Attention-survey-2021
A General Survey on Attention Mechanisms in Deep Learning
TKDE 2021
Attention is an important mechanism that can be employed for a variety of deep learning models across many different domains and tasks. This survey provides an overview of the most important attention mechanisms proposed in the literature. The various attention mechanisms are explained by means of a framework consisting of a general attention model, uniform notation, and a comprehensive taxonomy of attention mechanisms. Furthermore, the various measures for evaluating attention models are reviewed, and methods to characterize the structure of attention models based on the proposed framework are discussed. Last, future work in the field of attention models is considered.
这篇文章调研了大量的注意力方法,集中在surprised learning领域。
1 Introduction
让模型模仿人的注意力(attention),只关注重要部分,忽略次要部分的思想,最早出现在CV领域,例如论文Learning to combine foveal glimpses with a third-order Boltzmann machine NIPS 2010和Recurrent models of visual attention NIPS 2014。但是我们普遍认为现在的注意力机制起源,是在NLP领域,Neural machine translation by jointly learning to align and translate ICLR 2015。
注意力受到研究人员的重视,有以下原因:
- 效果好,取得SOTA的模型往往会采用注意力方法(特别是在Transformer方法被提出后)。使用注意力方法在各个领域都被证明有效。
- 注意力机制可以很容易的和原来的base model结合,一起通过BP优化。
- 某些情况下,注意力可以为深度学习带来更合理的解释
这篇survey的贡献:
- 使用统一的描述、统一的框架描述了大量不同领域的注意力机制
- 提出注意力的一种分类法
- 评估注意力模块的不同方法
2 General Attention Model
作者讨论的模型架构分为四部分,feature model、attention model、query model和output model。
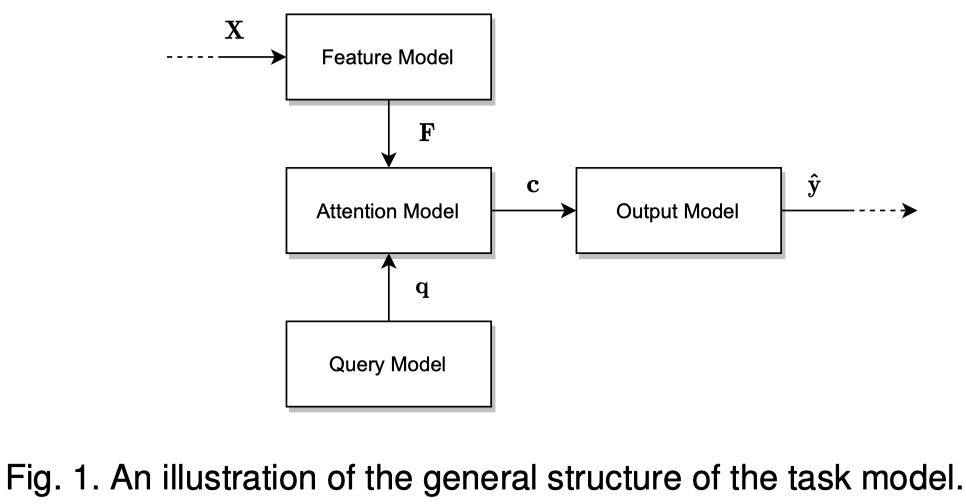
feature model是base model,也就是用来处理原始数据,进行信息提取,然后得到需要进行attention的特征向量。它可以是CNN、RNN、GNN等各种网络网络结构,假设经过feature model之后,得到了特征集合\(F\):

query model会产生查询向量,它根据此刻output model需要的context生成,用来评估各个特征向量哪个是可能更重要的:
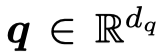
query vector可能是直接定义的某个向量;也可能是RNN中之前的隐藏状态等。
attention model是关键,它的整个过程如图:
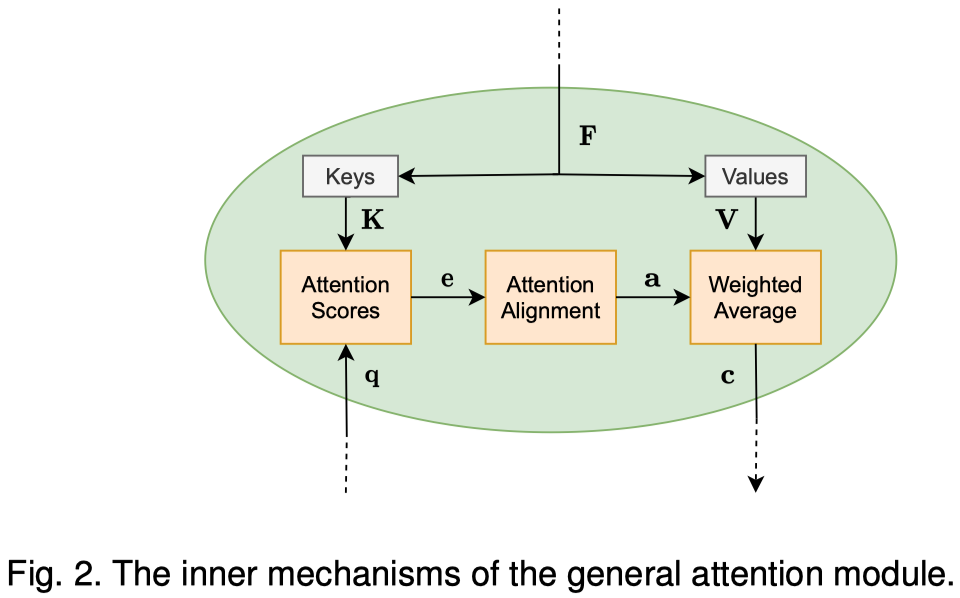
attention model接收到上面feature model和query model的输入后,根据特征向量会构建对应的value集合和key集合。这一步可能是类似于Transformer中的线性投影;也可能什么都不做,直接使用特征向量;可以是任意合理的映射函数。下面是采用Transformer中的线性投影:
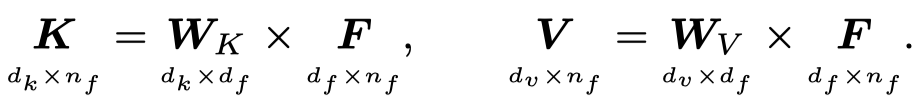
接下来经过三个步骤:
1. score function
利用query和key,计算attention value:
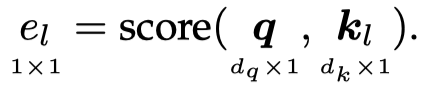
\(e_l\)表示第\(i\)个key vector对于query \(\mathbf{q}\)有多重要。最终对应每个value vector都有一个attention value:
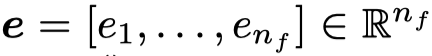
2. alignment function
在很多情况下,得到的attention value可能会超出\([0,1]\),并且我们期望的注意力最后得到的输出是平均加权和。所以attention value会经过一个alignment function进行重新分布(redistributed):
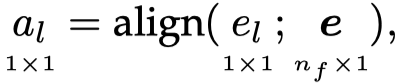
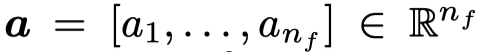
最常用的方法是softmax,当然还有其它的方法。
3. weight average
对value vector根据attention weight,加权求和:

output model是使用feature model提取出的特征向量经过attention之后得到的输出,表示后续的网络结构。