Opportunities-and-Risks-of-Foundation-models
On the Opportunities and Risks of Foundation Models
2021 斯坦福大学 arxiv
在这篇论文里,斯坦福大学的研究者提出了一个概念“foundation models”用来指代在大规模数据上进行训练,可以用于大范围应用的模型。
下面仅仅是基础概念和发展的笔记,具体请参考论文。
AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles (e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities, and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
论文中定义的foundation model:
A foundation model is any model that is trained on broad data at scale and can be adapted (e.g., fine-tuned) to a wide range of downstream tasks; current examples include BERT [Devlin et al. 2019], GPT-3 [Brown et al. 2020], and CLIP [Radford et al. 2021].
foundation的命名(没有使用大语言模型、预训练模型等名字)主要是想强调模型的影响范围,并且想强调这些model不是能够直接进行各种下游任务,而是需要adaptation(fine-tuning、prompt、 architecture reusing、 embedding reusing等等)。这些模型的一点点改进,几乎可以推进所有NLP领域的进展,甚至是跨研究社区的领域进展,对于社会的法律和道德等方面也有影响,作者在论文称之为“强杠杆作用”(high leverage)。foundation模型的好的方面和坏的方面会被所有采用它的下游任务方法所集成,同时它还具有可解释性弱、可能产生不可预计的错误预测场景等问题。
作者提出,foundation models的出现使得AI的发展进入了新的阶段:
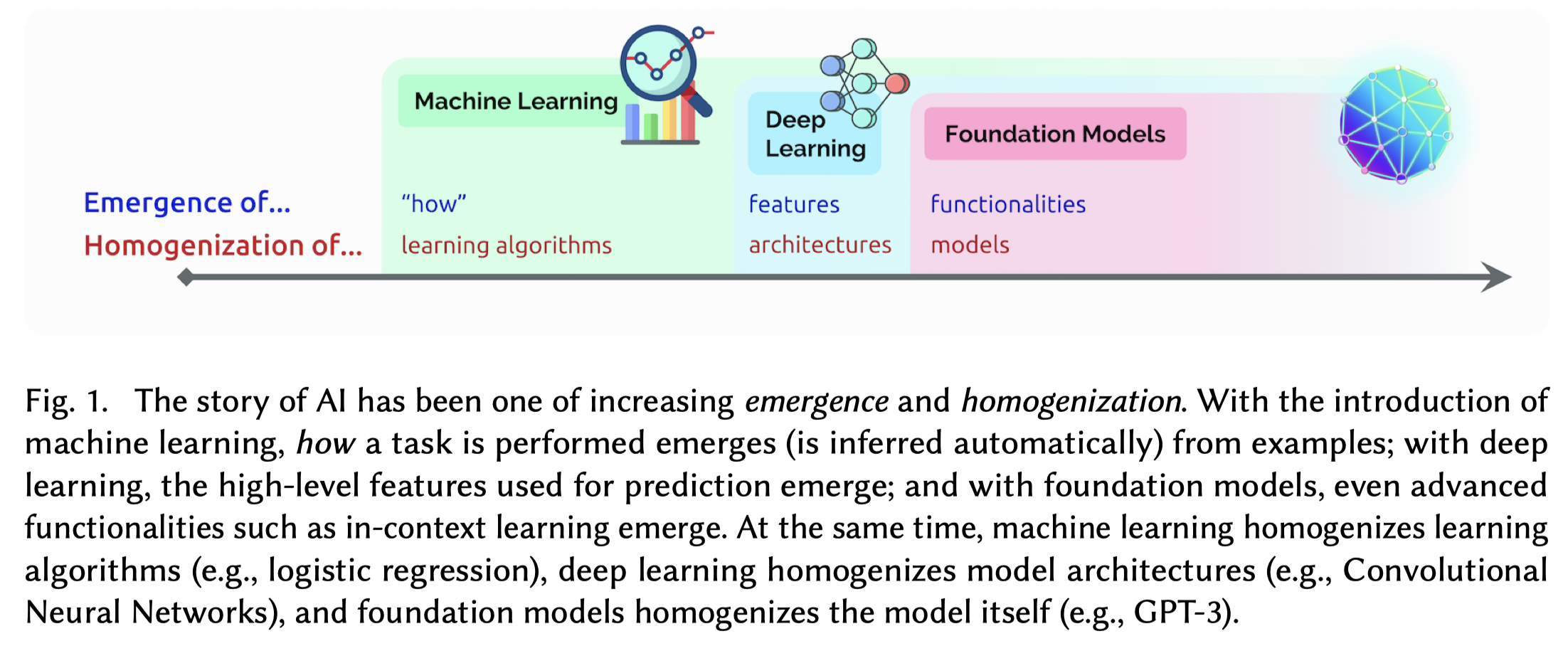
- machine learning:20世纪90年代开始到2015年,机器学习的算法/模型可以在不同应用通用,但是特征的导出依赖于领域专家的特征工程。机器学习取代了之前的专家知识库等概念,开始引领AI的发展。
- deep learning:2015年左右,Yann LeCun提倡的深度学习“deep learning”[Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep Learning. Nature 521, 7553 (2015).] 让模型架构能够在不同应用通用,用来实现自动特征导出,极大的降低了对领域专家特征工程的需求。只需要很少的数据预处理,深度学习模型就可以自动学习high level的feature。
- foundation model:2019年开始,随着BERT,GPT-2,T5等模型的出现,证明了模型在大规模数据集上进行训练,可以通过很小的改变适应到一系列和预训练任务独立的下游任务。不仅仅是deep learning模型的架构通用,而是model本身(参数、输出等)就可以在不同任务中通用。同时,跨研究社区、跨模态等应用也开始出现。
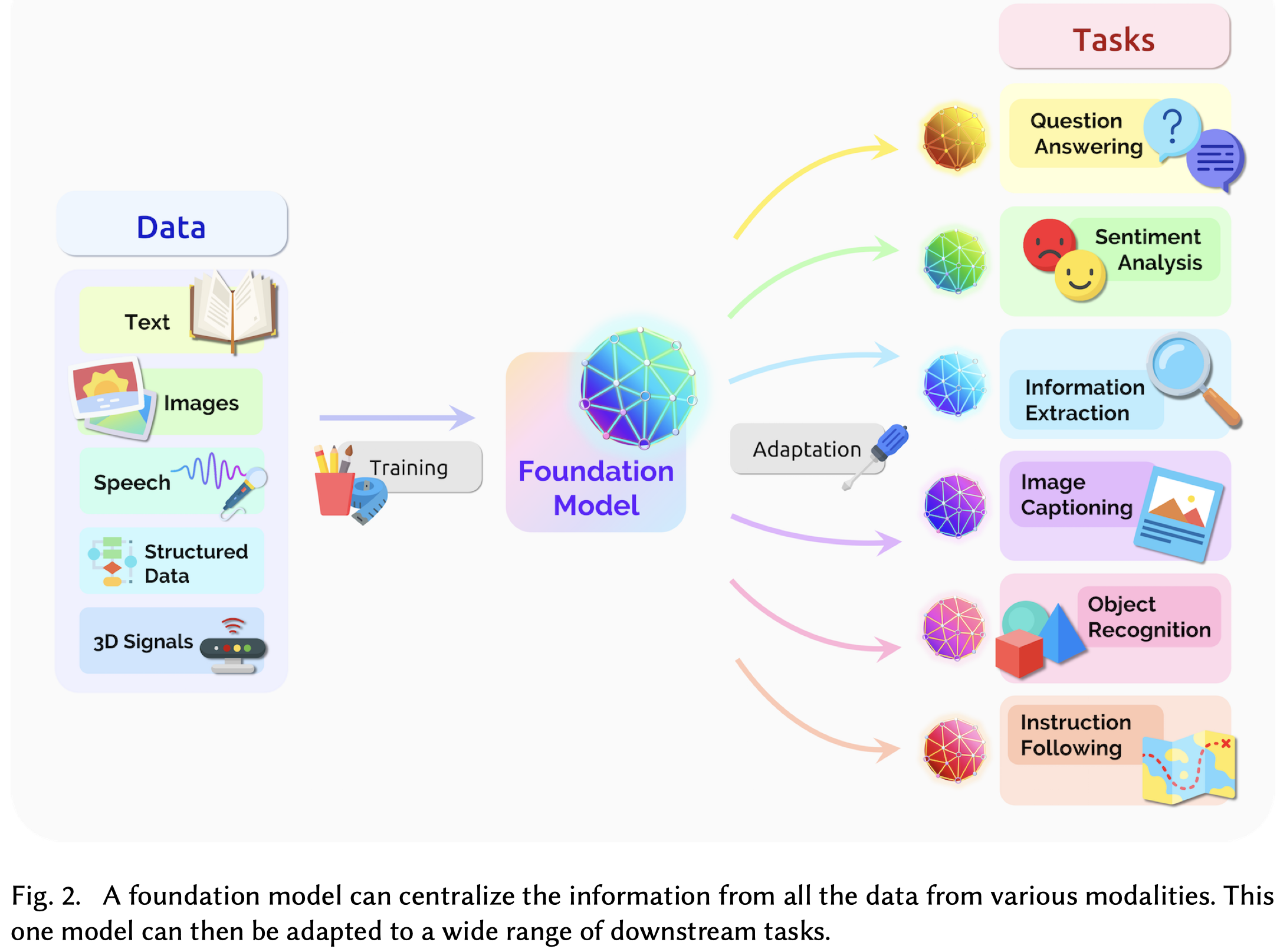
foundation models的出现依赖于模型结构(Transformer)、大规模在线数据的产生和收集、计算资源的指数级增加、训练方法(自监督学习)等多方面的进展。foundation model体现出的另一个不一样的点是,会直接面向社会公开/部署,让各个领域研究者/公司/个人/政府都可以尝试,因而对社会也产生了影响(环境/偏见/歧视/不可解释等)。
后面更多的论文内容没有记录,前面对于foundation model的探讨讲的不错。