SEEK
SEEK: Segmented Embedding of Knowledge Graphs
ACL 2020
虽然目前对于KGE的研究已经很多了,但是目前的方法都存在一个问题,简单的方法模型的表达能力不够;复杂的方法参数多,复杂性高,难以应用与实际的大规模的知识图谱。
本文就考虑如何在不增加复杂度的情况下增加模型的表达能力:
- 增加特征之间的交互
- 保存关系的属性——对称性与不对称性
- 设计有效的得分函数
核心方法是将实体和关系的embedding拆分为k个segment。
模型方法:
首先将实体和关系的embedding拆分为k个segment。
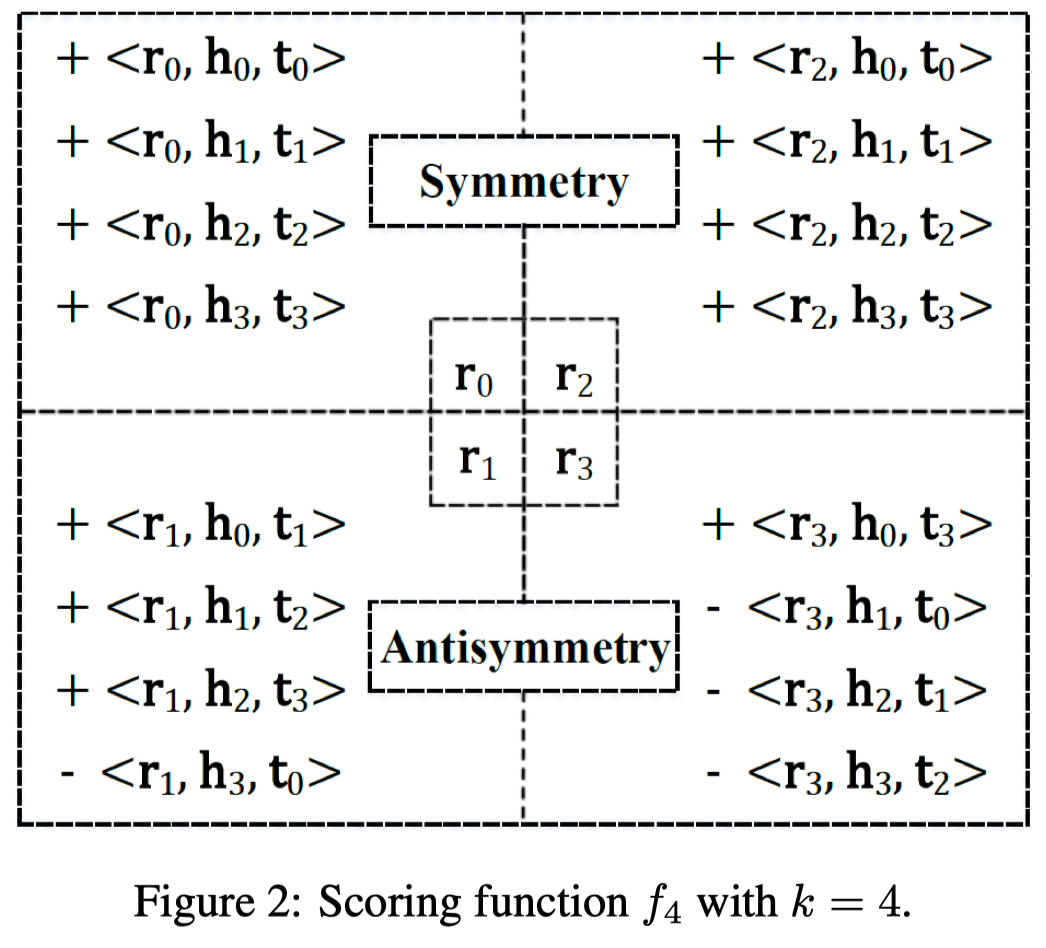
直接看最后的得分函数
\[ f_4(h,r,t)= \sum_{0\leq x,y< k} s_{x,y} \cdot \left \langle r_x, h_y, t_{w_{x,y}} \right \rangle \\ \]
\[ w_{x,y} = \begin{cases} y, & \mbox{if }x\mbox{ is even}, \\ (x+y)\%k, & \mbox{if }x\mbox{ is odd} \end{cases} \]
\[ s_{x,y} = \begin{cases} -1, & \mbox{if }x\mbox{ is odd and } x+y\geq k, \\ 1, & otherwise \end{cases} \\ \] 分析上面的方法,引入\(s_{x,y}\)可以建模关系的对称和不对称性,将\(h\)和\(t\)互换的情况下,\(f_4(h,r,t)\)不一样。
引入\(w_{x,y}\)限制了\(t_{w_{x,y}}\),不再是所有分段的全体组合。
最终实验在FB15K,DB100K,YAGO37三个数据集下进行了实验。