ConvRe-LLM
ConvRe
An Investigation of LLMs’ Inefficacy in Understanding Converse Relations. 北航. EMNLP 2023. 代码.
Large Language Models (LLMs) have achieved remarkable success in many formal language oriented tasks, such as structural data-to-text and semantic parsing. However current benchmarks mostly follow the data distribution of the pre-training data of LLMs. Therefore, a natural question rises that do LLMs really understand the structured semantics of formal languages. In this paper, we investigate this problem on a special case, converse binary relation.** We introduce a new benchmark ConvRe focusing on converse relations, which contains 17 relations and 1240 triples extracted from popular knowledge graph completion datasets.** Our ConvRE features two tasks, Re2Text and Text2Re, which are formulated as multi-choice question answering to evaluate LLMs’ ability to determine the matching between relations and associated text. For the evaluation protocol, apart from different prompting methods, we further introduce variants to the test text and few-shot example text. We conduct experiments on three popular LLM families and have observed various scaling trends. The results suggest that LLMs often resort to shortcut learning and still face challenges on our proposed benchmark.
在这篇论文里,作者探究了LLM对于逆关系converse relations理解的问题,为此,创建了一个benchmark ConvRe。作者发现LLM能够更好的理解normal relation,而不能很好的理解逆关系。并且随着model size增大,反而理解效果越差。作者推测是由于LLM在预训练阶段学习到了很多特征,在推理时,习惯于利用这些预训练特征走捷径shortcut。
尽管LLM已经在data-to-text和semantic parsing等任务上已经表现出了很好的结果,但是仍然有个关键问题需要探究:
do these LLMs genuinely understand the nuanced semantics of formal languages, or are they merely exploiting statistical patterns inherent in their pre-training data?
是否是真正的理解了语言,还是说仅仅在利用预训练阶段的统计特征。作者将这种倾向看做是shortcut learning:
Geirhos illustrated et al. (2020), highlighted a phenomenon in deep learning known as shortcut learning. These deep variations learning on the known test as text shortcut bring different effects are decision rules that achieve high performance on standard benchmarks but fail to generalize under more challenging testing conditions such as real-world scenarios. This issue is particularly significant in language processing tasks, where a language model may show an ability to reason that is learned from the training data, but its performance can drop drastically—sometimes to levels equivalent to random guessing—when superficial correlations are removed from the dataset (Niven and Kao, 2019).
shortcut learning就是指在benchmark里起到作用的有bias的映射规则,但是在实际中可能并不存在
作者特别针对逆关系的理解问题进行了探究:
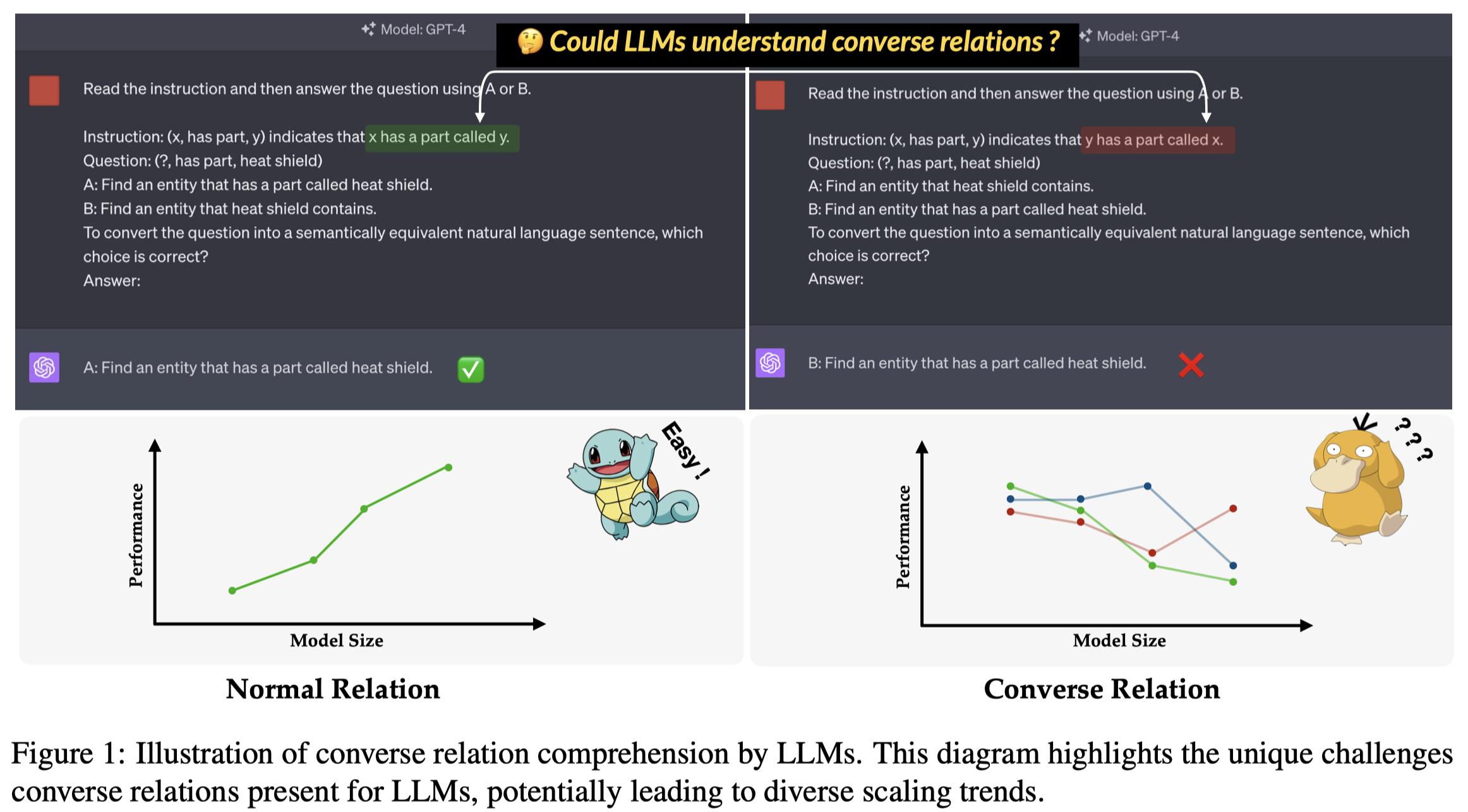
从WN18RR (Dettmers et al., 2018), FB15K-237 (Toutanova and Chen, 2015), Wikidata5M (only transductive settings) (Wang et al., 2021), NELL-ONE (Xiong et al., 2018), ICEWS14 (García-Durán et al., 2018), ConceptNet5 (Speer et al., 2017)等数据集中,人工选择了\(17\)种relation和对应的triples。
然后,作者设计了两类任务:Re2Text任务将relation 三元组(无头实体)转化为句子;Text2Re将句子,转化为无头实体的三元组。两个任务都是做选择的形式。


在这两个任务里的关键设置是对text句子进行改写,将其转化为更不常在LLM预训练语料中出现的形式。利用这个句子去控制可能存在的捷径。
作者对于OpenAI GPT-3 (Brown et al., 2020), Anthropic Claude (Anthropic, 2023), and Google FLAN-T5 (Chung et al., 2022)三类LLM进行了实验。实验结果:
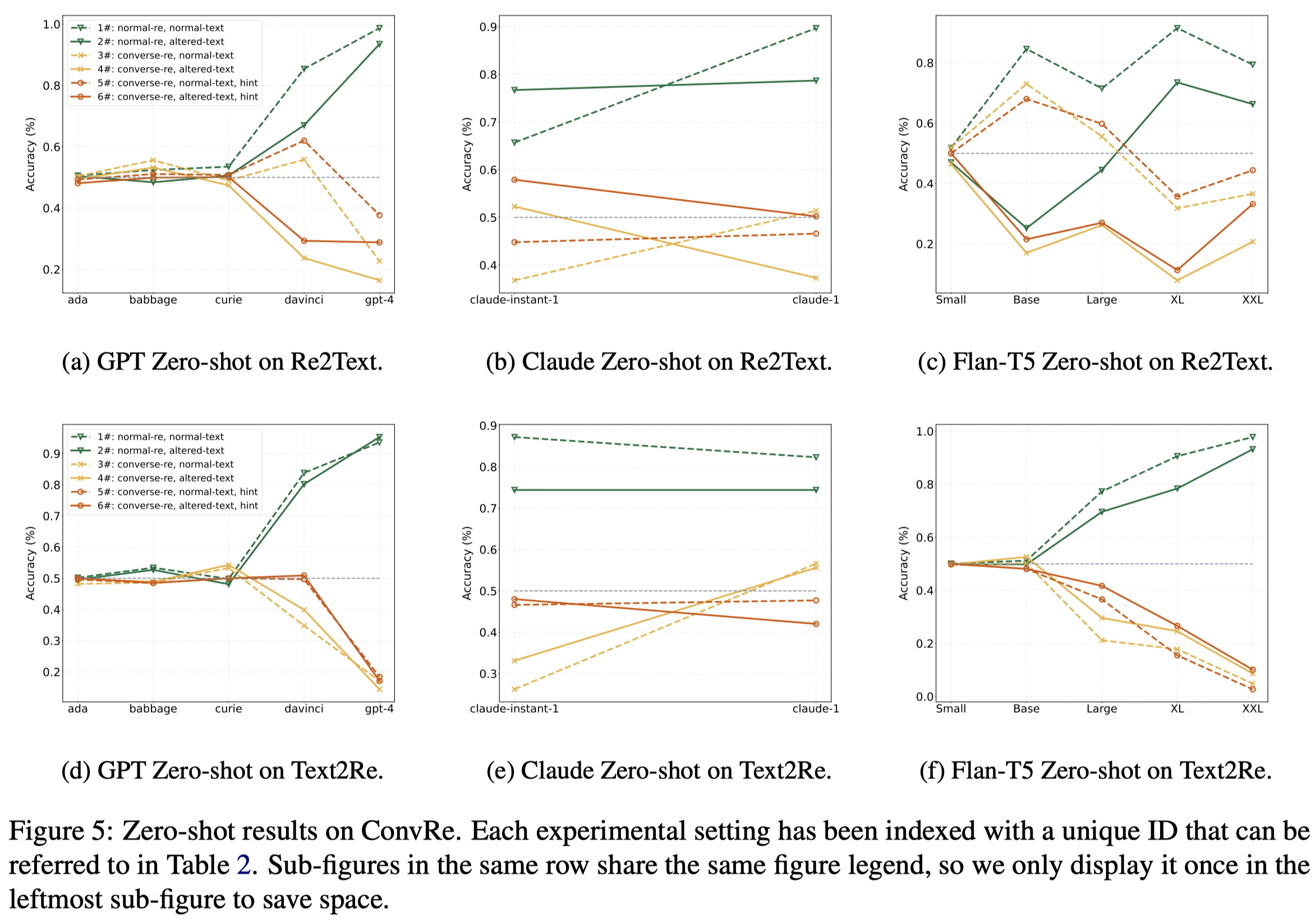
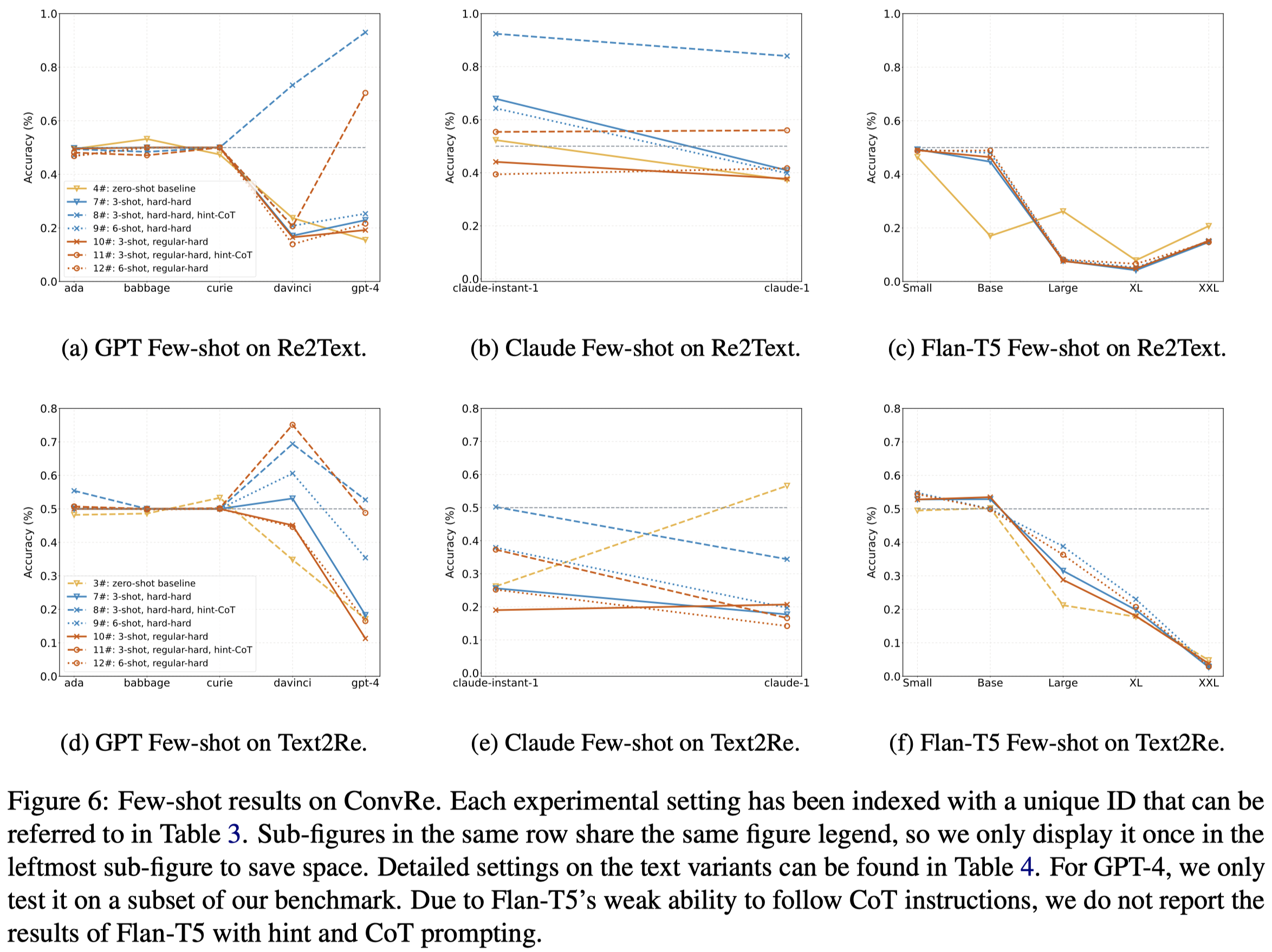
可以看出来,目前最优的GPT-4等模型,对于逆关系的理解甚至不如小模型。更大的model,学习预训练数据效果更好,也更有可能潜在的更倾向于利用捷径。
We conjecture that larger models have stronger priors, causing them to rely more heavily on memorized patterns from training data, which can conflict with the given task.