GPT-1
Improving Language Understanding by Generative Pre-Training
2018-06年,OpenAI,GPT-1
Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI).
参考:
- 原论文《Improving Language Understanding by Generative Pre-Training》
- 沐神的GPT讲解视频
GPT把Transformer的解码器拿出来在大规模数据集上进行预训练;BERT把transformer的编码器拿过来。BERT-base维度和结构层数和GPT-1是一样的,并且也使用了BooksCorpus数据集进行预训练。
1 Introduction
作者希望解决什么问题?
深度学习的模型往往需要足够的标注数据进行训练,但是这往往代表着高昂的人工代价和成本。同时在很多领域没有这么多的标注数据。但是直接利用无标签数据进行信息捕获的方法,是一直以来期望能够实现的方向。即便是有足够标注数据的领域,如果引入通过无监督方式学习到的表示,也可能进一步提升模型效果,比如使用预训练好的word embedding来提升NLP任务结果。
但是目前在如何利用无标签数据这个方向上的方法存在两个问题:
- 从无标签文本当中学习什么样的优化目标是最适合之后进行task transfer的,没有明确的答案。
- 对如何把学习到的表示转化到特定的任务,没有统一的方法/共识,很多方法往往会针对特定任务进一步改造模型架构,引入更多的参数。
作者是用什么方法/思路解决上面的问题的?
思路:半监督预训练+有监督的任务相关的微调,unsupervised pre-training+supervised fine-tuning
In this paper, we explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning.
最终期望能够在大规模语料上训练好,对于不同的任务(甚至是和语料表示的领域不相关的任务)只需要很小的改动即可。
Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks.
设计:预训练(Transformer decoder)+微调(把输入采用traversal-style approaches,变为序列化token的输入,输出在Transformer后加一个线性层和softmax)
使用transformer作为总体的架构,因为它更能够处理长期依赖(想想它是所有token都一起经过attention的),因此在不同的task之间,提供了较好的鲁棒性(设想下不同的task需要的信息是不同的,可能存在于语料的不同地方,那么当然需要预训练的模型尽量把所有的信息都能够记住)。
有研究者认为预训练实际上是一个regularization scheme,因此能够让深度学习有更好的泛化性,这里如有兴趣,可以参考paper《Why does unsupervised pre-training help deep learning?》
2 Framework
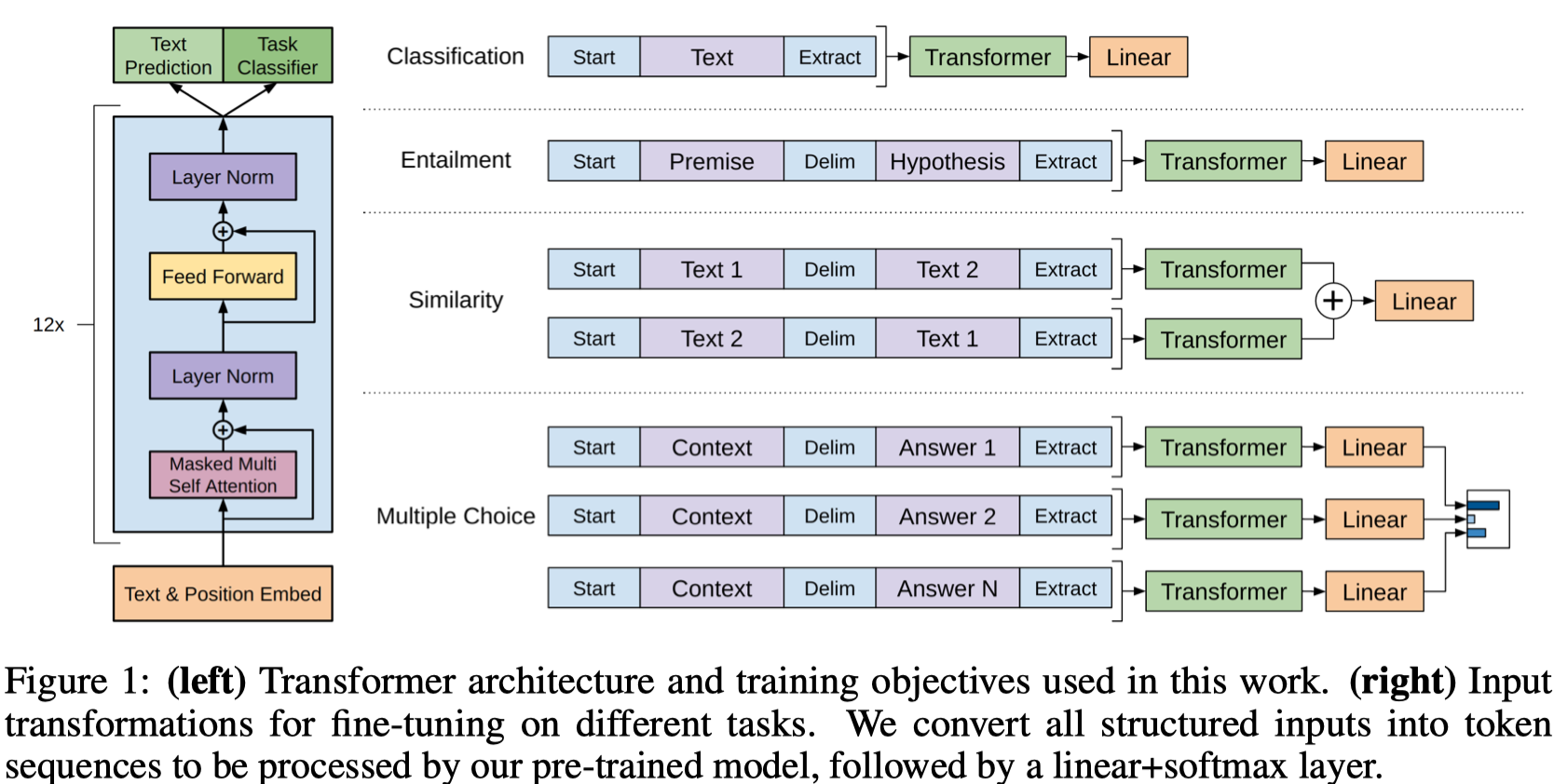
从上图可以看到,GPT会把各个子任务变为序列的形式,在开始加入一个\(Start\)词元,在最后加入一个抽取\(Extract\)词元。整个序列输入transformer解码器,然后使用抽取词元的表示经过线性层,作为具体的预测目标。
- Entailment:指在premise中是不是支持hypothesis,三分类问题
- Similarity:两段文本是不是相似,构造两个序列
- Multiple Choice:n个答案,构造n个序列输入
2.1 Unsupervised pre-training
优化目标,标准的语言模型优化目标,已知前\(k\)个token,尝试预测当前token \(i\),\(k\)就是窗口大小:
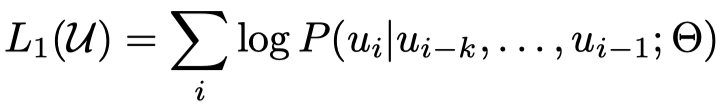
已知前面几个token的情况下,预测第i个token出现的概率;这点和BERT中的不太一样;BERT的预训练是采用了带掩码的语言模型,会mask掉任意的word然后进行了预测,做完形填空,这样来看BERT的预训练的语义方向是双向的。
优化目标\(L_1\)是整个语料\(U\)各个token出现的概率,一般情况下概率之间应该是相乘的,这里使用\(log\)之后,就变成了多个概率相加。相加的操作比相乘更容易并行,计算也更简单。\(k\)越大的话,整个模型会月倾向于使用更长的文本中寻找信息。
输入是context token(不太清楚具体指什么vector,难道就是简单的token编码,比如one-hot?)。
使用的模型是transformer的解码器,因为transformer的编码器是可以看到整个文本的,而解码器是只会看到前面的词,因此在GPT里还是使用了transformer的解码器。结构是12层+768 dimensional states+12 attention heads,输出是预测是哪个token的概率:
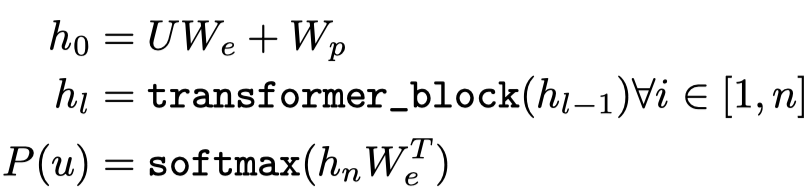
其中的\(W_e\)是指token embedding组成的矩阵。
2.2 Supervised fine-tuning
输入是token,对于某些任务,比如问题-回答等,需要把原来结构化的输入变为与序列化的输入。
对于输入\(<x^1,\cdots,x^m>\),放入transformer里,获得最后一层的位置\(m\)输出的表示。
参数就是前一步train好的Transformer,后面再加一线性层,最后经过softmax获得预测的标签\(y\):
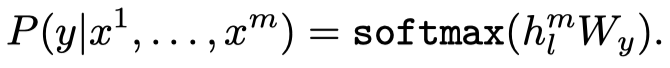
优化的目标函数:
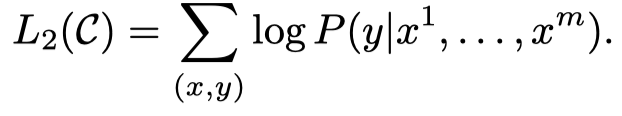
作者同样是有了辅助目标函数来增加有监督模型泛化性(让有监督模型不仅仅是只看重一个优化目标),加速收敛(不仅仅依赖于微调对于pre-train model的updating)。但是作者在后面的实验部分发现,辅助函数主要是对规模比较大的有监督的数据集效果比较好,而对于规模比较小的数据集效果不如移除辅助目标函数。
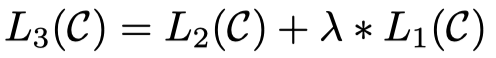
在优化task相关的目标loss的同时,也进一步优化之前pretrain的目标loss。
3 Experiments
在BooksCorpus数据集上进行了预训练,7000篇没有被发表的书。
作者用到了大量的训练上的trick,这里不提。有一部分是我不了解的,也没有使用过。
总的来说,在4个任务atural language inference,question answering,semantic similarity, text classification,一共12个数据集上的9个数据集取得了最好的结果。
具体的结果也不粘贴了,参考论文。
主要看一下消融实验:
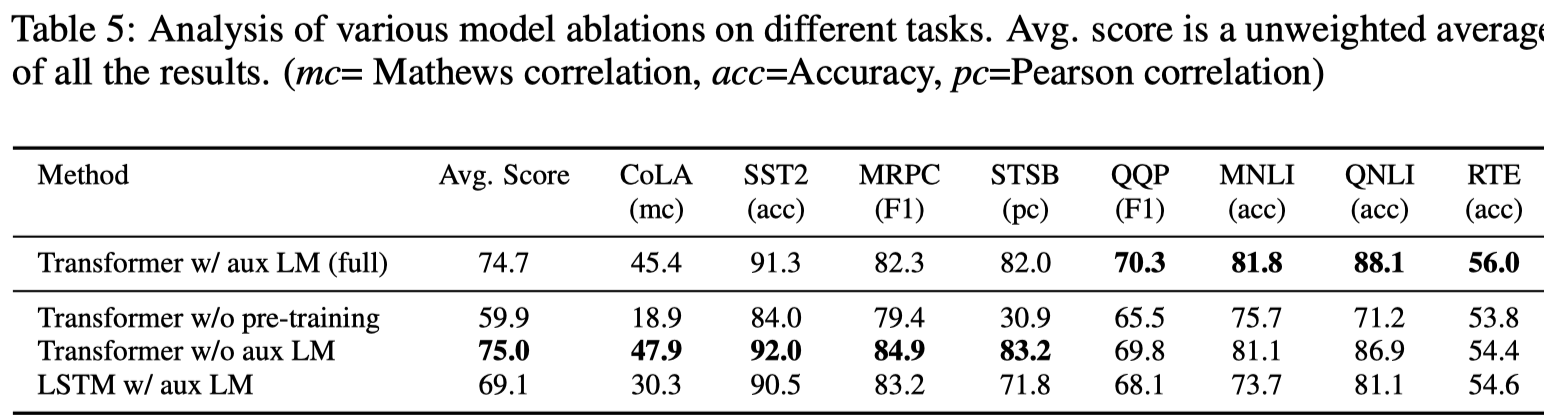
证明了:
- 加入辅助目标函数,帮助模型在规模更大的数据集上取得了更好的效果
- 使用Transformer而不是LSTM,帮助模型取得了更好的效果(除了在MRPC数据集上)
- 如果不使用预训练,在所有数据集下都出现了严重的效果下降
Conclusion
Our work suggests that achieving significant performance gains is indeed possible, and offers hints as to what models (Transformers) and data sets (text with long range dependencies) work best with this approach. We hope that this will help enable new research into unsupervised learning, for both natural language understanding and other domains, further improving our understanding of how and when unsupervised learning works