GPT-3
Language Models are Few-Shot Learners
GPT-3,NIPS 2020 技术报告63页,不是投稿的论文,OpenAI,2020-05
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3’s few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
GPT-3比GPT-2强调的zero-shot的设置,稍微回退了一点,变为强调few-shot的设置。
1 Introduction
最近NLP领域热衷于研究pre-trained的语言表示,寻找能够实现task-agnostic的方法。
一开始研究者学习word的表示,然后作为task-specific的模型的输入。
最近出现了预训练+fine-tunning的模式,取得了很大的进展。
问题:进行任务相关的微调,可能带来下面几个缺点:
fine-tuning需要为不同的任务收集有监督的数据。每一个新任务都需要收集新的数据,这当然限制了模型的表达能力
fine-tuning的操作,会使得之前pre-training好的model向着一个狭隘的训练分布拟合,导致实际上更大的模型不一定会在训练分布之外表现出更好的泛化性,也就没有办法真正的评估出预训练模型的好坏
从人类的角度来看,学习特定的语言任务并不需要太多的数据,比如一个简单的描述就可以让人类进行对应的行为。这使得人类可以很快的学会大量不同的任务,并且同时无缝的执行不同的语言任务。我们期望语言模型也能够拥有这样的易变性(fluidity)和普遍性(generality)
解决思路:
一方面近期出现了一些在NLP上进行元学习的方法,比如“in-context learning”,把预训练模型的输入,构造出不同task的形式,让模型能够在训练的时候学习到广泛的模式识别能力。
Recent work [RWC +19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
下面这张图是对于语言模型可能在进行潜在的元学习的说明,并不是GPT-3真正的训练过程。比如不同的document有不同的context,是在讨论不同的领域。
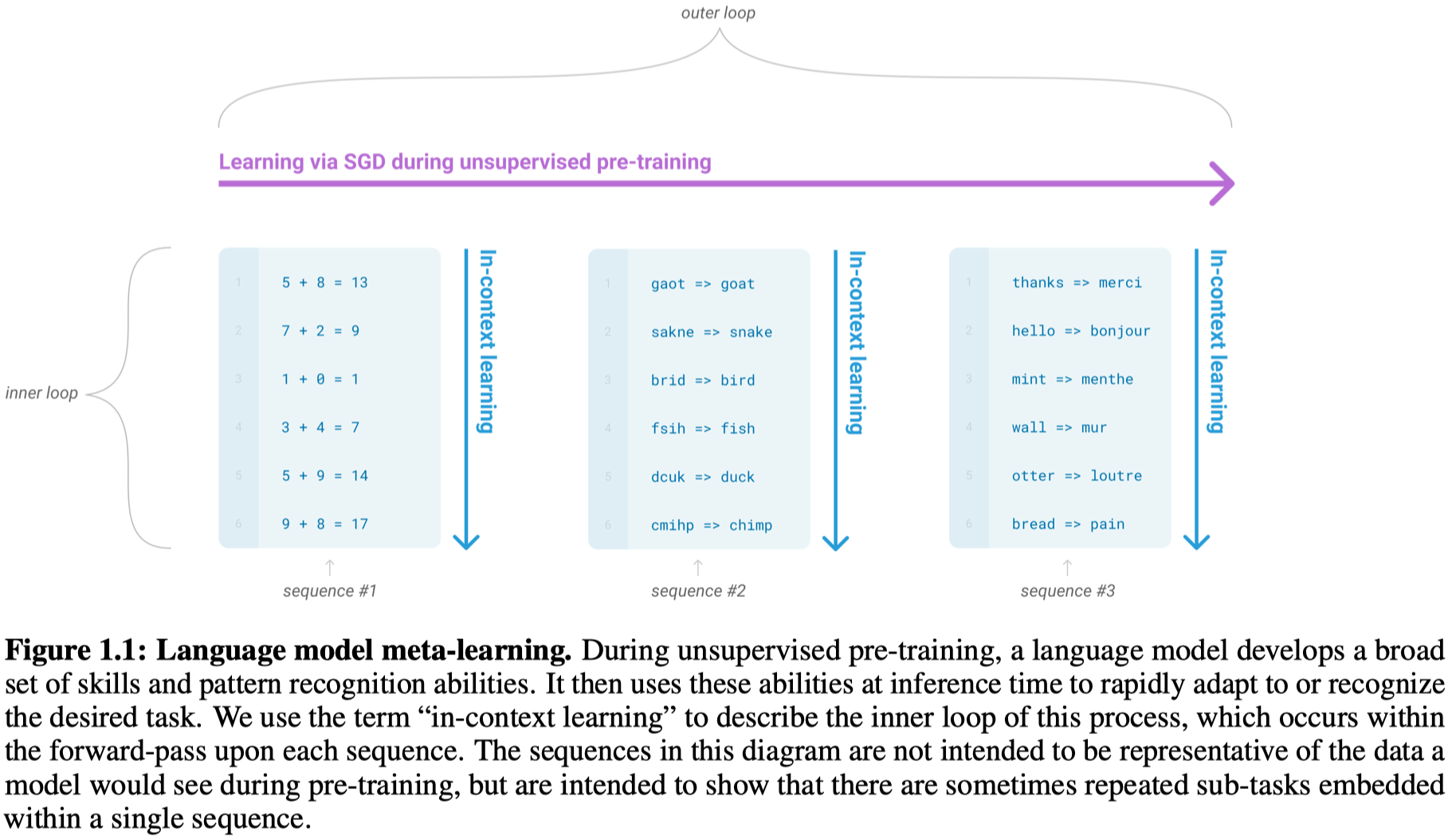
但是这一方向的元学习方法效果还远远不够好。
另一方面,最近出现了一系列基于transformer的大模型,随着规模增大,效果逐渐提升。
那么作者的思路就是结合两者:
如果也将元学习的模型规模扩大,可能它的能力也会得到提高。
Since in-context learning involves absorbing many skills and tasks within the parameters of the model, it is plausible that in-context learning abilities might show similarly strong gains with scale.
虽然作者提到了元学习的概念,但是这里的n-shot的example,并不会像一般的元学习方法一样去更新参数,在GPT-3的n-shot的example仅仅是作为输入,用来提示必要的信息。
这篇文章作者进行了以下的探究和贡献:
- 提出了拥有1750亿参数量的GPT-3,重点在于探究它的元学习能力。参数量是GPT-2的116倍;GPT-1的1600倍左右。
- 对GPT-3的性能,分别在zero-shot、one-shot和few-shot的设置下进行了大量的实验。讨论了GPT-3表现优越的地方,和表现不好的情况。
- 研究了在大规模语料中出现的数据污染问题(data contamination),即测试集中的内容可能在训练集中出现,特别是因为很多数据是收集于web上。发展出一套评估数据污染情况和后果的工具。
2 Approach
GPT-3使用的几种不同的实验设置:

最终效果显示,GPT-3在少次任务下表现相对最好,甚至在某些情况下超过了SOTA的模型;在one-shot和zero-shot的情况下,很多的任务表示promising,没有达到SOTA。
Broadly, on NLP tasks GPT-3 achieves promising results in the zero-shot and one-shot settings, and in the the few-shot setting is sometimes competitive with or even occasionally surpasses state-of-the-art (despite state-of-the-art being held by fine-tuned models).
在一个移除随机符号的NLP任务下,不同设置的GPT-3的性能:
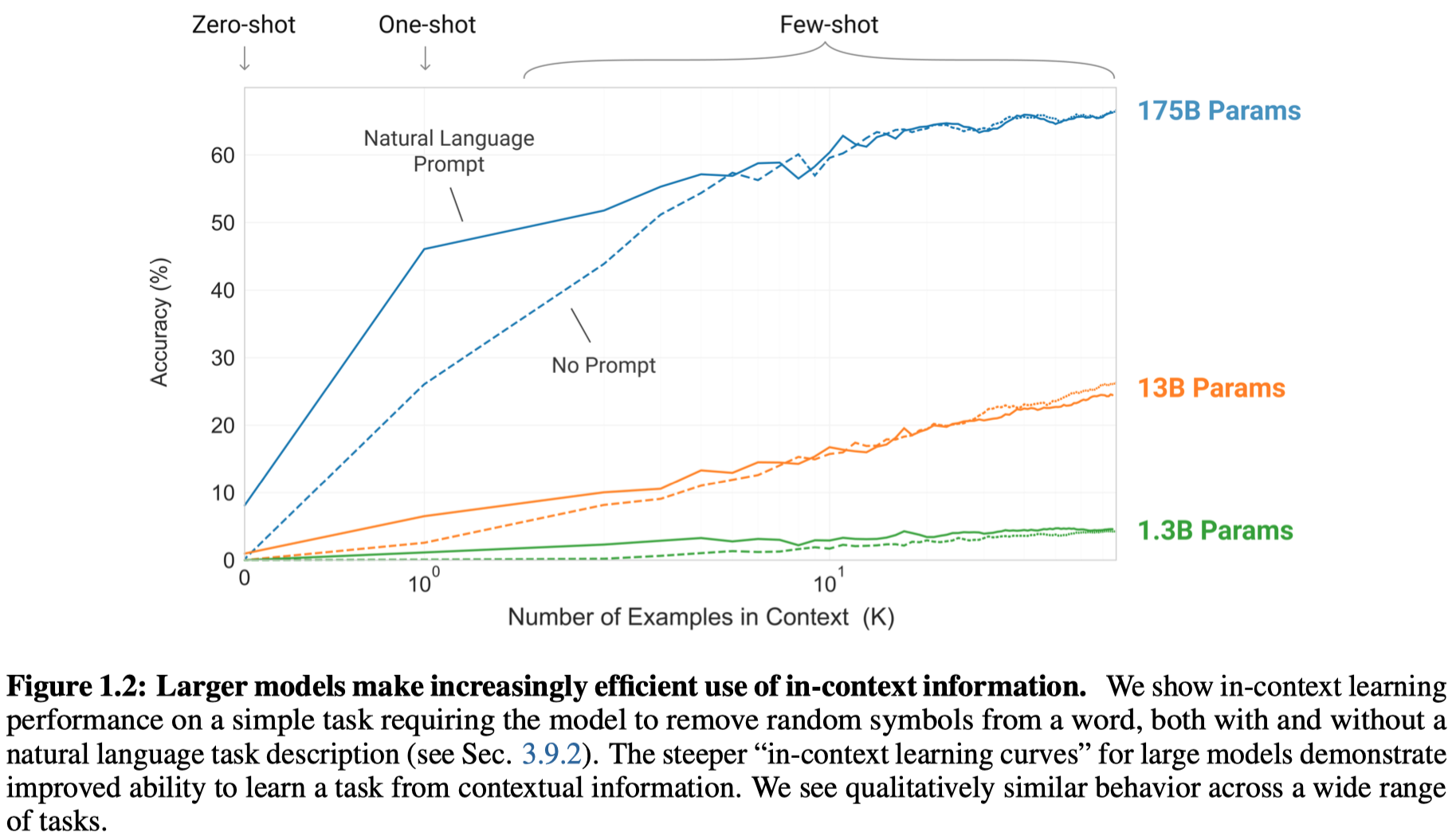
作者也发现,GPT-3在一些任务,比如自然语言推理以及阅读理解的部分数据集下表现不好。
At the same time, we also find some tasks on which few-shot performance struggles, even at the scale of GPT-3. This includes natural language inference tasks like the ANLI dataset, and some reading comprehension datasets like RACE or QuAC.
2.1 Model and Architectures
沿用GPT-2的架构。区别是使用了Sparse Transformer中的一些机制:
we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer.
实现的不同大小的模型:
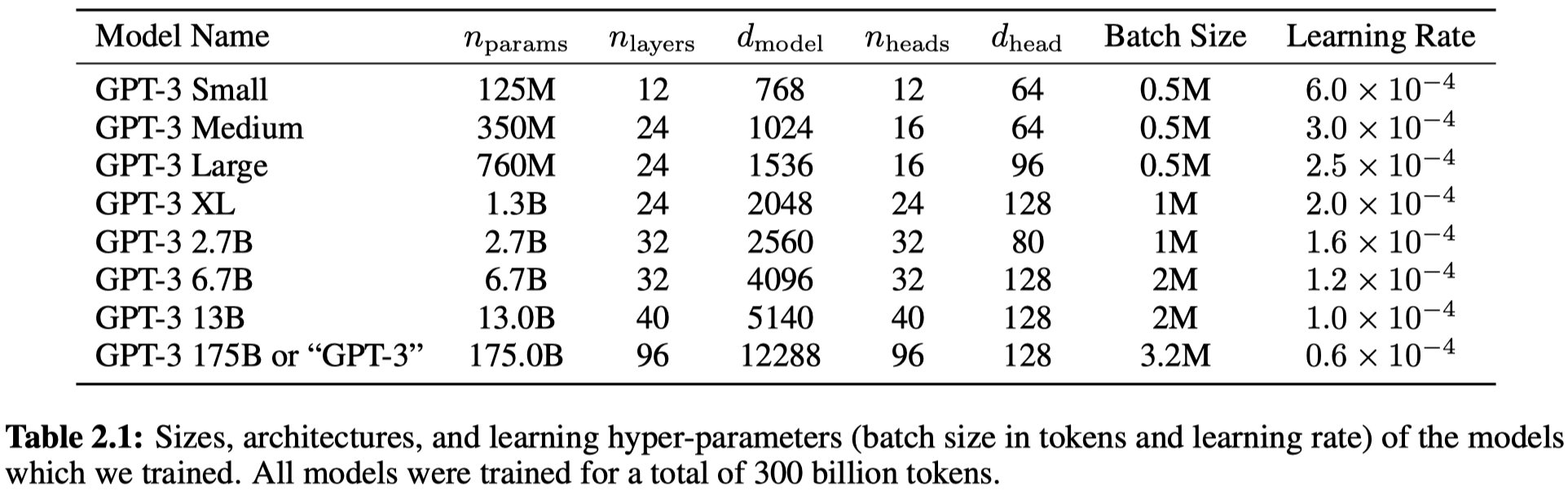
更大的模型,使用了更大的batch size和更小的学习率。猜测是大模型拟合能力更强,容量更大,因此扩大batch size、减小learning rate都是避免模型拟合太快
2.2 Training Dataset
大规模语料,来自多个不同的数据集,由于规模大,整个语料基本上一个sequence只需要训练一次即可。
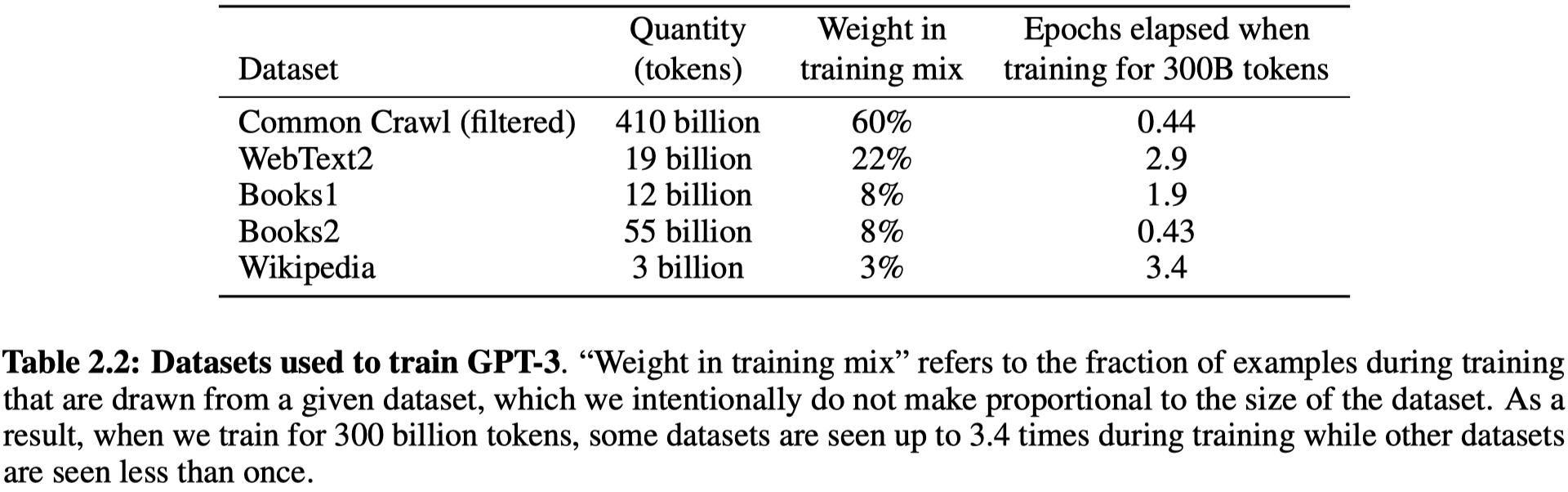
这里需要特别注意Common Crawl,原始版本包括了万亿级别单词,但是数据质量比较低。因此作者对它进行了一系列的数据清洗,最后得到了大概4100亿token,大小570 GB。
- 把Common Crawl数据集下载下来,然后使用一个简单的线性回归分类器,正类是高质量的数据集,比如GPT-2的WebText里的数据;负类是Common Crawl中原始的数据。然后对所有的Common Crawl中数据进行预测,如果分类到了正,就认为质量还可以,否则的话就过滤掉。
- 去重,使用LSH算法判断两个document是不是重合的。
- 把多个高质量的数据集加进去
在训练的时候,根据数据集的质量来采样,而不是根据数据集的大小。
在训练大规模model的时候,大规模语料可能在无意间包含了下游任务的测试信息,因此作者根据所有测试任务的验证和测试集,对训练语料进行了数据清洗。
To reduce such contamination, we searched for and attempted to remove any overlaps with the development and test sets of all benchmarks studied in this paper.
但是GPT-3的初始版本训练的数据集没有完全过滤掉污染的数据,并且由于训练代价,没法再次进行训练。
Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model.
3 Results
不同大小的模型,计算量和验证集上的损失下降的趋势。
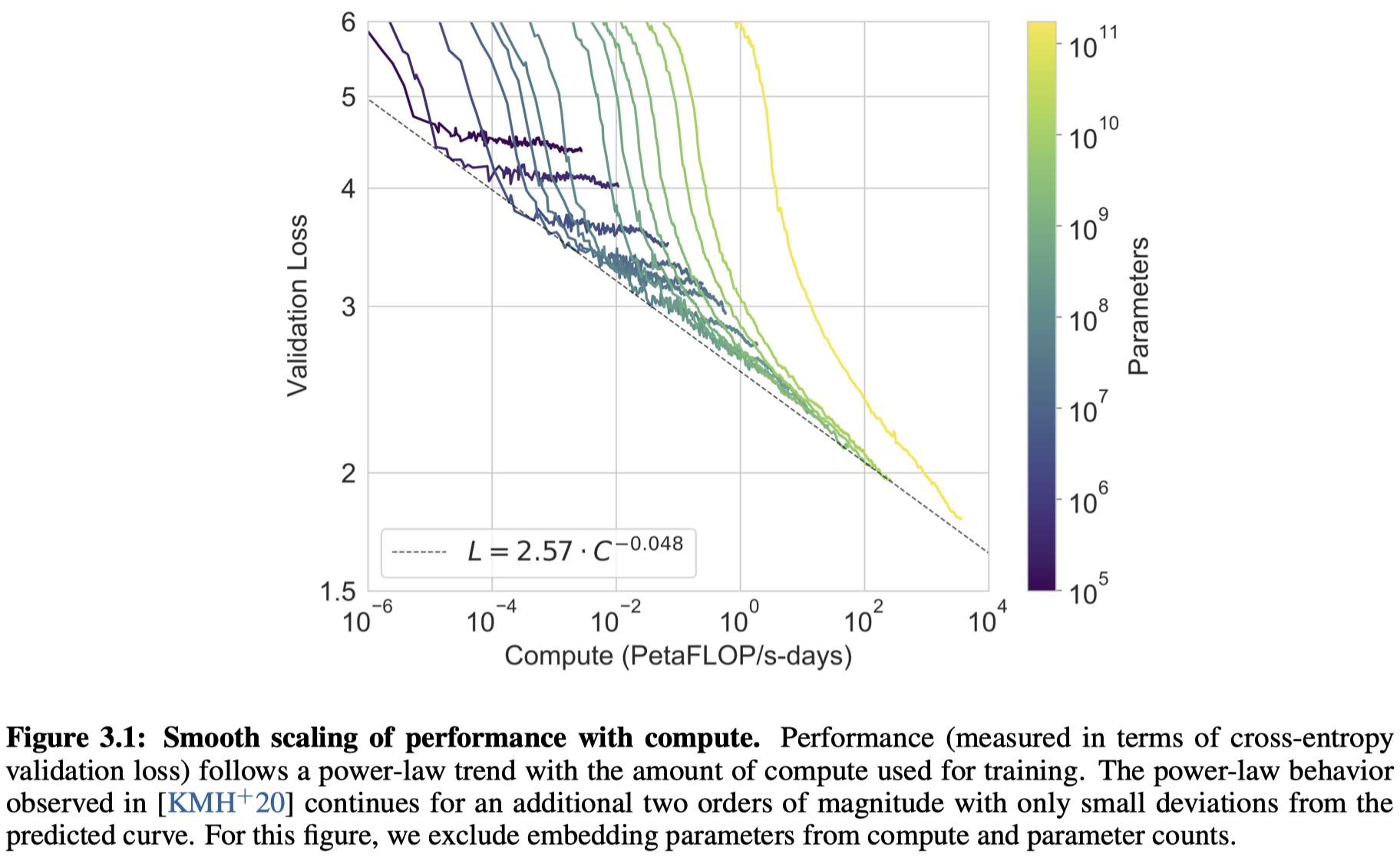
可以看到,对于单个模型,最好的方案是在每个loss和计算量相对平衡的点,继续进行运算,loss基本处于收敛的情况。如果把各个模型的平衡点相连,大致上是一个power-law的分布。也就是说,找到一个合适的模型,不过度训练的情况下,随着计算量呈指数增长,模型精度大概是线性下降的趋势。
5 Limitations
- 虽然效果比GPT-2要好很多,但是在文本生成任务上还是较弱。GPT-3擅长描述一段的文本,但是不擅长写更多、更长的文本。
- 结构和算法上的局限性,比如只能从前向后看。然后比如是在预测的时候,对于每一个token都是一样的处理,没有提取最重要的token。并且也只能学习文本的信息,并没有对物理世界的各种其它信息的感知。
- 样本有效性不够,使用了过多过大的语料。
- 不确定性,不确定GPT-3到底是在推理的时候真的从头学习到了怎么进行新的任务,还是说只是识别出了之前在预训练的时候见过的模式。
- 训练代价昂贵。
- 无法解释。
6 Broader Impacts
- 可能会被用来做坏事,假新闻造谣、论文造假等等
- 公平、偏见(性别、种族、宗教等等)。比如GPT-3更可能认为某个角色是男性
- 能耗
Conclusion
We presented a 175 billion parameter language model which shows strong performance on many NLP tasks and benchmarks in the zero-shot, one-shot, and few-shot settings, in some cases nearly matching the performance of state-of-the-art fine-tuned systems, as well as generating high-quality samples and strong qualitative performance at tasks defined on-the-fly. We documented roughly predictable trends of scaling in performance without using fine-tuning. We also discussed the social impacts of this class of model. Despite many limitations and weaknesses, these results suggest that very large language models may be an important ingredient in the development of adaptable, general language systems.