GPT-2
Language Models are Unsupervised Multitask Learners
GPT-2 OpenAI,15亿参数量,2019-02
Natural language processing tasks, such as question answering, machine translation, reading comprehension, and summarization, are typically approached with supervised learning on taskspecific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText. When conditioned on a document plus questions, the answers generated by the language model reach 55 F1 on the CoQA dataset - matching or exceeding the performance of 3 out of 4 baseline systems without using the 127,000+ training examples. The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText. Samples from the model reflect these improvements and contain coherent paragraphs of text. These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations.
遗憾的是尽管比BERT-large的3.5亿参数量还要大,但是效果并没有超过BERT。因此在GPT-2主要在zero-shot设置下进行探究。
1 Introduction
问题:之前出现的在大规模数据集上训练大模型的方法,对数据集的分布以及特定的任务很敏感。这些系统的适应面积还比较狭窄。作者希望能够进一步推动这些大模型的泛化性,往最终的理想目标更进一步:不需要给每个任务都创建和人工标注数据集。
假设:作者认为在特定领域下进行task相关的训练,是造成目前众多系统泛化性受到约束的原因。比如目前出现的利用多任务学习提升模型泛化性的方法,即在训练的时候可以同时看到不同任务相关的数据集,从元学习的角度看,每个任务(dataset, objective)可以看做是一个training sample。如果要让一个ML系统的泛化性足够好,可能需要成百上千的多任务。当然这是很难一直拓展的下去的。
另外,对于已有的预训练+微调的模式,对于不同的任务仍然需要有标注好的数据。
Our suspicion is that the prevalence of single task training on single domain datasets is a major contributor to the lack of generalization observed in current systems.
方法:作者直接让训练好的语言模型能够在下游的zero-shot的任务下进行预测,不需要任何结构和参数上的调整。核心在于两点:(1)足够大、足够多样化、质量较可靠的大规模数据集WebText(2)整体参数量达到了15亿的基于Transformer的模型(和GPT-1整体架构一样,只不过是层数更多,并且采用了一些新的训练trick)。
2 Approach
在GPT-1里,对于要预测的任务加入了词元(START、EXTRACT和delimiter),这些词元是在无监督的时候没有见过的词元,但是因为会进行task-specific的微调,所以这些词元回去尝试学到合适的表示。但是现在GPT-2要做zero-shot的设置,那么就不能在不同task下,加入没见过的词元。因此在GPT-1中的词元的引入就不再合适了。
也就是说要让输入的序列,变得更像自然语言。
比如做机器翻译:(translate to french, english text, french text)。第一个输入translate to french,就叫做提示prompt。
为什么加入这样自然语言描述的prompt就能够让机器执行相应的任务?作者认为训练好的大模型应该有能力学习到这样的推理能力。
Our speculation is that a language model with sufficient capacity will begin to learn to infer and perform the tasks demonstrated in natural language sequences in order to better predict them, regardless of their method of procurement.
比如下面在数据集里关于法语翻译成英语的例子:

可以猜想,如果语料库确实质量好,数据量足够大,那么对于不同的任务应该可以理解到不同的含义。
2.1 Training Dataset
作者构建了尽可能大,尽可能包括更多领域的数据。
Our approach motivates building as large and diverse a dataset as possible in order to collect natural language demonstrations of tasks in as varied of domains and contexts as possible.
作者自己从Reddit上导出了网页内容,为了保证数据质量,人工的过滤/审核抓取的网页内容是不实际的。因此作者从Reddit上爬取的数据是至少有3个karma的帖子(karma是佛教里业力、报应值的意思,在用户对Reddit的帖子进行点赞投票的时候,会获得相应的karma),表明至少这些内容是有意义或者是有趣的。最后的WebText,在2017年12月之后,经过了数据清洗,去重之后,包括了超过800万的文档,总共40G的数据。
2.2 Input Representation
模型对输入文本的要求会限制模型的泛化性。
作者采用了Byte Pair Encoding (BPE)的方法在word-level和byte-level上进行平衡。word-level的编码效果比较好,而byte-level的泛化性强。
这一部分没看懂。
2.3 Model
继续沿着OpenAI GPT model的架构,但是做了几个稍稍的改进:
- 把layer normalization移到每个block的输入部分;并且在最后的self-attention block输出加了一个额外的layer normalization、
- 残差层的参数初始化值考虑到了网络的深度,乘以系数\(1/\sqrt{N}\),\(N\)代表残差层的深度。
根据网络的深度,设计了四个大小不同的模型:
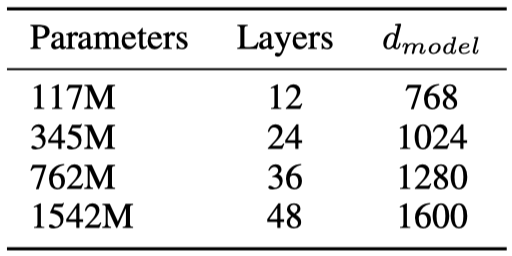
最大的模型参数量比GPT-2大了14倍。
3 Experiments
涉及到的方面很多,很多任务具体不是很了解,看一下总体的情况:
在zero-shot设置下,不需要经过有监督的训练,直接在8个数据集中的7个数据集获得了SOTA:
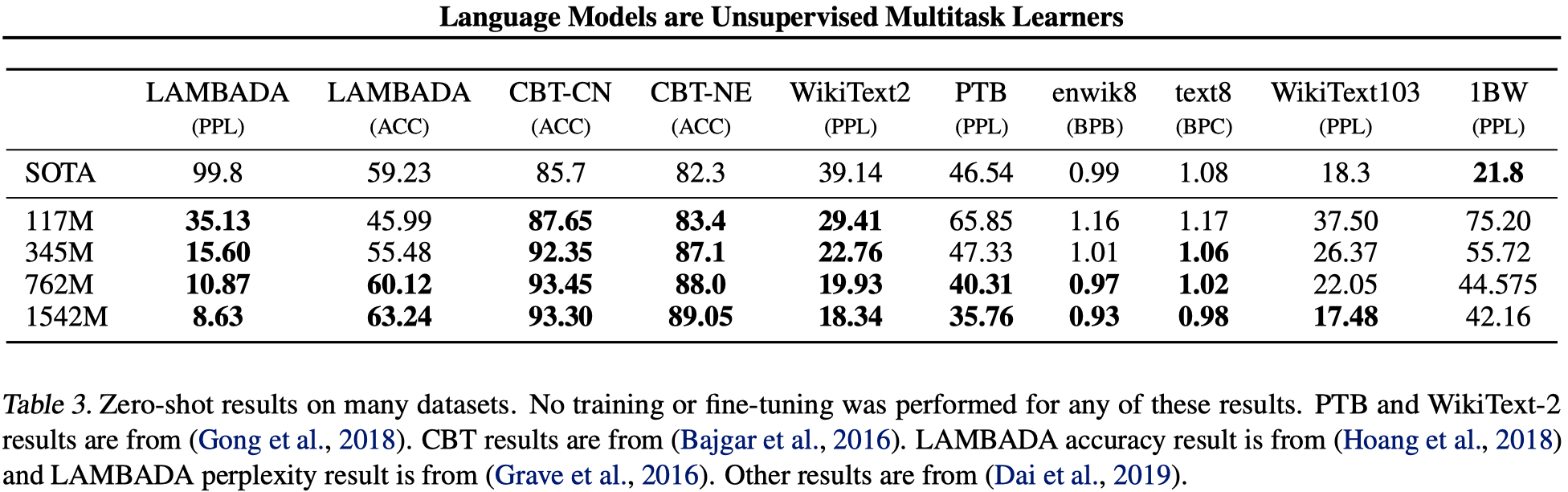
GPT-2在Children’s Book Test(类似于完形填空)、LAMBADA(文本长依赖建模能力,预测长句子的最后一个单词)、Winograd Schema challenge(对含糊不清的文本进行常识推理)等task都取得了SOTA的结果。
但是在一些其它的task表现不太好,特别是翻译和QA,表现出来的效果并没有比之前非常粗浅的方法效果好,距离已有的SOTA方法差距很远。
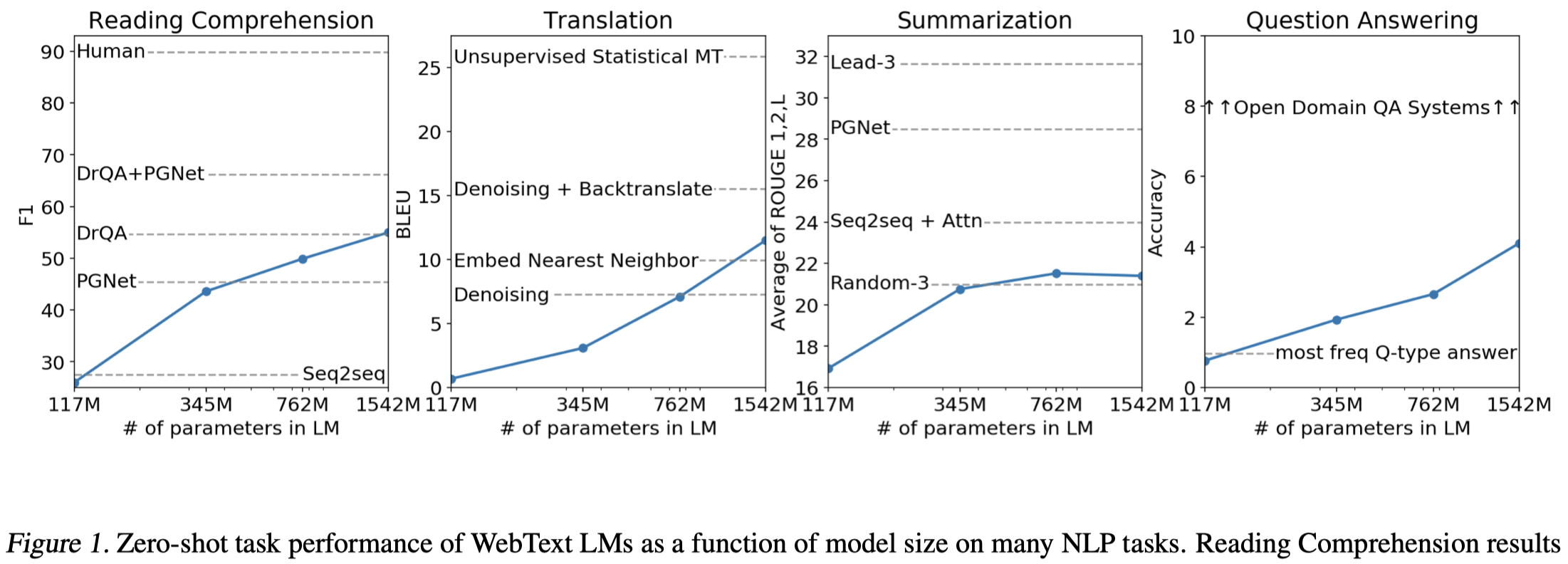
需要注意的是,即便是这么大的模型,作者认为仍然是欠拟合(underfit)WebText的:
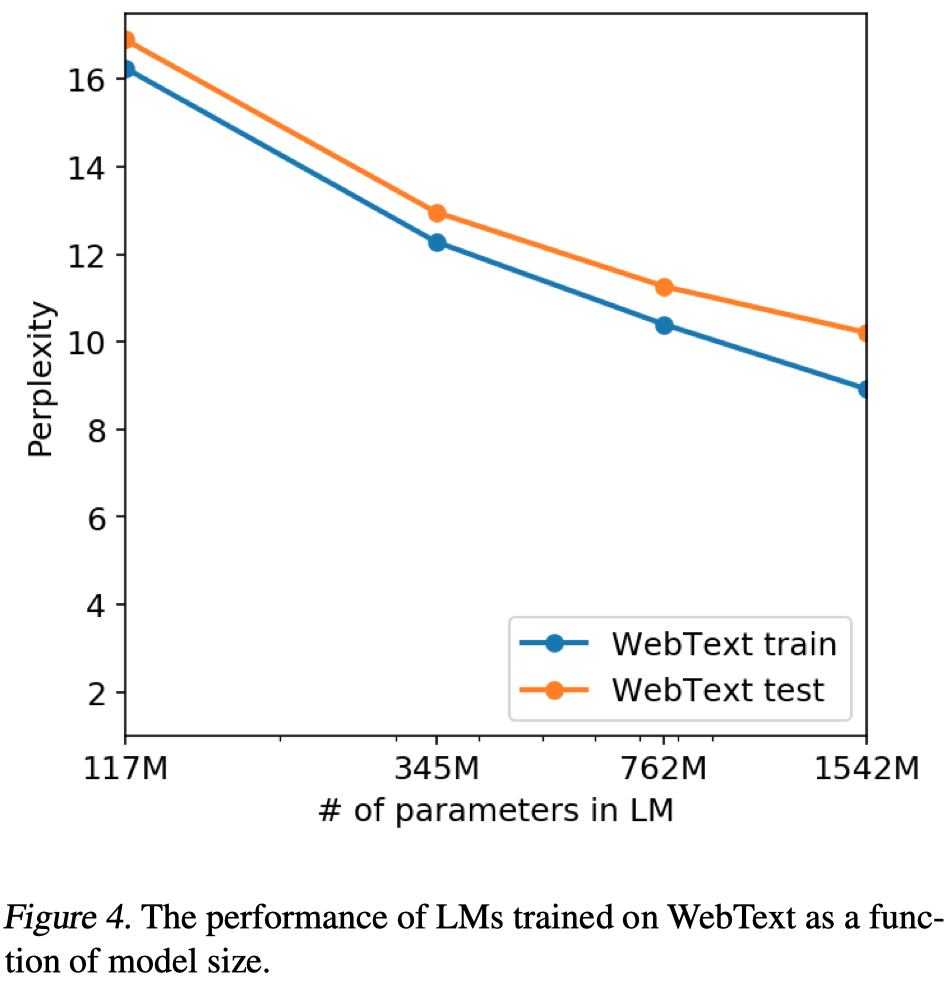
随着模型增大,在WebText上的效果一直在变好,如果继续增大模型,效果应该会进一步增加。纵轴是困惑度(perplexity),越小越好,下面的它的常用的对数形式(来自知乎):
