GPT-4
GPT-4 Technical Report
2023-03-14日OpenAI发布的多模态GPT-4,下面是关于它技术报告的一个总结。大多是简单的high-level的描述和输入输出cases,具体模型细节、部署架构等等都没有说。
We report the development of GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs. While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers. GPT-4 is a Transformerbased model pre-trained to predict the next token in a document. The post-training alignment process results in improved performance on measures of factuality and adherence to desired behavior. A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4’s performance based on models trained with no more than 1/1,000th the compute of GPT-4.
1. Introduction
GPT-4是一个能够输入text和image输出text的大模型。GPT-4在很多测试上取得了很好的效果,比如在simulated bar exam(模拟律师资格考试)中超越了90%的人类测试者。
下面是它的一些新特点和技术介绍。
2. Predictable Scaling
Openai开发出了一套能够提前预测不同规模下模型性能的方法,这使得他们能够在使用1000倍到10000倍更少的计算资源的情况下提前预测模型的效果。
(可惜没有提到到底是如何用小模型预测大模型性能的,不过这个肯定是非常重要的大模型将来发展方向)
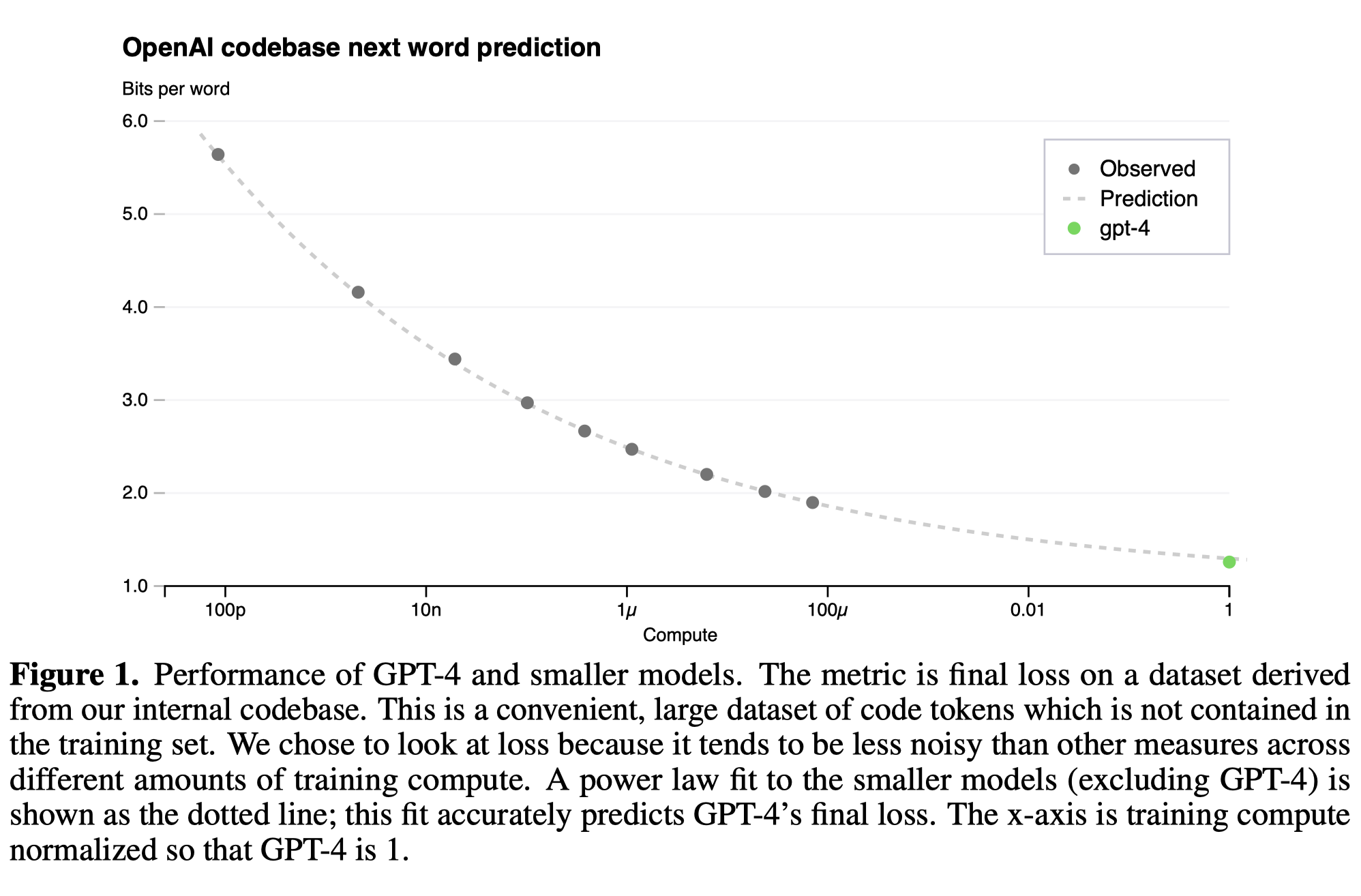
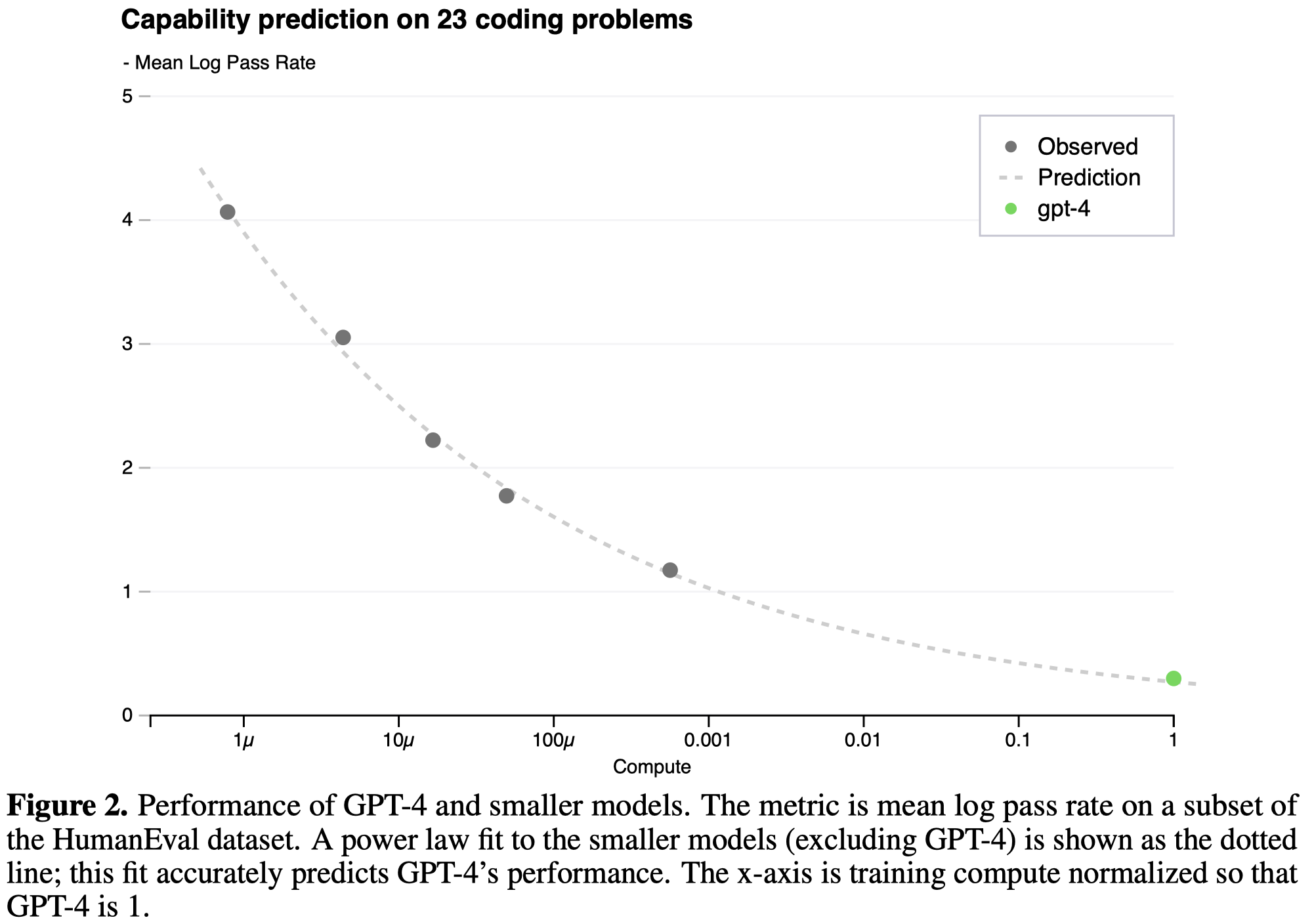
从上面两个图可以看到,对于GPT-4在不同scale下的性能表现,还是预测的很准的。
另外GPT-4表现出来的比较好的一点是,之前研究者发现在某些任务下随着规模增大,大模型的效果反而可能下降。但是GPT-4奇怪的逆反了这一趋势:
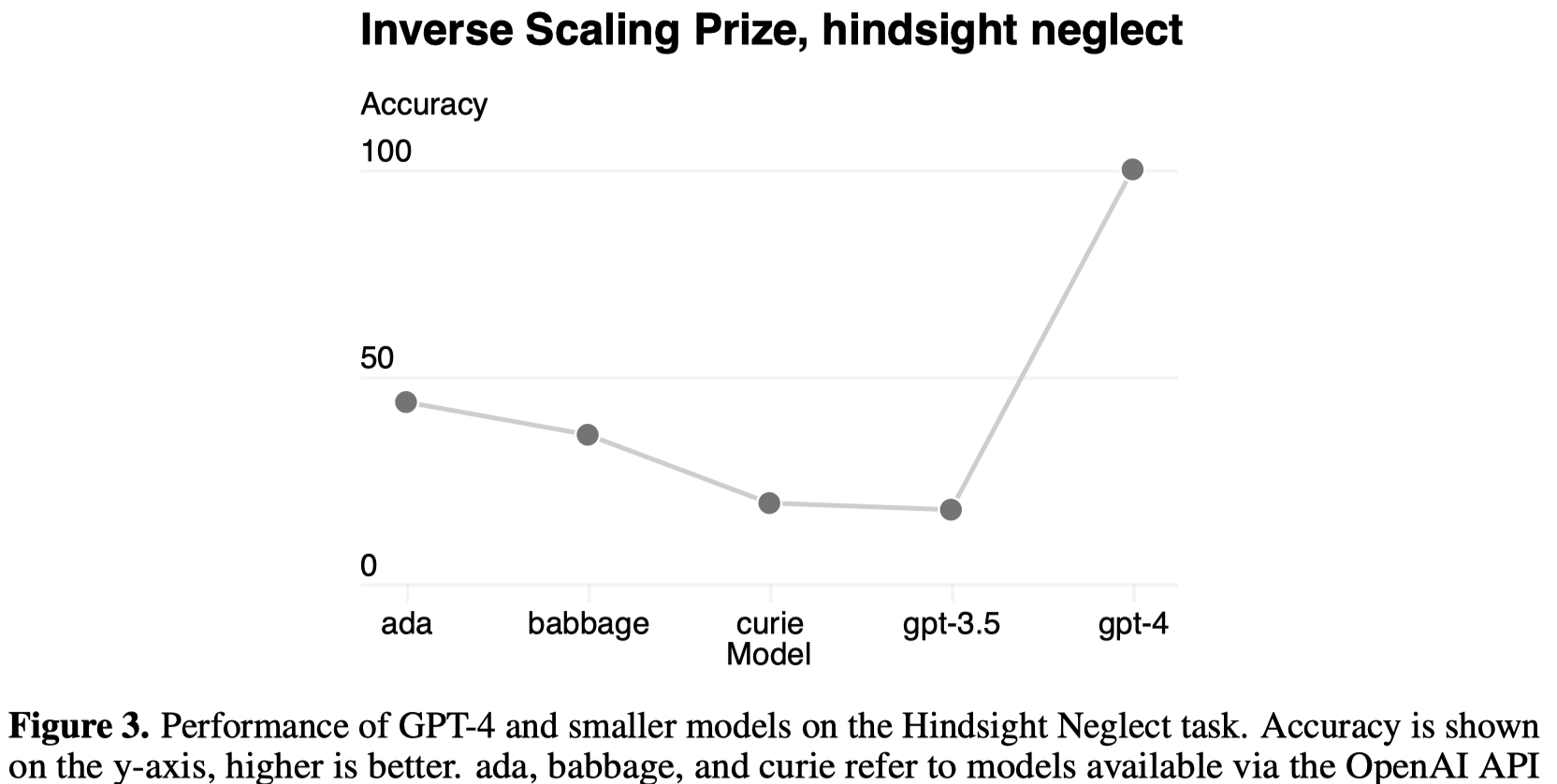
3. Capabilities
接下来是对于GPT-4各种任务表现的说明。OpenAI试验了两个测试版本,一个是在训练集中移除了可能覆盖的测试集内容,然后进行训练;一个是使用完全的原始版本的训练集。最后在两个版本中选择最低的值进行report。下图中小括号里是指超过了多少的人类测试者。部分小括号里是区间因为这些测试是划分等级的,同一分数的人很多。
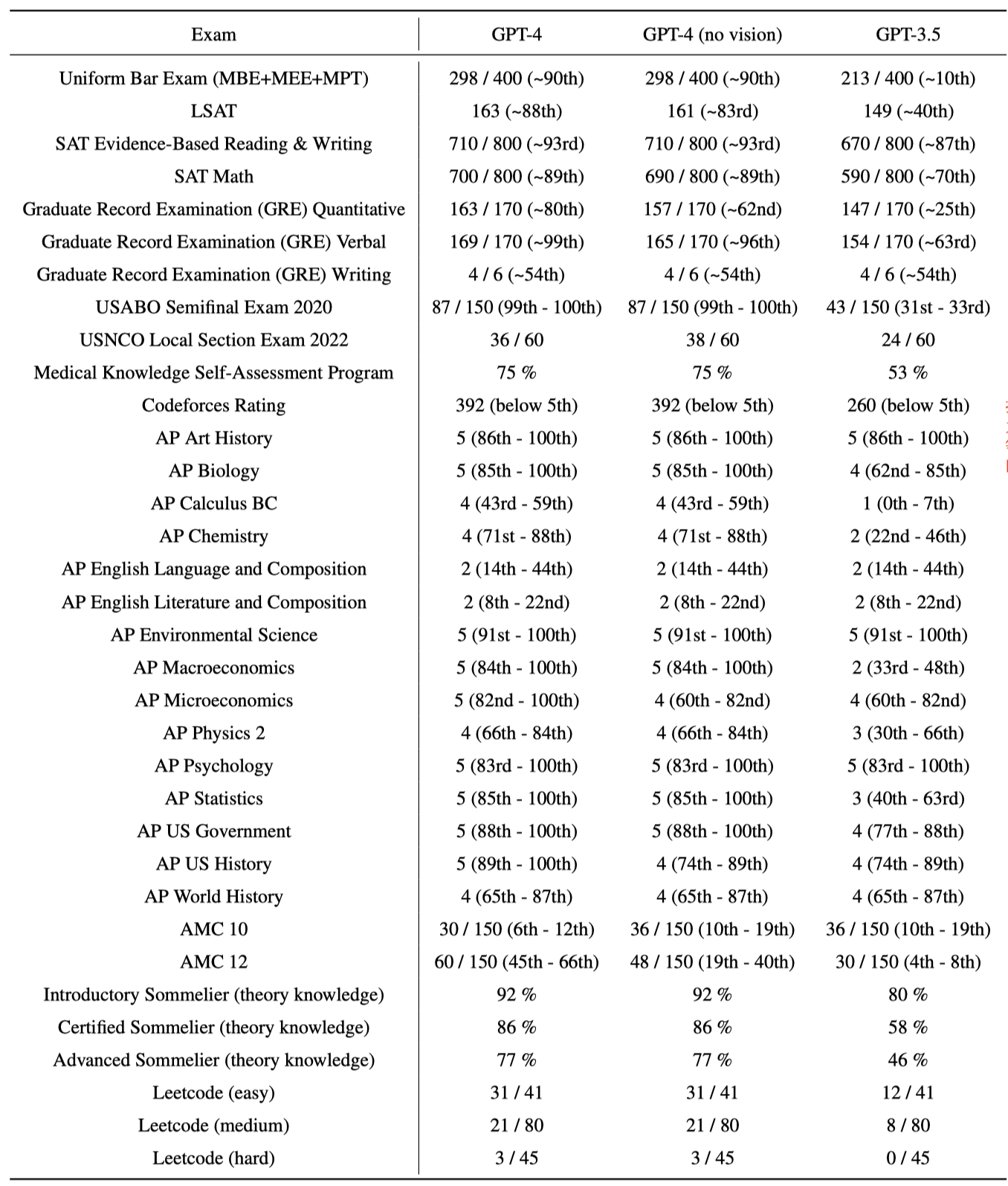
总体来看很强大了,比如LeetCode easy题能够通过75%,然后中等题和困难题通过数量比GPT-3.5要高很多,不过不清楚这个原因是不是因为网上很多人们问LeetCode题导致本身数据就比较多。
GPT-4比GPT-3.5更强大的是在复杂任务上表现效果好了很多:
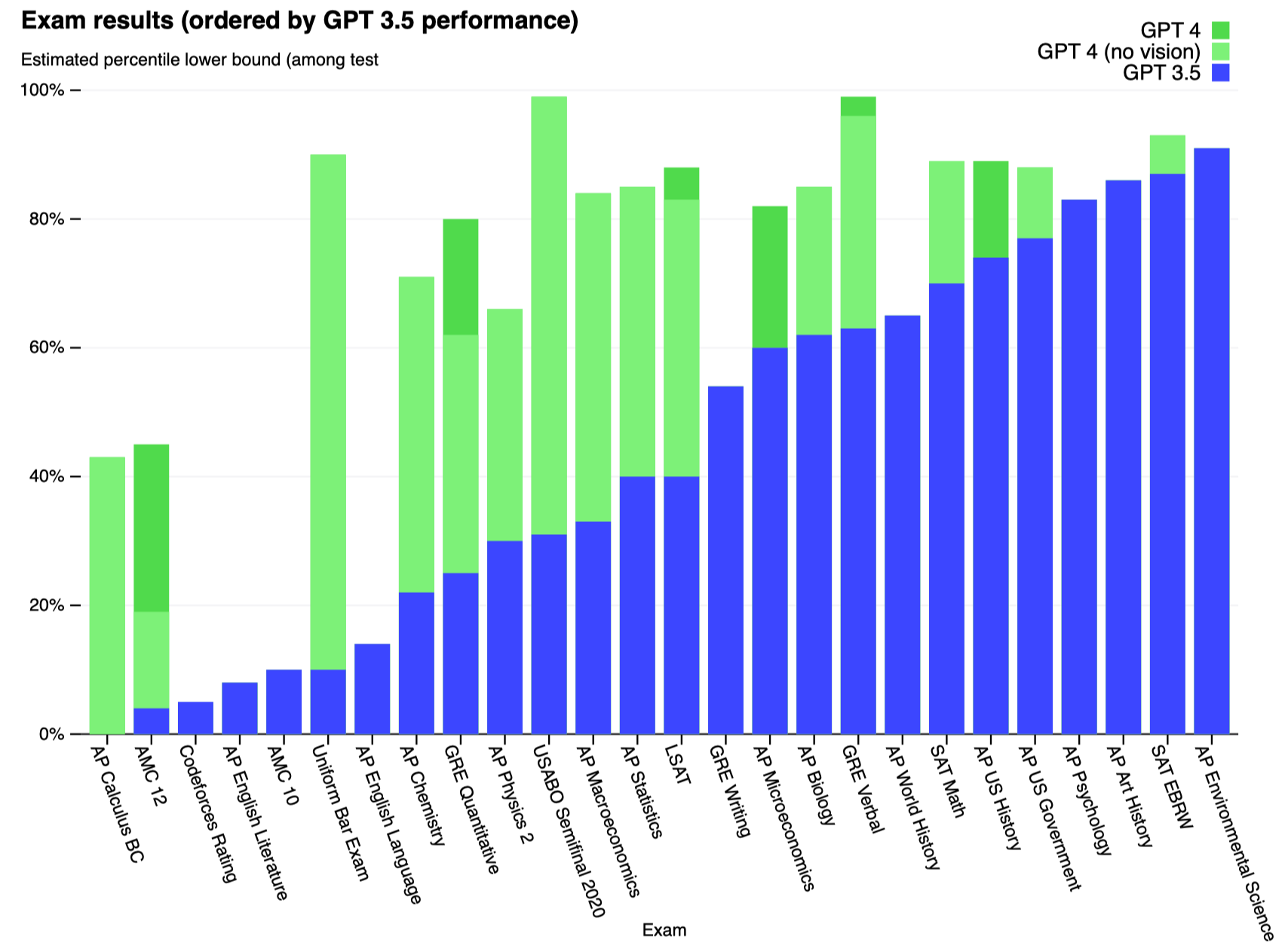
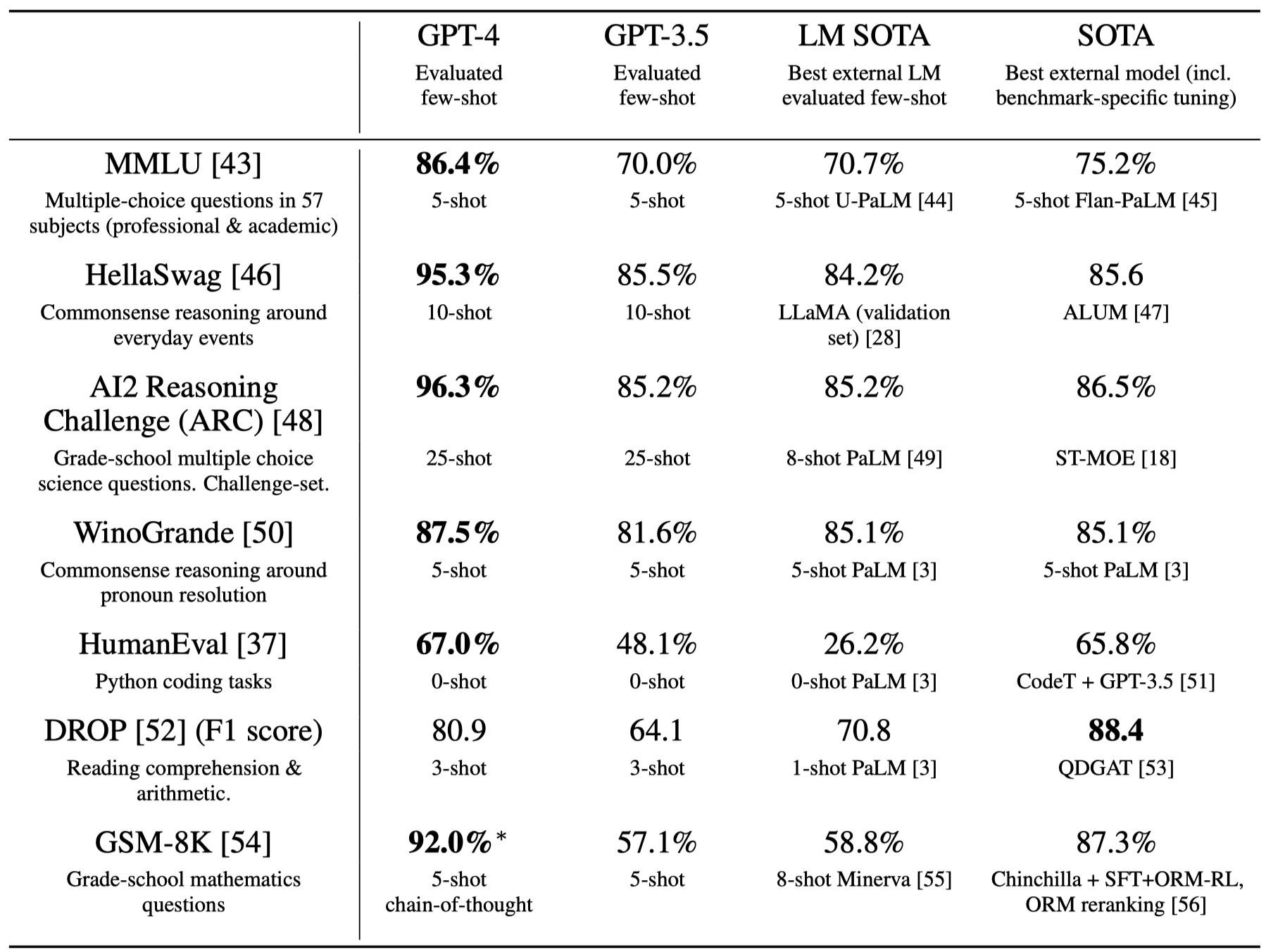
和其它大模型进行比较,当然是SOTA了,而且是不需要fine tuning只需要few-shot prompting:
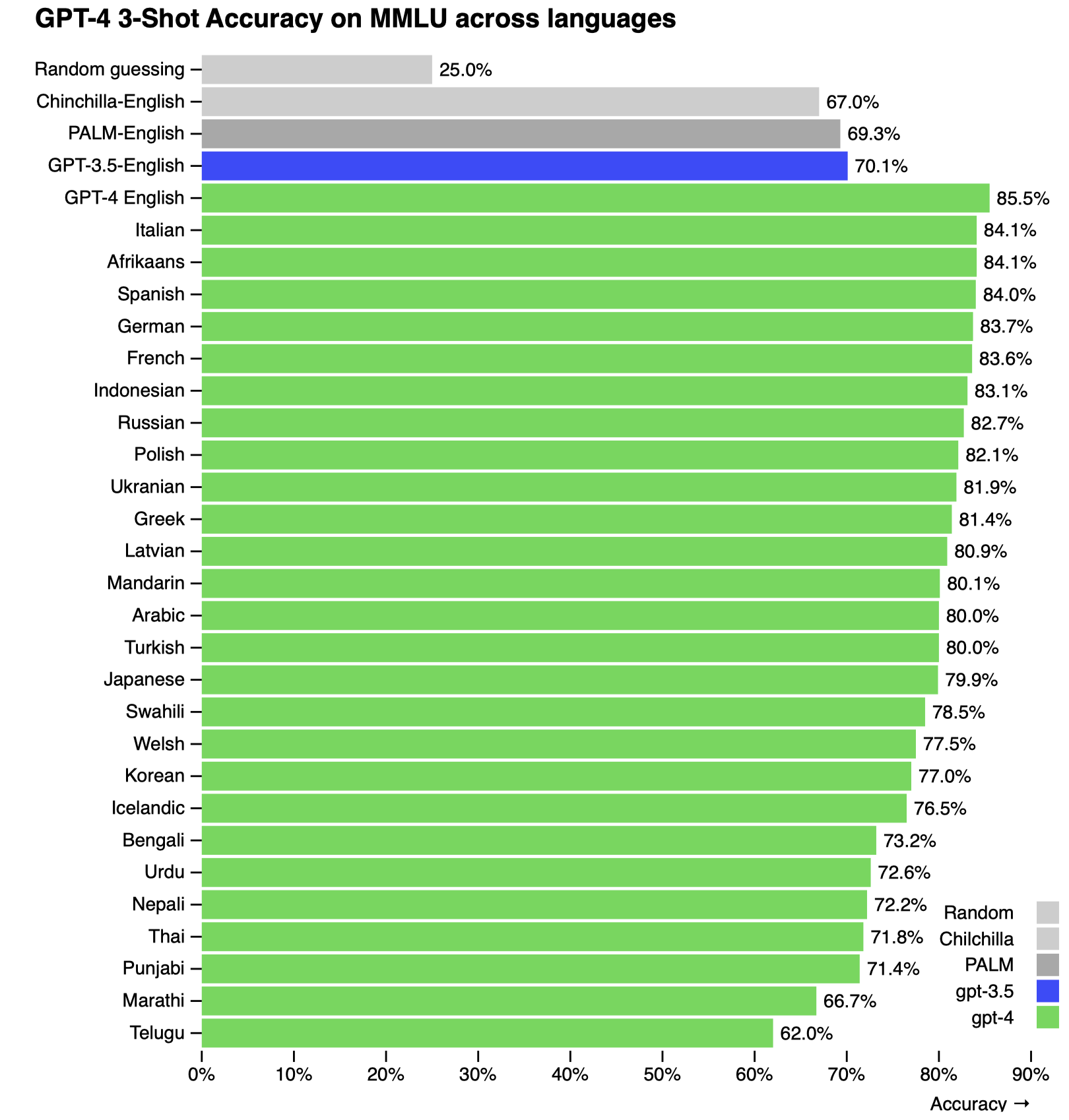
GPT-4在MMLU数据集上对多语言场景的效果(不知为何,没有汉语):
GPT-4可以输入图像,理解笑话:

GPT-4对于图像还有更多强大的应用场景,比如直接识别图表:
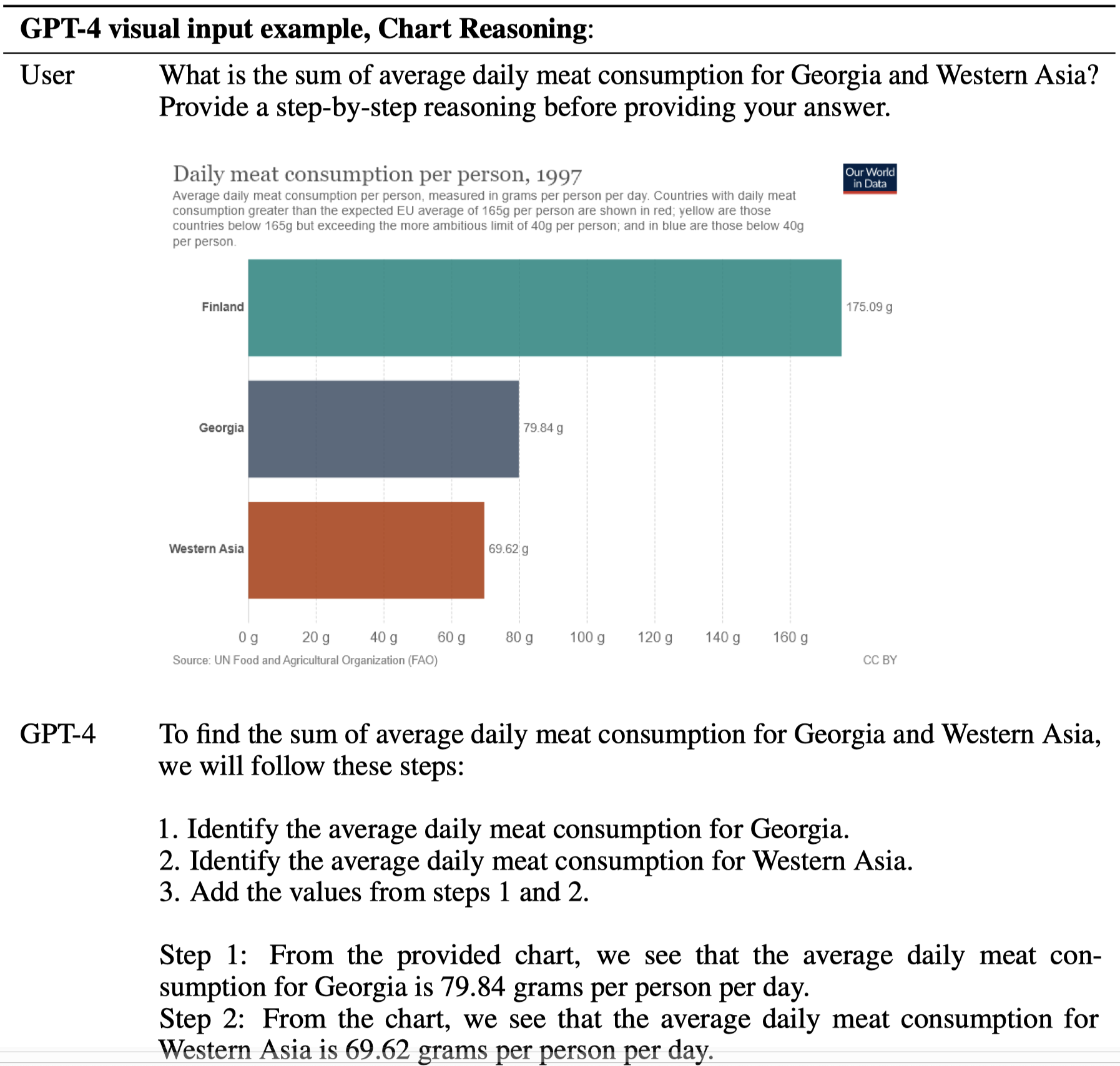
直接回答试卷题目:

识别图片上异常的地方:

直接理解论文……

理解幽默图片……

甚至是进一步理解包含了领域知识的幽默图片:

一句话总结,强的离谱。各种通用领域,特别是公开数据比较容易获得的任务已经被GPT-4以端到端的统一方式很好的完成了。接下来可能需要更多关注公开数据少、可信度和可解释性要求高的场景。最近这一年大量的NLP和多模态小任务会直接被GPT-4终结(除非在证明了GPT-4真的做不好的场景中继续研究),继续投入资源研究无意义了💔 。
4. Limitations
GPT-4仍然会产生错误的事实输出,不过通过RLHF比GPT-3.5产生错误事实的概率要小很多。
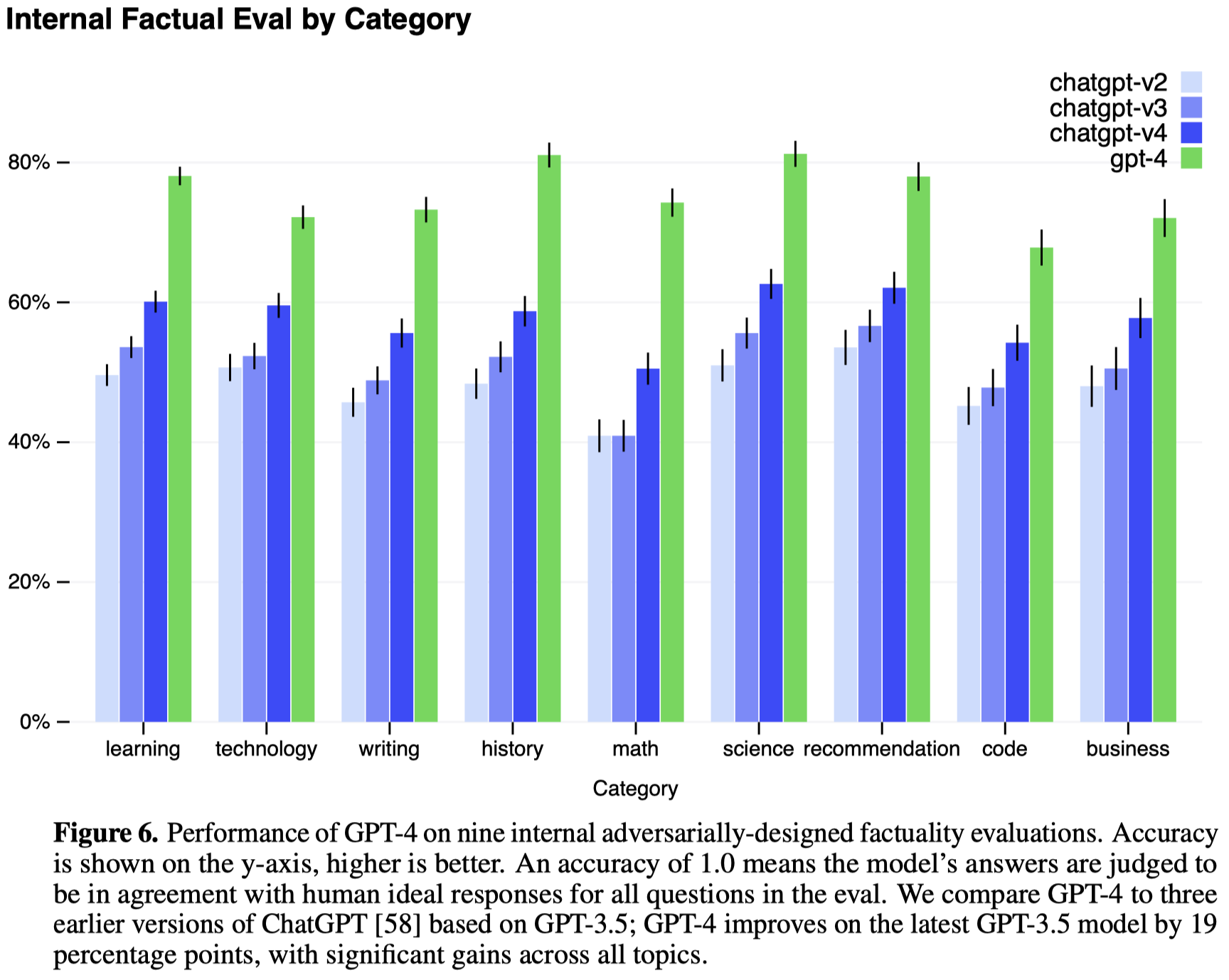
5. Risks & mitigations
Adversarial Testing via Domain Experts:邀请了50位各领域专家来帮助评估GPT-4可能产生的risk。通过采集领域专家的建议来进一步提升模型的可信性和安全性。比如说能够帮助GPT-4拒绝提供生产危险化学品方法的请求:

Model-Assisted Safety Pipeline:关于GPT-4的一个重要问题是如何让它知道什么样的问题是应该回答的。GPT-4对于输入安全性过于“放松”或者过于“谨慎”都不合适。
为了让模型能够更好的识别可回答的问题,OpenAI使用包括下面两个组件的方法:
- an additional set of safety-relevant RLHF training prompts
- rule-based reward models (RBRMs)
RBPM是一系列的zero-shot GPT-4分类器,能够为GPT-4 policy model提供额外的采取正确action的信号。比如下面是一个用来判断是否要拒绝的RBPM说明:

最后的回答应该是A-R的选项,并且提供这样做的原因:

通过采用上面的安全性控制策略,GPT-4能够更好的选择是否要回答用户的提问,比如下面不应该回答的问题:

应该回答,但是回答应该更加谨慎:

总体上,在OpenAI的评估中,通过使用RLHF,GPT-4能够更好地采取合适的反应:

尽管GPT-4对于危险输入的限制能力已经获得了很大提升,但是输入危险prompt依然是非常可能的。因此在部署后进行持续的安全性检测与更新是非常必要的。