When-not-to-trust-LLM-entity-knowledge
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
华盛顿大学,ACL 2023,代码。
Despite their impressive performance on diverse tasks, large language models (LMs) still struggle with tasks requiring rich world knowledge, implying the difficulty of encoding a wealth of world knowledge in their parameters. This paper aims to understand LMs’ strengths and limitations in memorizing factual knowledge, by conducting large-scale knowledge probing experiments on two open-domain entity-centric QA datasets: PopQA, our new dataset with 14k questions about long-tail entities, and EntityQuestions, a widely used open-domain QA dataset. We find that LMs struggle with less popular factual knowledge, and that retrieval augmentation helps significantly in these cases. Scaling, on the other hand, mainly improves memorization of popular knowledge, and fails to appreciably improve memorization of factual knowledge in the long tail. Based on those findings, we devise a new method for retrieval augmentation that improves performance and reduces inference costs by only retrieving non-parametric memories when necessary.
1. Introduction
之前已经有工作讨论过LM对于less frequent entities的记忆能力并不好[Large language models struggle to learn long-tail knowledge. 2022]。有后续的研究提出可以通过引入non-parametric knowledge来缓解这一问题[Few-shot learning with retrieval augmented language models]。但是Understanding when we should not trust LMs’ outputs is also crucial to safely deploying them in real-world applications。
这篇文章的目的就在于搞清楚什么时候应该trust LLM输出的factual knowledge,什么时候不应该trust LLM的输出factual knowledge。
为了探究这个问题,作者构造了一个新的知识探测数据集PopQA,主要是由各类less popular的实体相关知识构成。
主要发现如下:
- factual knowledge frequently discussed on the web is easily memorized by LMs, while the knowledge that is less discussed may not be well captured and thus they require retrieving external non-parametric memories.
- scaling up models does not significantly improve the performance for less popular questions.
- we found that retrieval-augmented LMs are particularly competitive when subject entities are not popular.
- we also find that retrieval augmentation can hurt the performance of large LMs on questions about popular entities as the retrieved context can be misleading.
2. Evaluation Setup
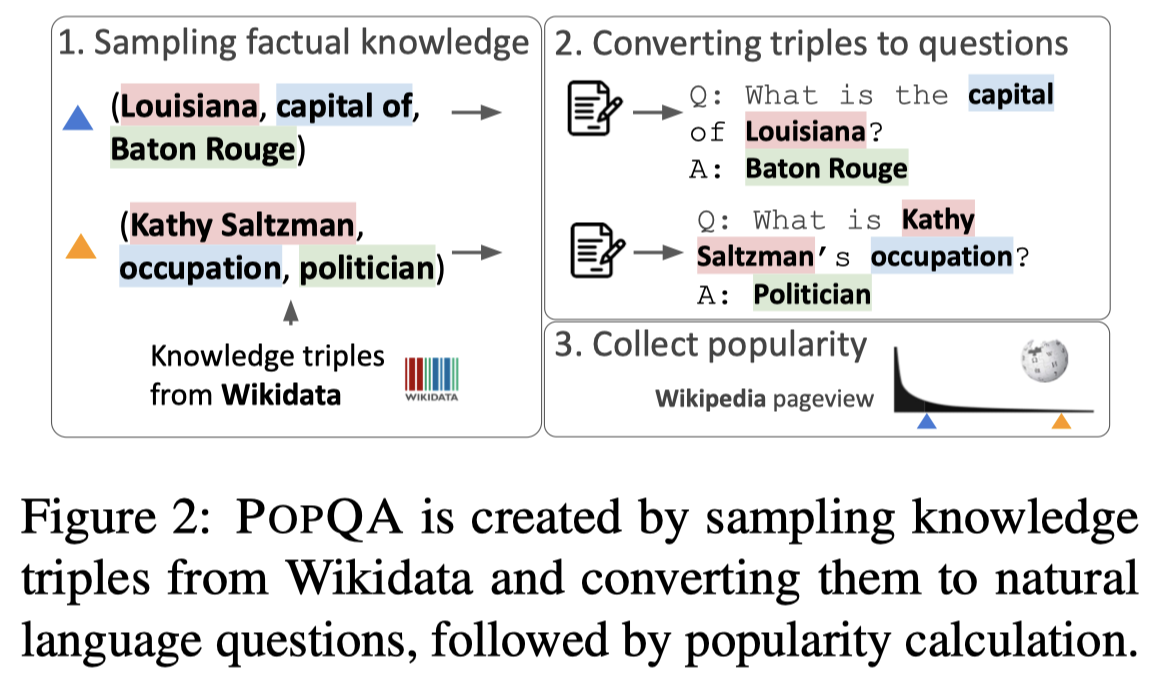
作者从Wikidata中构造了自己的数据集,entity的popularity用维基百科相关页面的点击次数Wikipedia monthly page views来评估,PopQA数据集构造流程如下:
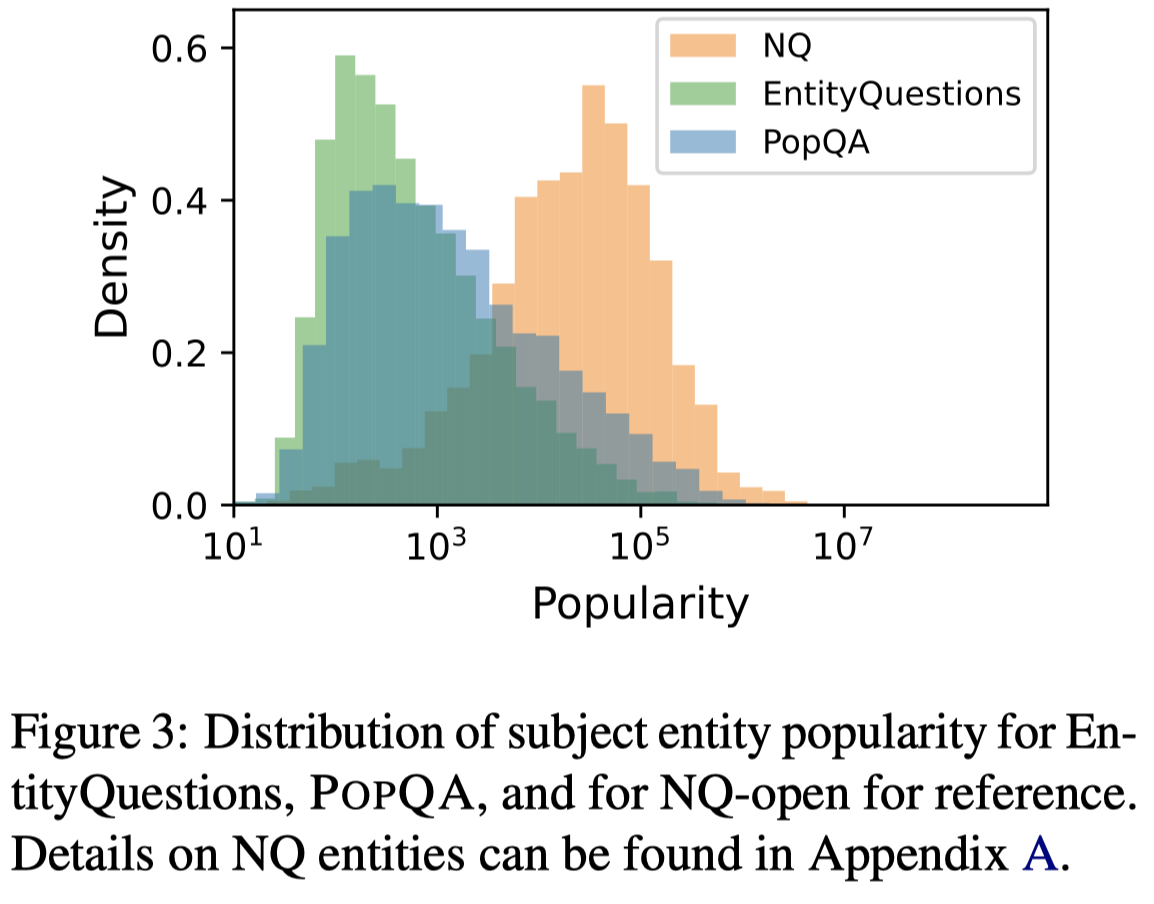
实体的popularity统计分布:
在询问LLM的时候,使用下面的句子模板:

已知头实体和关系,预测尾实体。除了自己构造的数据集外,还使用了EntityQuestions数据集[Simple entity-centric questions challenge dense retrievers. EMNLP 2021]。
具体在查询LLM是使用了few-shot的in-context learning方法。
3. Memorization Depends on Popularity and Relationship Type
先看总体上的实验结果:
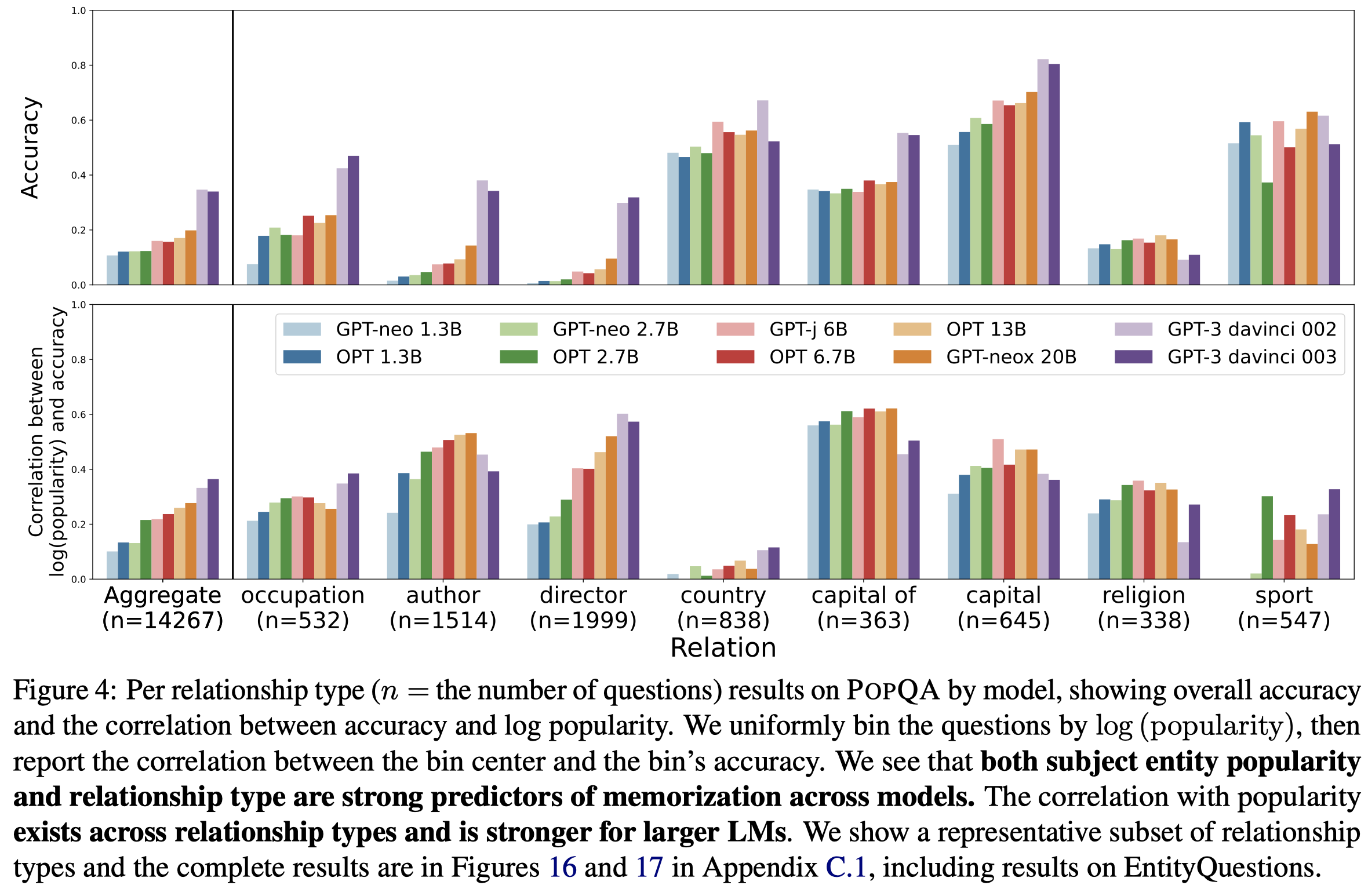
有以下的observation:
- 总体上,更大的LLM记忆的knowledge更多,表现效果更好
- 图4底部是entity popularity和回答的准确率accuracy之间的相关性correlation。可以看到这种相关性是正的,并且这种相关性随着LLM参数量的增加,总体上进一步增强
- 图4上半部分能看出来,不同relationship下的实体,LLM的回答准确率有很大差异。并且对于有些relation,popularity和准确性之间没有很强的相关性(如country、sport),但是准确性却很高。这可能是因为这些问题是LLM可以简单的通过一些特征surface-level artifacts就判断出来进行回答的。比如可以根据一个person entity的名字拼写,猜出他/她是来自那个国家
尽管上面的实验结果发现,更大的LLM似乎记忆效果更好,下面的实验进一步分析对不同popularity问题的回答准确度和LLM参数量大小之间的关系:
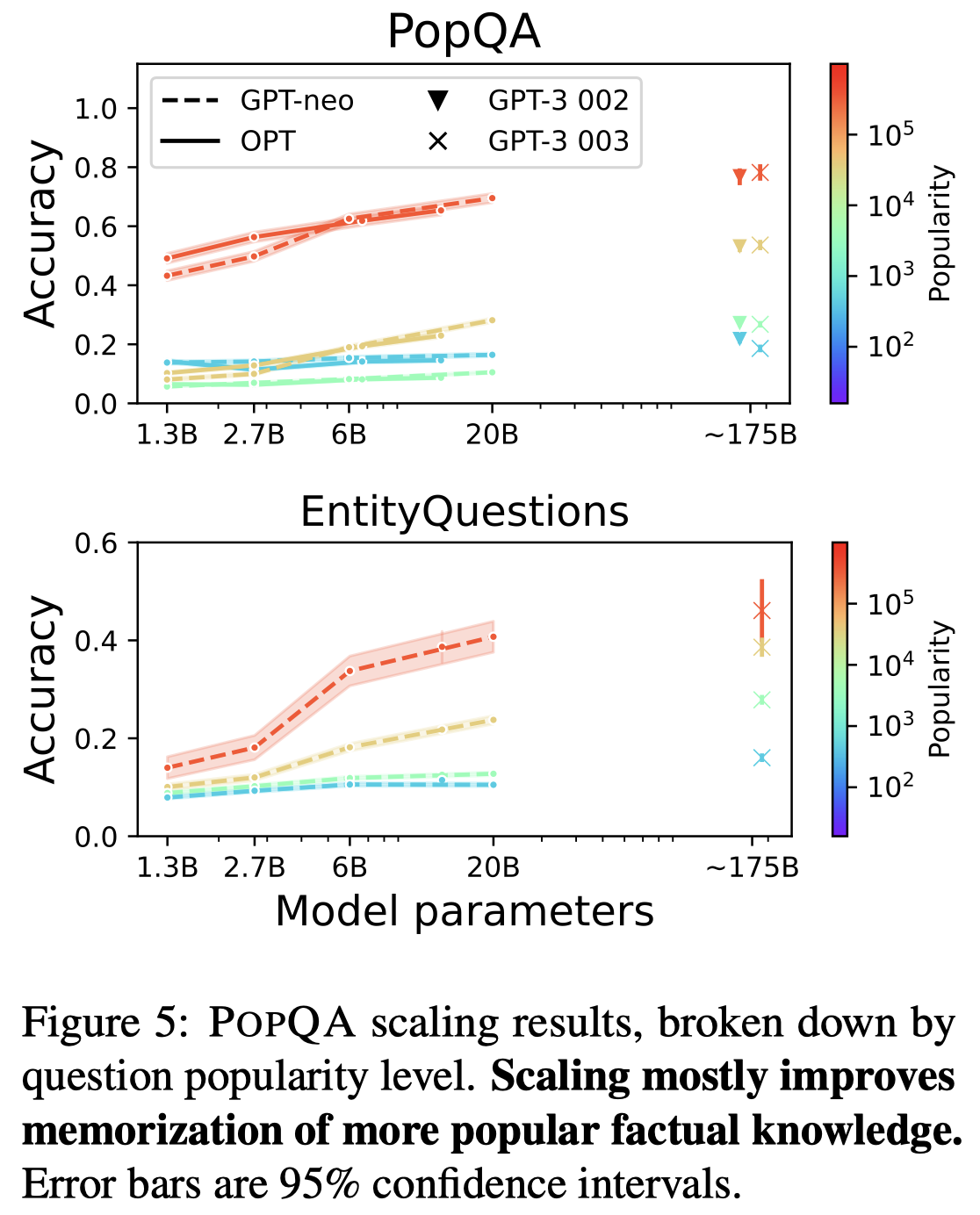
能够看出来,Figure 5 shows that on both P OP QA and EntityQuestions, most of scaling’s positive effect on parametric knowledge comes from questions with high popularity.
而less popular的问题,随着model参数量增加,增长很慢(尽管是有增长的)。因此作者推测,不断扩大LLM参数量,会进一步降低能够被可靠记忆的entity popularity的阈值。但是估计很难真正的抵达long tail entity的popularity范围。
4. Non-parametric Memory Complements Parametric Memory
作者对比了2个开箱即用的基于检索的方法:BM25和Contriever。同时还对比了一个GenRead的方法,该方法是直接让LM生成上下文,而不是通过检索。
利用现有的检索技术,从Wikipedia dump中直接检索到top-1相关的paragraph,然后与要探测的question拼接,作为输入到LLM的prompt。
下面的实验结果可以看出来,通过检索增强之后,几乎所有的LLM都能够获得总体效果的提升:
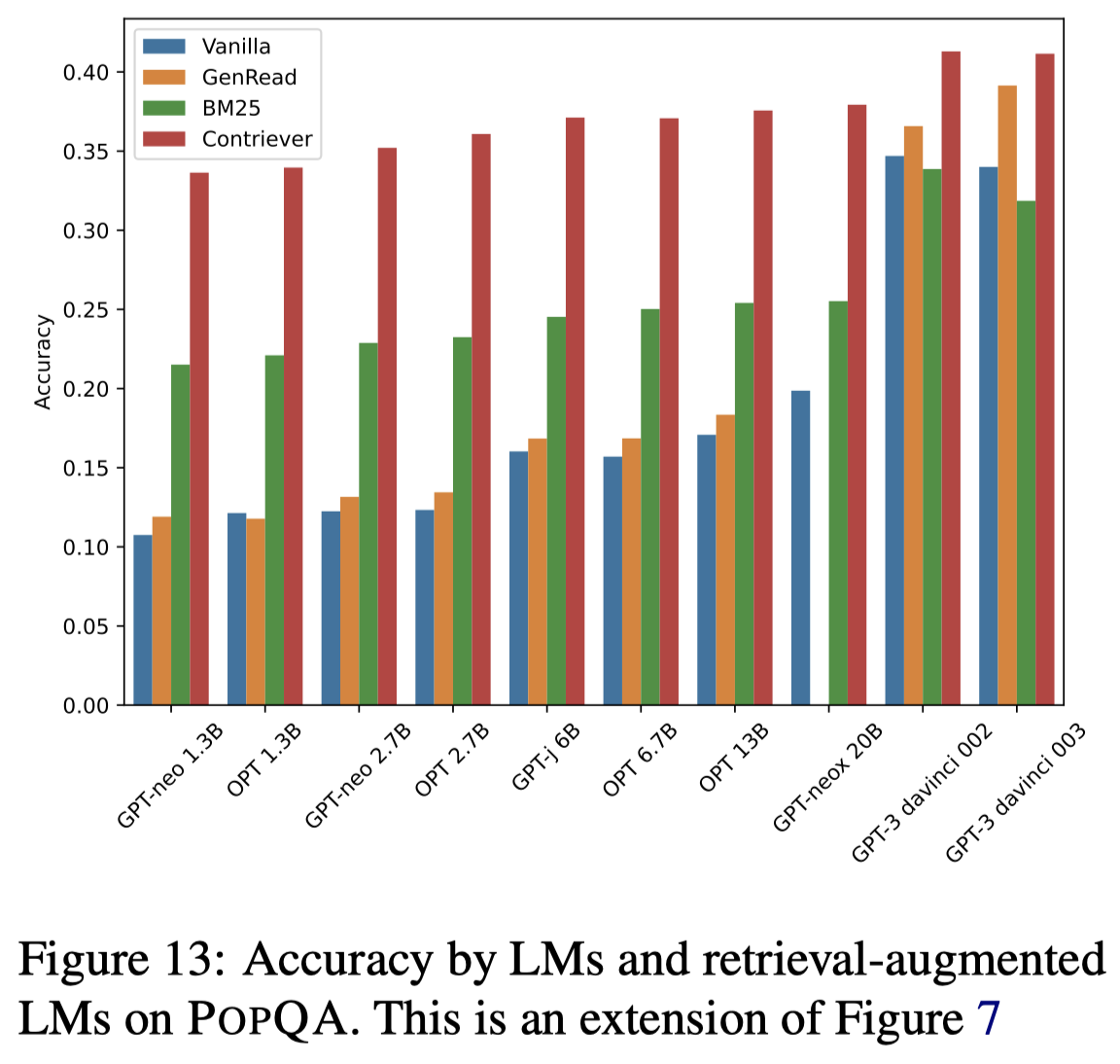
上图还有一个有意思的发现,直接让LLM生成额外的文本辅助增强prompt的GenRead方法,在更大的LLM中,效果是逐渐提升的。在GPT-3中已经靠近了纯检索的Contriever方法。
进一步实验发现,这种增强的效果提升主要是由于对less popular问题效果的提高:
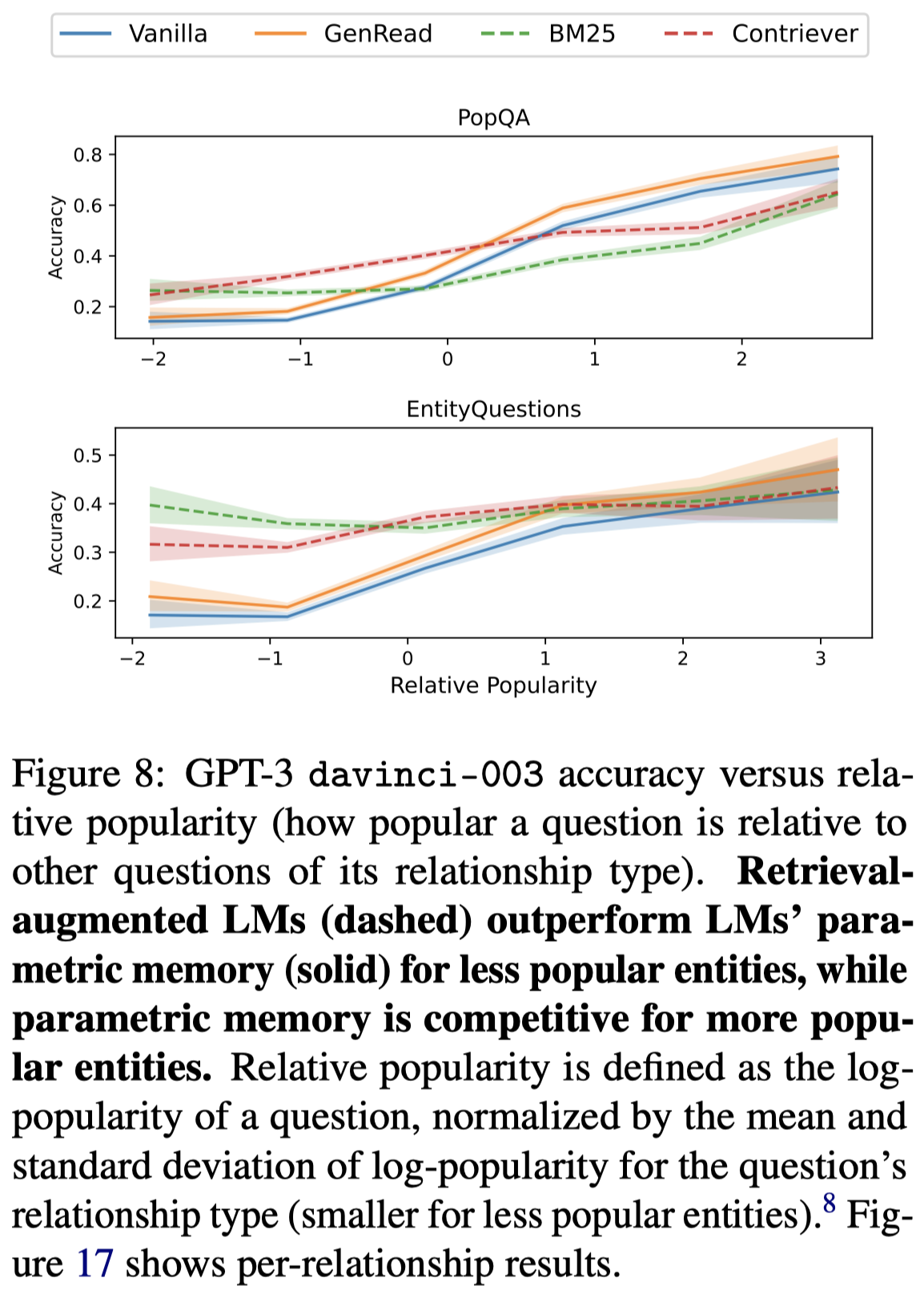
而在比较popular的问题上,检索增强甚至会降低效果。检索到的额外文本也不能够保证一定是有意义的,可能会误导LLM的输出。下图也佐证了这一点:
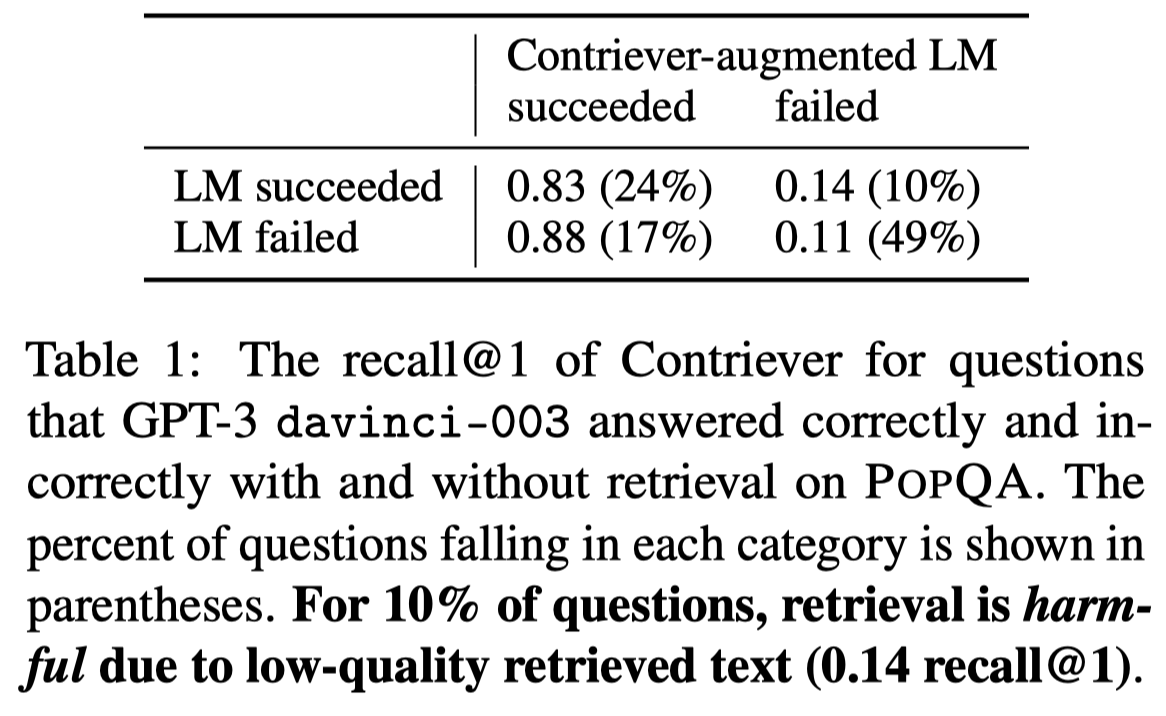
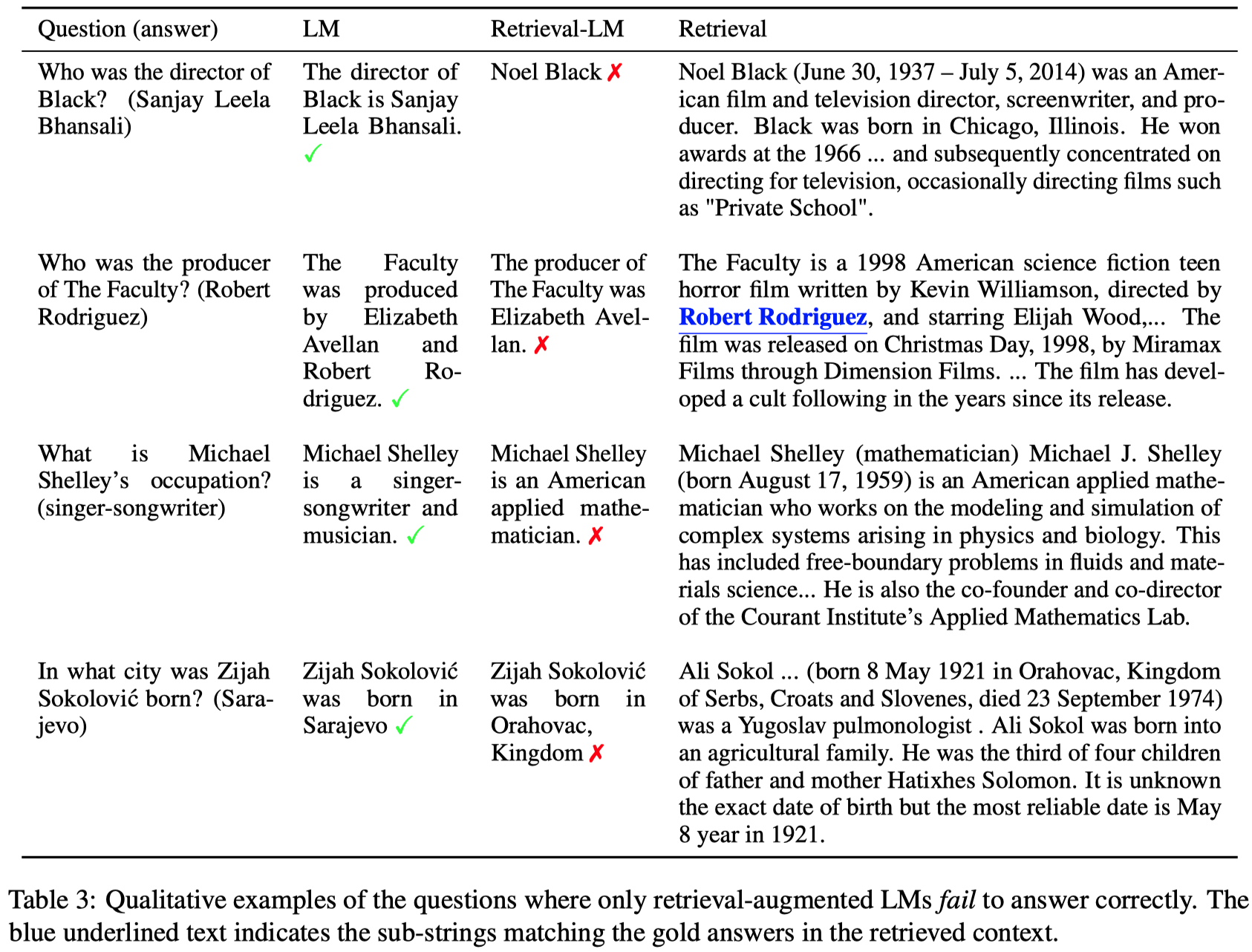
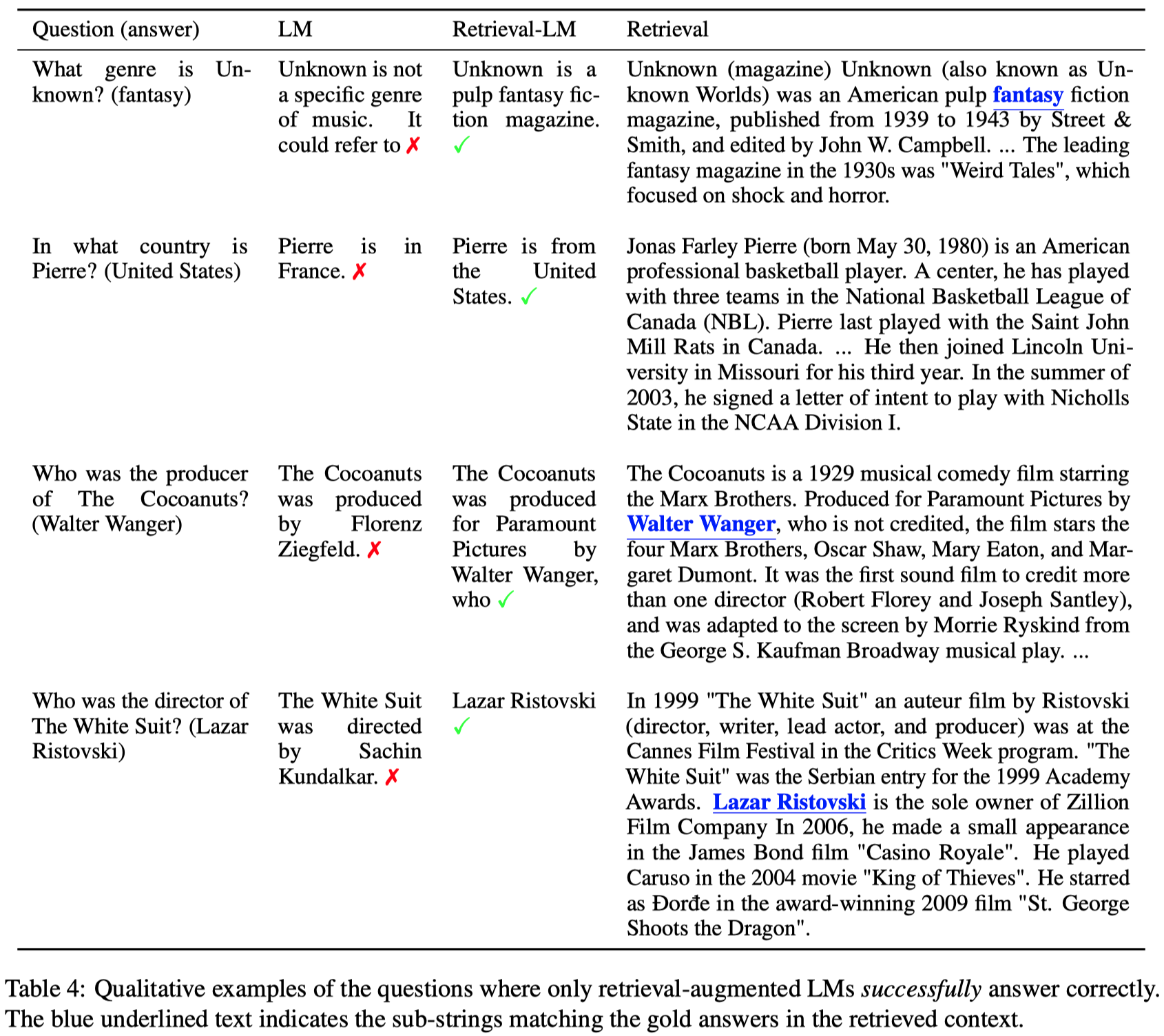
table 1中,本来LLM回答正确的问题,在检索增强后,可能会被误导(表格中10%的问题占比)。
下面是几个检索结果对原始LLM生成结果的影响实例:
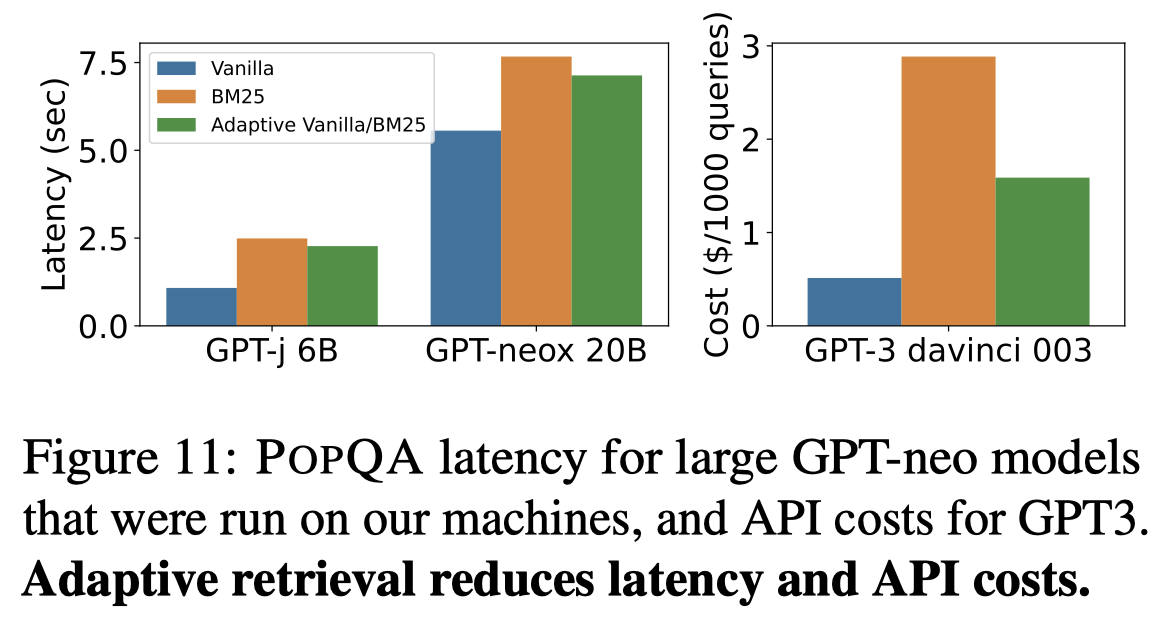
5. Adaptive Retrieval: Using Retrieval Only Where It Helps
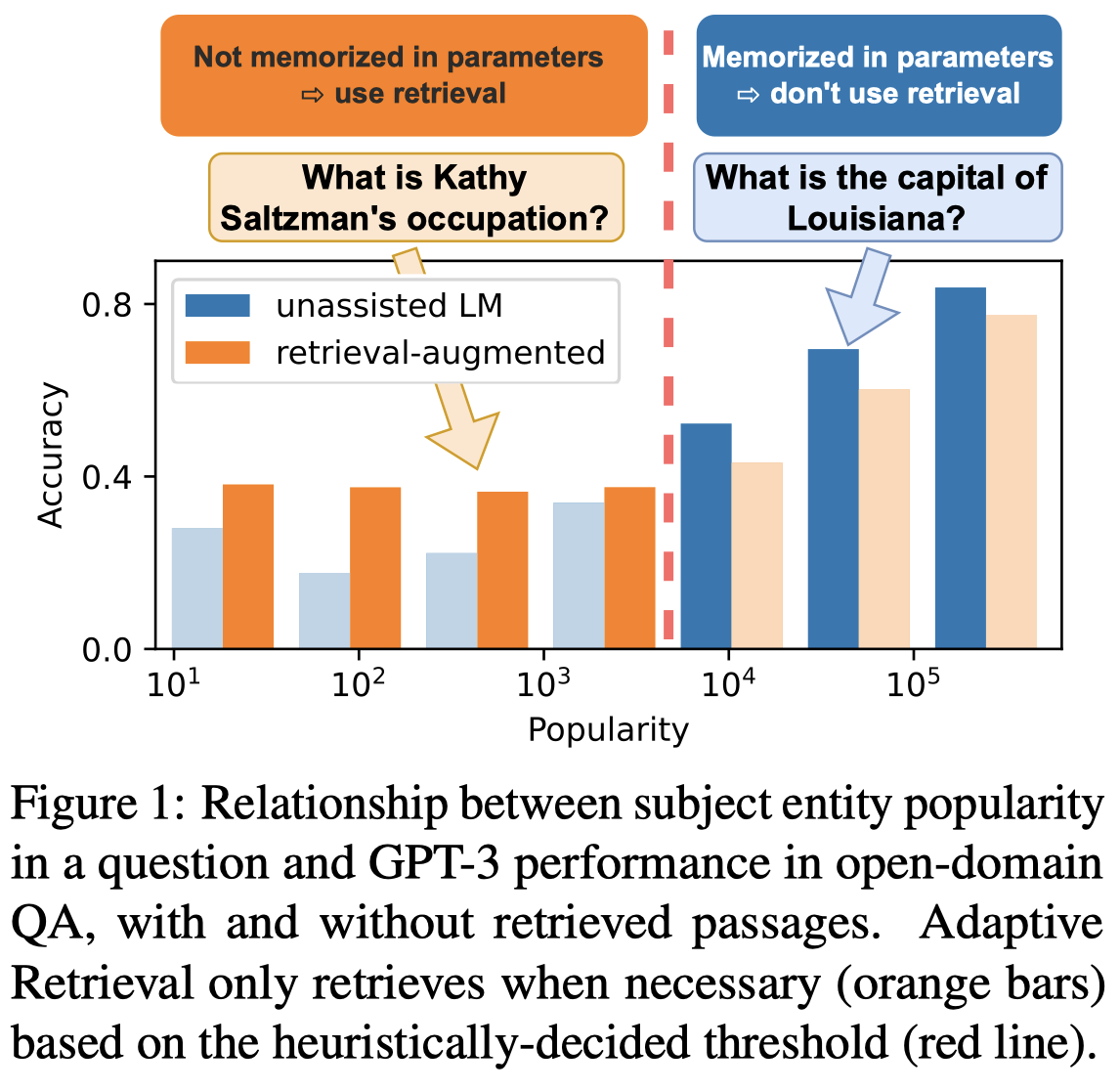
基于以上的实验观察,作者提出了一种Adaptive Retrieval的简单方法,就是给不同relationship设定不同的popularity阈值,只有小于阈值的问题才会进行检索增强,而大于阈值的问题就认为是比较popular的问题,只需要让LLM自己回答即可。
阈值的选择是通过在development set上,选择能够让不同relationship回答准确率最高的threshold。下面是作者的示意图:
在应用了作者的adaptive检索方法之后,效果都是有提升的,并且是越大的LLM提升越明显:
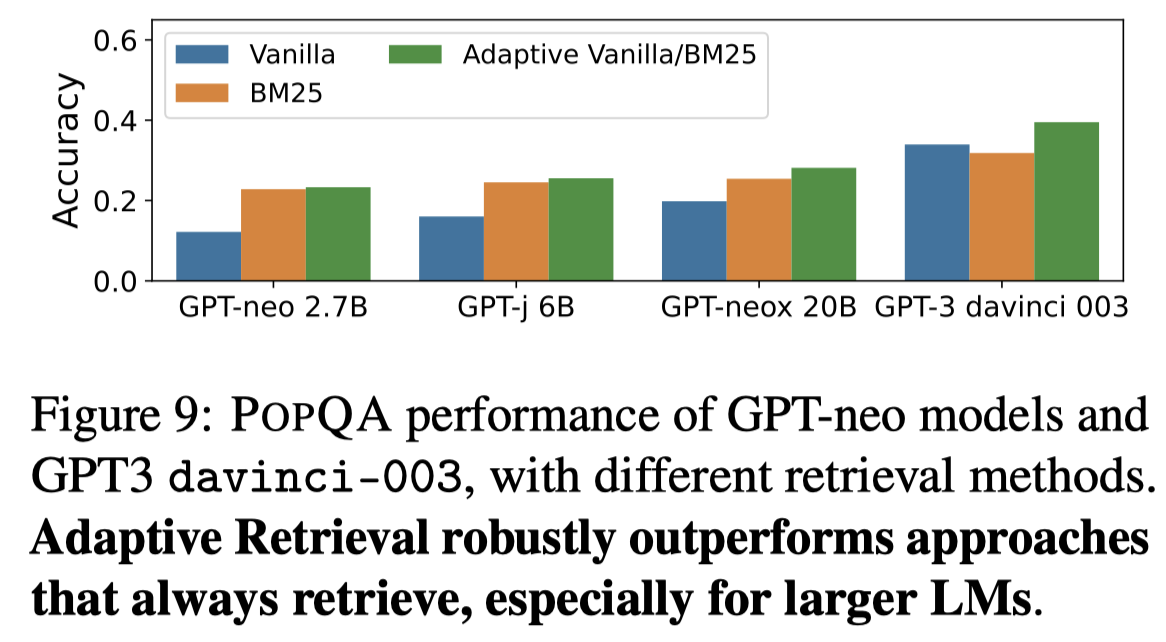
具体原因是因为,对于小LLM来说,几乎总是需要检索,而越大的LLM,越不太依赖检索:
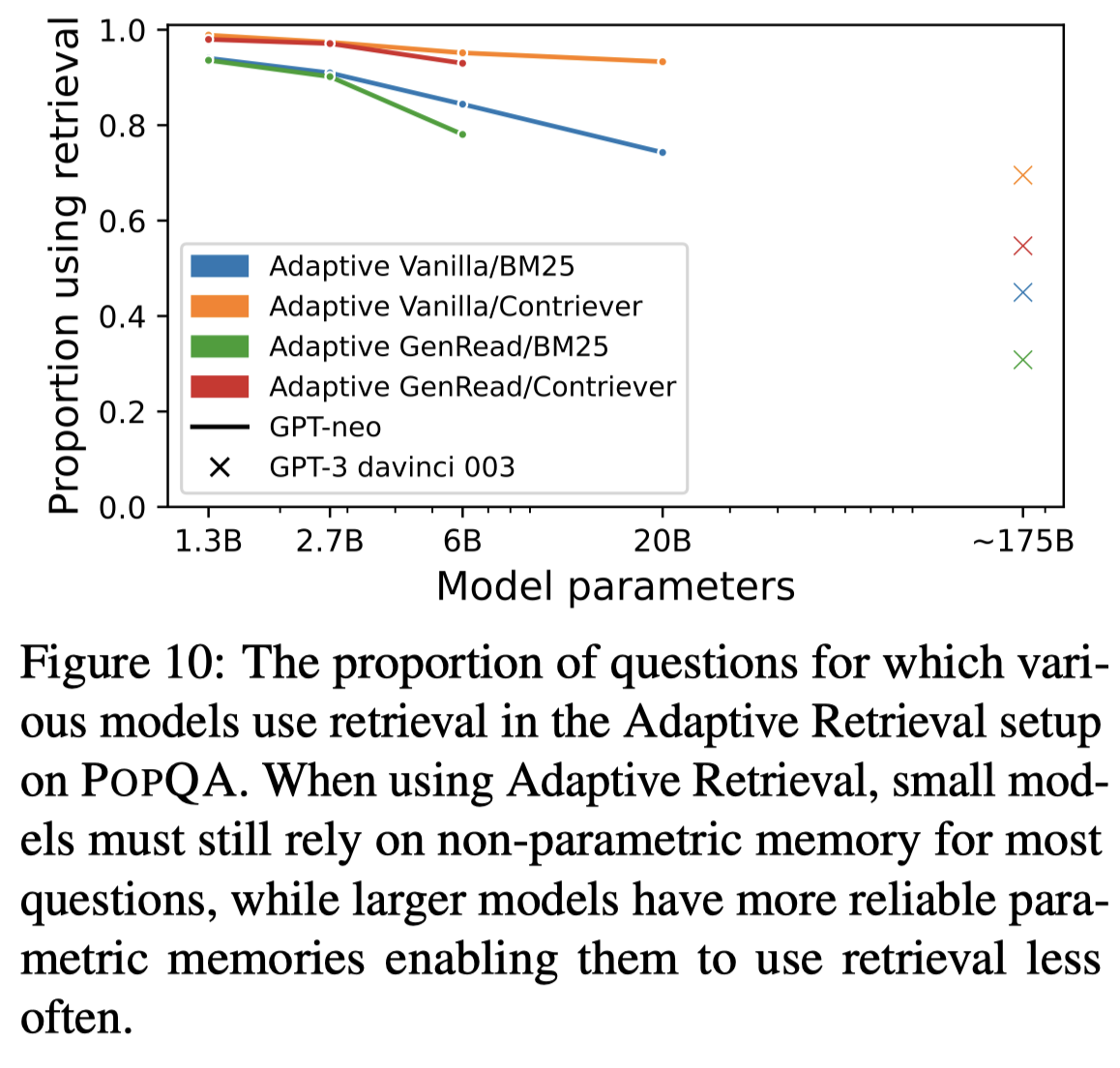
上面图10的实验结果表明,小LLM的检索阈值几乎是1,而越大的LLM,检索阈值越小。
这种自适应的检索增强方法另一个好处是,减小了时延(不需要检索以及更短的input length)和调用GPT的花费(更少的处理token,所需要的money更少),实验结果: