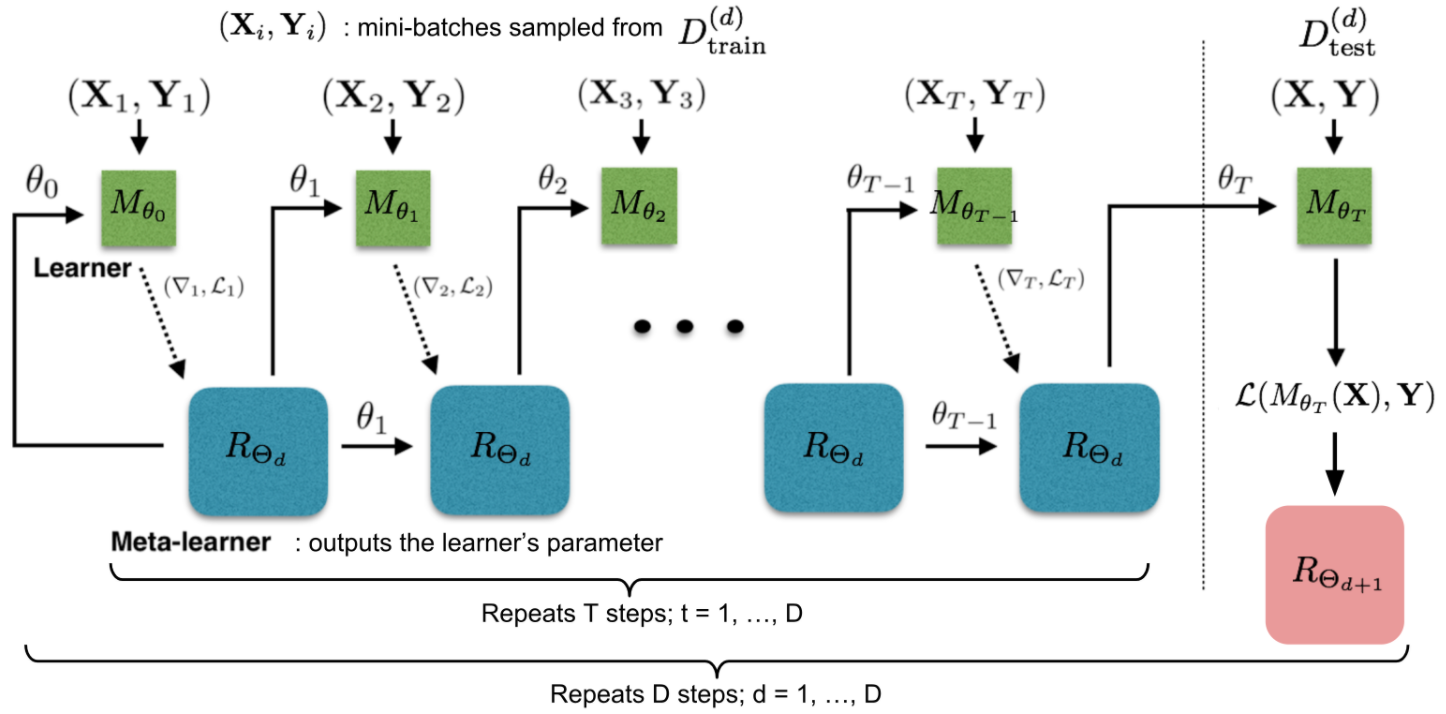
把梯度下降,看做是一步LSTM中的状态更新:
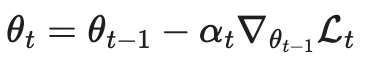
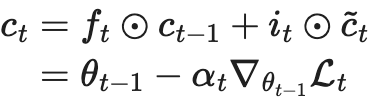
然后使用LSTM来显式的建模梯度下降步骤:
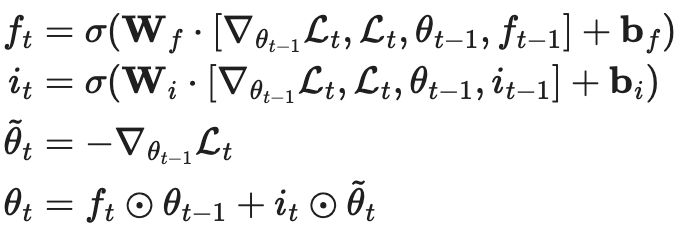
MAML
Model-Agnostic Meta-Learning 简称 MAML (Finn, et al. 2017),是一种通用的优化算法,

使用不同task,分别计算梯度,然后再使用prediction set进行实际的参数更新。