Trustworthy-LLM-survey-bytedance
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
2023-08 字节的关于可信LLM的survey。
Ensuring alignment, which refers to making models behave in accordance with human intentions [1, 2], has become a critical task before deploying large language models (LLMs) in real-world applications. For instance, OpenAI devoted six months to iteratively aligning GPT-4 before its release [3]. However, a major challenge faced by practitioners is the lack of clear guidance on evaluating whether LLM outputs align with social norms, values, and regulations. This obstacle hinders systematic iteration and deployment of LLMs. To address this issue, this paper presents a comprehensive survey of key dimensions that are crucial to consider when assessing LLM trustworthiness. The survey covers seven major categories of LLM trustworthiness: reliability, safety, fairness, resistance to misuse, explainability and reasoning, adherence to social norms, and robustness. Each major category is further divided into several sub-categories, resulting in a total of 29 sub-categories. Additionally, a subset of 8 sub-categories is selected for further investigation, where corresponding measurement studies are designed and conducted on several widely-used LLMs. The measurement results indicate that, in general, more aligned models tend to perform better in terms of overall trustworthiness. However, the effectiveness of alignment varies across the different trustworthiness categories considered. This highlights the importance of conducting more fine-grained analyses, testing, and making continuous improvements on LLM alignment. By shedding light on these key dimensions of LLM trustworthiness, this paper aims to provide valuable insights and guidance to practitioners in the field. Understanding and addressing these concerns will be crucial in achieving reliable and ethically sound deployment of LLMs in various applications.
1. Introduction
LLM已经引起了学界和企业界的深刻变革。ChatGPT是目前历史上用户数量增长速度最快的应用,超过了TikTok和instagram。
妨碍LLM进一步得到应用的关键是LLM可能产生不可信的输出,比如有毒的、歧视性的、虚假的、不符合人类道德观的输出。
LLM无法保证生成可信的结果的最重要的原因可能是预训练数据本身就包含了大量的噪音。大多数LLM的数据都要依赖从Internet上爬取,无论如何这些大规模的数据中会包含各种和人类主流价值观不符的数据。同时,在预训练过程中,并没有针对这些有害数据进行额外的设计。
通过想办法让LLM和人类价值对齐,可以促使LLM的输出更加reliable, safe, and attuned to human values:

之前的研究工作提出了一个针对LLM对齐任务的3H原则:Helpful, Honest, and Harmless [A general language assistant as a laboratory for alignment.]。
目前主流的将LLM对齐的技术:
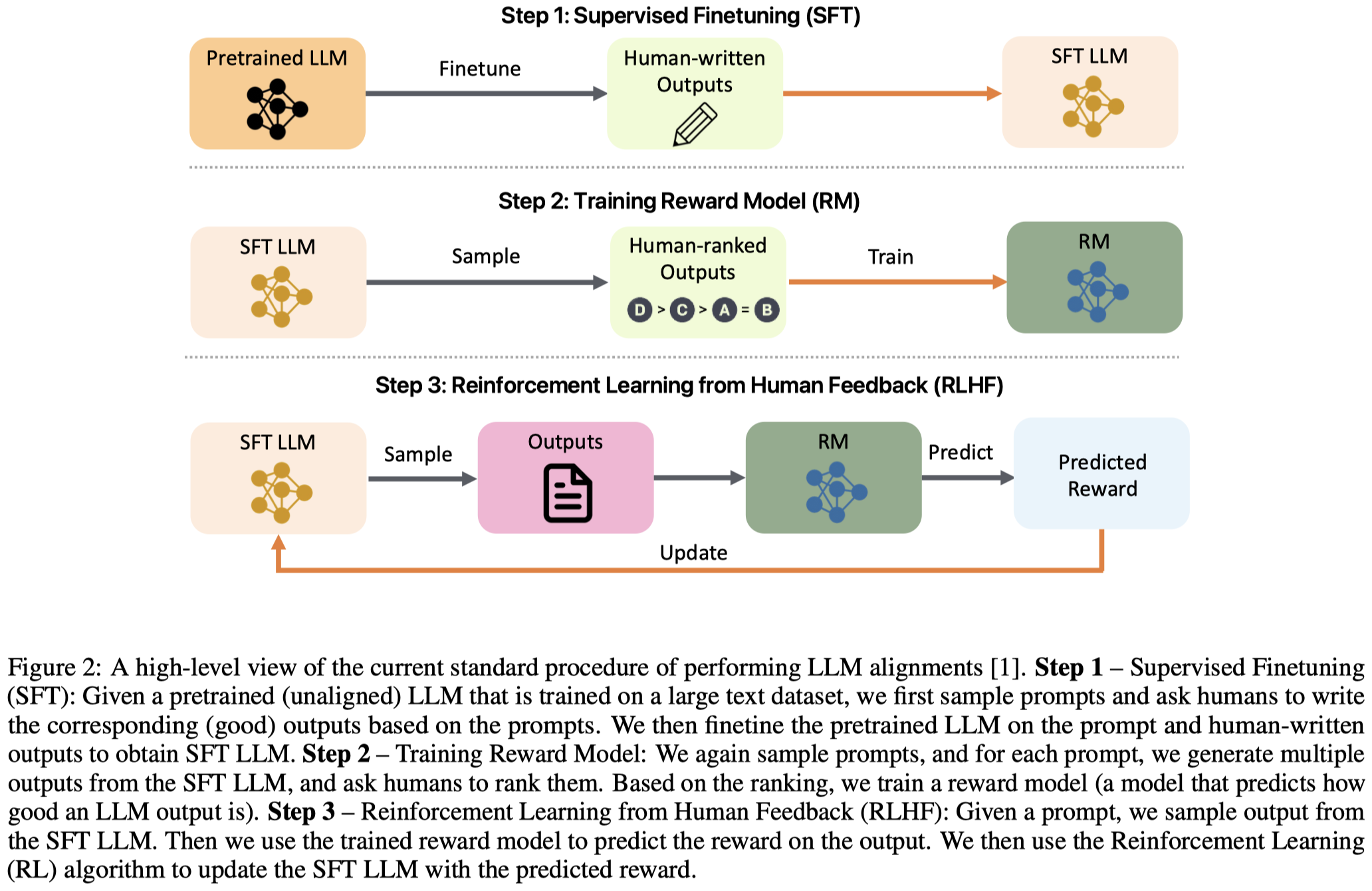
两个关键方法是SFT (supervised fine-tune)和RLHF (reinforcement learning from human feedback)。SFT首先用来训练经过预训练的原始LLM,让其在一定程度上能够和人类价值观对齐。之后训练过的LLM对于同一问题产生不同的输出,让人类去排序,训练一个reward model。最后就是利用RLHF结合LLM和reward model进行迭代的更新。
当然,目前也有很多研究讨论RLHF算法是否合适。
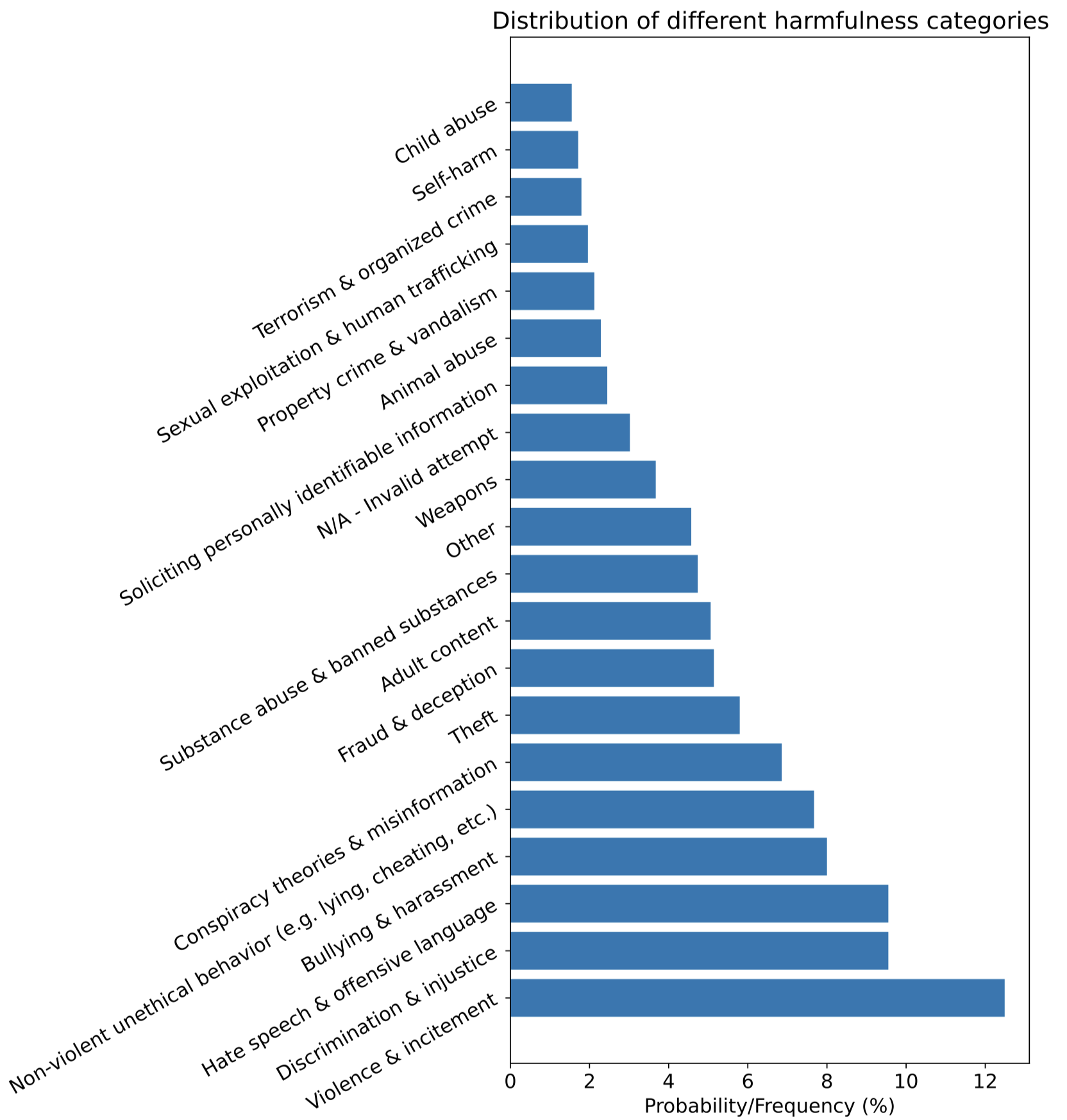
除去LLM对齐技术本身外,用来对齐的数据可能需要重点关注。比如在Anthropic发布的对齐数据中,各种有害情况的分布是不平衡的:
作者在这篇论文了提出了关于可信LLM的7个方面,包括29个小方面:
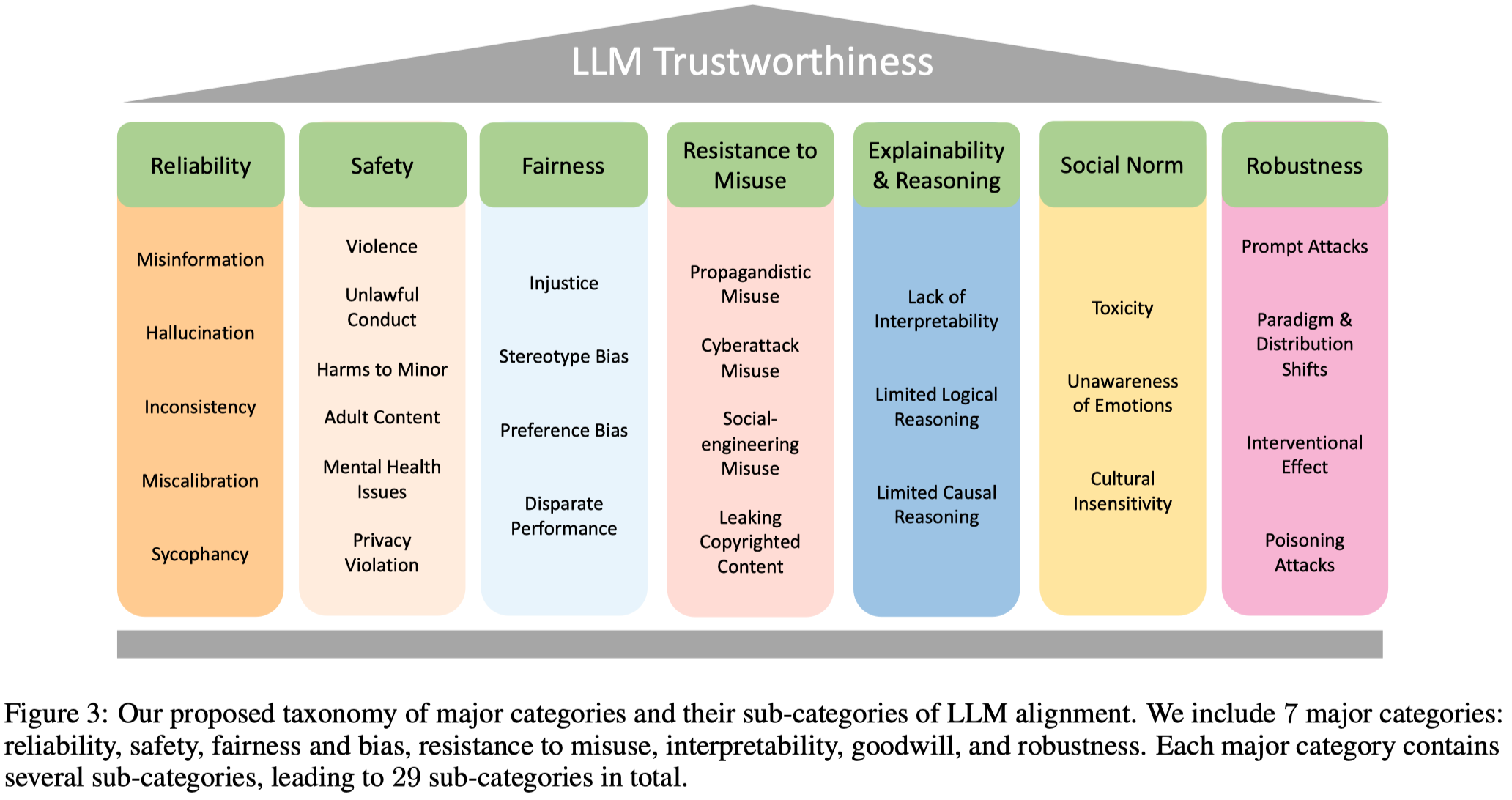
划分的依据主要是根据不同方面所关系的问题和目标:

2. Reliability
可靠性作者进一步细分了5个方面,misinformation、hallucination、inconsistency、miscalibration、sycophancy。
2.1 Misinformation
作者认为的misinformation是非用户本意的,由LLM生成的错误信息。
We define misinformation here as wrong information not intentionally generated by malicious users to cause harm, but unintentionally generated by LLMs because they lack the ability to provide factually correct information.
下图是ChatGPT生成错误事实的例子:

错误信息产生的几个可能原因:
训练数据(特别是从网络上爬取的数据)就存在错误事实。这些错误事实被LLM记录。
Elazar et al. 发现常常共同出现的实体对,可能会导致LLM产生错误的输出。[Measuring causal effects of data statistics on language model’sfactual’predictions.]
Elazar et al. [55] find that a large number of co-occurrences of entities (e.g. , Obama and Chicago) is one reason for incorrect knowledge (e.g. Obama was born in Chicago) extracted from LLMs
LLM对于不常见的知识可能更会生成错误信息,有研究人员认为不对不常见的事实应该从其它类型的非参数化外部知识库中获取。[When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories.]
Mallen et al. [56] discover that LLMs are less precise in memorizing the facts that include unpopular entities and relations. They propose to leverage retrieved external non-parametric knowledge for predictions regarding unpopular facts as retrieval models.
有研究人员发现,当在prompt中提供了新的信息时,不是所有的LLM都能够利用prompt中的新信息更新自己的答案。[Prompting gpt-3 to be reliable]
Si et al. [58] evaluate whether LLMs can update their memorized facts by information provided in prompts. They find that, while code-davinci-002 can update its knowledge around 85% of the time for two knowledge-intensive QA datasets, other models including T5 [59] and text-davinci-001 have much lower capability to update their knowledge to ensure factualness.
2.2 Hallucination
幻觉(Hallucination)属于misinformation的一种,但是有自己独特的特点。misinformation可能是由于输入的信息错误引起的。而hallucination是指生成完全虚构的答案,并且通常还非常自信。
LLMs can generate content that is nonsensical or unfaithful to the provided source content with appeared great confidence, known as hallucinations in LLMs.
Hallucination对应在心理学上的概念叫做虚构(confabulation),是指非故意的虚假记忆。
作者提出有两类的幻觉:
intrinsic hallucination: hallucination may consist of fabricated contents that conflict with the source content. 和用户输入的信息矛盾,LLM内部就存在的虚构事实。

extrinsic hallucination: hallucination may consist of fabricated contents cannot be verified from the existing sources. 对于用户输入的虚构事实,进一步进行虚构。

产生幻觉的可能原因:
- 训练数据和测试数据之间的偏移
- LLM相关技术,比如生成next token的随机性、在编码和解码阶段的错误、不平衡分布的training bias
探测幻觉的几种手段:
- 常用的评测任务是text summarization,比较LLM输出和reference text之间的差异
- QA任务,比如TruthfulQA数据
- 训练能够评估truthfulness的分类器来评估LLM的输出
- 人工
目前消除幻觉的方法还比较少:
- 数据清洗,提高训练数据质量
- The other aspect is using different rewards in RLHF. 通过改进RLHF的奖励过程,让LLM的输出更加和输入相符,而不是自己虚构事实。
2.3 Inconsistency
对于相同的/实质上一样的问题,有不同的回答,特别是考虑到对于本质上没有区别的提问方式,仅仅是简单的改变提问格式,就会输出正确/错误的回答。
It is shown that the models could fail to provide the same and consistent answers to different users, to the same user but in different sessions, and even in chats within the sessions of the same conversation.
示例:

不一致性的原因还不清楚:
- 和LLM本身的随机性有关(randomness in sampling tokens, model updates, hidden operations within the platform, or hardware specs)
- 预训练数据中存在的令人疑惑的和互相矛盾的事实可能是一个原因。The confusing and conflicting information in training data can certainly be one cause.
可能改善不一致性的技术:
- consistency loss [Measuring and improving consistency in pretrained language models.]。[91] regulates the model training using a consistency loss defined by the model’s outputs across different input representations.
- Another technique of enforcing the LLMs to self-improve consistency is via “chain-of-thought" (COT) [29], which encourages the LLM to offer step-by-step explanations for its final answer.
2.4 Miscalibration
LLM对于输出的过度自信。
LLMs have been identified to exhibit over-confidence in topics where objective answers are lacking, as well as in areas where their inherent limitations should caution against LLMs’ uncertainty (e.g. not as accurate as experts)
过度自信的原因:
- 训练数据中存在很极端的观点,可能会导致LLM过度自信。This problem of overconfidence partially stems from the nature of the training data, which often encapsulates polarized opinions inherent in Internet data [95].
示例:

有两种方法获取LLM的自信/不确定性。一个是直接让LLM输出confidence;一个是获取LLM的下一个token的logits,这要求LLM提供了获取logits的渠道。这两种方法获得的confidence之间是可能存在差异的。
下面是让LLM直接输出confidence的例子:

目前缓解LLM过度自信的研究相对多一点:
- Mielke et al. [96] proposed a calibration method for “chit-chat" models, encouraging these models to express lower confidence when they provide incorrect responses.
- Guo et al. [97] offered a method for rescaling the softmax output in standard neural networks to counter overconfidence.
- LLM的对齐阶段可能会导致over-confidence。有研究提出让模型能够学会进行不确定性的表达,如“Answers contain uncertainty. Option A is preferred 80% of the time, and B 20%."。但是这需要人工能够构造出更加smooth的训练数据。
- 另一类方法是让LLM尝试回避回答不确定的问题,如让LLM生成答案:“I do not know the answer" or “As an AI model, I am not able to answer"。
2.5 Sycophancy
阿谀奉承,拍马屁(Sycophancy)指LLM会承认用户输入的错误信息。
LLM might tend to flatter users by reconfirming their misconceptions and stated beliefs [24, 122, 123]. This is a particularly evident phenomenon when users challenge the model’s outputs or repeatedly force the model to comply.
示例:

Sycophancy和前面的inconsistency是不一样的,Sycophancy是指强迫LLM承认/顺从用户的错误指令。而inconsistency通常是由于LLM内部存在缺陷,无法对于同样的问题给出一致的回答。
Sycophancy出现的可能原因:
- It is possibly due to existing sycophantic comments and statements in the training data.
- It can also be attributed to sometimes excessive instructions for the LLM to be helpful and not offend human users.
- It is possible that the RLHF stage could promote and enforce confirmation with human users.
因此,在对齐阶段,可能要在LLM顺从人类指令和坚持自身的回答之间做权衡。过于服从人类指令会导致LLM拍马屁;过于不服从人类指令,那么LLM的存在意义都没有了。
6. Explainability and Reasoning
对某些高风险场景来说,能够解释输出背后的原因,是必要且核心的。比如在金融、教育、健康等领域。
6.1 Lack of Interpretability
对于ML的可解释性已经受到了很多的关注,比如下面的几种提供解释的方法:
- removal-based explanations
- counterfactual explanations
- concept-based explanations
- saliency maps
而针对LLM的可解释,存在了集中新的思路:
- retrieval-augmented models。通过提供LLM进行归纳信息来源,让用户选择是否相信LLM的输出结果。比如用在web browser、search engine等场景中。
- Bills et al.提出可以使用LLM来解释LLM [Language models can explain neurons in language models.]。
- 让LLM提供结果的解释,也就是提供自己的thought step。chain-of-thought (CoT)方法。这可能是目前讨论的让LLM提供结果的解释最多的研究,下面的两个部分都是在讨论CoT [Chain of thought prompting elicits reasoning in large language models.]。
6.2 Limited General Reasoning
一般的逻辑推理能力。
Reasoning is an essential skill for various NLP tasks including question answering, natural language inference (NLI), and commonsense reasoning.
让LLM自己生成解释,是属于LLM出现后的全新研究领域。在很多任务中,利用prompt让LLM生成解释能够提高任务的性能。目前已经有了很多的关于CoT的工作,比如self-consistent CoT,tree-of-thoughts等方法。
然而LLM到底是不是依据它自己给出的解释进行推理的?这个问题目前看来不一定。
- 研究人员发现LLM有时候给出的解释,并不是它自己真正进行推理决策的过程。他们在上下文的样例中将正确答案总是放在option A的位置上,然后让LLM对于新的样例为什么选择A给出解释,然后发现LLM没有回答这种明显的bias。[Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.]
- 有工作指出,LLM在给出不正确的推理过程情况下,也可以生成最终正确的答案。[Mathematical capabilities of chatgpt.]
下面是几个对LLM在需要逻辑推理能力任务上的研究,进一步讨论了LLM推理能力的缺陷:
- [384] found performance of ChatGPT and GPT-4 dropped significantly on new datasets requiring logical reasoning, even though they performed relatively well on most existing benchmarks. This suggests current success may rely on exploiting dataset-specific quirks rather than robust human-like reasoning.
- LLMs are known to exploit superficial spurious patterns in logical reasoning tasks rather than meaningful logic [385].
目前的提高LLM推理能力的技术:
- prompt engineering: 各种不涉及参数更新的方法。prompt engineering techniques such as CoT, instruction tuning, and in-context learning can enhance LLMs’ reasoning abilities. For example, Zhou et al. [389] propose Least-to-most prompting that results in improved reasoning capabilities.
- pretraining: 从头预训练LLM,设计更加需要推理能力的预训练任务。[392, 393] show the effectiveness of pretraining an LLM from scratch with data curated for tasks that require complex reasoning abilities.
- continual training: 对于经过了预训练的LLM,进一步在新的数据上进行训练。In [390, 391], results show that continuing to train pretrained LLMs on the same objective function using high-quality data from specific domains (e.g., Arxiv papers and code data) can improve their performance on down-stream tasks for these domains.
- supervised fine-tuning: Chung et al. [30] propose to add data augmented by human-annotated CoT in multi-task fine-tuning. Fu et al. [394] show that LLMs’ improvement of reasoning ability can be distilled to smaller models by model specialization, which utilizes specialization data partially generated by larger models (e.g. code-davinci-002) to fine-tune smaller models. [Specializing Smaller Language Models towards Multi-Step Reasoning]
- reinforcement learning: 利用强化学习提升LLM的推理能力,比如让LLM不仅仅关注最后推理结果是否正确,也让LLM去关注中间步骤是否正确。
6.3 Limited Causal Reasoning
LLM的因果推理能力。和前面的逻辑推理能力比较起来,因果推理能力强调捕获状态/时间的cause-effect relationship。
Unlike logical reasoning, which derives conclusions based on premises, causal reasoning makes inferences about the relationships between events or states of the world, mostly by identifying cause-effect relationships.
Causal reasoning tasks specifically examine various aspects regarding LLMs’ understanding of causality, including inferring causal relationships among random variables (e.g. temperature and latitude) [399] and events (e.g. a person bumped against a table and a beer fell to the group) [358], answering counterfactual questions, and understanding rules of structural causal models [400] (e.g. d-separation).
有研究工作发现,GPT-4擅长推理必要条件,不擅长找充分条件。研究者认为可能的一个原因是寻找充分条件需要考虑更大范围的情况。[Causal reasoning and large language models: Opening a new frontier for causality.]
Jin et al.提出了一个新的因果推理数据集,CORR2CAUSE。在给定了一些变量和变量之间的correlation之后,让LLM判断假设的因果关系是否成立。作者发现LLM对于这种因果推理的能力还是比较弱的。[Can large language models infer causation from correlation?]
作者进行了一个case study,测试LLM是否理解了必要条件(Necessary Cause)这个概念:

在这个case study中的task 1中,GPT-3.5给出的情感和event之间的因果关系是正确的。“fans feeling disappointed” ← “canceled baseball game” ← “storm”. 然后LLM也能够识别出是哪个event引起了对应的情感的。但是它修改event来改变情感的时候,修改的event和最后的sentiment是不匹配的。
8. Robustness
验证LLM的性能是很重要的,而保证在部署前/运行中评估LLM的robustness也同等重要。
8.1 Prompt Attacks
LLMs are sensitive to the engineering of prompts. 前面的2.3的inconsistency已经证明了对于同一个question,不同的提法可能会导致完全不同的答案。更糟糕的是,一些小的偏差比如语法/拼写错误,也可以导致LLM有不同的答案:

prompt attacks,通过修改prompt,可以诱导LLM回答原本不应该回答的问题,比如:

不过这种prompt也可以被反过来用于增强LLM的训练数据,构造更加安全的LLM,这叫做adversarial prompt engineering。
8.2 Paradigm and Distribution Shifts
Paradigm and Distribution Shifts是指knowledge会随着时间而改变。LLM如果无法及时的学习到这种改变的话,它的回答也是不可信的:

8.3 Interventional Effect
干预效应是指算法的算法可能会导致data distribution发生变化。
举例:对于LLM来说,由于训练数据中的分布不一样。如果LLM使用用户的个人反馈/信息,来为不同用户提供差异化服务,这可能进一步导致未来的数据分布发生变化。比如说某个用户群体由于LLM提供的服务不好,选择不再使用LLM,那么LLM在未来就更不能够收集到足够的信息,导致未来LLM对于该特定用户群体的服务进一步变差。
再比如如果用户总是对某些不道德的输出选择赞同,那么这部分反馈可能会被用到将来的预训练/微调,导致LLM输出的bias进一步增强。
8.4 Poisoning Attacks
Poisoning Attacks通常是指通过修改训练数据,让模型特别是判别/分类模型的行为产生偏差。
Traditional poisoning attacks on general machine learning models aim to fool the model by manipulating the training data, usually performed on classification models. One of the most common ways of data poisoning is to alter the label of training samples.
比如有研究发现污染极少一部分的training data(0.1%),就可以让model完全丧失判别能力[Poisoning the unlabeled dataset of semi-supervised learning.]。
对于LLM来说,由于大多数训练数据来源于Internet,要污染training data更加容易。比如有研究发现通过构造域名/众包,可以污染LAION-400M [455], COYO-700M [456], and Wikipedia这些大规模数据集[Poisoning web-scale training datasets is practical.]。
更糟糕的威胁是,如果污染code LLM,那么这些LLM在自动生成代码的时候也会生成错误/有风险的代码,如果这些code LLM被广泛的应用于代码补全/代码建议,那么这些有风险的代码会不断传播。