LLM-survey-renmin
A Survey of Large Language Models
人大,arXiv 2023.05,代码。
Ever since the Turing Test was proposed in the 1950s, humans have explored the mastering of language intelligence by machine. Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable artificial intelligence (AI) algorithms for comprehending and grasping a language. As a major approach, language modeling has been widely studied for language understanding and generation in the past two decades, evolving from statistical language models to neural language models. Recently, pre-trained language models (PLMs) have been proposed by pretraining Transformer models over large-scale corpora, showing strong capabilities in solving various natural language processing (NLP) tasks. Since the researchers have found that model scaling can lead to an improved model capacity, they further investigate the scaling effect by increasing the parameter scale to an even larger size. Interestingly, when the parameter scale exceeds a certain level, these enlarged language models not only achieve a significant performance improvement, but also exhibit some special abilities (e.g., incontext learning) that are not present in small-scale language models (e.g., BERT). To discriminate the language models in different parameter scales, the research community has coined the term large language models (LLM) for the PLMs of significant size (e.g., containing tens or hundreds of billions of parameters). Recently, the research on LLMs has been largely advanced by both academia and industry, and a remarkable progress is the launch of ChatGPT (a powerful AI chatbot developed based on LLMs), which has attracted widespread attention from society. The technical evolution of LLMs has been making an important impact on the entire AI community, which would revolutionize the way how we develop and use AI algorithms. Considering this rapid technical progress, in this survey, we review the recent advances of LLMs by introducing the background, key findings, and mainstream techniques. In particular, we focus on four major aspects of LLMs, namely pre-training, adaptation tuning, utilization, and capacity evaluation. Furthermore, we also summarize the available resources for developing LLMs and discuss the remaining issues for future directions. This survey provides an up-to-date review of the literature on LLMs, which can be a useful resource for both researchers and engineers.
1. Introduction
语言是人类从小开始学习,终身都在使用的工具。让机器能够像人一样的读、写和交流是人工智能领域一直以来的追求。
语言建模language modeling(LM)是指能够生成词序列概率似然的技术手段,能够实现预测下一个或者确实的token。其对应模型的发展经历了四个阶段:
- Statistical language models (SLM). 根据固定范围的context来预测下一个词,比如n-gram models。需要注意下,这里的SLM的缩写,和某些论文中出现的Small Language Model是两个含义。
- Neural language models (NLM). 利用神经网络来预测word sequence probabilities。每一个word被建模为distributed representations [A neural probabilistic language model 2003],最出名的有word2vec方法。
- Pre-trained language models (PLM). 先在语料上预训练,之后在具体任务上微调。早期的尝试包括ELMo(基于biLSTM),后续出现了BERT,GPT1,2(基于Transformer)等方法。
- Large language models (LLM). 简单的讲LLM就是large-scaled PLM,比如GPT-3,PaLM等。
LLM和PLM(之前看到也有研究把PLM对应的方法叫做SLM)的区别,作者分出3点:
- LLM比起SLM涌现出了新的能力(emergent abilities [Emergent abilities of large language models 2022]),比如GPT-3比起GPT-2,能够通过in-context learning进行few-shot任务。
- LLM改变了人们使用和发展AI算法的方式。对LLM的应用更多的是通过改变输入,然后利用API进行访问。
- LLM使得科研和工程之间的界限变得模糊。预训练LLM可能模型架构本身不再是问题,问题是工程实践(如何处理和选择数据、如何并行训练、如何细微地调整模型的细节)
由于现在对于LLM模型最小scale并没有统一的认识(特别是LLM的性能和训练数据以及模型本身的大小有关),因此在这篇论文里,作者简单的把10B以上参数量的PLM叫做LLM。
发展LLM面临的问题,作者总结了3个大的方面:
- LLM出现能力涌现的原因到底是什么?
- 学术界较难从头训练一个LLM,特别是很多LLM由大公司开发,实现细节不公开(这就是为什么我们要发展open LLM)
- 如何让LLM和人类偏好对齐?特别是如何阻止生成有毒的、虚假编造的输出。
2. Overview
2.1 Background for LLMs
scaling law是指随着模型大小,数据集大小以及计算次数等的增加,LLM性能变化的形式化的变化趋势。作者介绍了两个有代表性的scaling law:
- KM scaling law:2020年OpenAI提出的[Scaling laws for neural language models 2020],表示模型的性能和三个因素成power-law:model size(模型大小),dataset size(训练数据大小)和training compute(训练计算FP)。KM scaling law更强调在一定的计算负担情况下,增大model size而不是dataset size。
- Chinchilla scaling law:2022年Google DeepMind提出的,强调在一定的计算负担情况下,更好的选择是同时增加dataset size和model size。
利用scaling law可以帮助我们选择预训练模型大小和数据集大小。
但是,存在一些LLM能力不符合scaling law,当模型大小较小的情况下无法显示,然而在大模型中突然表现出来的能力,这就是LLM的涌现能力(Emergent Abilities)。下面是3个典型的涌现能力:
- In-context learning:在GPT-3中正式提出(虽然在GPT-2中实际已经使用),是指模型在提供了自然语言描述的指令instruction和几个demonstrations之后,无需训练和梯度更新,就能够生成期望的输出的能力。
- Instruction following:通过在预训练数据集中加入指令instruction,进行instruction tuning,模型能够学会仅仅通过指令,不需要demonstration,就能够准确执行任务的能力。
- Step-by-step reasoning:通过chain-of-thought (CoT) prompting,LLM模型能够一步步的解决复杂任务,这一点在之前的PLM是无法做到的。
2.2 Technical Evolution of GPT-series Models
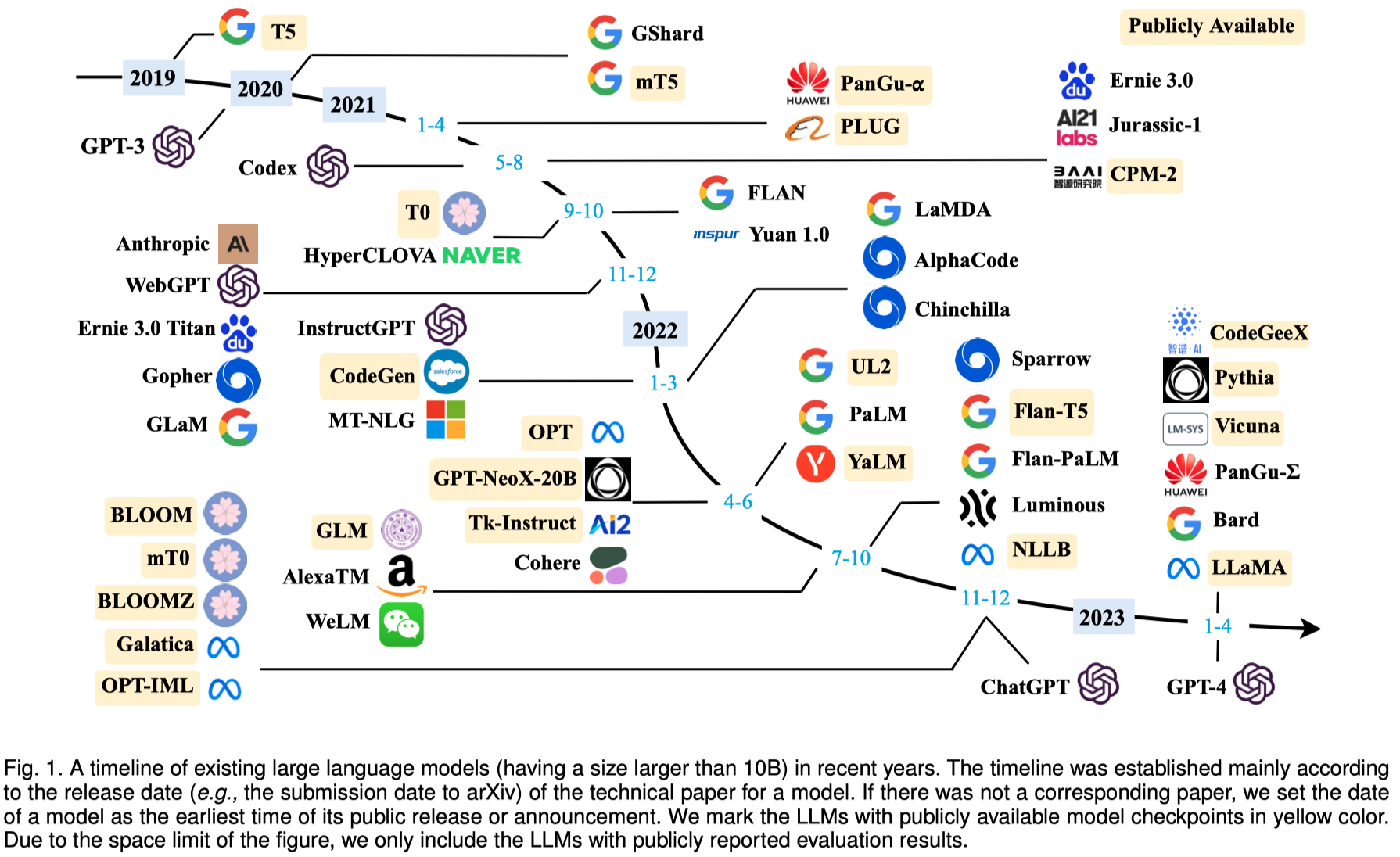
作者简要的介绍了GPT家族的发展过程。
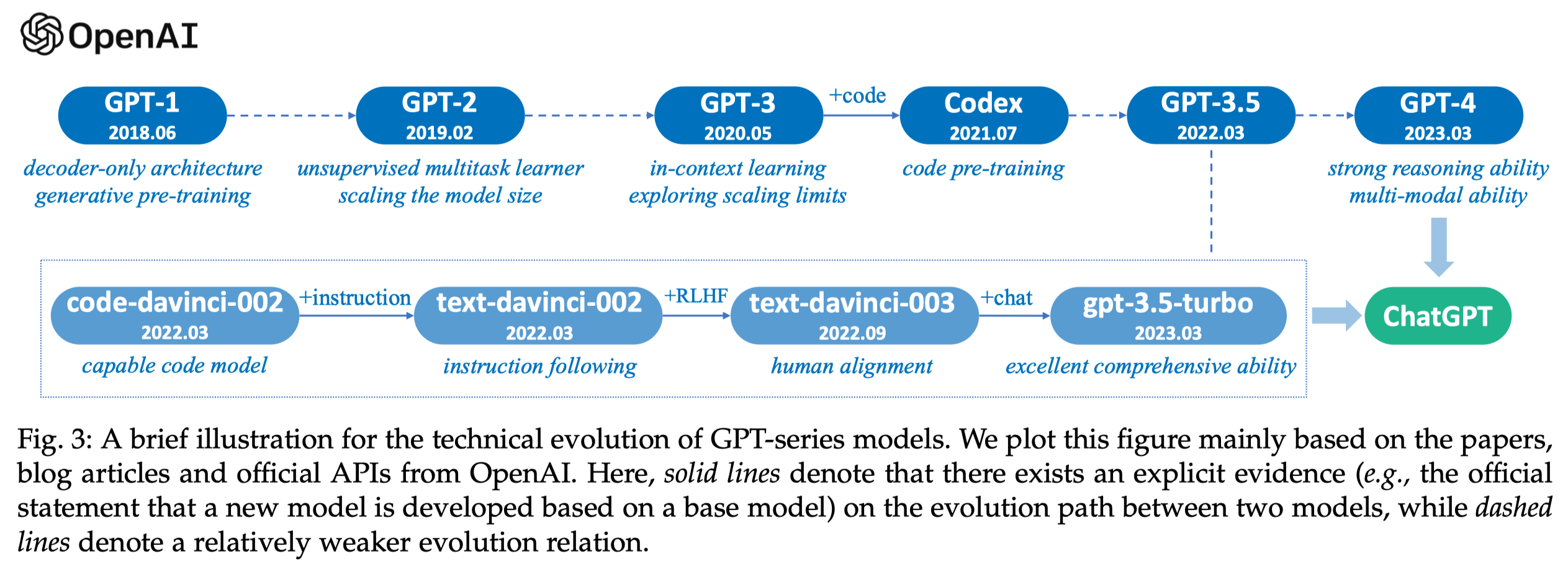
- Early Explorations. GPT-1和GPT-2。GPT-1(Generative Pre-Training)2017年提出,follow了Transformer的工作,使用Transformer的decoder部分进行单向的next word预测。GPT-2在2019年提出,参数量达到了1.5B,在更大的数据集上进行训练,通过把各类NLP任务建模为word prediction任务,实现无需训练的通用多任务学习器。
- Capacity Leap. GPT-3在2020年提出,是OpenAI的里程碑,参数量达到了175B。GPT-3不仅仅能够适用于很多NLP任务,还能够适用于很多复杂的需要推理的任务上。
- Capacity Enhancement. 对GPT-3能力的增强,主要包括代码预训练(Training on code data)和人类对齐(Human alignment)。通过加入代码数据,增强GPT-3的推理能力,代表工作是2021年7月提出的Codex。人类对齐Human alignment是指从人类偏好中进行学习,代表工作是2022年1月提出的InstructGPT,利用了RLHF人类反馈强化学习(reinforcement learning from human feedback)。RLHF不仅能够提升LLM对于人类指令的理解,更能够用来缓解有害输出的生成(比如询问GPT怎么样制作爆炸物)。这些对于GPT-3的提升产生了GPT-3.5系列模型。
- The Milestones of Language Models. ChatGPT在2022年11月推出,ChatGPT和InstructGPT可以看做是双胞胎,只不过ChatGPT的预训练数据集中加入了对话数据,让ChatGPT格外擅长和人类交互。随后在2023年3月推出了多模态GPT-4。
3. Resources of LLMs
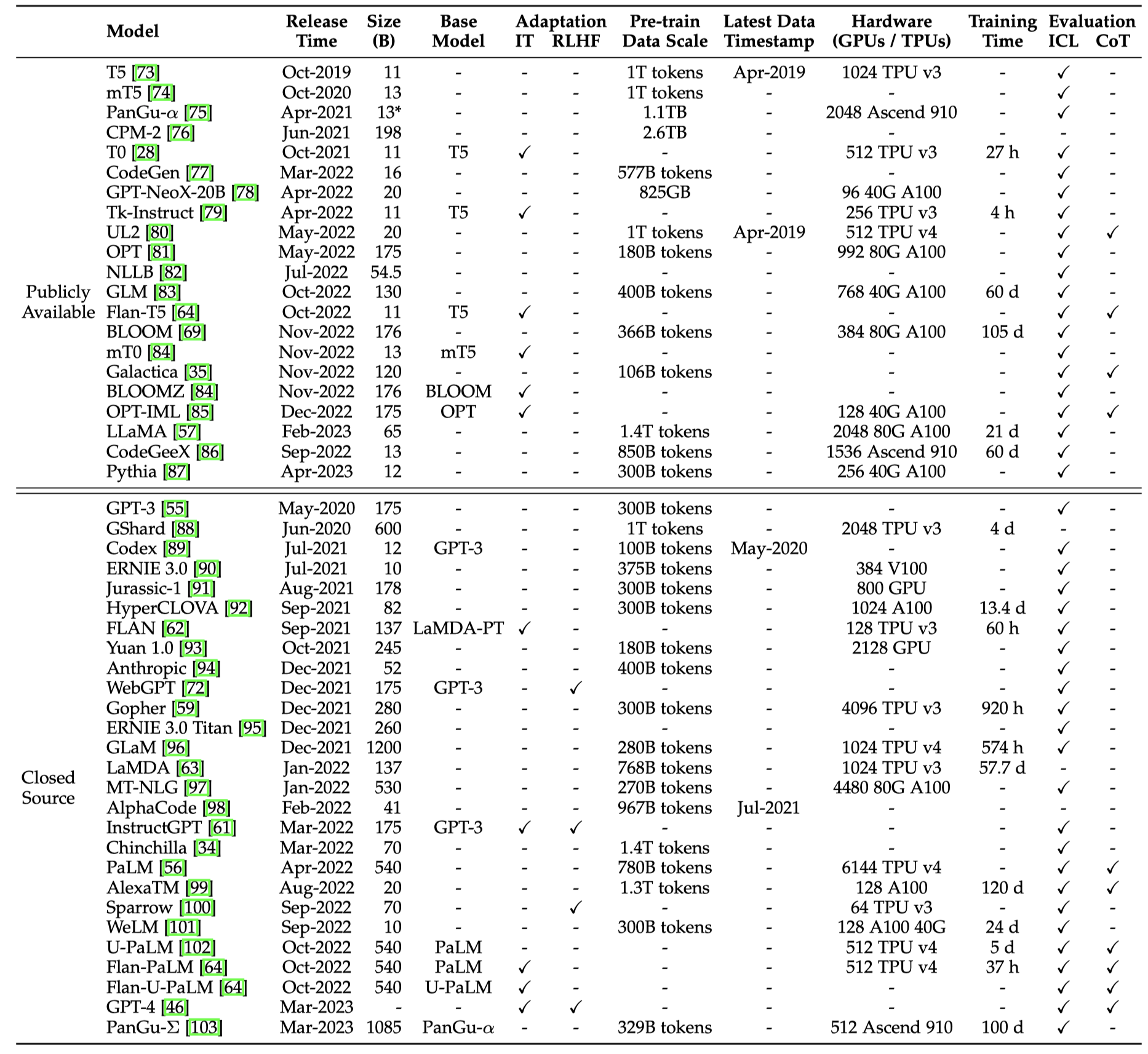
3.1 Publicly Available Model Checkpoints or APIs
目前可以获取的开源参数的模型:
Models with Tens of Billions of Parameters. 这个量级的LLM大致参数是在100B以下。作者推荐了以下几个可以考虑的模型:
- Flan-T5(11B version),可以用来研究指令微调的效果,它从指令训练task的数量、model size和加入CoT的数据三个方面进行了训练。
- CodeGen(11B version):可以作为探究LLM生成代码的base。它还额外的引入了MTPB这个benchmark,包括了115个专家生成的编程问题。
- mT0(13B version):可以作为多语言任务的base。
- PanGu-\(\alpha\)(largest public version 13B):可以作为中文zero-shot或者few-shot任务的base。
- LLaMA(largest version 65B):目前被应用研究最多的开源LLM,下面有具体的介绍。
- Falcon:通过更加精心准备的预训练数据达到更好效果的最新开源LLM。
Models with Hundreds of Billions of Parameters. 100B以上的LLM。这一级别的开源模型就比较少了,包括OPT,OPT-IML,BLOOM,BLOOMZ,GLM等。
- OPT(175B version)有个对应的加入了指令微调的版本OPT-IML。
- BLOOM(176B version)和BLOOMZ(176B version)主要可用于跨语言任务。
- GLM(130B version):一个中英双语LLM。额外提供了一个很流行的更小size的中文模型ChatGLM2-6B(是之前ChatGLM-6B的升级版),其加入了量化、32K上下文size和快速推理等特征/技术。
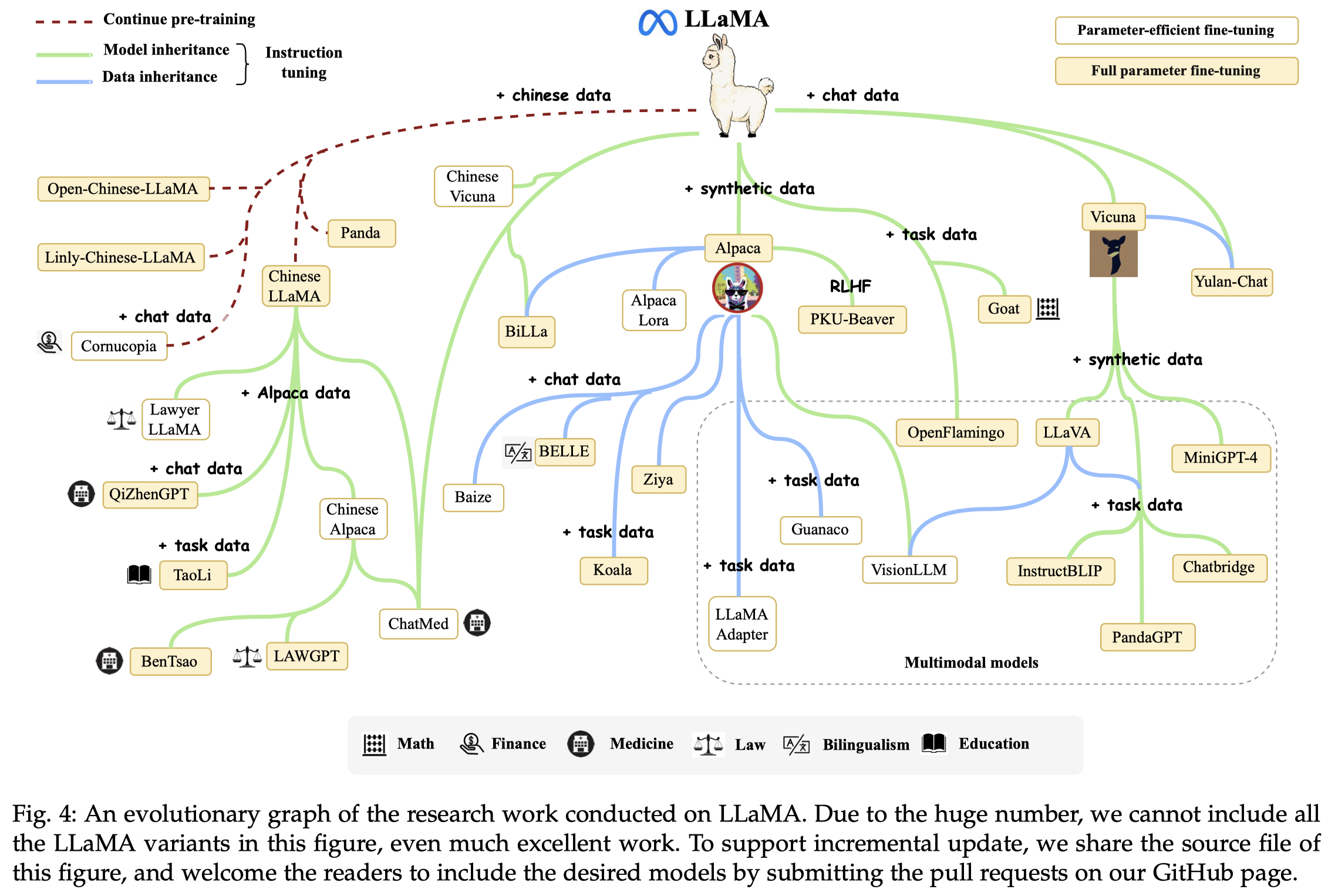
LLaMA Model Family. 由Meta AI在2023年2月推出的开源LLM,可能是目前被改造应用最多的模型。
Alpaca:是首个基于LLaMA-7B进行指令微调的模型。指令微调的数据是使用了52k个利用self-instruct基于
text-davinci-003生成的指令。该指令微调数据集叫做Alpaca-52K,并且被后续的Alpaca-LoRA,Koala,BELLE等LLM使用。Vicuna:在LLaMA基础上加入了从ShareGPT平台上导出的用户对话数据。Vicuna是目前很多multimodal LLM常用的base language model,比如LLaVA,MiniGPT-4,InstructBLIP和PandaGPT。
3.2 Commonly Used Corpora
常见的预训练LLM的数据来源:
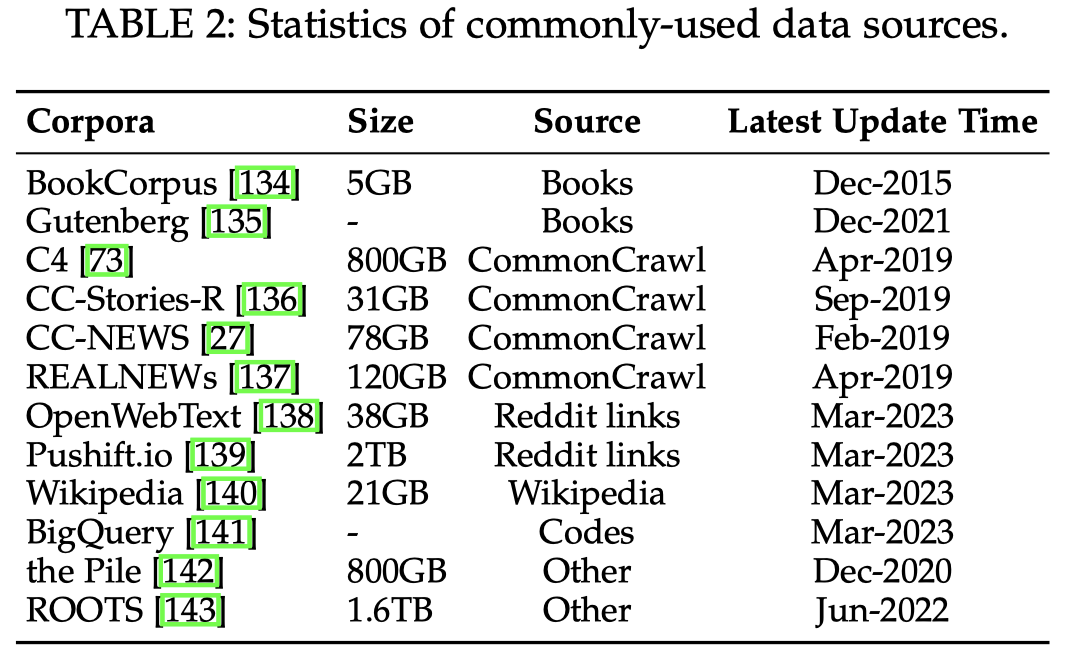
- Books:
- BookCorpus:小规模的书籍数据集,11000本书,GPT和GPT-2中使用了。
- Project Gutenberg:目前最大的公开书籍数据集,70000本书,在MT-NLP和LLaMA预训练中使用了。
- Books1和Books2:更大的book数据集,在GPT-3的训练中使用了,但是未开源。
- CommonCrawl. CommonCrawl.是目前互联网中最大的开源爬取网页的数据集,千万亿字节/千T级别的数据。但是数据质量较低,有以下的数据清洗的版本:
- C4:Colossal Clean Crawled Corpus,有5个版本,en (806G), en.noclean (6T), realnewslike (36G), webtextlike (17G), and multilingual (38T)。
- CC-Stories (31G):CommonCrawl.的一个子集,其中的内容是story-like的样式。可以通过CC-Stories-R访问其的复现版本。
- REALNEWS (120G)
- CC-News (76G)
- Reddit Links. 从Reddit上爬取的数据
- WebText:包括了Reddit上点赞数/赞同数高的post,未开源。有个开源的替代OpenWebText。
- PushShift.io:一个不断更新的Reddit的dump数据集,还有提供了一套查询,总结等功能的接口。
- Wikipedia. 维基百科,很多LLM都会使用的数据源。GPT-3,LaMDA,LLaMA都使用了。
- Code:包括代码和代码相关的QA平台
- BigQuery:Google开源的大规模代码数据
- Others
- Pile(800G):book,code,website,paper等各类数据混杂的数据集。GPT-J (6B), CodeGen (16B) 和 Megatron-Turing NLG (530B)等LLM使用。
- ROOTS(1.61T):各类小数据集的混合,59种语言,包括自然语言和编程语言。BLOOM预训练使用。
3.3 Library Resource
作者总结了几个可以用来训练LLM的库
- Transformers:Hugging Face的开源仓库
- DeepSpeed:Microsoft开发的优化库,可以用来训练LLM,比如MT-NLG,BLOOM就是基于此库
- Megatron-LM:英伟达开发的用于训练LLM的库,支持各类并行算法、分布式训练等
- JAX:Google提供的开发高性能ML算法的库
- Colossal-AI:HPC-AI Tech提供的开发大规模AI模型的库,ColossalChat就是基于此开发
- BMTrain:OpenBMB开发的支持分布式训练大规模参数量AI模型的库,目前可以通过它的ModelCenter直接访问Flan-T5、GLM。
- FastMoE:支持训练MoE模型,基于PyTorch。
4. Pre-Training
4.3 Data Collection and Preparation
略,参见论文
4.2 Architecture
现有的主流LLM架构:
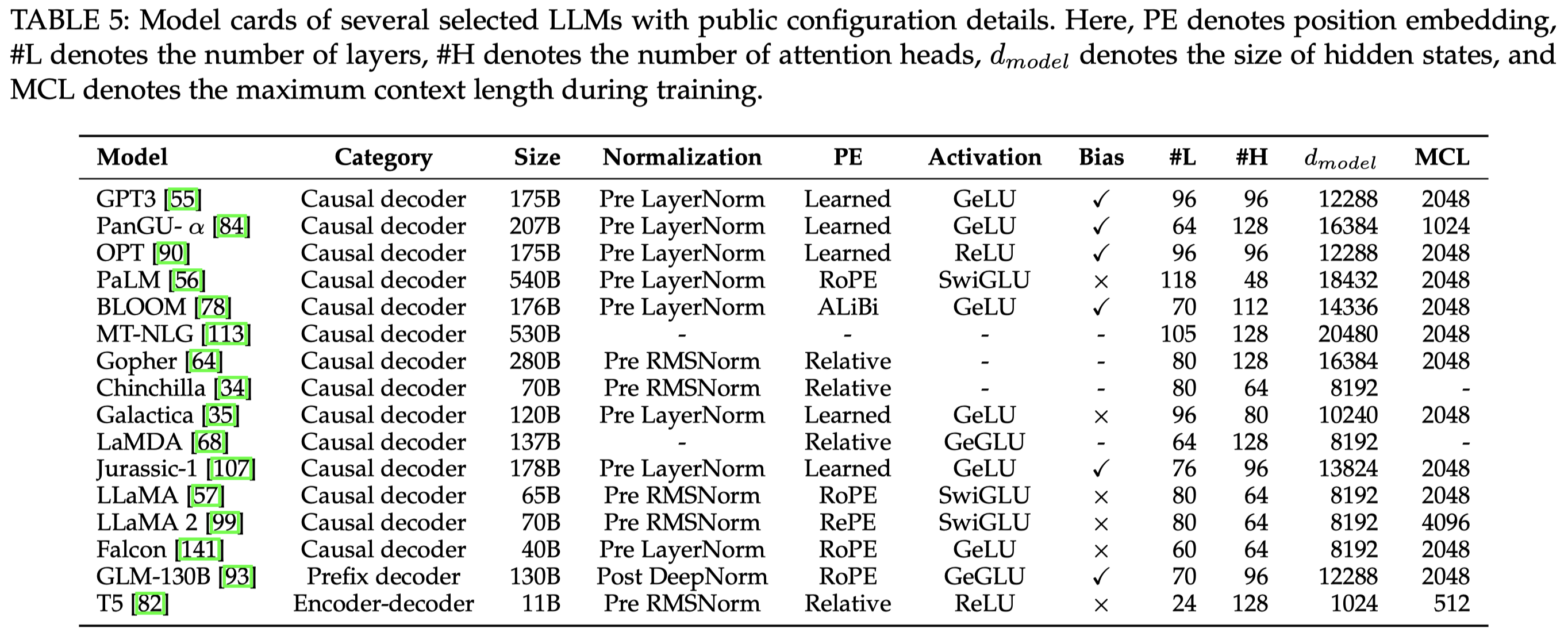
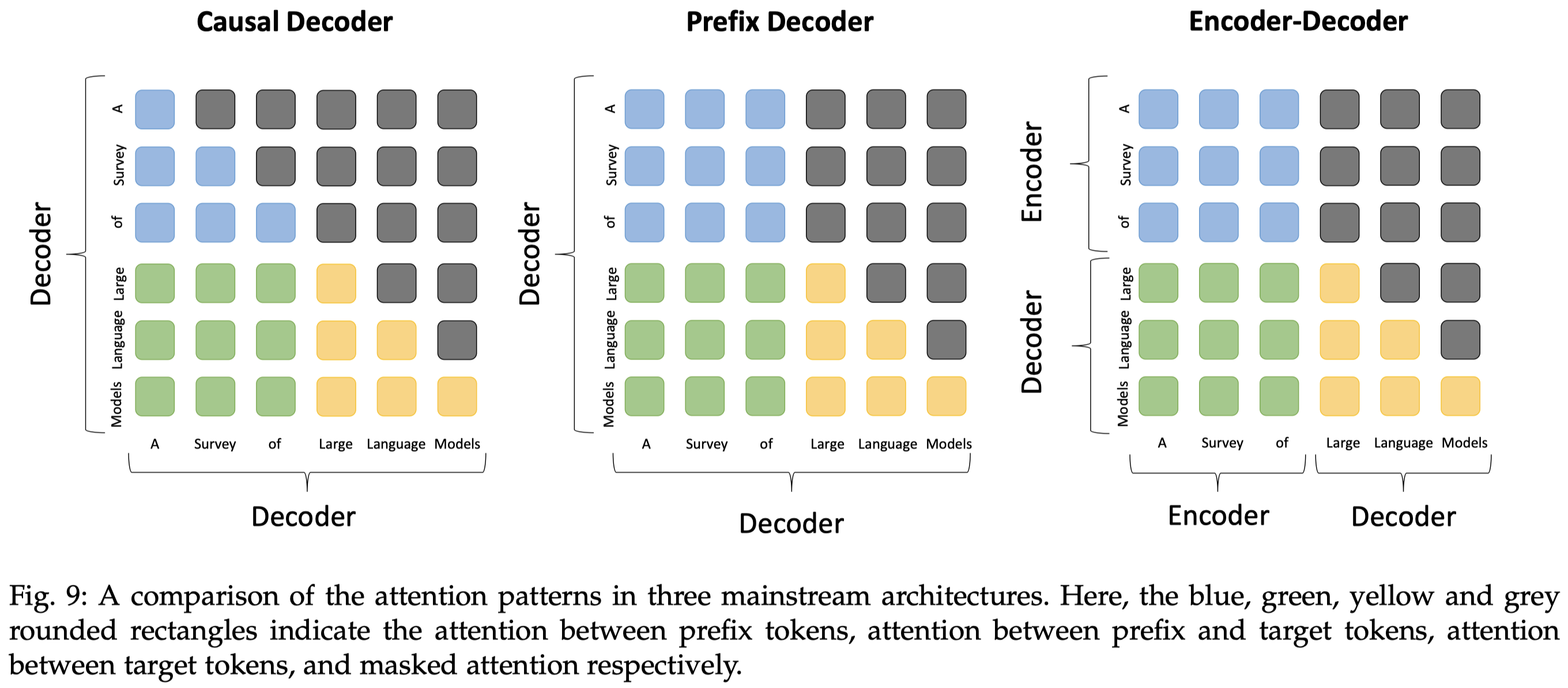
首先是基于Transformer的3种架构:
- Encoder-Decoder:原始的Transformer架构,双向mask的encoder+单向mask的decoder,在当前的LLM中用的比较少,比如Flan-T5
- Causal Decoder:单向mask的decoder,也是当前使用最多的架构,只能够看到前面的token,不断的预测下一个token
- Prefix Decoder:在给定的prefix tokens之间使用双向attention,对于要生成的tokens使用单向mask。常用的实践策略是在casual decoder基础上继续训练以加速收敛,得到prefix decoder,例如U-PaLM就是在PaLM基础上发展来的。
至于上面这3中架构到底各有什么优劣,现在没有定论,只不过大家现在主要都是follow OpenAI的casual decoder。不过现在有少数的研究发现,casual decoder似乎表现出了更好的zero-shot和few-shot能力。
然后是其它新兴的架构,主要目的是缓解Transformer的二次方计算效率问题:
- parameterized state space models:比如S4、GSS、H3
- long convolutions:比如Hyena
- Transformer-like architectures that incorporate recursive update mechanisms:比如RWKV,RetNet。一方面继续保持了Transformer便于并行训练的优点,一方面还不需要关注全部的序列,可以像RNN一样只关注前一个输入。
另外,LLM还常常结合Mixture-of-Experts,通过部分激活策略实现在保持计算效率的情况下增大模型参数。训练MoE常见的问题是不稳定。
5. Adaption Tuning of LLMs
作者主要介绍了instruction tuning、alignment tuning和efficient tuning。
5.1 Instruction Tuning
指令微调主要用来激发/加强LLM对于人类指令的执行能力(个人感觉像是LLM本身经过预训练后已经拥有了解决各种任务的能力,只不过还没有学会到底怎么样按照人类的指令去输出人类期望的结果。指令微调就是告诉LLM人类到底是期望各种task以什么样的结果输出的)。
指令微调就是一种有监督的训练,和多任务学习等都是相关的。
首先是怎么样构造带有指令的数据集。来源有三种:
- 现有的数据集(Formatting Existing Datasets):将已有的各种任务的数据集收集起来,加入人工的任务描述。PromptSource是一个可以为不同数据集构造合适的描述的众包平台。
- 基于人类输入构造的数据(Formatting Human Needs):现有的NLP数据集不能够全面的、准确的满足实际的人类需要。InstructGPT就将真实用户的查询作为instruction。GPT-4进一步人工构造危险的有毒的指令,让模型学会拒绝这样的指令。
- 自动构造的数据:类似于Self-instruct,一些半自动的方法被提出来以减小人类标注指令的负担。
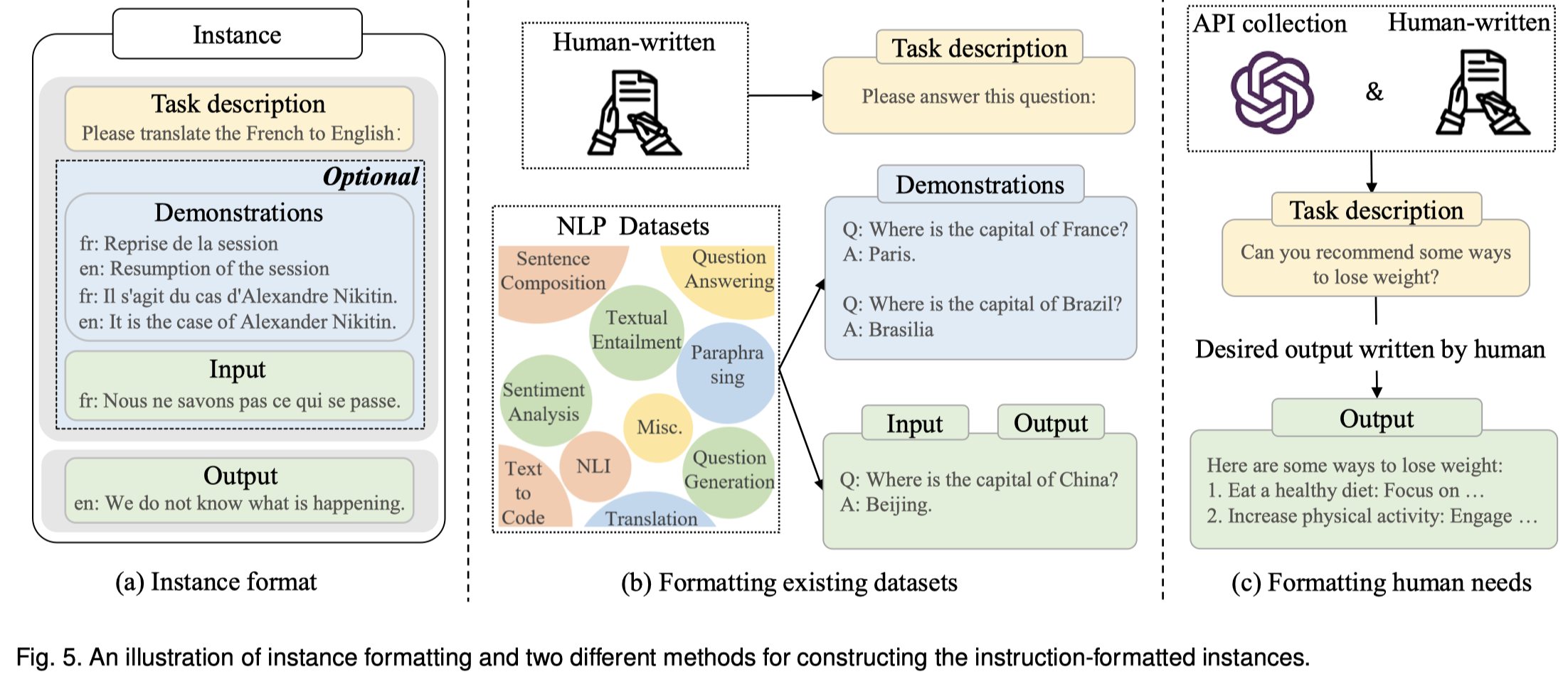
构造的指令数据集有以下几个关键因素
- task的数量。效果的提升在task数量增加到一定数量时会逐渐达到一个确定的层级。
- task descriptions的差异性(长度、结构、创新性等)。
- 每个task不需要有很多对应的instance,通常较少数量的instances就足够了。
- 具体输入到LLM的prompt格式,比如要不要加入推理步骤、要不要加入demonstrations等。
总体上来说,似乎指令的多样性要比数量更重要。
在训练的时候,由于指令数据集要远远小于预训练的语料,因此训练起来更快。除了一般的要关注的有监督训练的各种超参设置外,还有几个额外需要关注的策略:
- Balancing the Data Distribution.
- 直接混合不同task dataset的数据,然后随机选择;
- 增大高质量dataset数据的被采样的概率;
- 设置单个dataset最大采样的次数,避免过大的dataset过于影响instruction tuning效果;
- Combining Instruction Tuning and Pre-Training.
- 在instruction tuning加入pre-training的数据,让模型在指令微调过程中保持在预训练过程中学习到的能力和知识。OPT-IML incorporates pre-training data during instruction tuning, which can be regarded as regularization for model tuning.
- 使用多任务学习同时预训练和指令微调。some studies attempt to train a model from scratch with a mixture of pre-training data (i.e., plain texts) and instruction tuning data (i.e., formatted datasets) using multi-task learning.
- 将指令微调数据集直接作为预训练数据中的一部分。GLM-130B [83] and Galactica [35] integrate instruction-formatted datasets as a small proportion of the pre-training corpora to pre-train LLMs, which potentially achieves the advantages of pre-training and instruction tuning at the same time.
经过instruction tuning之后,模型一般会取得性能提升:
- the models of different scales can all benefit from instruction tuning [64, 217], yielding improved performance as the parameter scale increases [84].
- instruction tuning demonstrates consistent improvements in various model architectures, pre-training objectives, and model adaptation methods [64].
并且会获得更好的任务泛化性:
- A large number of studies have confirmed the effectiveness of instruction tuning to achieve superior performance on both seen and unseen tasks [85, 217].
- instruction tuning has been shown to be useful in alleviating several weaknesses of LLMs (e.g., repetitive generation or complementing the input without accomplishing a certain task) [61, 64].
- LLMs trained with instruction tuning can generalize to related tasks across languages.
5.2 Alignment Tuning
5.3 Efficient Tuning
6. Utilization
作者主要简单介绍了两种利用LLM进行下游任务的prompt方法:ICL(in-context learning)和CoT(chain-of-thought)。CoT可看做是ICL的拓展,在ICL的输入中加入了中间推理步骤。下图是ICL和CoT的示意:
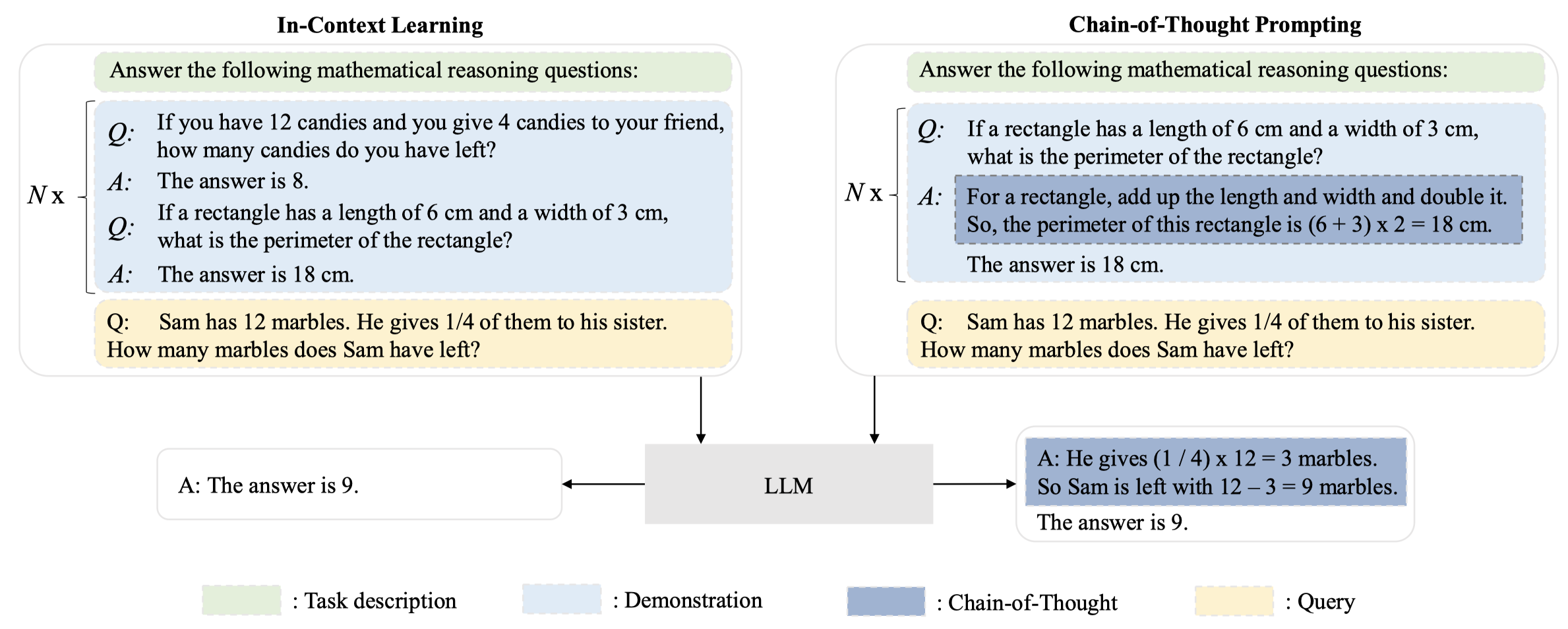
6.1 In-Context Learning
ICL的prompt主要有3部分:task description \(I\), demonstrations \(D_k = \{ f(x_1,y_1),\dots,f(x_k,y_k) \}\)和query \(x_{k+1}\):
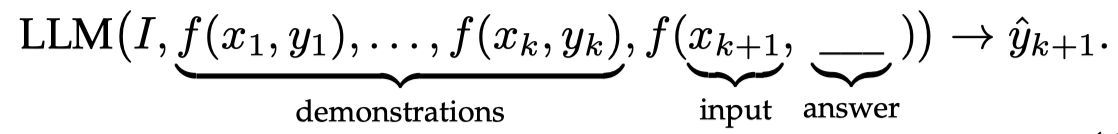
如果按照GPT-3中的定义,demonstrations不是必须的(尽管常常可以提升性能),只有任务描述的prompt也可以叫做ICL。
ICL和instruction tuning有很深的联系,只不过instruction tuning需要在有instruction的数据集上进行微调,而ICL只是改变LLM的输入。通过instruction tuning能够有效提升LLM的ICL能力。
在ICL中,怎么样选择合适的demonstrations是很关键的,有下面几种思路可以参考:
- Heuristic approaches. 有些研究通过利用k-NN算法选择和当前样本相似的demonstrations [Does GPT-3 generate empathetic dialogues? A novel in-context example selection method and automatic evaluation metric for empathetic dialogue generation. COLING 2022]。还有的研究进一步考虑了demonstrations内部的差异性[Complementary explanations for effective in-context learning. 2022]。
- LLM-based approaches. 还有的研究使用LLM来选择合适的demonstrations [Learning to retrieve prompts for in-context learning. NAACL 2022]。还有的研究直接使用LLM来生成对应的demonstrations,无需人工干预 [What can transformers learn in-context? A case study of simple function classes. 2022]。
另外,demonstration的顺序也可能是一个影响性能的因素。有研究发现LLM有时候会倾向于重复demonstrations最后一个例子的答案 [Calibrate before use: Improving few-shot performance of language models. ICML 2021]。
对ICL背后的原理,作者主要介绍了两个问题:
- How Pre-Training Affects ICL?
- 在预训练的时候,预训练任务可能会影响ICL。有研究者发现通过设计合适的预训练任务可以让SLM也获得ICL能力 [Metaicl: Learning to learn in context. NAACL 2022]。
- ICL还可能和预训练语料的来源有关 [On the effect of pretraining corpora on in-context learning by a largescale language model. NAACL 2022]。有研究者发现ICL出现在预训练语料聚类出现很多不频繁类的情况下 [Data distributional properties drive emergent in-context learning in transformers. 2022]。
- How LLMs Perform ICL?
- 部分研究者将ICL看做是隐式的梯度下降,将demonstrations在前馈过程中对应的计算看做是产生meta-gradient [Transformers learn in-context by gradient descent. 2022]。
- 还有的人将ICL抽象为算法学习过程。有研究发现LLM在预训练过程中实际上编码了隐式的模型 [What learning algorithm is in-context learning? investigations with linear models. 2022]。
6.2 Chain-of-Thought Prompting
研究者发现,如果能够利用多个不同的推理路径能够提升LLM推理能力 [On the advance of making language models better reasoners. 2022]。同时,如果涉及更加复杂的推理步骤,似乎能够进一步激发LLM的推理潜力 [Complexity-based prompting for multi-step reasoning. 2022]。
CoT的不同推理路径可能提供了不同的答案,self-consistency方法就是通过集成多个推理路径的答案取得更好的效果 [Self-consistency improves chain of thought reasoning in language models. 2022]。
另一个关键的CoT工作是AuToCoT [Automatic chain of thought prompting in large language models. 2022],它通过利用Zero-shot-CoT [Large language models are zero-shot reasoners. 2022]来自动选择合适的CoT。
对于CoT,作者也介绍了两个原理性问题:
- When CoT works for LLMs?
- CoT能力通常出现在模型参数量大于10B的情况下 [Chain of thought prompting elicits reasoning in large language models. 2022]。
- CoT通常是对于一般的ICL无法很好的完成的复杂推理任务能够起到提升作用。对于不需要复杂推理的任务,甚至可能会带来性能下降 [Rationale-augmented ensembles in language. 2022]。
- Why LLMs Can Perform CoT Reasoning?
- CoT能力的来源常常被广泛认为是在code data上进行了训练(尽管现在缺乏具体的实验验证这一点)。instruction tuning似乎对LLM的CoT能力没有提升。
- CoT中,patterns (equations in arithmetic reasoning)和text (the rest of tokens that are not symbols or patterns)是更加关键的要素,消融掉这两个部分都会导致性能的下降,甚至patterns是否正确都没有特别大的影响。
除去上面两点外,作者还简单提及了利用LLM的另一个思路模型定制(model specialization)[Specializing smaller language models towards multistep reasoning. 2023]。