NSCaching
NSCaching: Simple and Efficient Negative Sampling for Knowledge Graph Embedding
ICDE 2019
提出了一种针对KGE的动态负采样方法NSCaching,核心思想是得分高的负样本很重要但是数量少,因此,作者直接使用cache来保存得分高的负样本,同时随着训练动态更新cache,可以看做是基于GAN的负采样方法的distilled版本。
Introduction
motivation:在训练KGE的时候,负样本的质量很重要,也就是说那些越难与正样本区分的负样本可能越重要。high-quality negative triplets should have large scores,因为基于embedding的model实际上对于大多数负样本不敏感,给出的都是比较低的打分。如果使用random采样,采样得到的负样本,激活函数如果是sigmoid函数,那么如果负样本得分在<<0的区间内,那么梯度会很小,造成梯度消失的问题。
下面的图分析了负样本得分与正样本得分差距的情况。红线右侧这一部分是值得训练的负样本。越大的margin表示负样本与正样本越相等,越有训练的价值,随着训练的进行,这一部分的负样本越来越少。
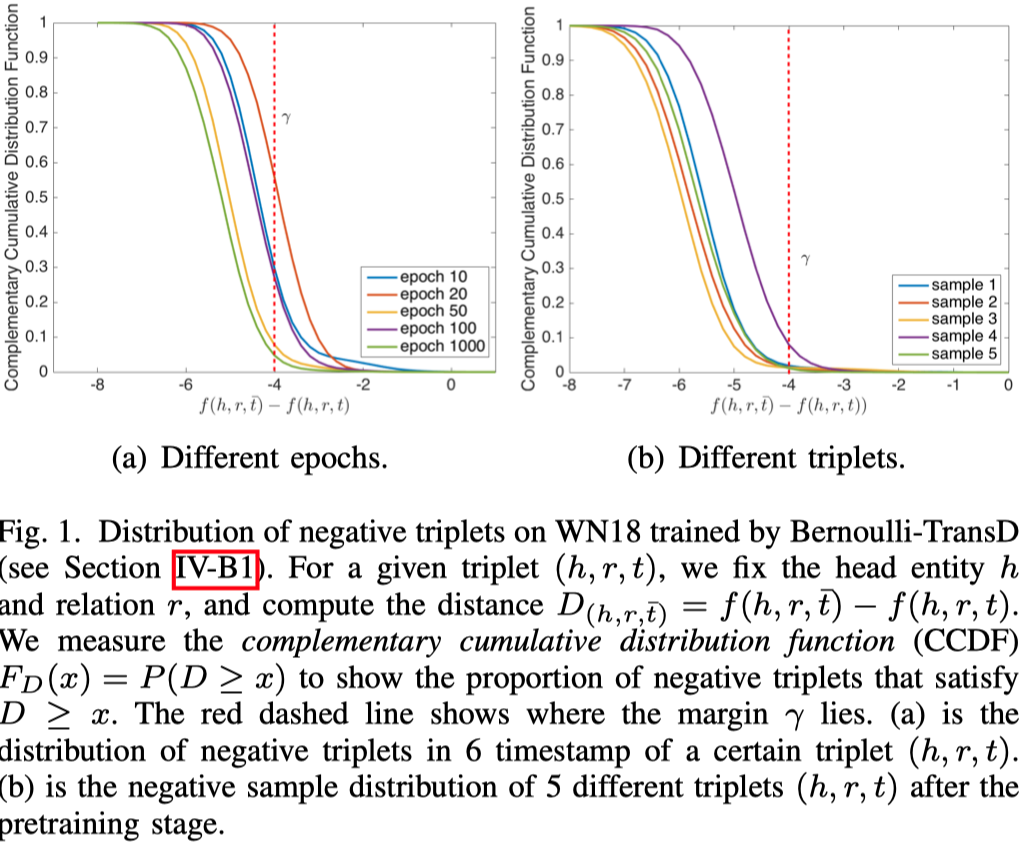
目前有方法比如KBGAN等,尝试使用GAN解决上面的问题,但是GAN首先会引入额外的训练参数;同时GAN的训练存在instability和degeneracy的问题,并且它们可能有更高的variance,导致训练结果更不稳定。
method:高质量的负样本数量并不多,分布上来看是一个很skew的曲线,因此可以使用cache来保存高质量的负样本,同时随着训练,不断更新这些负样本。
Method
方法很直观,为每个head和tail保存高质量负样本cache,负样本的质量用上一步训练的模型对它的预测结果进行衡量。从cache中随机选择head或者tail entity构造负样本。然后用于KGE model进行训练。

step 6和step 8是重点。
Uniform sampling strategy from the cache
由于负样本cache中的实体都能够用来构造高质量负样本,同时因为最大得分的负样本也可能是假阴性样本,因此不应该总是采样最大得分负样本,直接使用Uniform sampling来控制false negative triplets。
Importance sampling strategy to update the cache
对于head cache和tail cache都是使用一样的更新过程。

从所有实体中选择\(N_2\)个实体作为更新候选项并入cache中,然后基于相对重要性采样\(N_1\)个实体作为更新后的cache。
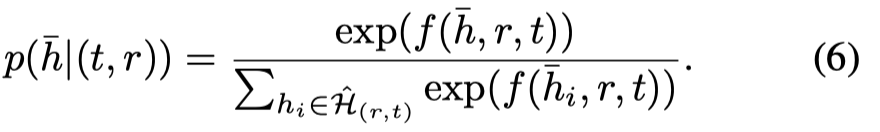
这一步没有总是保留最大得分的\(N_1\)个实体也是为了控制假阴性样本。因为假阴性负样本的存在,总是使用top N最大得分的负样本也不合适。
NSCaching will learn from easy samples first, but then gradually focus on hard ones, which is exactly the principle of self-paced learning
在作者实验中,采用\(N_1=N_2=50\),负样本数量为1。