GenRead
Generate rather than Retrieve: Large Language Models are Strong Context Generators
University of Notre Dame和Microsoft,ICLR 2023,代码。
Knowledge-intensive tasks, such as open-domain question answering (QA), require access to a large amount of world or domain knowledge. A common approach for knowledge-intensive tasks is to employ a retrieve-then-read pipeline that first retrieves a handful of relevant contextual documents from an external corpus such as Wikipedia and then predicts an answer conditioned on the retrieved documents. In this paper, we present a novel perspective for solving knowledge-intensive tasks by replacing document retrievers with large language model generators. We call our method generate-then-read (GenRead), which first prompts a large language model to generate contextual documents based on a given question, and then reads the generated documents to produce the final answer. Furthermore, we propose a novel clustering-based prompting method that selects distinct prompts, in order to generate diverse documents that cover different perspectives, leading to better recall over acceptable answers. We conduct extensive experiments on three different knowledge-intensive tasks, including open-domain QA, fact checking, and dialogue system. Notably, GenRead achieves 71.6 and 54.4 exact match scores on TriviaQA and WebQ, significantly outperforming the state-of-the-art retrieve-thenread pipeline DPR-FiD by +4.0 and +3.9, without retrieving any documents from any external knowledge source. Lastly, we demonstrate the model performance can be further improved by combining retrieval and generation. Our code and generated documents can be found at https://github.com/wyu97/GenRead.
作者提出了使用LLM生成的question的documents,作为question的background来回答问题,generate-then-read。
Introduction
knowledge-intensive tasks如开放域QA任务等,常常需要大量的word knowledge / domain knowledge。之前的常常通过检索外部知识源Wikipedia等来获得relevant contextual documents。
retrieve-then-read来解决knowledge-intensive tasks存在的问题:
- First, candidate documents for retrieval are chunked (e.g., 100 words) and fixed, so the retrieved documents might contain noisy information that is irrelevant to the question.
- Second, the representations of questions and documents are typically obtained independently in modern two-tower dense retrieval models (Karpukhin et al., 2020), leading to only shallow interactions captured between them (Khattab et al., 2021).
- Third, document retrieval over a large corpus requires the retriever model to first encode all candidate documents and store representations for each document.
而作者认为,LLM生成的document比传统的检索结果更加和query question更加相关,原因是:LLM的生成结果是通过基于question的token,然后经过attention等机制生成的,而一般的检索只是利用question和document的embedding相似度去检索的。显然LLM的生成结果会和question更加相关。
We believe this is because large language models generate contextual documents by performing deep token-level cross-attention between all the question and document contents, resulting in generated documents that are more specific to the question than retrieved documents.
在检索方法中,检索的答案越多,能够提供更多的不同角度/方面的knowledge,从而增加最后回答答案的准确率。
但是如果是相同的prompt,LLM会倾向不断输出重复的内容。因此作者提出从不同的聚类中选择上下文样例,从而产生更多样的输出documents。
Method
作者尝试了两种不同的设置,一种是zero-shot setting,也就是一直使用LLM来回答问题。另一种是supervised setting,用LLM来生成documents,因为目前有监督的方法效果还是更好,并且效率更高。
有一种生成不同结果的思路是直接修改解码策略。但如果保持input一样,即使是修改解码策略,也很难生成covering different perspectives的documents,虽然内容可能改变,但是表达的knowledge总是倾向于重复。更多样documents,更大的相关信息召回率。
因此作者提出clustering-based prompt方法,提取不同的上下文样例,构造不同的prompt,生成的多个结果文档,一起再来辅助回答问题。核心包括3步:
- 初始化:先用LLM给训练集中的每个question生成一个document。也可以使用检索的方法,为每个question从外部知识源中检索一个相关document;
- 编码document,基于K-means无监督聚类:作者使用GPT-3这类LLM为每个question-document进行编码,然后进行K-means聚类。聚类的数量K,和要生成的documents数量一致
- 采样并且生成K个documents:对每一个聚类,采样n个样例作为上下文,然后生成query question的一个document,最终生成的K个documents。这些documents作为background,和query question组合成一个prompt,获得最终的答案。

除去基于聚类的prompt方法,作者还尝试了让人工写不同的prompt。人类写的prompt效果不错,但是有两个问题: 1. 人工写的prompt,难以泛化到不同的task上 2. 人工写的prompt对于不同LLM来说不一定还是好的prompt
Experiments
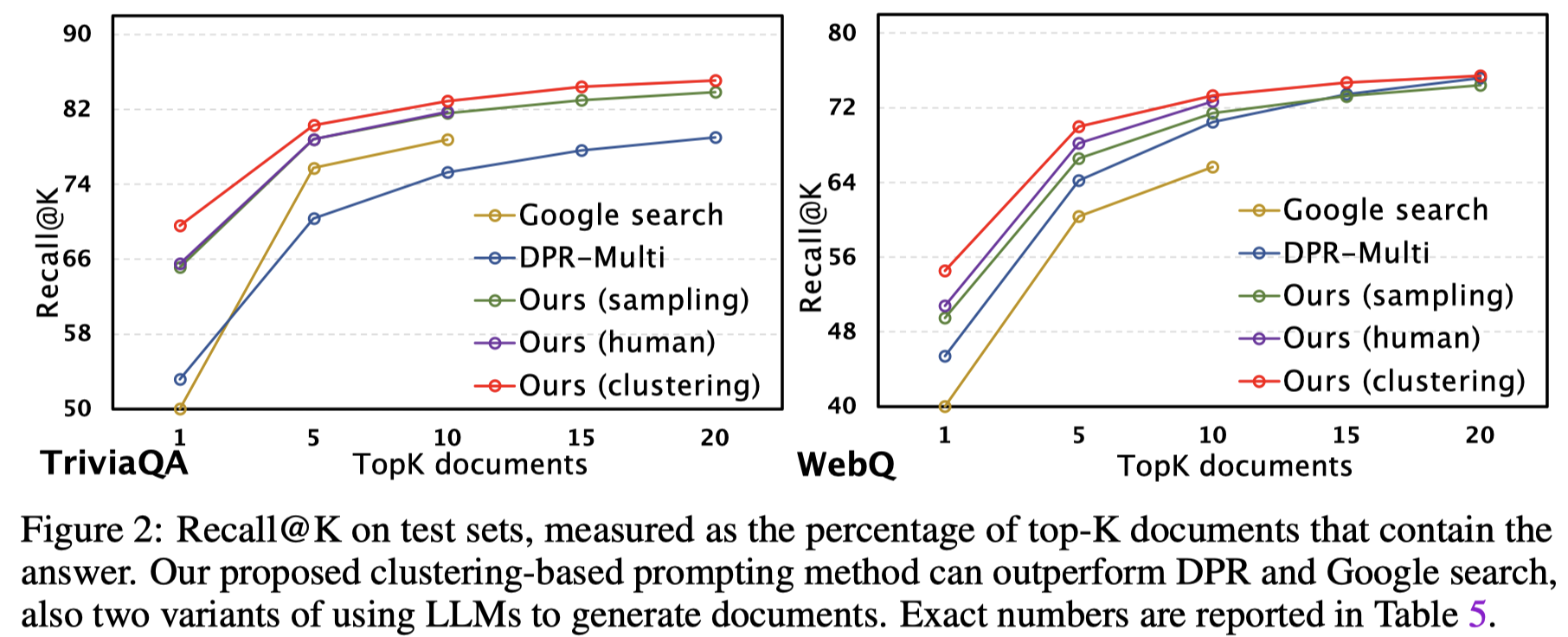
总体实验结果:
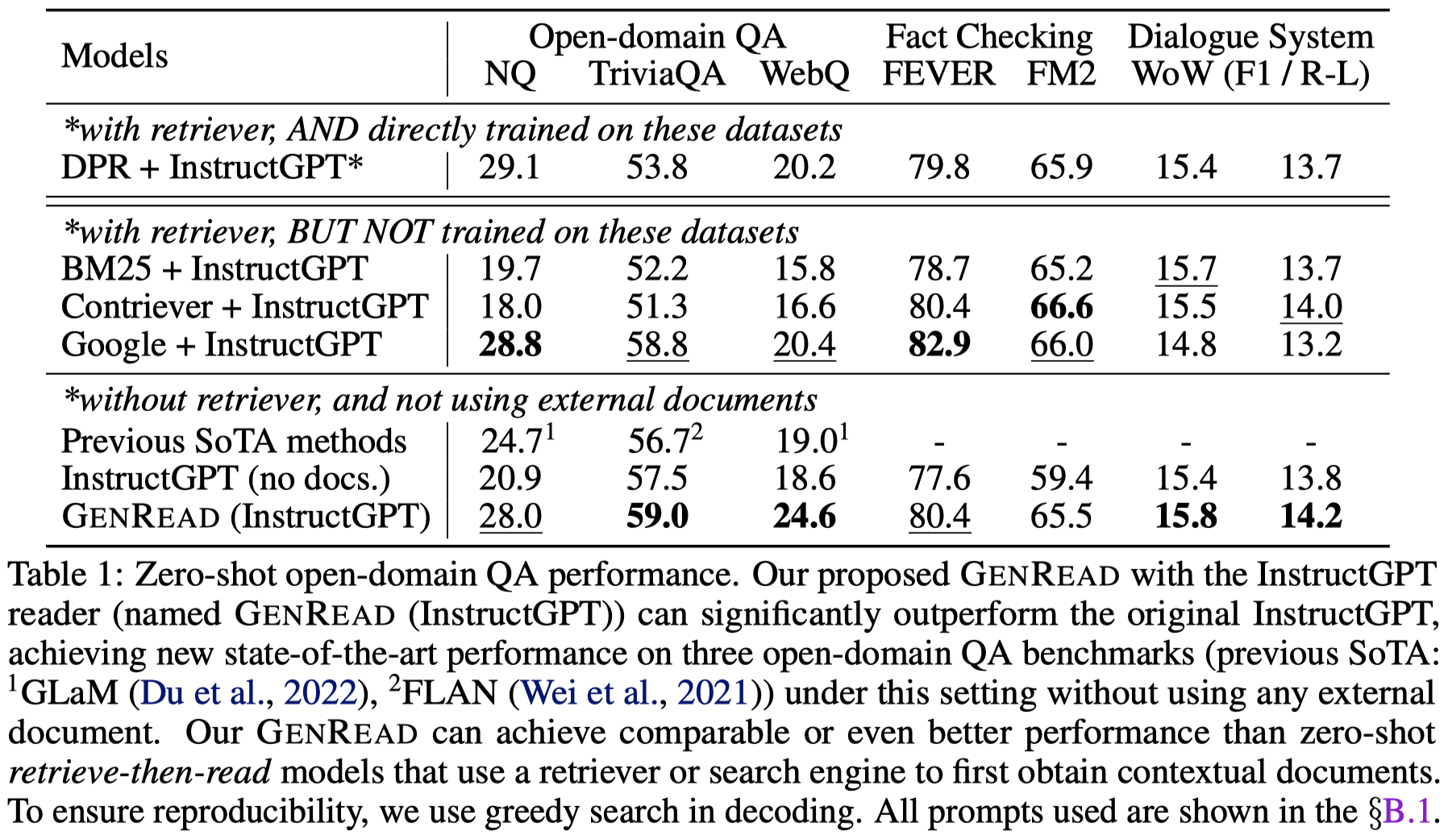
作者还尝试把检索的文档和生成的文档结合起来,发现效果进一步提升。简单的说就是用生成的文档替换一部分检索的文档,作为回答question的背景知识: