is-gpt3-good-data-annotator
Is GPT-3 a Good Data Annotator?
南洋理工与阿里达摩,ACL 2023,代码。
Data annotation is the process of labeling data that could be used to train machine learning models. Having high-quality annotation is crucial, as it allows the model to learn the relationship between the input data and the desired output. GPT-3, a large-scale language model developed by OpenAI, has demonstrated impressive zero- and few-shot performance on a wide range of NLP tasks. It is therefore natural to wonder whether it can be used to effectively annotate data for NLP tasks. In this paper, we evaluate the performance of GPT-3 as a data annotator by comparing it with traditional data annotation methods and analyzing its output on a range of tasks. Through this analysis, we aim to provide insight into the potential of GPT-3 as a general-purpose data annotator in NLP.
作者探讨了利用GPT-3生成sentiment analysis (SA),relation extraction (RE),named entity recognition (NER)和aspect sentiment triplet extraction (ASTE)等任务的数据方法。
1. Introduction
为什么要讨论数据标注问题?因为从大的方面讲,AI技术应该面向社会各界提供服务(论文中称为The democratization of artificial intelligence)。但是一个AI model往往需要大量的标注数据。
The democratization of artificial intelligence (AI) (Garvey, 2018; Rubeis et al., 2022) aims to provide access to AI technologies to all members of society, including individuals, small- and medium-sized enterprises (SMEs), academic research labs, and nonprofit organizations.
标注数据的获得需要很高成本:
- labor costs associated with the labeling process
- the time and resources required to hire, train and manage annotators.
- Additionally, there may be costs associated with the annotation tools and infrastructure needed to support the annotation process.
对于个人和小公司来说这种成本往往是不可接受的。
另一方面,GPT-3等大模型有很多knowledge,可以执行广泛的NLP任务;但是在production环境中,使用BERT-base等small的model可能是更加合理的(个人认为这种small model在极端情况下,需要高响应的场景中也不实用)。
所以,论文作者就关注利用GPT-3生成/标注训练数据,去更好的训练small model以降低标注数据获取成本。
用GPT生成训练数据/标注数据,然后训练small model,可以看做是一种蒸馏技术。(那么人类标注,然后训练model,是不是能够看做一种人类到model的蒸馏?)
2. Methodology
作者的标注数据获取方法有三种:
- prompt-guided unlabeled data annotation (PGDA):tagging-based approach,让LLM直接对in-domain unlabelled data进行标注
- prompt-guided training data generation (PGDG):generation-based approach,让LLM生成带有label的数据
- dictionary-assisted training data generation (DADG):generation-based approach,利用external knowledge source去辅助生成带有label的数据。先在Wikidata中查询相关的样例,然后让GPT模仿生成数据。这样做的好处是对于一些LLM的预训练数据没有包括/占比较少,学习效果不好的domain,更能够生成可信的结果。
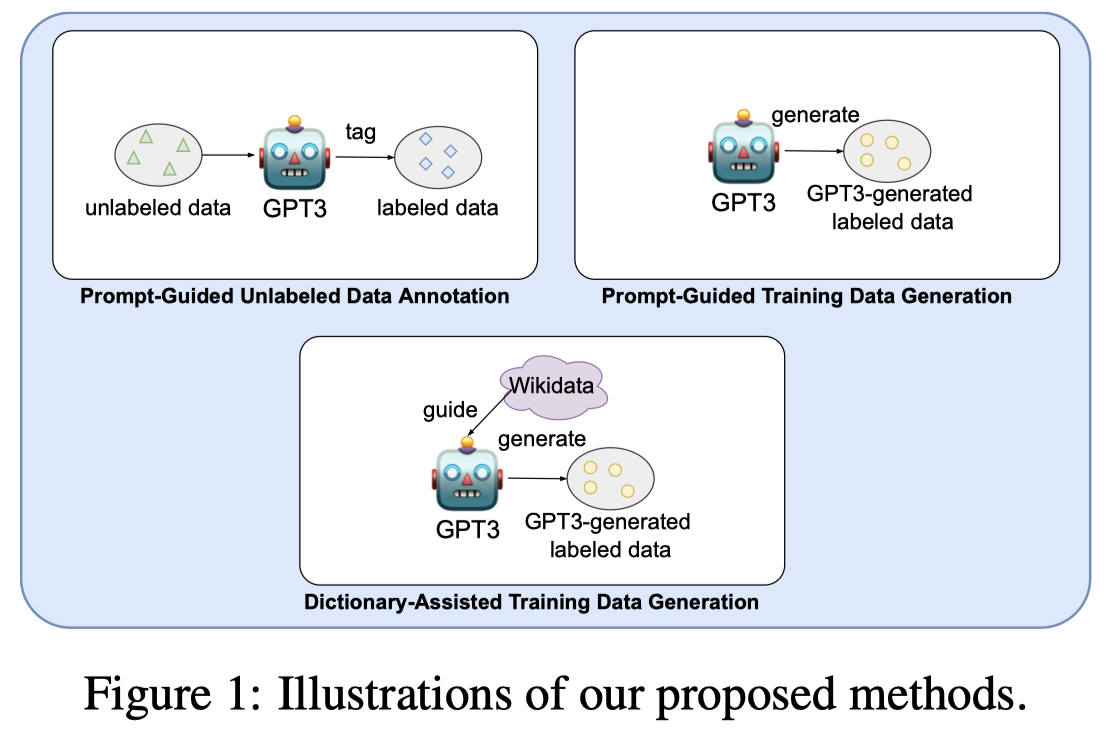
三种思路对于不同的任务有不同的prompt,但是都采用了in-context learning的形式。
3. Experiments
3.1 Experiment Settings
一些设置:
- GPT-3使用
text-davinci-003,使用其生成的data去训练small model - small model是
BERT-base - DADG利用到的外部知识源是Wikidata
下面主要记录了在RE和NER任务上的表现,其它任务请参见论文原文。
3.2 FewRel
FewRel数据集有64种relation。
下面是三种方法分别用到的prompt示例:
PGDA方法用到的unlabeled data是原始数据集中的样例移除人工标注之后的data。然后再使用GPT新标注的结果去训练BERT。
作者设计了5种PGDA方法用到的prompt,但由于这个数据集label space很大,这种标注方法效果并不好:

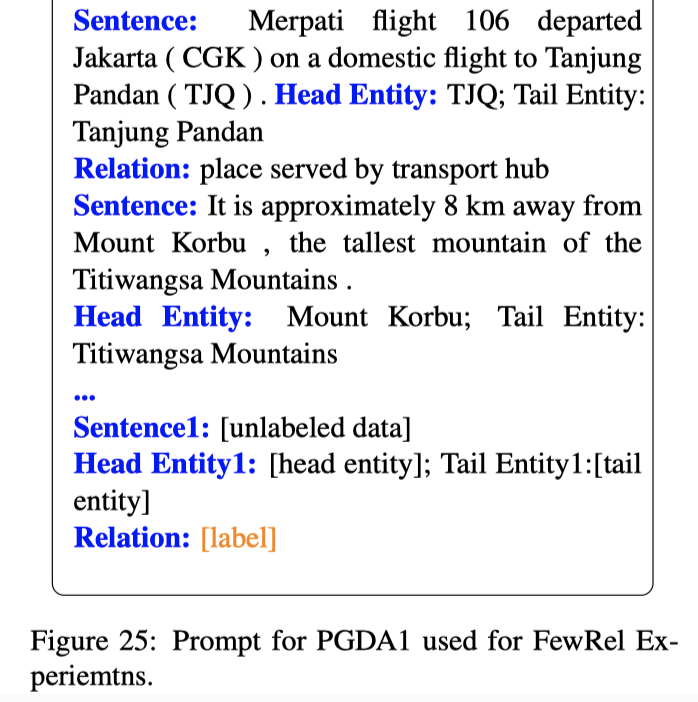
PGDG生成方法,第一步让GPT生成特定relation的head/tail entity;第二步让GPT根据head/tail entity去创造包含这两个实体的sentence;从论文描述中看,应该是随机找的demonstrations。


DADG方法第一步在Wikidata中查询对应relation的entity pairs;第二步用查询到的entity pairs作为上下文生成新的sentence。与上面的PGDG类似。
实验结果:
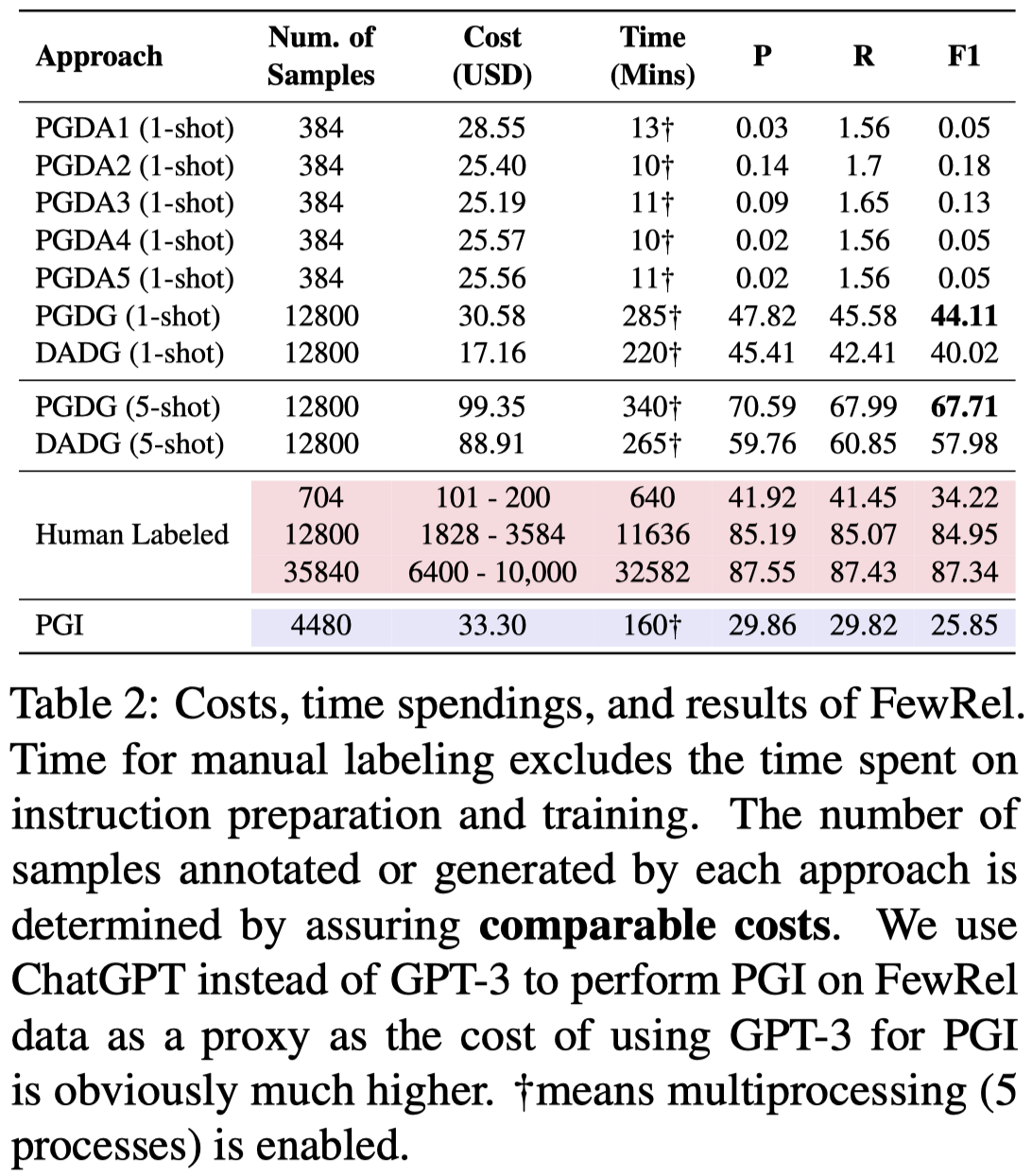
观察:
- 由于这个数据集有很多relation label,GPT不能够准确的标注label,因此PGDA方法效果最差
- 基于生成的方法PGDG和DADG效果比PGDA要好很多。最重要的是,标注代价要远远小于人工标注
3.3 CrossNER
作者使用CrossNER数据集中的AI数据集(14种entity label)。
PGDA方法,作者发现GPT标注entity的时候:
- it may also identify entities that are not of the specified entity type, resulting in incorrect labeling
- GPT-3 may not accurately identify the boundaries of the entities
因此,作者除了直接让GPT标注实体外,还让加了额外的一个确认entity type的步骤:


首先,让GPT标注对应entity type的entity;然后再次确认,让GPT对于识别出的entity重新决定属于哪一类entity。(尽管经过这么两步,PGDA方法效果仍然是最差的)
基于生成的PGDG是两步,第一步让GPT生成不同entity type下的可能entity;第二步让GPT利用生成的entity去生成对应的sentence:

基于生成的DADG第一步是从Wikidata中查询属于entity type的entities;第二步和PGDG第二步一致。
实验结果:
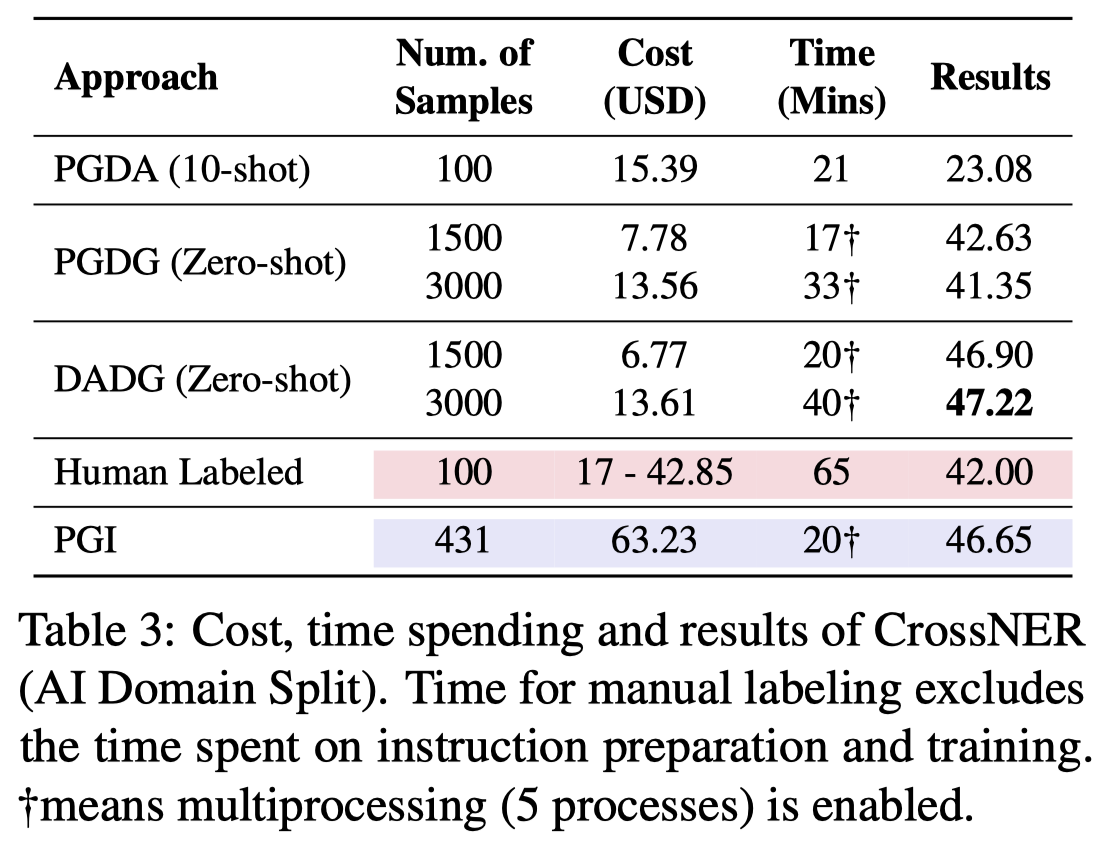
PGDG和DADG方法甚至超过了完全使用人类标注的效果,不过人类标注的实验只用了100个样例,这个比较结果不够公平。但还是非常promising的。
4. Further Analysis
4.1 Impact of Label Space
两种类型的生成训练数据的思路各有优缺点:
- The tagging-based approach (PGDA) is more appropriate for tasks with smaller label spaces and clearly defined labels,比如SE和ASTE方法中label只有2-3种,这种情况下PGDA方法效果更好。
- In contrast, the generation-based approaches (PGDG and DADG) are better suited for tasks with larger label spaces or labels that possess a certain degree of ambiguity,对于实验中的FewRel和CrossNER数据集,让GPT准确的理解label是很难的,因此直接标注的效果反而不好
- The tagging-based approach (PGDA) 能够直接利用in-domain unlabeled data;然而the generation-based approaches may generate data that contains information that was "learned" during pre-training and may not align with the distribution of in-domain data. 也就是说生成的数据特征分布不能够保证和真实世界的数据特征是一致的
4.2 Comparison with Human Annotators
与人类标注的比较:
- For human annotators, it usually takes longer time to train them for domain-specific data annotation, and their annotation speed is not comparable with machines in most cases
- Moreover, it is often more challenging for humans to construct training data without unlabeled data, or when the size of label space is very large.
- If we limit the number of data samples for model training, the per-instance quality of the data annotated by humans is still higher in most cases.
4.3 Impact of Number of Shots
不同任务中,增加上下文的样例数量来提升生成数据的效果,影响是不一样的,可能效果提升也可能效果下降:
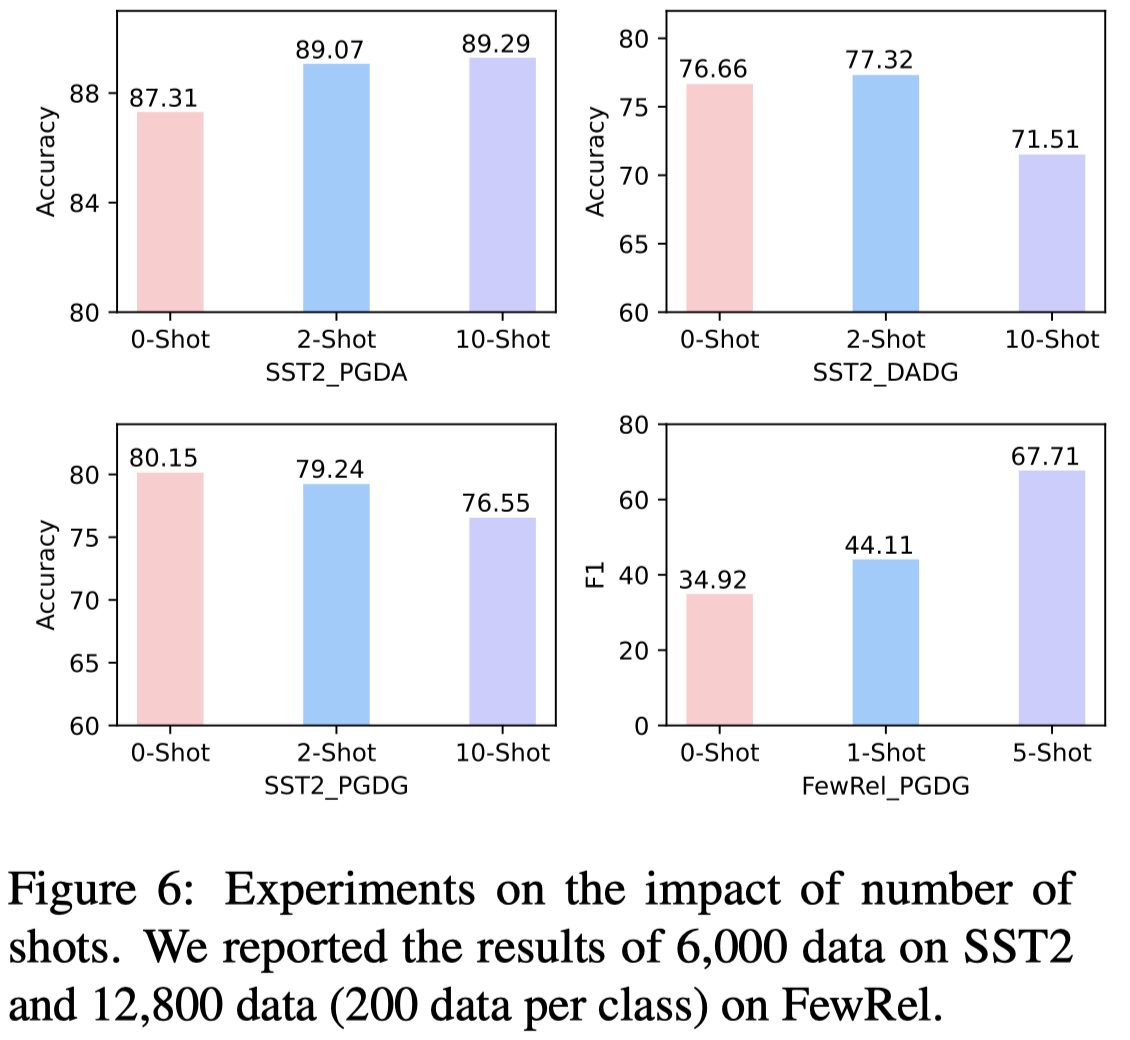
对于FewRel数据集,增加样例数量能够生成更加diverse的数据:

对于SST2数据集,增加样例数量,生成的数据越来越接近真实数据集中特点,反而会逐渐减少信息:
