LLM-too-positive-negative-comm-know
Say What You Mean! Large Language Models Speak Too Positively about Negative Commonsense Knowledge
复旦,ACL 2023,代码。
Large language models (LLMs) have been widely studied for their ability to store and utilize positive knowledge. However, negative knowledge, such as “lions don’t live in the ocean”, is also ubiquitous in the world but rarely mentioned explicitly in the text. What do LLMs know about negative knowledge? This work examines the ability of LLMs to negative commonsense knowledge. We design a constrained keywords-to-sentence generation task (CG) and a Boolean question-answering task (QA) to probe LLMs. Our experiments reveal that LLMs frequently fail to generate valid sentences grounded in negative commonsense knowledge, yet they can correctly answer polar yes-or-no questions. We term this phenomenon the belief conflict of LLMs. Our further analysis shows that statistical shortcuts and negation reporting bias from language modeling pre-training cause this conflict.
作者主要讨论了LLM对于negative commonsense knowledge在判断和生成两个角度有明显差别的问题。LLM擅长判断某个knowledge是否成立,但是在生成对应的negative knowledge cases的时候又常常发生错误。

Probing Protocol
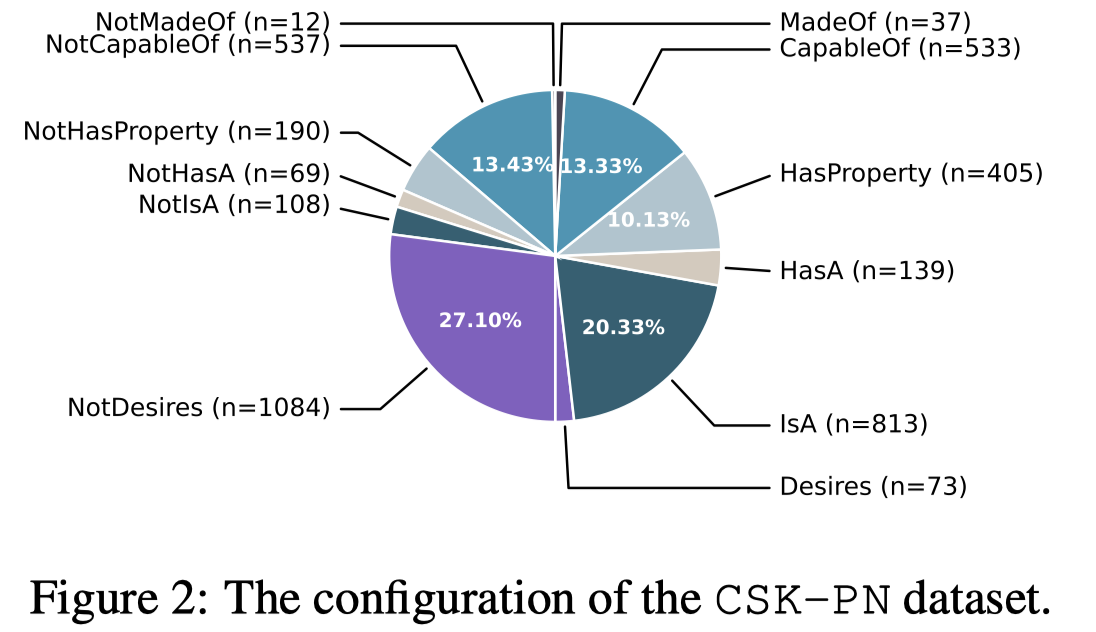
The CSK-PN Dataset
作者基于前人的工作[NegatER: Unsupervised Discovery of Negatives in Commonsense Knowledge Bases.]创建了一个新的探测LLM对于negative commonsense knowledge的数据集CKS-PN,一共有4,000个三元组,其中positive and negative分别相同的数量:
Probing Task Formulation
作者设计了两个task去探测:Boolean Question Answering (QA)和Constrained Sentence Generation (CG)。
Boolean Question Answering (QA):回答yes/no,用来探测LLM对于commonsense knowledge的belief:

Constrained Sentence Generation (CG)是一个keyword-to-sentence task,给定原始的三元组,模型需要生成一个完整的句子,自己判断是否在句子中添加negation cues,如not,unable等:

最后在探测的时候,作者使用了\(k\)-shot上下文学习。作者自己编写了\(32\)个正负样例examples,然后随机选择从正负样例中选择,初始默认正负样例各占一半。
Evaluation Metrics
三种指标:
- TP:accuracy on the positive cases
- TN:accuracy on the negative cases
- Acc:accuracy on the whole dataset
Do LLMs have negative commonsense knowledge?
The Belief Conflict
先看总体结果:
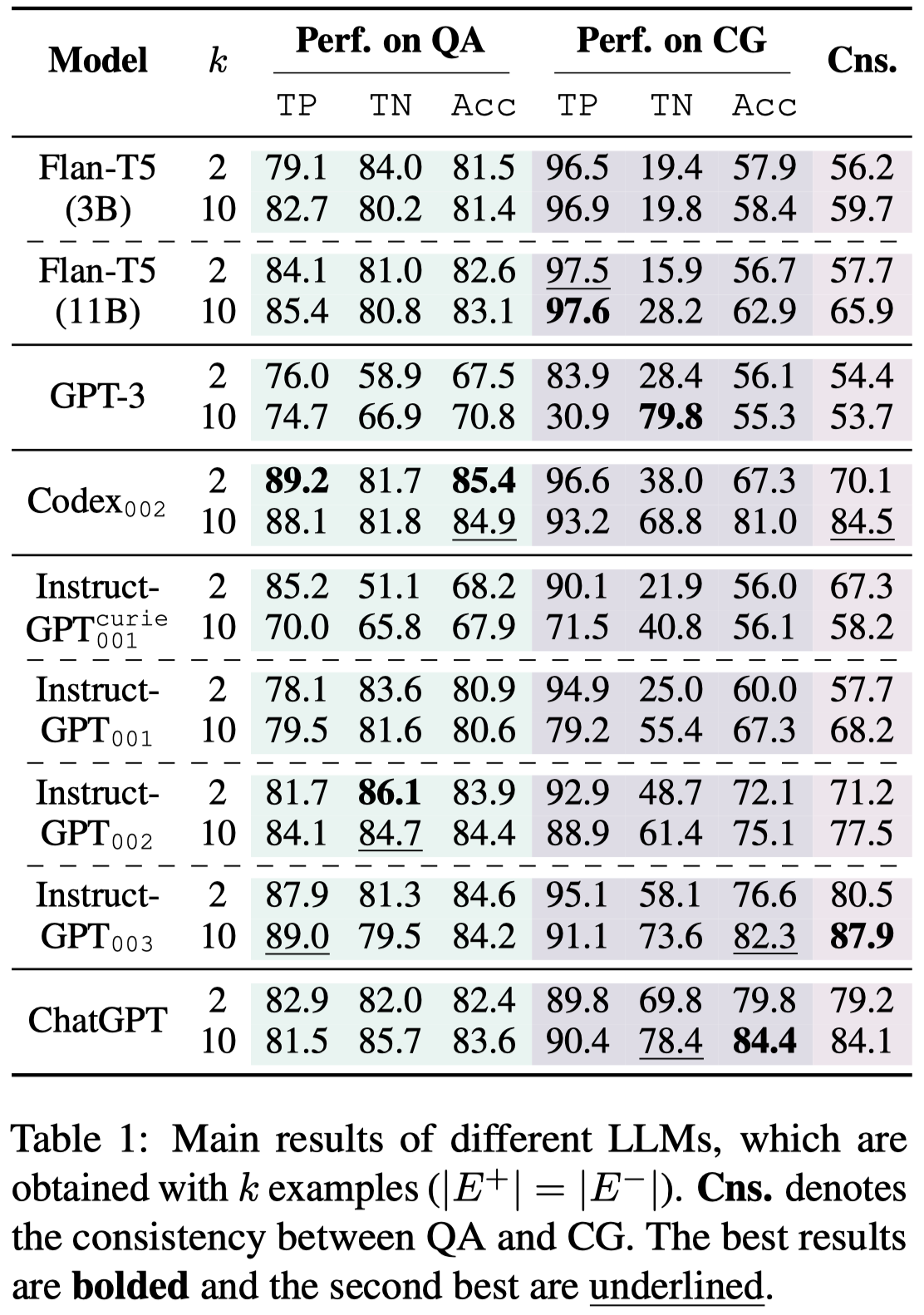
观察:
- belief conflict manifests itself in two ways: the gap between TP and TN on the CG task, and the gap of TN between the QA and CG tasks
- 对于QA task,大多数LLM的TP和TN指标差距不大;但是对于CG task,大多数LLM的TP要远好于TN
- InstructGPT-003和ChatGPT表现比较好,作者推测是因为在RLHF过程中,human feedback常常包含一些negative knowledge和rebuttal statements,比如admitting errors or instructing the model not to do something
Sensitivity to the Number of In-Context Examples
增大上下文样例数量,保持正负样例比例不变:
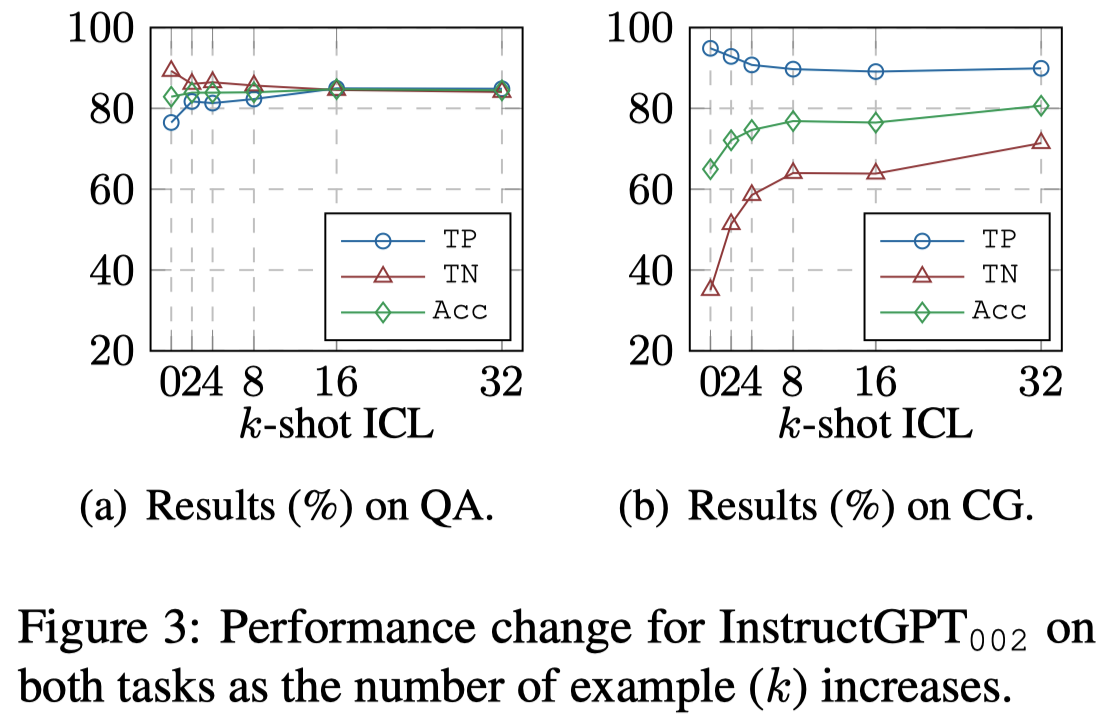
增大上下文样例数量对CG任务影响更大。
Analysis on the Belief Conflict
Could keywords as task input hinder the manifestation of LLMs’ belief?
作者首先检测是否是CG任务的使用keywords作为输入的prompting方式影响了negative knowledge的生成,因此作者设计了额外的两种task:
keywords-to-answer task

question-to-sentence task

实验结果:
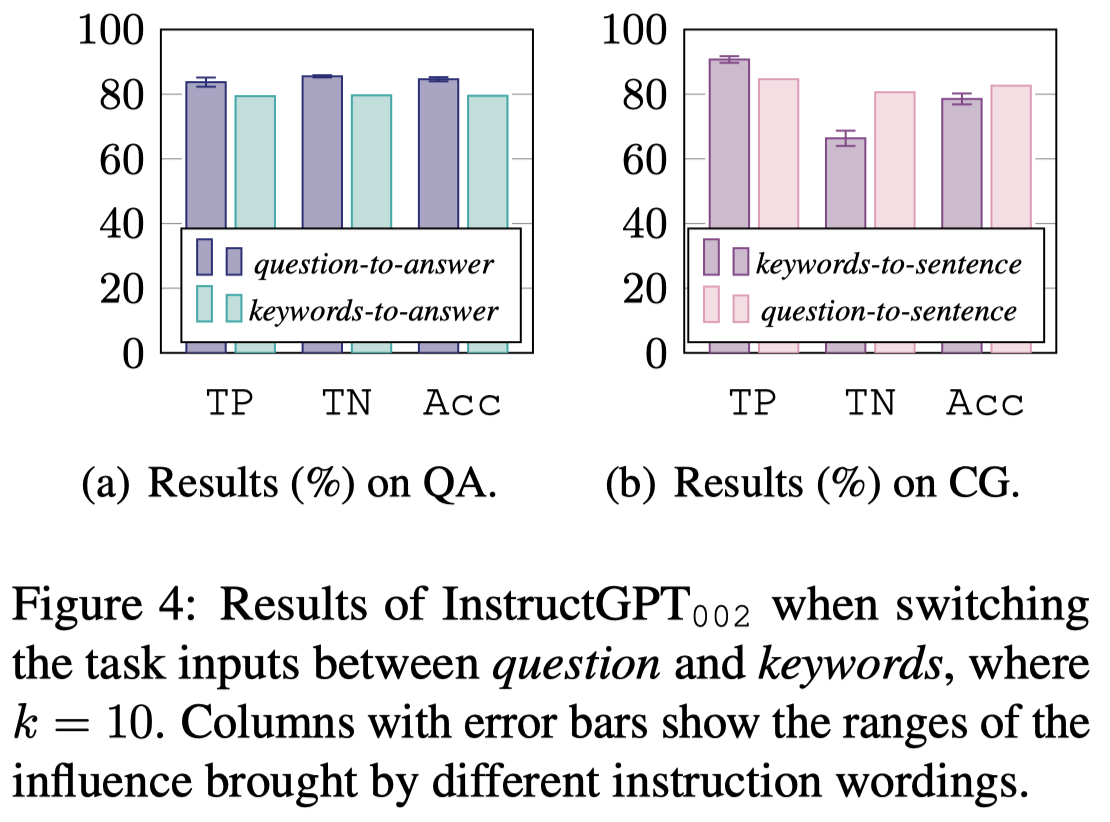
观察:
- Figure a证明了使用keywords作为输入,LLM仍然能够在QA任务中判断出negative knowledge是否成立;这说明keywords作为输入不会太影响对于knowledge的belief
- Figure b证明了如果把keywords换为一个完整的question,TP和TN的指标差异消失了。作者推测尽管回答的还是个完整的sentence,但是由于在预训练语料中有很多的negated texts following a Boolean question,比如"...? No, lions do not live in the ocean."这种格式的句子。LLM对于这种问题question已经将其退化为了一个回答yes/no的判别问题了。为了验证这一点判断,作者移除了上下文的样例,直接让LLM回答,然后发现此时80%以上的回答都以Yes/No开头,然后再生成sentence。
- 上面这点的发现,让人怀疑commonsense knowledge在LLM的encoding方式,它是否仅仅擅长类比在语料中见过的表达,而很难泛化为其它的表达?LLM是否真正的理解了knowledge?According to this experiment, commonsense knowledge seems to be stored in LLMs in the same manner as it is in the corpus. LLMs struggle to generalize them, as evidenced by the keyword inputs for negative knowledge that do not have a statistical shortcut from pre-training.
Will the keyword co-occurrence within corpus affect LLMs’ generation?
作者探究这种negative knowledge和positive knowledge之间的差异,是否和预训练语料中实体之间的共现频率相关。
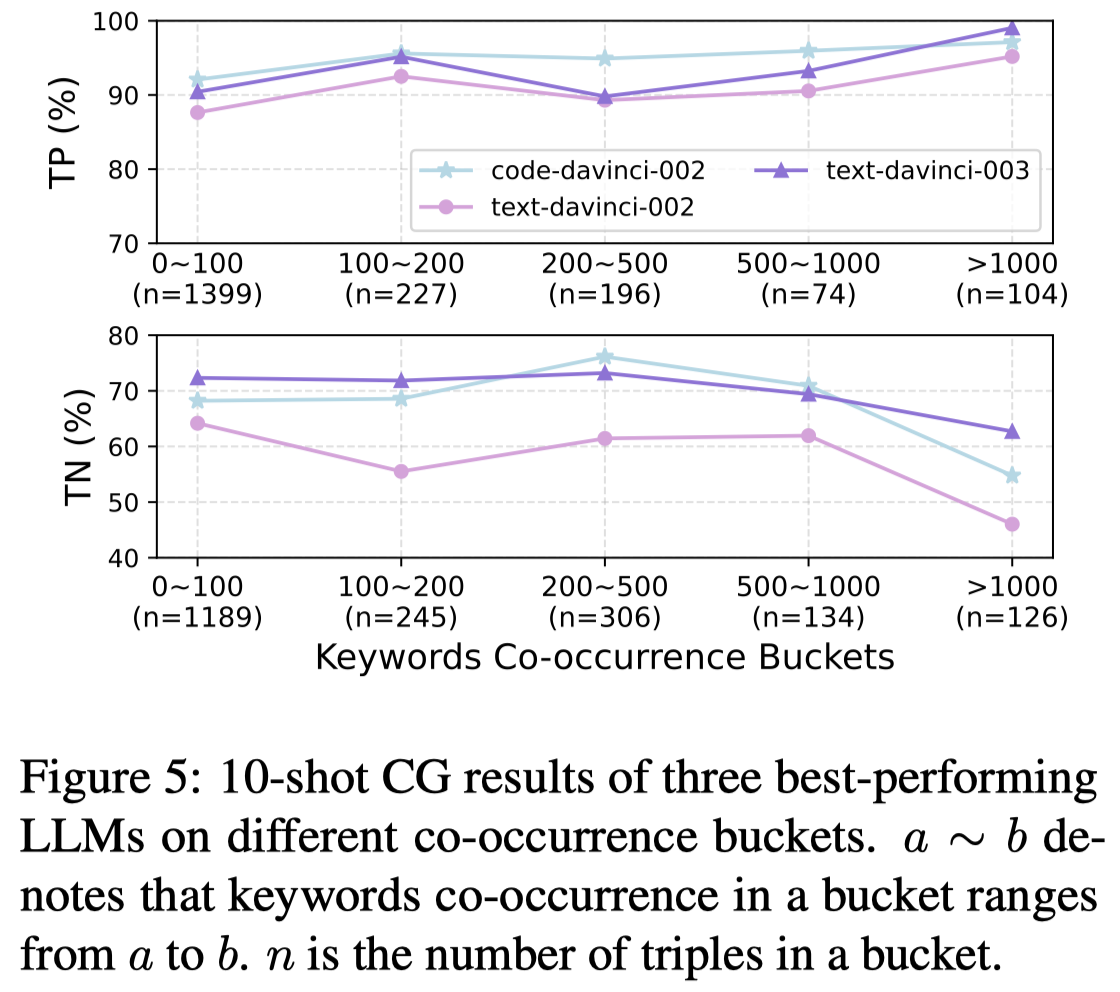
观察:
- We conclude that the hard-to-generate negative knowledge for LLMs tend to be those in which they have seen many subjects and objects appear together. 越倾向于一起出现的头尾entity,LLM越倾向于产生positive的描述,越难以正确的描述negative knowledge
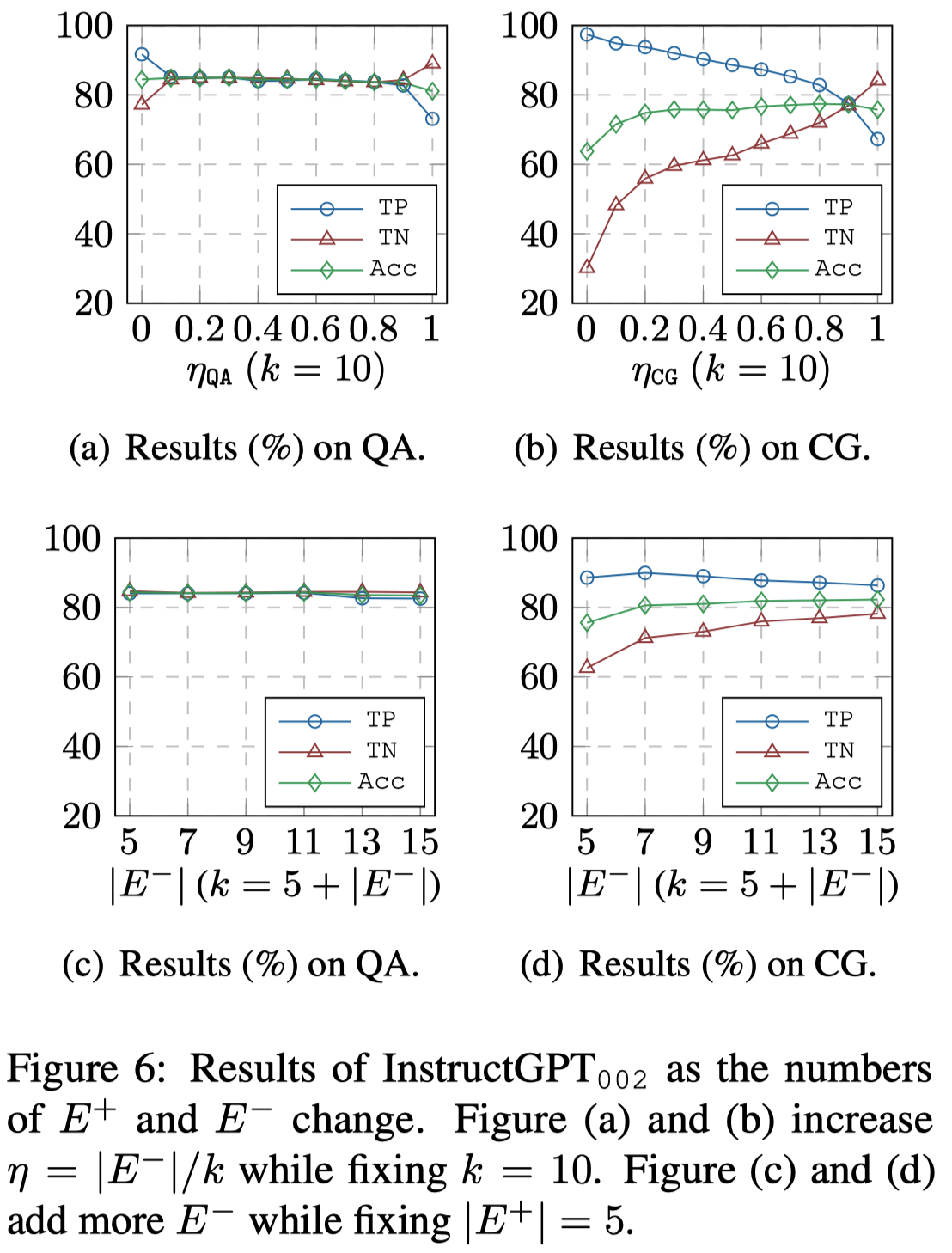
How does the balance of positive and negative examples affect negation bias?
作者发现通过增加上下文中负样例的数量/占比,可以一定程度缓解难以正确产生negative cases的问题:
Do Chain-of-Thought help generate texts with negative commonsense knowledge?
作者讨论了是否能够通过CoT来缓解对negative knowledge的生成问题:
- Deductive Reasoning Prompting:演绎推理,prompting中的上下文样例被修改为
<input, “Let’s think step by step: ...”, output>的格式。- 对于positive propositions,采用modus ponens logic,
if P then Q. P. Therefore, Q.,举例:Things with lightweight bodies and strong wing muscles (P) can usually fly (Q). Birds have these physical characteristics (P). Therefore, birds can fly. (Q)。 - 对于negative propositions,采用modus tollens,
If P then Q. Not Q. Therefore, Not P.,举例:If something is a intelligent being (P), then it must have the ability to think (Q). Computers cannot think (Not Q). Therefore, computers are not intelligent beings (Not P).
- 对于positive propositions,采用modus ponens logic,
- Fact Comparison Prompting:和已有的related fact保持一致,prompting中的上下文样例被修改为
<input, “Related fact: ...”, output>,举例:对于lions do not live in the ocean的Related fact举例是lions live in the land。
实验结果:
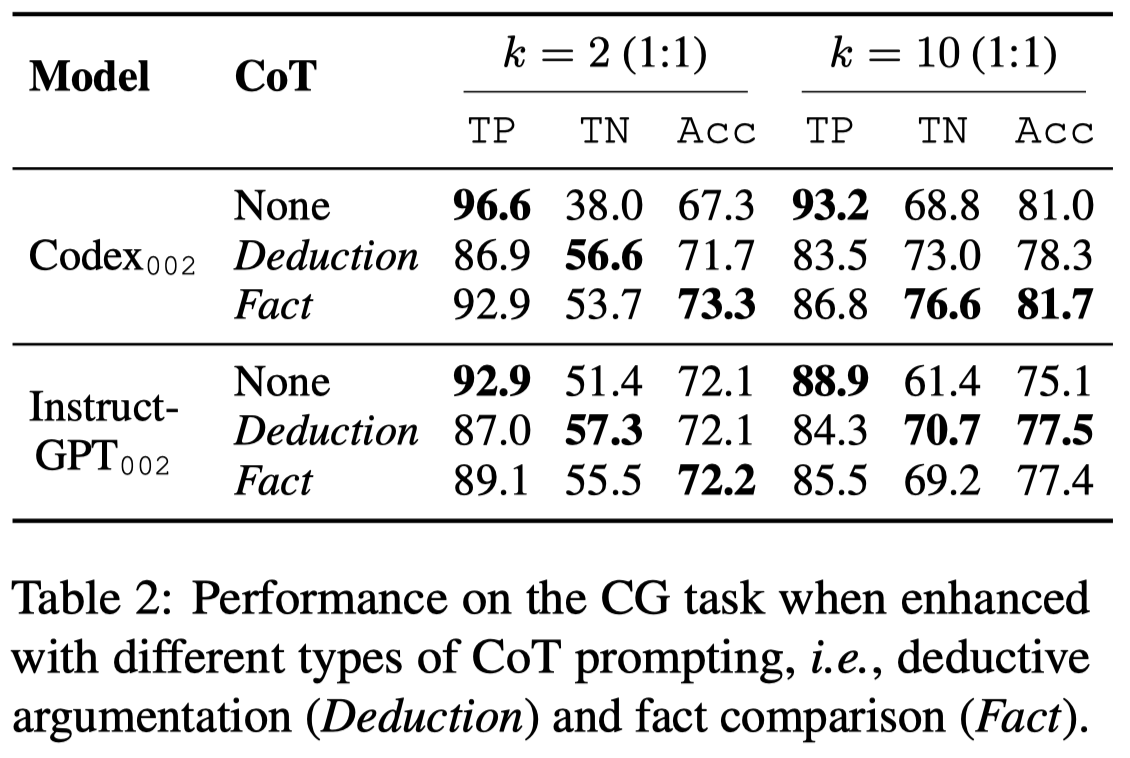
观察:
- 加入中间的推理步骤能够缓解对negative knowledge的生成问题
- 演绎推理Deductive Reasoning的方法比Fact Comparison的方法在TP上效果下降;作者认为这是因为演绎推理会倾向于关心特殊情况,而在判断commonsense的时候比较保守。commonsense knowledge不是在所有情况下都成立的,它只是common情况下成立,就比如常识上鸟都会飞;但是企鹅是鸟,然后企鹅不会飞。这种特点导致演绎推理常常认为一般的knowledge不成立,降低了TP指标。这一点应该是commonsense和fact knowledge的区别之一