LLM-reason-survey-zju
Reasoning with Language Model Prompting: A Survey
浙大zjunlp,paper仓库。回顾并总结了使用LLM进行推理的各种现有方法。
Reasoning, as an essential ability for complex problem-solving, can provide back-end support for various real-world applications, such as medical diagnosis, negotiation, etc. This paper provides a comprehensive survey of cutting-edge research on reasoning with language model prompting. We introduce research works with comparisons and summaries and provide systematic resources to help beginners. We also discuss the potential reasons for emerging such reasoning abilities and highlight future research directions.
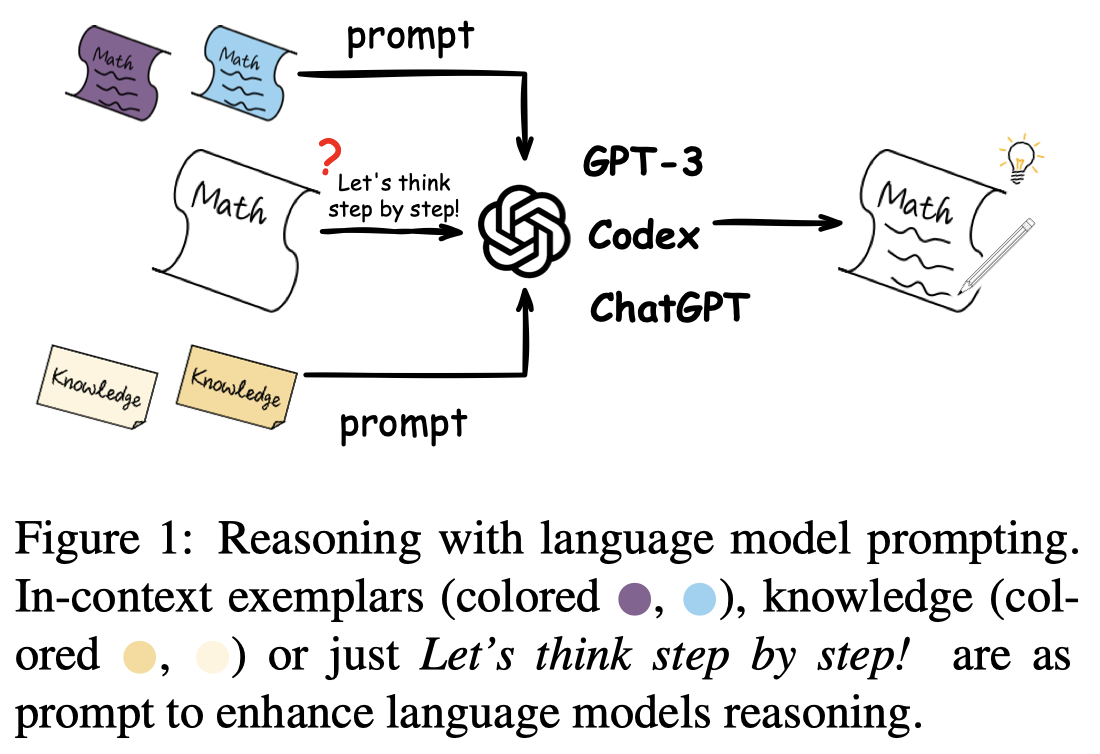
作者提出的分类如图:
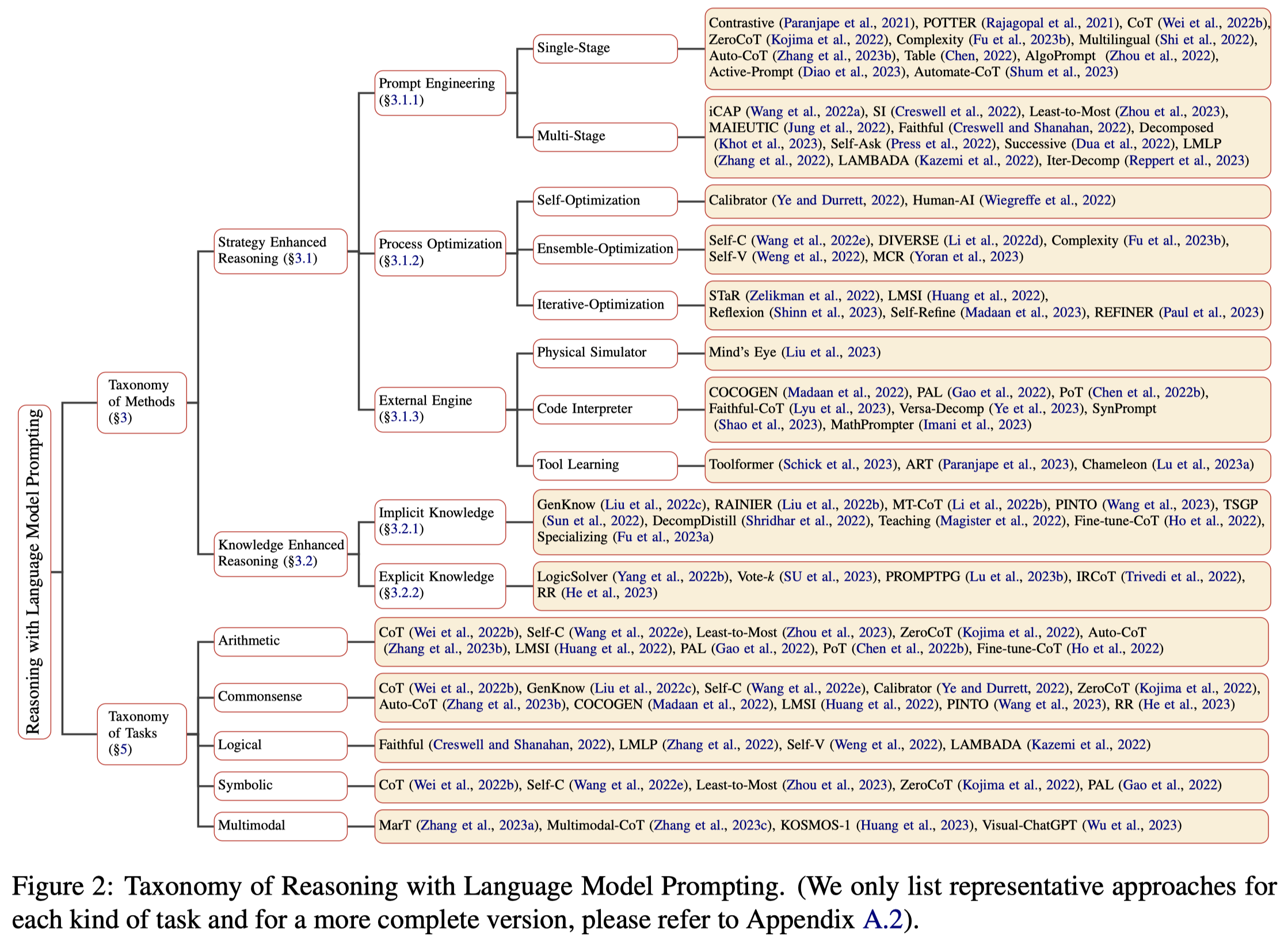
Taxonomy of Methods
作者主要划分为两个大类:
- Strategy Enhanced Reasoning
- Knowledge Enhanced Reasoning
Strategy Enhanced Reasoning
Prompt Engineering
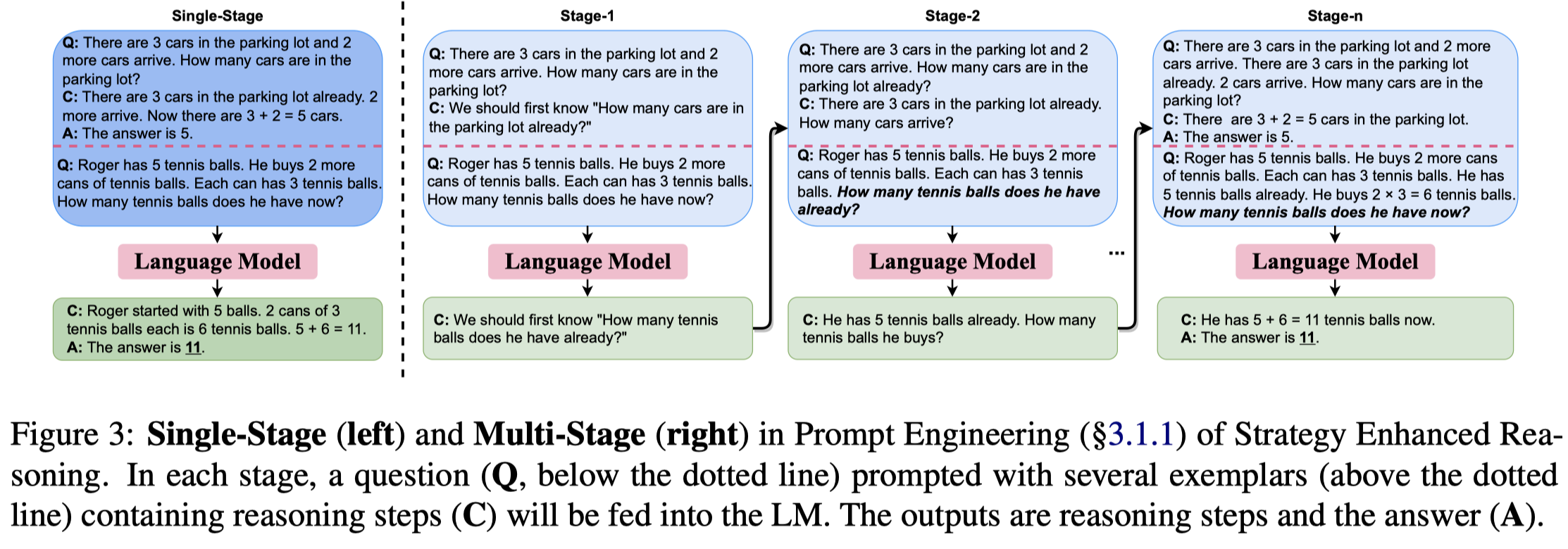
单步prompt早期的方法是基于模板,后来人们通过往ICL中加入更多的推理中间步骤(也就是CoT)来能够进一步的提升模型的推理能力。
后来的方法进一步把复杂的问题分解为几个步骤,进行multi-stage的prompting。
Process Optimization
prompt engineering仅仅是在修改输入,进一步的有工作探究怎么样优化推理步骤(叫做Natural language rationales,在有些paper中也叫做explanations)。作者简单介绍了三种过程优化方法:
- Self-Optimization:通过引入额外的module来矫正过程
- Ensemble-Optimization:集成多个不同的推理步骤的推理结果,获得更加鲁棒的推理能力
- Iterative-Optimization:迭代的重复推理过程,把推理答案加入到训练数据进一步fine tune模型

External Engine
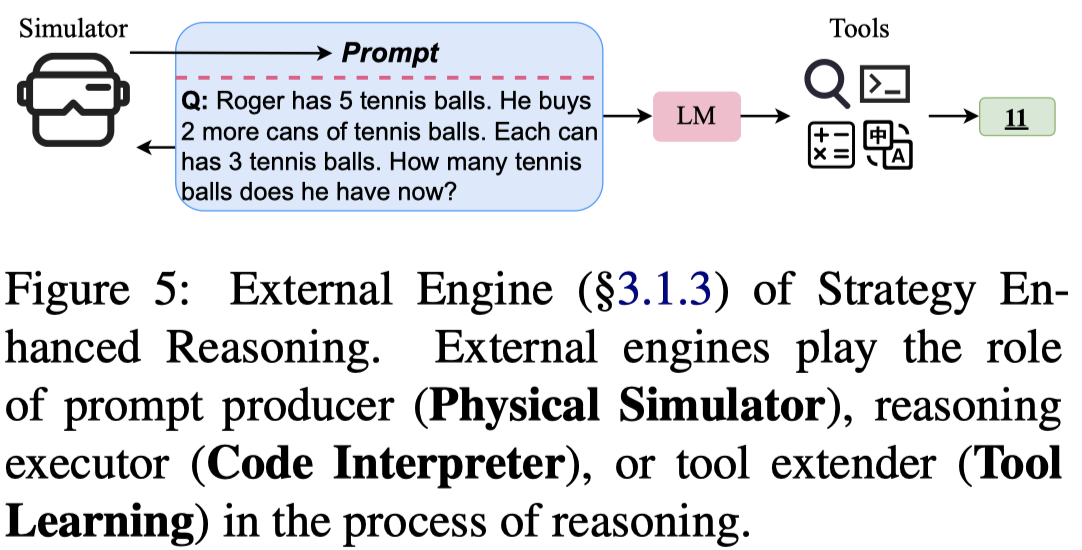
LLM模型本身的能力是有局限的,但是通过结合外部的推理引擎能够进一步提升LLM的推理能力。作者也同样简单介绍了三种:
- Physical Simulator:对物理过程的理解通过一个物理引擎进行模拟,然后再作为prompt输入到LLM
- Code Interpreter:将LLM和代码结合起来,利用程序语言更加鲁棒,能够更好的说明复杂结构和计算过程的优点
- Tool Learning:有些很简单的任务,LLM不一定能够超过非常简单的方法,因此有工作探究如何让LLM学习调用各种工具。
Knowledge Enhanced Reasoning
Implicit Knowledge
有研究发现LM内部学习到了隐式的知识(“modeledge”),因此一个自然的想法是使用这样的隐式知识来增强prompts。比如有人使用GPT-3生成知识和prompt来指导下游任务的LM。
Explicit Knowledge
LM generated knowledge缺点是不稳定与不可靠,因此有人考虑通过从已有的可信赖的外部资源(例如Wikipedia)去检索合适的知识来增强prompt。
Comparison and Discussion
Comparison of Language Models

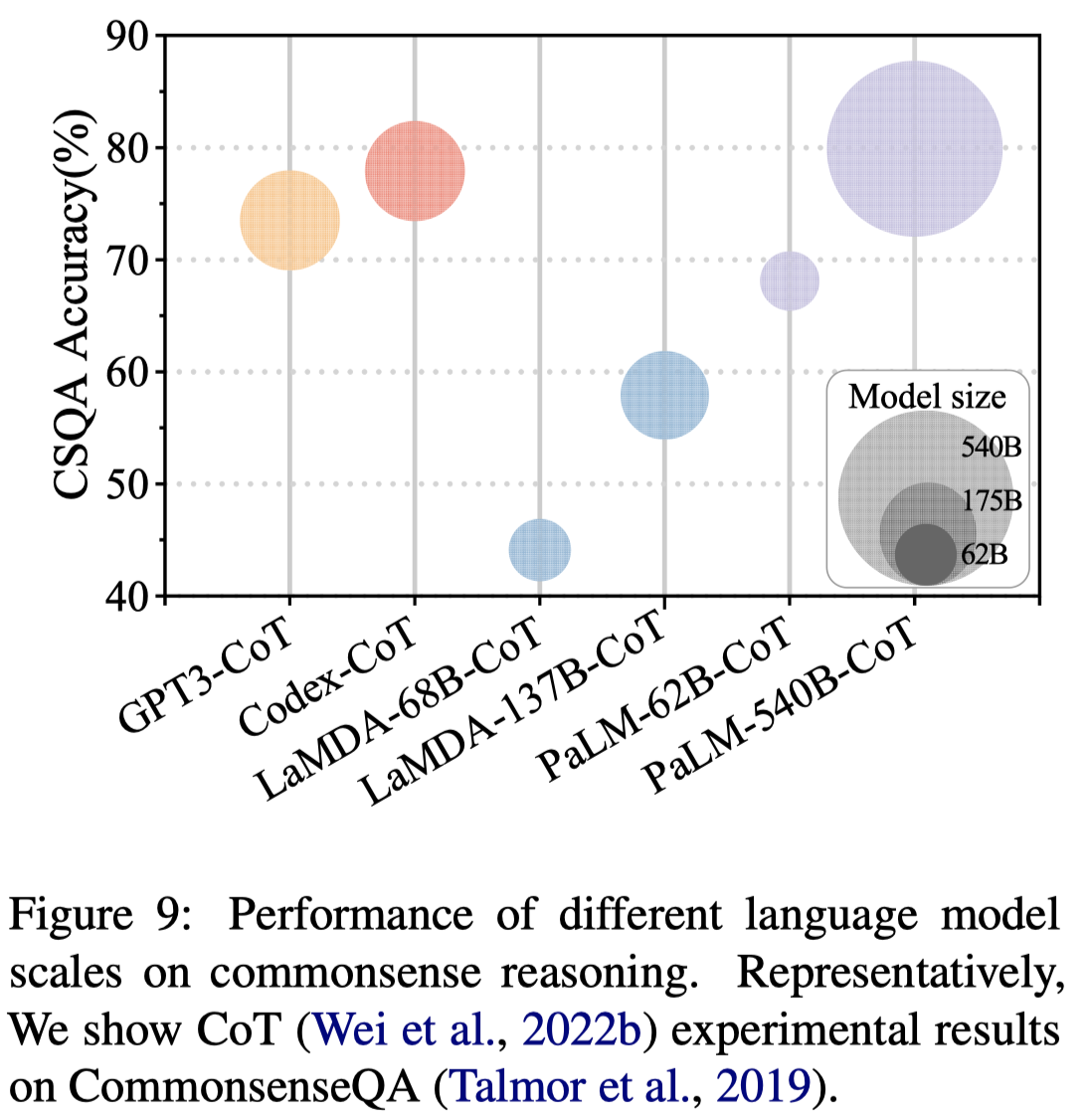
Codex加入CoT进行推理比单纯的GPT-3效果要好。CoT的出现表现在model size大于100B的时候,有研究发现,CoT和model size的关系之所以会表现出“涌现”,也可能是因为评估策略的问题,可能model size增大,CoT的中间步骤的效果是在逐渐变好的,只不过只有到了一定的大小,最终的答案才会变好。
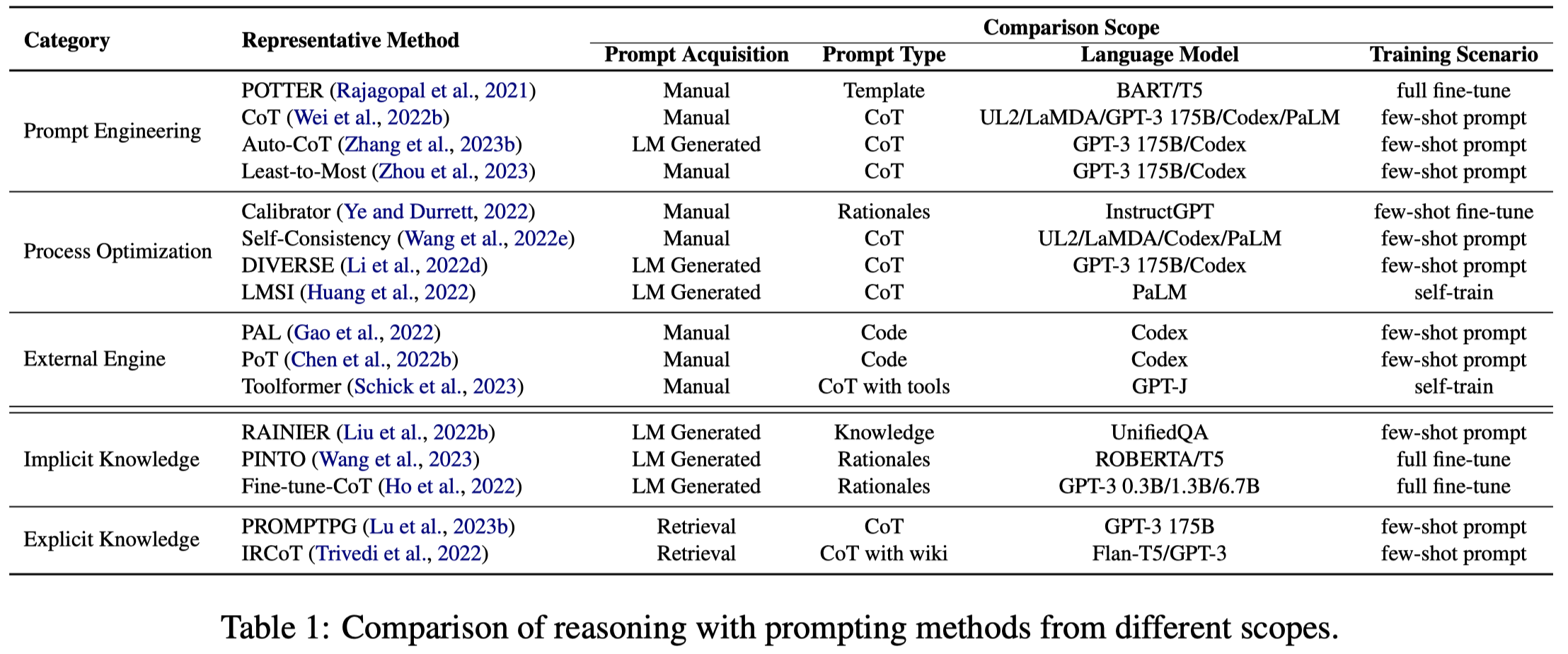
下图是不同构造prompt方法应用的总结:
Future Directions
Theoretical Principle of Reasoning:探究涌现能力、推理能力等出现的原因(decipher the dark matter of intelligence)
Efficient Reasoning:使用大模型本身就有很大的代价,如何减小使用大模型的代价。一个方向是研究更加通用的大模型;一个方向是把LLM的推理能力迁移到小模型上。
Robust, Faithful and Interpretable Reasoning:如何保证推理可靠
Multimodal (Interactive) Reasoning:使用不同模态的交互式的推理
Generalizable (True) Reasoning:对于LLM没有在训练过程中见过的任务进行推理