rethinking-role-of-demonstrations
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
华盛顿大学与Meta,EMNLP 2022,代码。
Large language models (LMs) are able to incontext learn—perform a new task via inference alone by conditioning on a few input-label pairs (demonstrations) and making predictions for new inputs. However, there has been little understanding of how the model learns and which aspects of the demonstrations contribute to end task performance. In this paper, we show that ground truth demonstrations are in fact not required—randomly replacing labels in the demonstrations barely hurts performance on a range of classification and multi-choice tasks, consistently over 12 different models including GPT-3. Instead, we find that other aspects of the demonstrations are the key drivers of end task performance, including the fact that they provide a few examples of (1) the label space, (2) the distribution of the input text, and (3) the overall format of the sequence. Together, our analysis provides a new way of understanding how and why in-context learning works, while opening up new questions about how much can be learned from large language models through inference alone.
作者对于上下文学习中,什么样的signal是对LLM进行task learning有帮助的进行了实验探究。
Experimental Setup
作者实验用model:
用的prompt实例:

作者主要针对4个ICL中的demonstrations可能提供的learning signal进行了实验:


Ground Truth Matters Little
作者的第一个重要发现是ICL中demonstrations的input-label是否正确匹配,对模型效果的影响不大。作者用随机的label来替换demonstrations的ground truth label,发现效果下降不是很多:
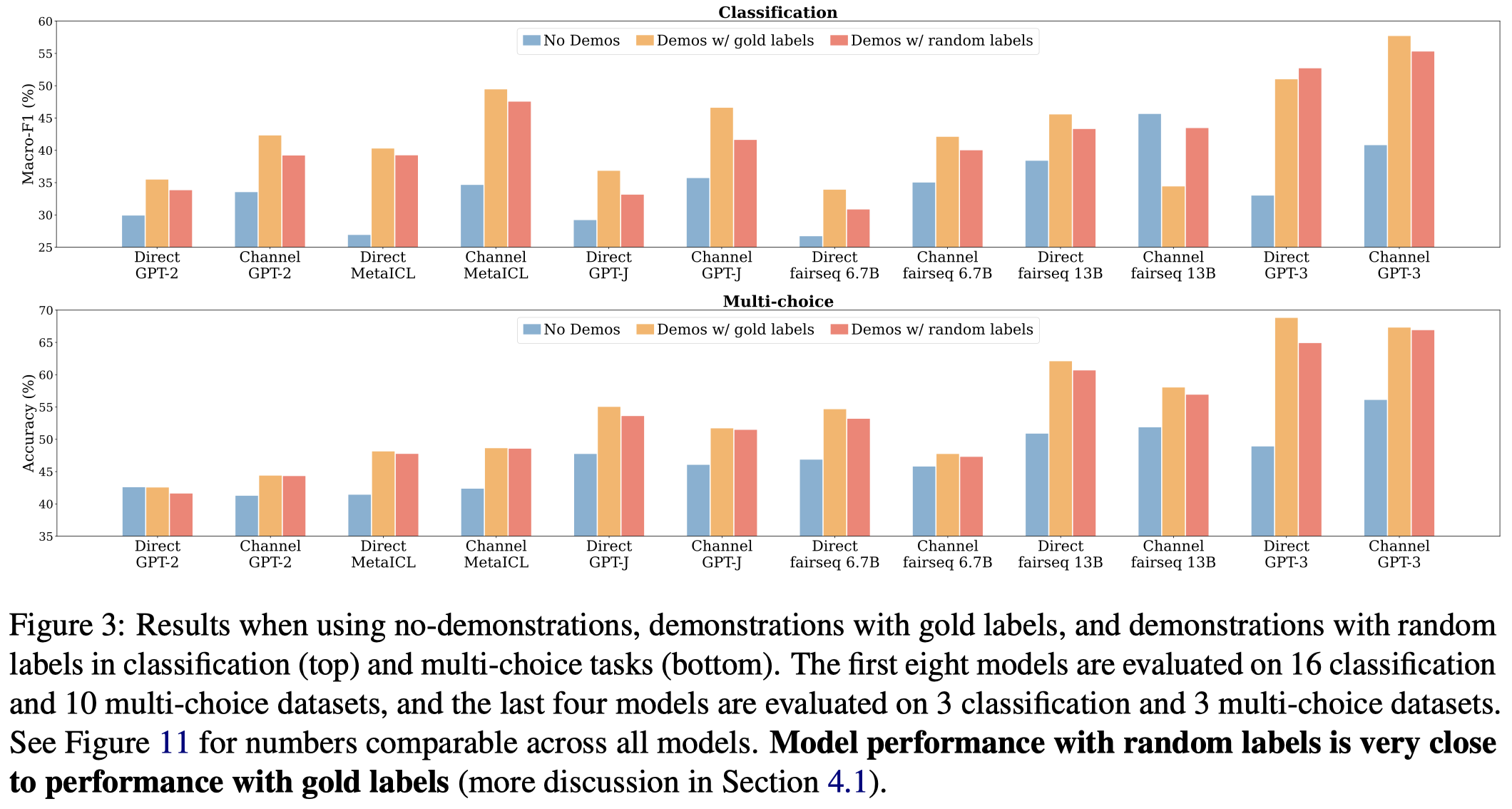
上面的结果说明给定demonstrations很重要;但是demonstrations中input-label的对应关系没有那么重要。似乎LLM能够自己根据demonstrations的input去恢复映射关系。
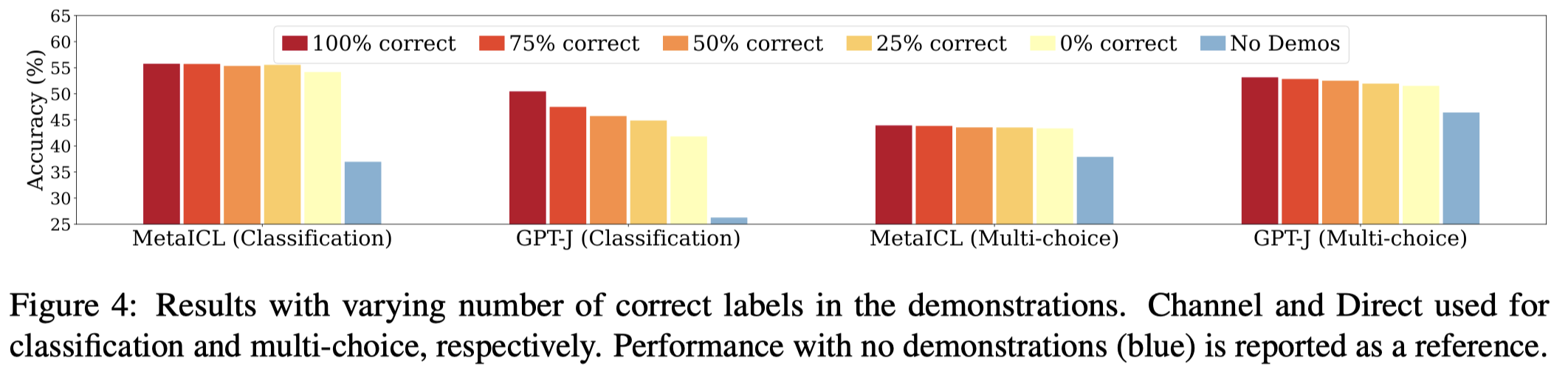
额外的实验同样证明了相同的变化趋势,作者随机替换一部分的ground truth label:
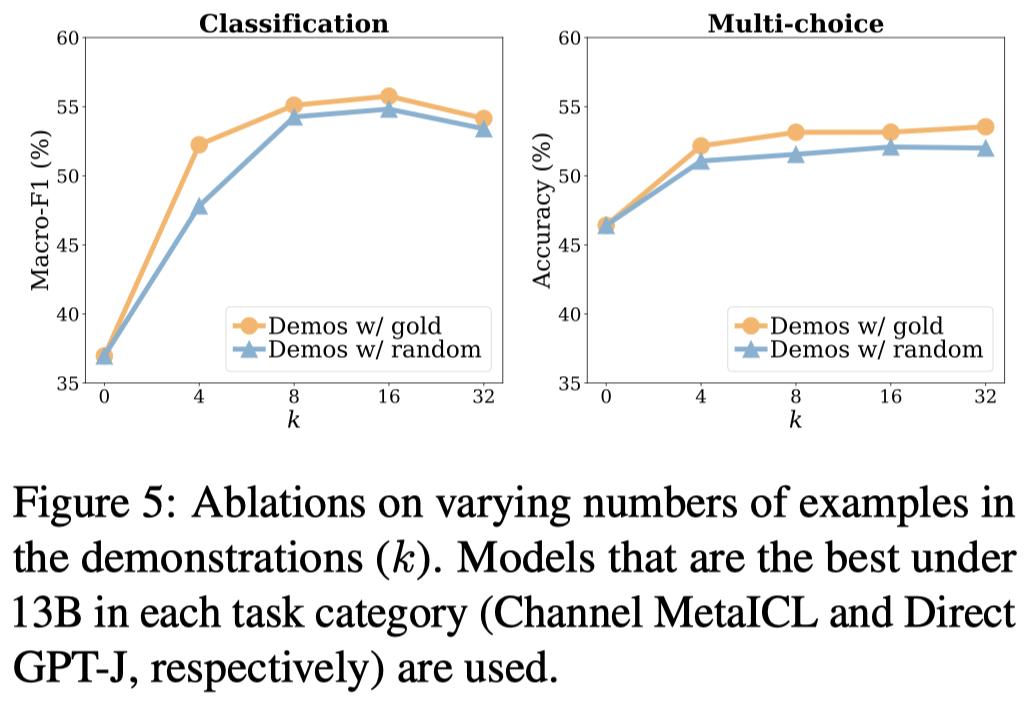
不同demonstrations数量:
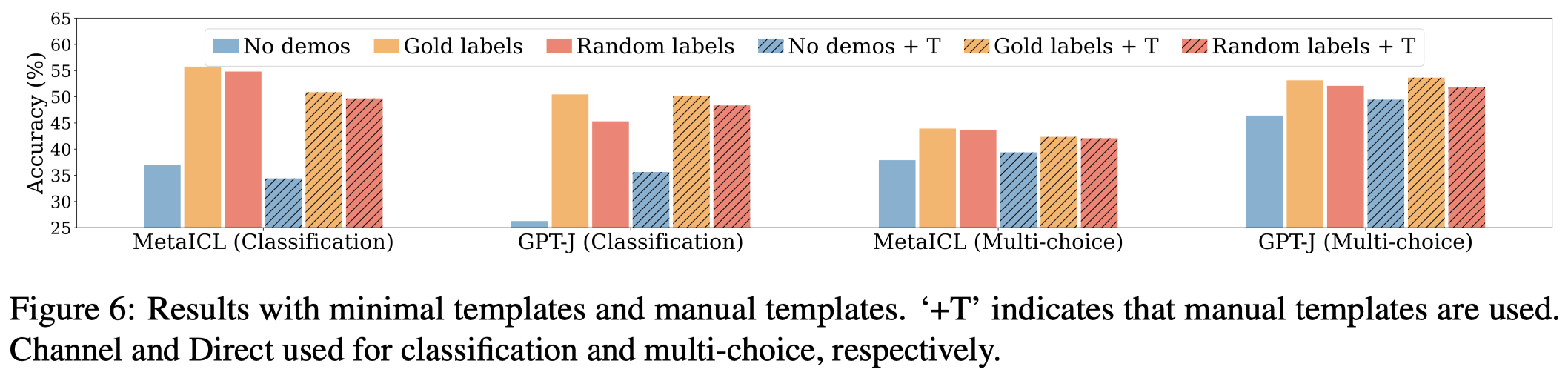
不同prompt template(换为人工设计的prompt):
Why does In-Context Learning work?
Impact of the distribution of the input text
然后,作者进一步探究了其它3个可能影响ICL效果的因素。对于input text的distributions,作者实验用外部语料库找到的句子,随机替换一些demonstrations的input,引入out-of-distribution text:

发现结果出了Direct MetaICL外,都出现了明显的效果下降。
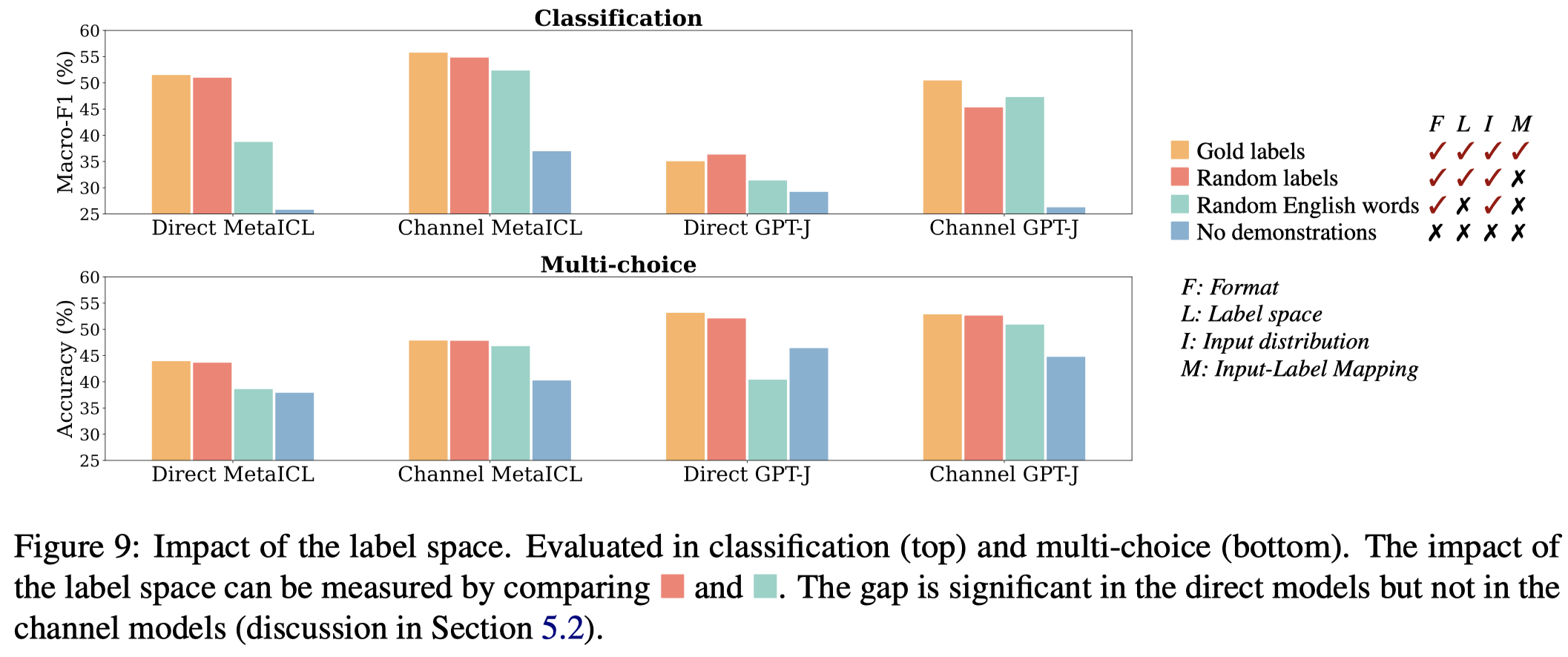
Impact of the label space
作者实验用随机英文单词,替换ground truth label,发现效果下降:
Impact of input-label pairing
作者实验了demonstrations的input-label这种format对效果的影响,包括No labels和labels only:

Discussion
Does the model learn at test time? 如何理解ICL是否进行了学习learning?要依据如何定义learning这个概念:
If we take a strict definition of learning: capturing the inputlabel correspondence given in the training data, then our findings suggest that LMs do not learn new tasks at test time. Our analysis shows that the model may ignore the task defined by the demonstrations and instead use prior from pretraining.
However, learning a new task can be interpreted more broadly: it may include adapting to specific input and label distributions and the format suggested by the demonstrations, and ultimately getting to make a prediction more accurately. With this definition of learning, the model does learn the task from the demonstrations.
如果认为learning是要利用demonstrations中input-label的mapping依赖来学会新task的映射关系,那么不能认为ICL进行了学习;如果认为learning是能够适应某种input和label的分布,并且按照一定的format进行输出,这种更加general的定义,那么可以认为ICL进行了学习。
Capacity of LMs. ICL的能力从哪里来?如果LLM不是主要根据样例中的input-label的mapping关系来学习的,那么它是从哪里学习映射关系的?作者认为可能是从language modeling的角度,判断input text和label text之间关联的。这种能力的获得可能是在预训练阶段。如之前有研究者认为,demonstrations的作用是task location,真正能力实在pre-training阶段获得的。
Reynolds and McDonell (2021) who claim that the demonstrations are for task location and the intrinsic ability to perform the task is obtained at pretraining time
Significantly improved zero-shot performance. 作者的工作启发了一种zero-shot模式,只需要提供给LLM无ground truth label的random label的样例,LLM或许就能够更好的执行zero-shot任务。