RGHAT
Relational Graph Neural Network with Hierarchical Attention for Knowledge Graph Completion
AAAI 2020
使用了两层注意力,相同关系下的实体的注意力+不同关系的注意力
无开源代码
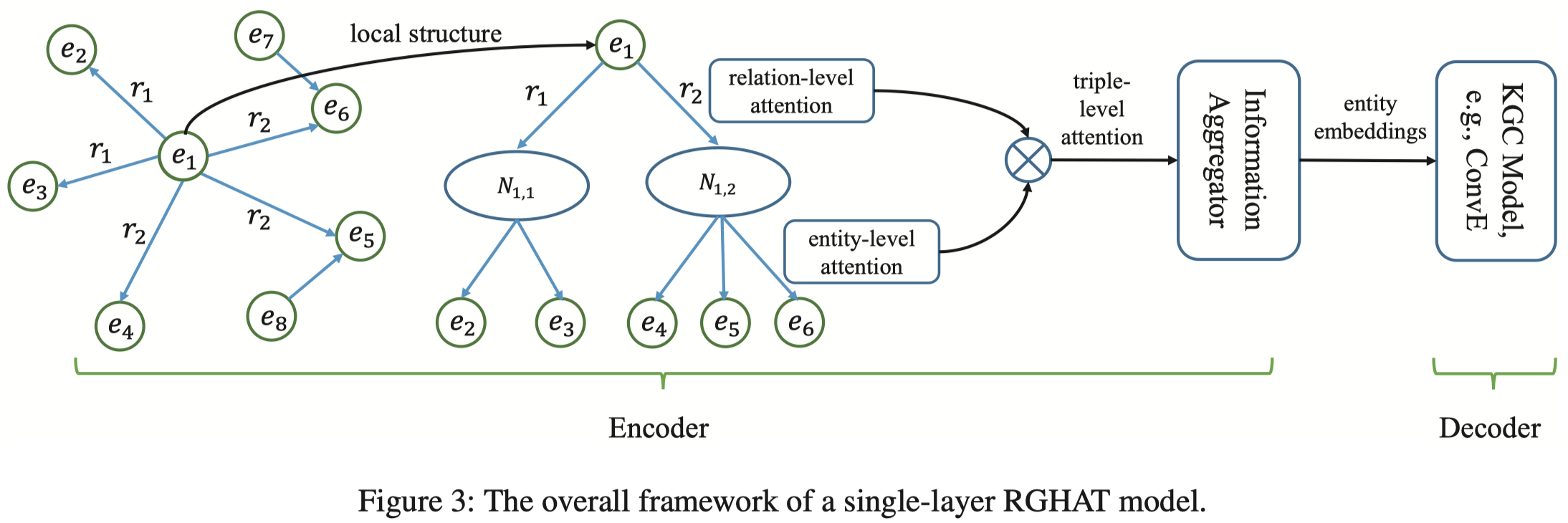
使用了两层的attention,
Relation-level attention \[ \mathcal{a}_{h,r}=W_1[h||v_r] \\ \alpha_{h,r}=softmax_r(\alpha_{h,r})=\frac{exp(\sigma(p\cdot a_{h,r}))}{\sum_{r^\prime\in N_h } exp(\sigma(p\cdot a_{h,r^\prime}))} \] Entity-level attention \[ b_{h,r,t}=W_2[a_{h,r}||t] \\ \beta_{r,t}=softmax_t(b_{h,r,t}) \] 最后计算triple-level attention \[ \mu_{h,r,t}=\alpha_{h,r}\cdot \beta_{r,t} \] 邻居信息的聚合 \[ \hat{h} = \sum_{r\in \cal{N}_{h}} \sum_{t\in \cal{N}_{h,r}} \mu_{h,r,t} b_{h,r,t} \] 与自身信息的聚合 \[ h^\prime = \frac{1}{2} ( \sigma(W_3(h+\hat{h})) + \sigma(W_3(h \odot \hat{h}))) \] 以上就是encoder,decoder是ConvE。
在实践中,
In the training stage, we adopt a two-layer RGHAT
For the encoder, the embedding size of entities is set as 100 for both the input and output layer.
The number of heads for the multi-head attention mechanism is set as 8.
A dropout with the rate as 0.5 is applied to each input layer of the encoder and the normalized attention coefficients following graph attention network.
L2 regularization with λ = 0.0005
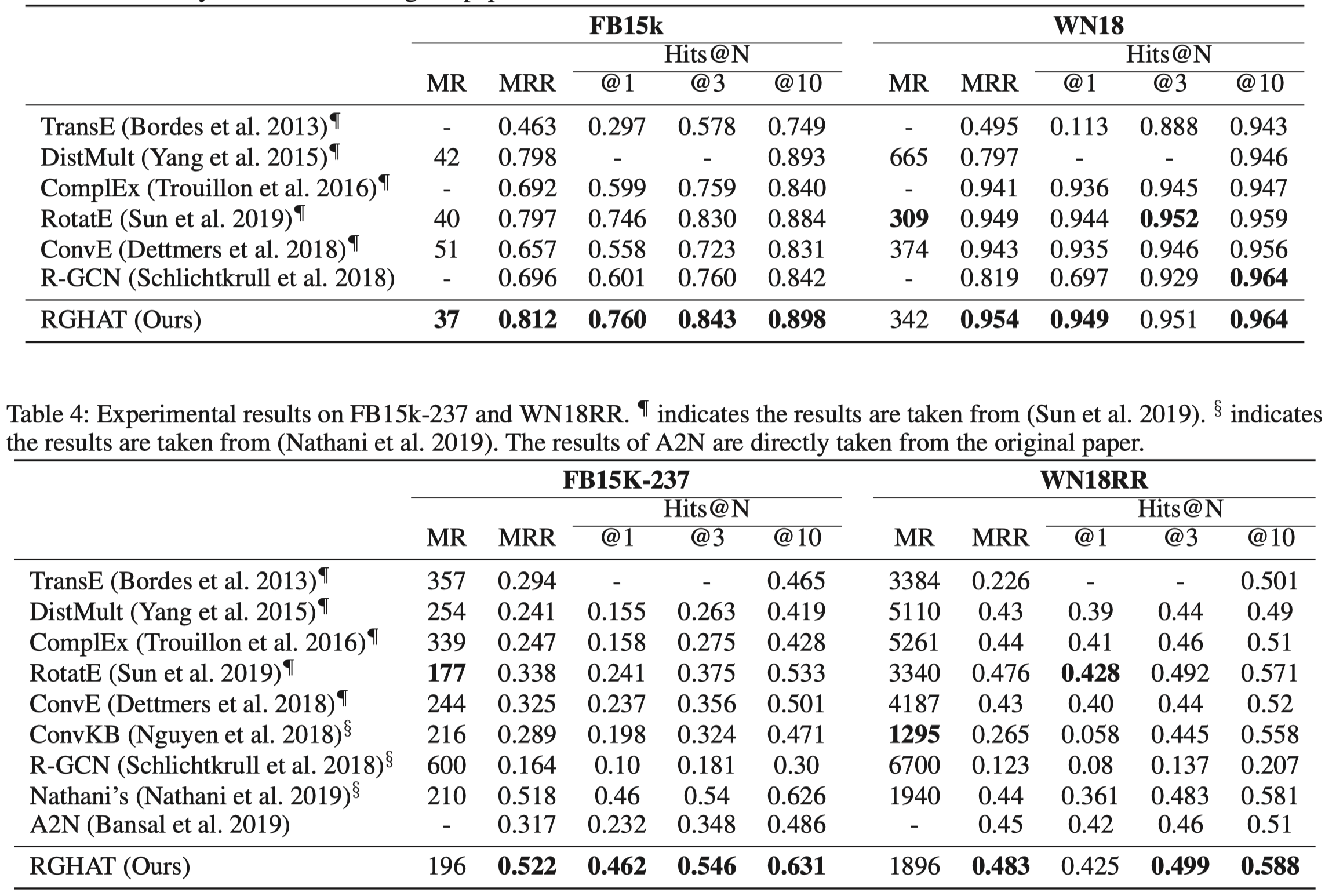
实验效果看起来很漂亮,但是无法复现就无法确定代码是否有正误,特别是在KBGAT存在test data leakage的情况下。