Head-to-Tail-Knowledgeable-LLM
Head-to-Tail: How Knowledgeable are Large Language Models (LLM)? A.K.A. Will LLMs Replace Knowledge Graphs?
Meta Reality Labs,arXiv 2023-08
Since the recent prosperity of Large Language Models (LLMs), there have been interleaved discussions regarding how to reduce hallucinations from LLM responses, how to increase the factuality of LLMs, and whether Knowledge Graphs (KGs), which store the world knowledge in a symbolic form, will be replaced with LLMs. In this paper, we try to answer these questions from a new angle: How knowledgeable are LLMs?
To answer this question, we constructed Headto-Tail, a benchmark that consists of 18K question-answer (QA) pairs regarding head, torso, and tail facts in terms of popularity. We designed an automated evaluation method and a set of metrics that closely approximate the knowledge an LLM confidently internalizes. Through a comprehensive evaluation of 14 publicly available LLMs, we show that existing LLMs are still far from being perfect in terms of their grasp of factual knowledge, especially for facts of torso-to-tail entities.
这篇工作是探究LLM在记忆knowledge问题上的又一篇工作。与前面的PopQA数据集有点类似,都是分析entity-related knowledge随着entity popularity变化的趋势。这篇工作分析了更多的开源LLM和不同领域下不同popularity的knowledge的回答准确性。
The Head-to-Tail Benchmark
QA pair generation
先来看作者的benchmark是如何构造的。
作者的数据源来自下面四个方面:
- Open domain: DBpedia knowledge graph,English snapshot from December 1, 2022
- Movie domain: IMDb from May 21, 2023
- Book domain: Goodreads scraped in 2017
- Academics domain: MAG from September 13, 2021 and DBLP from May 10, 2023
然后是如何定义popularity。作者从traffic和density两个维度评估popularity。如果有traffic信息,比如votes次数/浏览次数等,就使用traffic作为popularity;如果没有traffic相关信息,就使用density信息,比如一个entity有多少相关事实/工作。具体来说各个数据集的评估依据如下:
- IMDb (traffic): The number of votes (i.e., numVotes)
- Goodreads (traffic): The count of ratings (i.e., ratings_count)
- MAG (traffic): The number of citations (i.e., CitationCount)
- DBLP (density): The number of works the scholar has authored.
- DBpedia (density): The number of relational triples in DBPedia that contain the entity.
接下来,作者按照流行程度把不同的knowledge划分为3个部分:head、torso和tail。注意这里的head/tail不要和一般KG三元组描述常用的head/tail混淆。这篇paper中的head/tail只是表示流行程度。
具体的实体划分方法:计算top-1流行实体的累积popularity score,然后popularity score能够达到这个最大得分1/3的实体作为head实体,以此类推划分出torso entity和tail entity。
这种划分方法同样可以用在划分三元组的predicates上。作者将DBpedia中包括了对应predicate的三元组数量看做是predicate的popularity,然后按照相同的流程进行划分。
然后作者为了避免最新的knowledge对于LLM的影响,只截取了比较靠前年份的知识:
For IMDb, MAG, DBLP, and Goodreads, we kept only entities by the years 2020, 2020, 2020, and 2015, respectively.
这样保证了保留的knowledge都在LLM预训练数据的涉及时间范围之内。
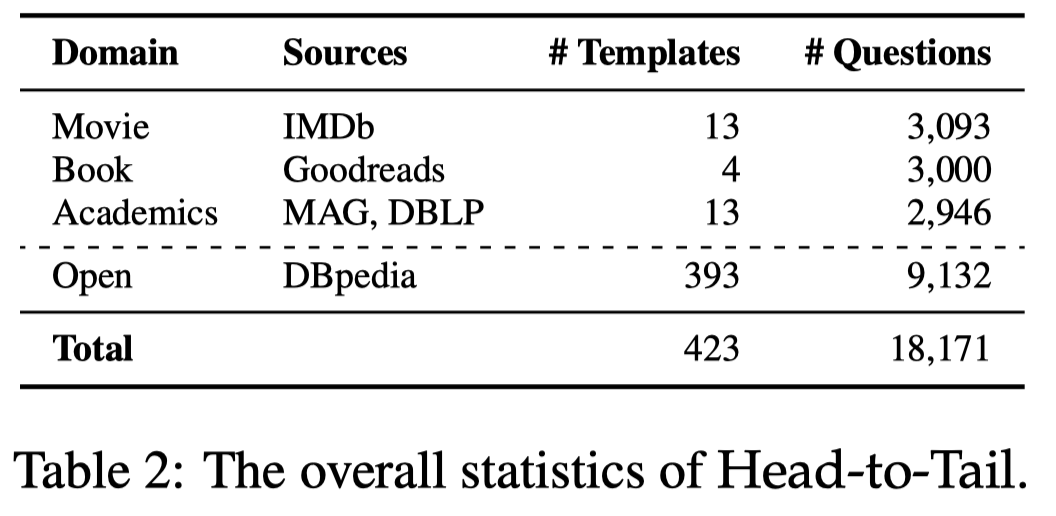
下面的表格是作者构造的各类entity分布:

可以看到大部分的entity都是在tail分组中。
然后为了能够prompt LLM去回答相应的knowledge,需要构造prompt模板。For each specific domain (Movie, Book, Academics), we manually designed the question template for each attribute. DBpedia contains a large set of attributes, so we first employed ChatGPT to draft the templates (using Prompt 1 in Appendix A.1), then proofread them manually and made necessary edits.
让ChatGPT去生成prompt template的方法:

用entity去填充prompt模板就能够得到相应的问题,作者最后构造出来的数据集question的分布如下:
最终,作者构造的整个数据集都是形式简单的关于事实的问题。无法探究LLM的理解能力、推理能力等。
Metrics
使用什么指标?作者定义了3类指标:
accuracy (A), hallucination rate (H), and missing rate (M), measuring the percentage of questions that an LLM gives the correct answer, gives a wrong or partially incorrect answer, or admits it cannot answer, respectively; by definition, A + H + M = 100%.
这里出现了一个missing rate指标,是因为作者允许LLM回答不知道/不确定。
如何计算指标?
LLM-Based. \(A_{LM}\), \(H_{LM}\)判断回答的答案到底是否正确,由于缩写等原因,通过完全匹配的评价方式不一定合适。因此作者给定ground truth和prediction,让LLM判断这两个是否一致。根据LLM的判断结果来计算指标。作者发现,这种方法,98%的情况下LLM的判断是可靠的。下面是作者用LLM判断结果是否和正确答案匹配的prompt:

Rule-Based. 就是最常见的直接计算指标,作者用了3种具体指标,exact match (EM) \(A_{EM}\), token F1 (F1) \(A_{F1}\), and ROUGE-L (RL) \(A_{RL}\)。
作者发现上面两种计算指标方法的评估结果在很大程度上是一致的。
Evaluation methodology
作者使用few-shot in-context learning去查询LLM。下面是具体:

few-shot的设置应该是搞了两个固定的不在数据集中的example,一个回答正确的答案;一个回答不确定。让LLM学会follow。
上面的prompt有两点可以借鉴:
- 让LLM的回复进行可能简洁,能够降低不确定性
- 让LLM回复不知道/不确定,能够减小LLM捏造事实的概率
Experimental Analysis
RQ1: How reliable are LLMs in answering factual questions?
下面是部分的LLM回答准确率,全部统计可以参考paper的附录A.3:
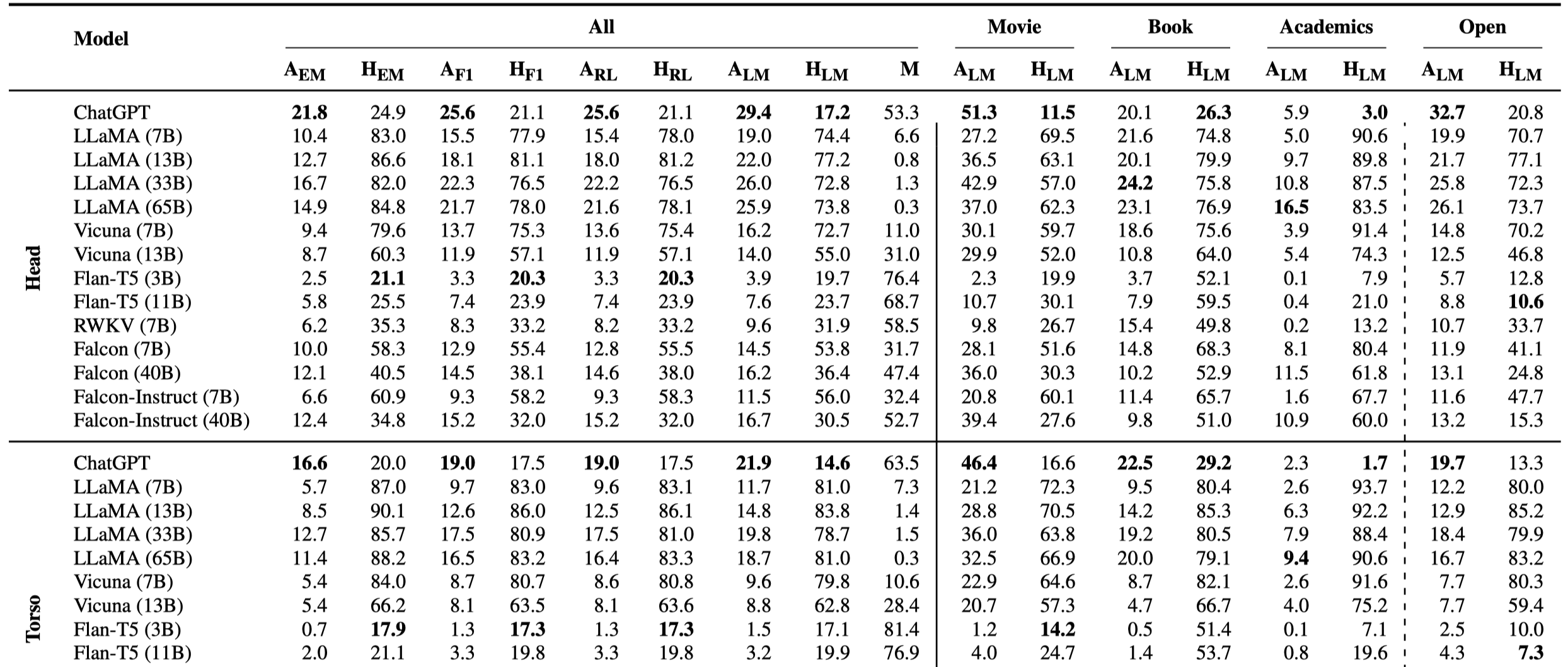
下面是ChatGPT和开源LLM表现相对最好的LLaMA 33B的对比:

有下面的观察:
- 对于GPT-3.5和各类开源LLM,表现最好的GPT-3.5总体上只有20%左右的问题能够被准确回答
- LLaMA的幻觉率\(H_{LM}\)很高,这表明LLaMA更喜欢强硬的给出答案,即使是错误的答案,也不愿意承认自己不知道/不会。ChatGPT就好很多,更加习惯承认自己不知道。这可能是因为ChatGPT的人类对齐/指令微调过程的效果。经过了指令微调Vicuna会比原始的LLaMA更愿意承认自己不知道,但是回答准确性同样下降了
- LLaMA和ChatGPT在open domain(DBpedia knowledge)的回答准确率比较接近,在不同领域下的回答效果不同。在不太常见的领域如Academics的回答准确率只有个位数
RQ2: Do LLMs perform equally well on head, torso, and tail facts?
下面是不同popularity entity的实验结果:
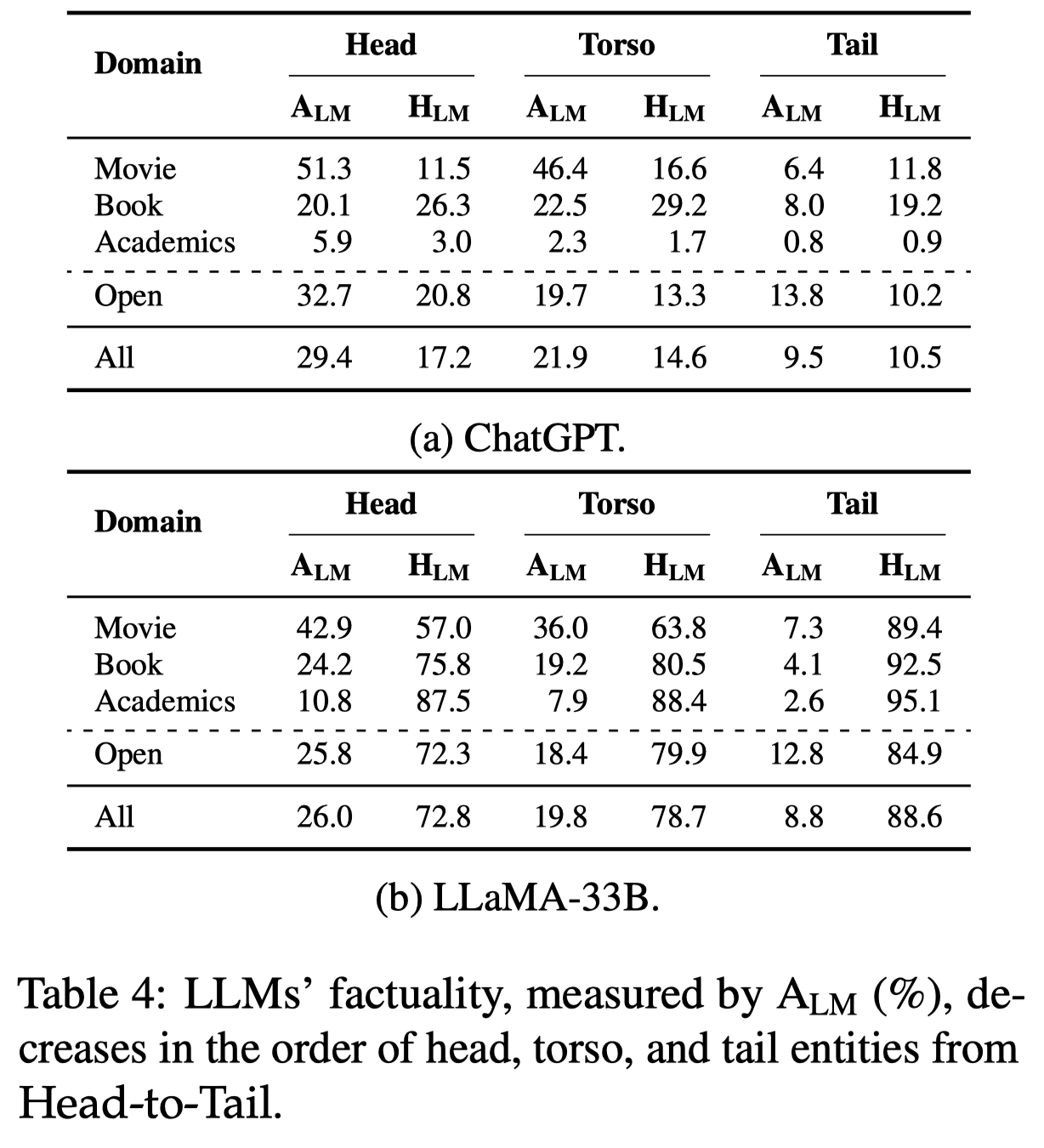
有以下的观察:
- 很明显的,随着popularity的降低,回答准确率也降低了
- 在head entity里,能够被正确回答的比例即使是GPT-3.5也只有30%左右,在比较不常见的domain里可能回答的准确率只有不到10%。而即使是在popular domain里的popular entity回答准确性也就在50%左右(如Movie domain的head entity)。不过,一个好的迹象是,ChatGPT出现幻觉hallucination的比例并没有随着popularity降低而提升。说明ChatGPT还是比较清楚自己不知道什么知识的
下面的实验结果是针对不同popularity的predicates:
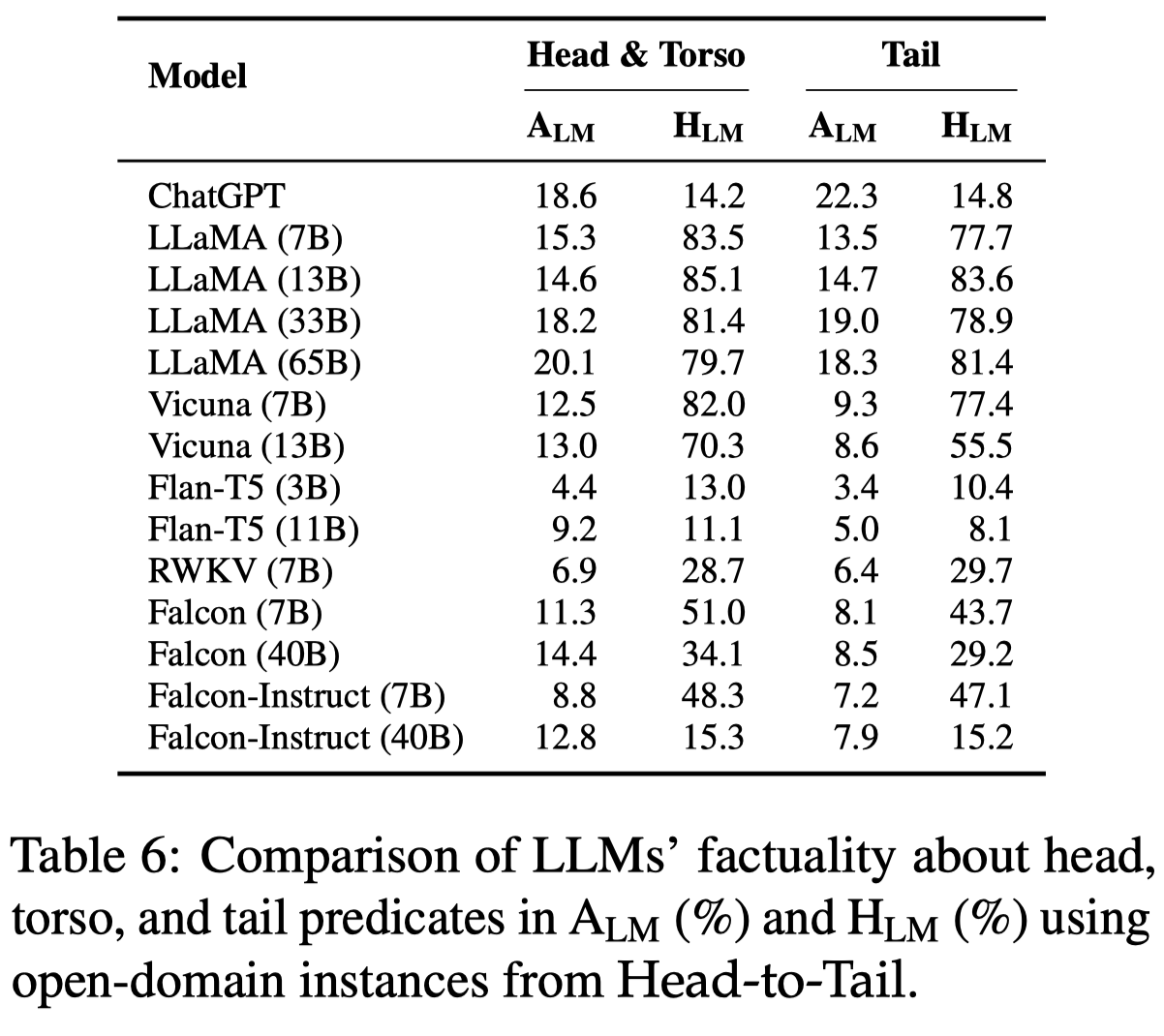
有如下的观察:
- 对于predicates的预测没有明显的随着popularity变化的趋势
- 不同LLM对于predicates的回答准确率没有特别显著的差别
RQ3: Does normal methods that improve LLMs increase the factuality?
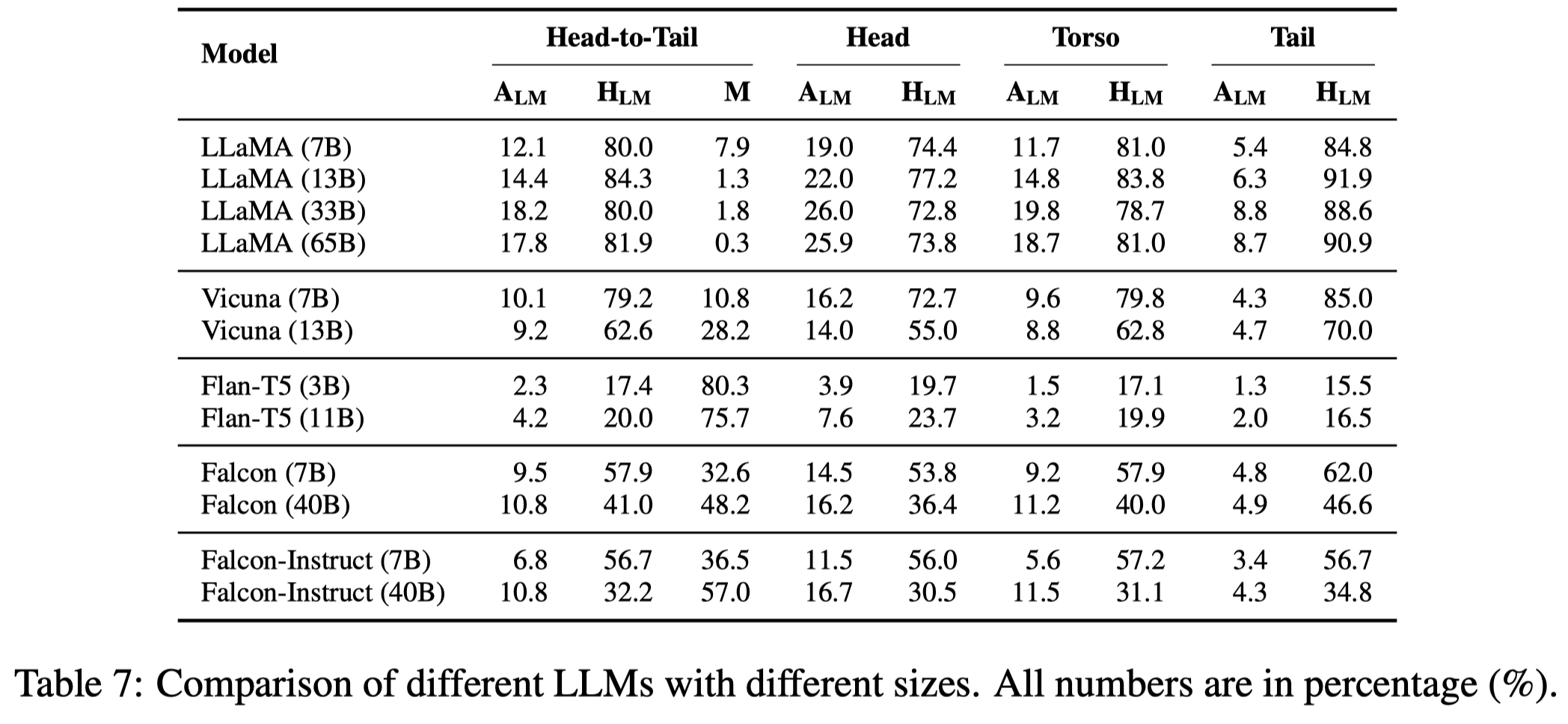
有下面的观察:
- 增大model参数量可以在一定程度上增加记忆效果,但在参数量到达一定程度时,继续增加参数量不一定总是能够带来更好的记忆效果,比如LLaMA-65B没有比LLaMA-33B表现更好
- 经过了指令微调的LLM回答更加保守,因此幻觉率会下降,同时回答的准确率也下降了
Robustness of our evaluation methodology
首先是LLM-based和rule-based的metric计算方法的对比:
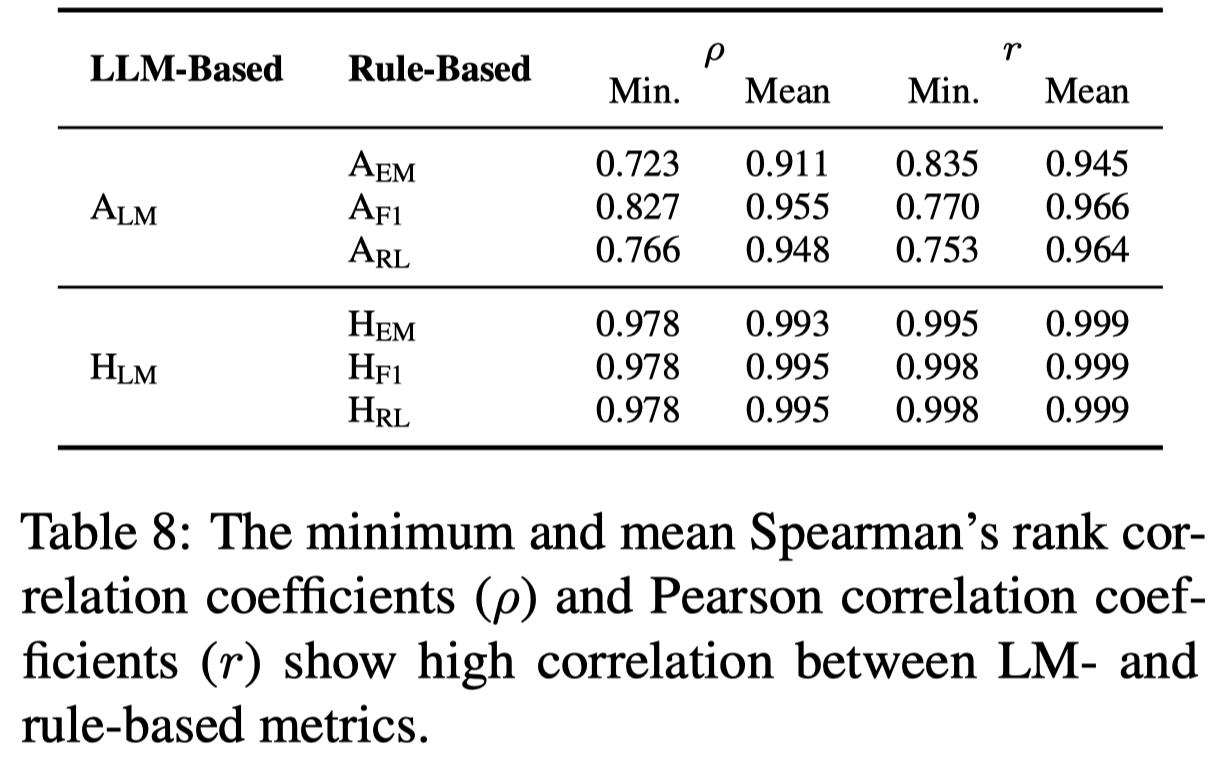
能够看出两种计算方法的相关性是很强的,rule-based metrics are good alternatives for lower-cost or faster evaluation。
然后是作者设计的prompt的robustness。作者让LLM对相同的问题重复产生答案,发现
- 如果不要求回答尽可能的简洁,18%的问题会有新答案
- 如果不允许LLM回答unsure,幻觉率会增大13%
这说明prompt LLM去尽可能回答简单的回复可能能够减小LLM重复回答的不确定性。 prompt LLM去回答不知道/不确定,能够有效的减低答案里存在hallucination。 在两个措施都使用的情况下,ChatGPT只对1%的问题重复回答有不同的结果。
The future of knowledge graphs
尽管LLM不能够准确的回答很多事实问题,但是它已经改革了人们寻找信息的方式。因此有必要仔细考虑knowledge的表示/表达/存储方法。显式表示知识的三元组形式(KG)和隐式表示知识的参数化形式(LLM)应该可以协作。
The symbolic form caters to human understanding and explainability
The neural form benefits machine comprehension and seamless conversations
同一knowledge可能同时在两者中都存在,但是哪一种形式是最合理的,可能没有最优解,依赖于任务场景/需求(个人见解)。
作者指出两个研究方向的必要性:
- 尽管popular entity/knowledge的预训练数据应该比较充分,但是LLM仍然不能够很好的记忆。有必要考虑如何提升LLM对于knowledge的记忆能力。比如knowledge infusion技术[A survey on knowledge-enhanced pre-trained language models]。
- 对于less popular的knowledge,可能用triple这种形式化的方法储存比较合理。然后把这种形式化的知识想办法增强LLM的回答。比如knowledge-augmented LLMs [Retrieval-based language models and applications]。