HAKE
Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction
2019-12-15 AAAI 2020
Hierarchy-Aware Knowledge Graph Embeddings(HAKE)就是不增加额外的信息,利用知识图谱的语义层级建模。
HAKE为了区分所有的实体,将实体嵌入分为两部分:
- 不同的语义层级下的实体,使用极坐标的模长/极径(modulus)表示
- 同一语义层级下的不同实体,使用极坐标的相位/极角(phase)表示
1 Introduction
问题:目前的模型大多没有对于语义层级关系(semantic hierarchy)进行建模
解决方案:引入极坐标系(polar coordinate system),
- 具有更高语义层级的实体具有更小的半径
- 同一语义层级的实体具有不同的角度
知识图谱在是一系列的事实的集合,是语义网络的拓展。
现在的知识图谱可以包含数以亿计的事实(fact),但是知识图谱不可能包含所有实际中存在的事实。因此,链路预测(link prediction)/知识图谱补全(knowledge base completion)成为了研究的一个方向。即如何根据已有的事实,预测可能存在的事实。
受到词嵌入的启发,知识图谱嵌入(knowgraph graph embedding)——将知识图谱映射到离散的表示形式,就成为了研究热点。
- 知识图谱嵌入的应用方向很多,不只是链路预测,还包括实体分类等等。
- 知识图谱嵌入也只是图嵌入的一个方向
- 链路预测对于其它的图(社交网络等),同样成立
之前的知识图嵌入的工作主要集中在建模关系的特性:
- 对称/不对称
- 可逆/不可逆
- 组合
在知识图谱当中存在语义的层级,比如在wordnet知识图谱里,[arbor/cassia/palm, hypernym, tree],tree的语义层级要高于[hypernym, tree]。对于如何利用知识图谱的语义特性的工作较少,并且很多要求要增加额外的信息,例如额外的文本描述,来建模知识图谱的层级关系。
Hierarchy-Aware Knowledge Graph Embeddings(HAKE)就是不增加额外的信息,利用知识图谱的语义层级建模。
HAKE为了区分所有的实体,将实体嵌入分为两部分:
- 不同的语义层级下的实体,使用极坐标的模长/极径(modulus)表示
- 同一语义层级下的不同实体,使用极坐标的相位/极角(phase)表示
2 The Proposed HAKE
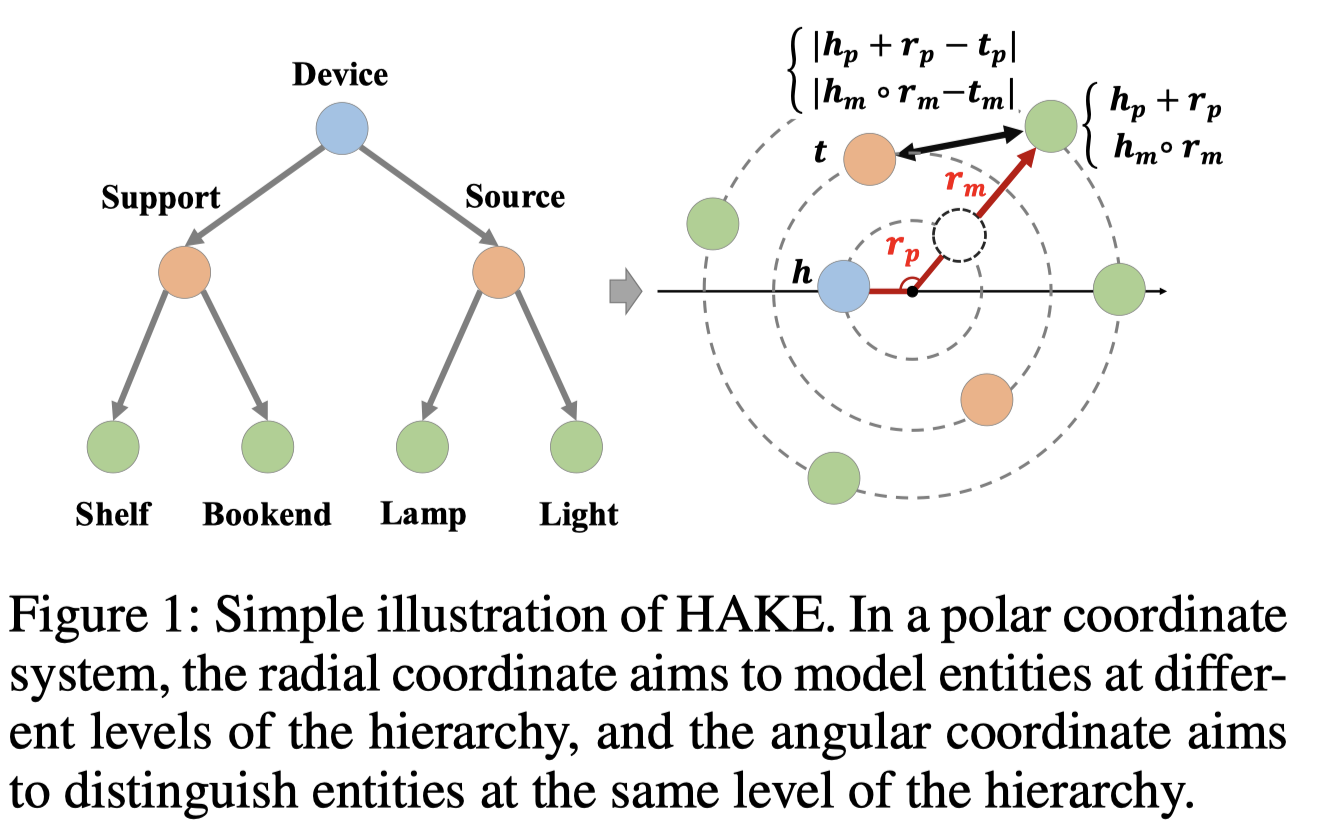
HAKE的模型图:
2.1 The modulus part
极坐标的极径建模实体的语义层级。
知识图谱中的实体可以组成一棵树,越往上的实体语义层级越高,越往下的语义层级越低。使用模量/极径表示实体在语义树中的深度,具有越高的语义层级的实体有更小的深度,更小的模量。
使用\(e_m\)表示嵌入的模量部分modulus part,则有: \[ h_m\circ r_m=t_m,\ where\ h_m,\ t_m\in R^k,\ r_m \in R^k_{+} \] 距离函数为: \[ d_{r,m}(h_m, t_m)=||h_m\circ r_m - t_m||_2 \] 要注意这里限制了\(r_m\)必须在正数域下,这是因为正数的\(r_m\)不会改变\(h_m\)的符号,这是因为对于正样本\((h,r,t)\),\(h_m\)与\(t_m\)倾向于有相同的符号,\[d_{r,m}(h_m,t_m)\]更小,而负样本\((h,r,t^{'})\)更难保证同一纬度下的\(h_m\)与\(t_m\)倾向有相同的符号,导致\(d_{r,m}(h_m,t_m^{'})\)更大。
这样的\(r_m\)成为了一个缩放操作,对于\((h,r,t)\),
- 如果h的层级比t更大,r倾向于>1
- 如果h的层级与t一样,r倾向于=1
- 如果h的层级比t更小,r倾向于<1
2.2 The phase part
进一步区分同一层级下的不同实体。
使用\(e_p\)表示相位部分, \[ (h_p+r_p)\ mod\ 2\pi = t_p,\ where\ h_p,t_p,r_p\in [0, 2\pi)^k \] 距离函数: \[ d_{r,p}(h_p,t_p)=|| \sin{((h_p + r_p - t_p)/2)} ||_1 \] 除以2是保证\((h_p + r_p - t_p)/2\in [0, 2\pi)^k\),上面的式子和pRotatE中的一样。
2.3 Loss Function
经过上面的两部分,获得总的嵌入: \[ e=[e_m;e_p] \] 之后计算\((h,r,t)\)存在概率的得分: \[ f_r(h,t)=-(d_{r,m}(h,t)+\lambda d_{r,p}(h,t)) \] 使用负采样的损失函数: \[ L=-log\sigma(\gamma-f_r(h,t))-\sum_{i=1}^n p(h^{'}_i, r, t^{'}_i) log\sigma(f_r(h^{'}_i,t^{'}_i)-\gamma) \\ p(h^{'}_j, r, t^{'}_j) =\frac{exp\alpha f_r(h^{'}_j, t^{'}_j)}{\sum_i f_r(h^{'}_i, t^{'}_i)} \]
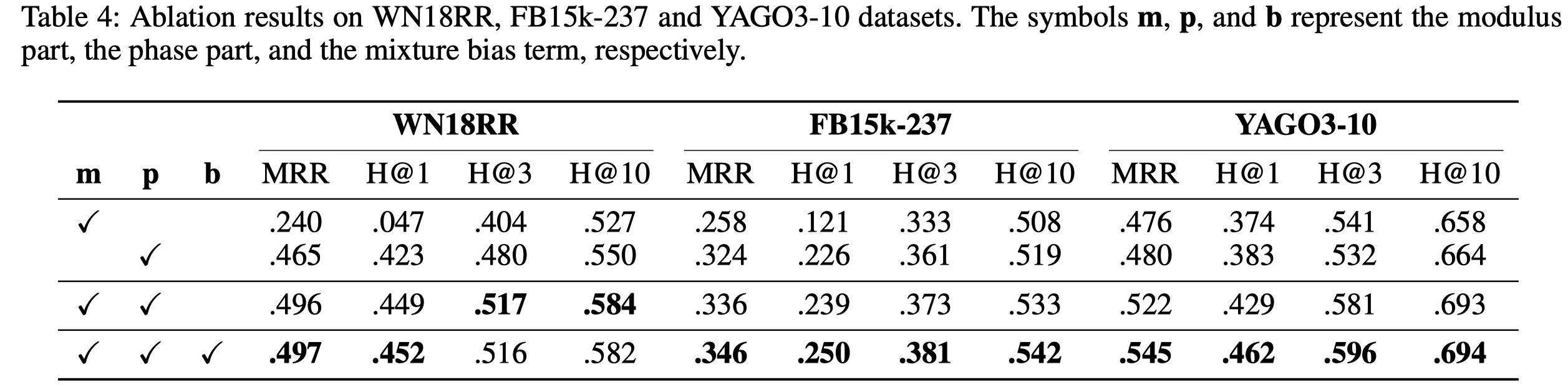
3 Experiments and Analysis
3.1 Main Results
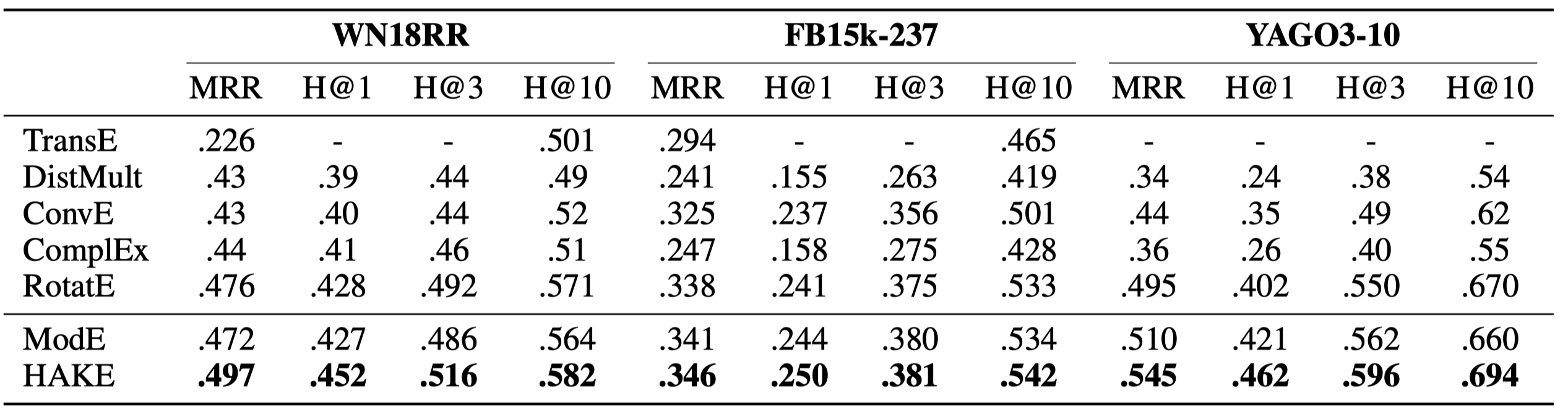
三个数据集:WN18RR, FB15k-237, YAGO3-10
为了说明phase part部分的作用,只保留modulus part,作为模型ModE: \[ d_{r,m}(h_m, t_m)=||h_m\circ r_m - t_m||_2\ where\ h_m,\ t_m\ r_m \in R^k \]
3.2 Analysis on Relation Embeddings
首先,说明HAKE能否捕获不同语义层级的信息。
只使用modulus part,下图是表示不同语义层级的关系embedding的直方图,横轴是大小,纵轴是密度
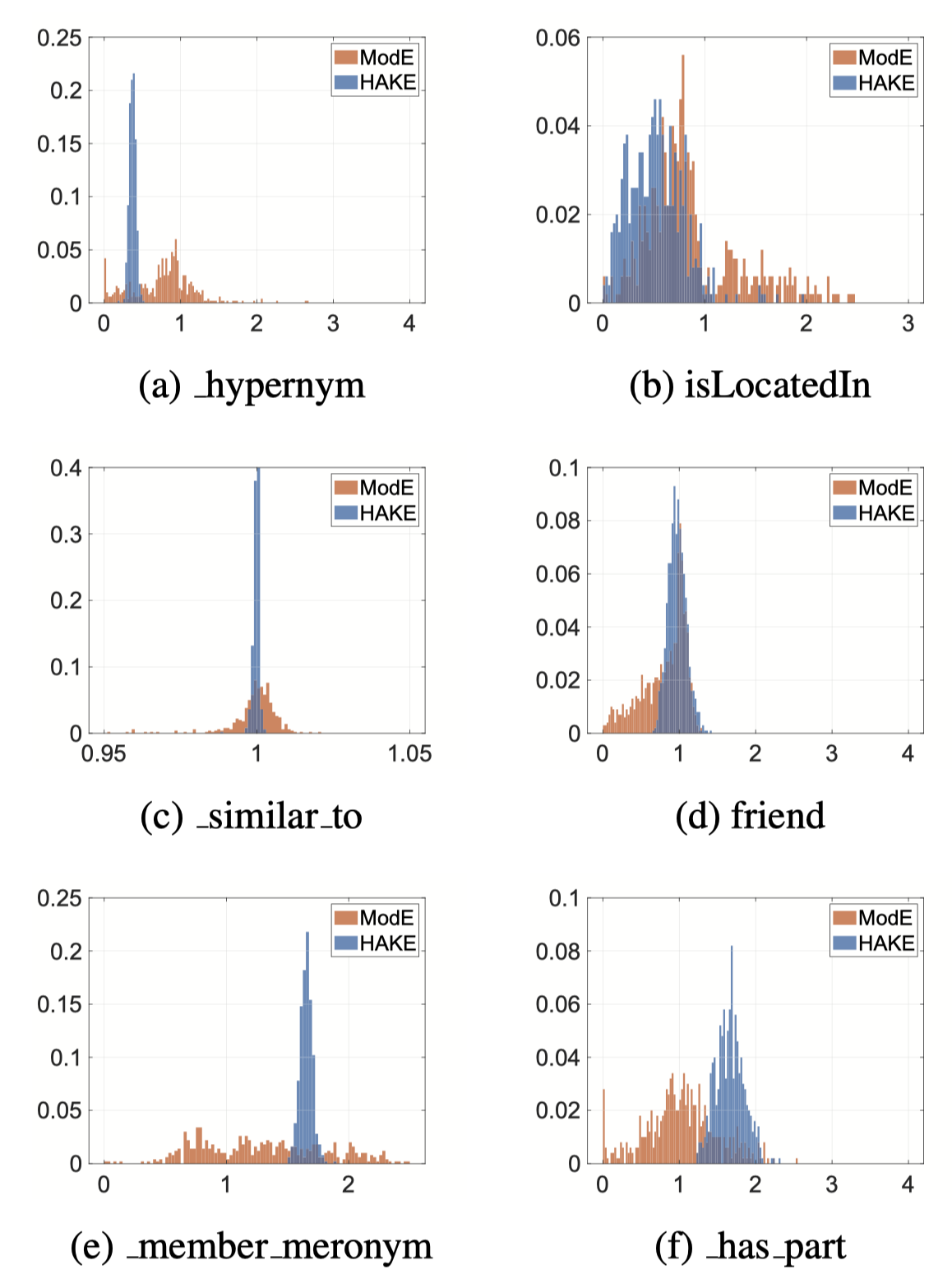
其中,
- a和b是尾实体比头实体的关系语义层级高,结果显示关系embedding大部分元素<1
- c和d是尾实体比头实体的关系语义层级一样,结果显示关系embedding大部分元素=1
- e和f是尾实体比头实体的关系语义层级低,结果显示关系embedding大部分元素>1
同样可以看出HAKE比ModE的方差更小,说明HAKE的建模更准确。
之后,说明phase part的作用,比较c和d的关系embedding的phase part

上述结果说明有很多关系嵌入的phase part元素分布在\(\pi\),导致\(h_p\)和\(t_p\)不一样,可以区分同一语义层级的不同实体。
3.3 Analysis on Entity Embeddings
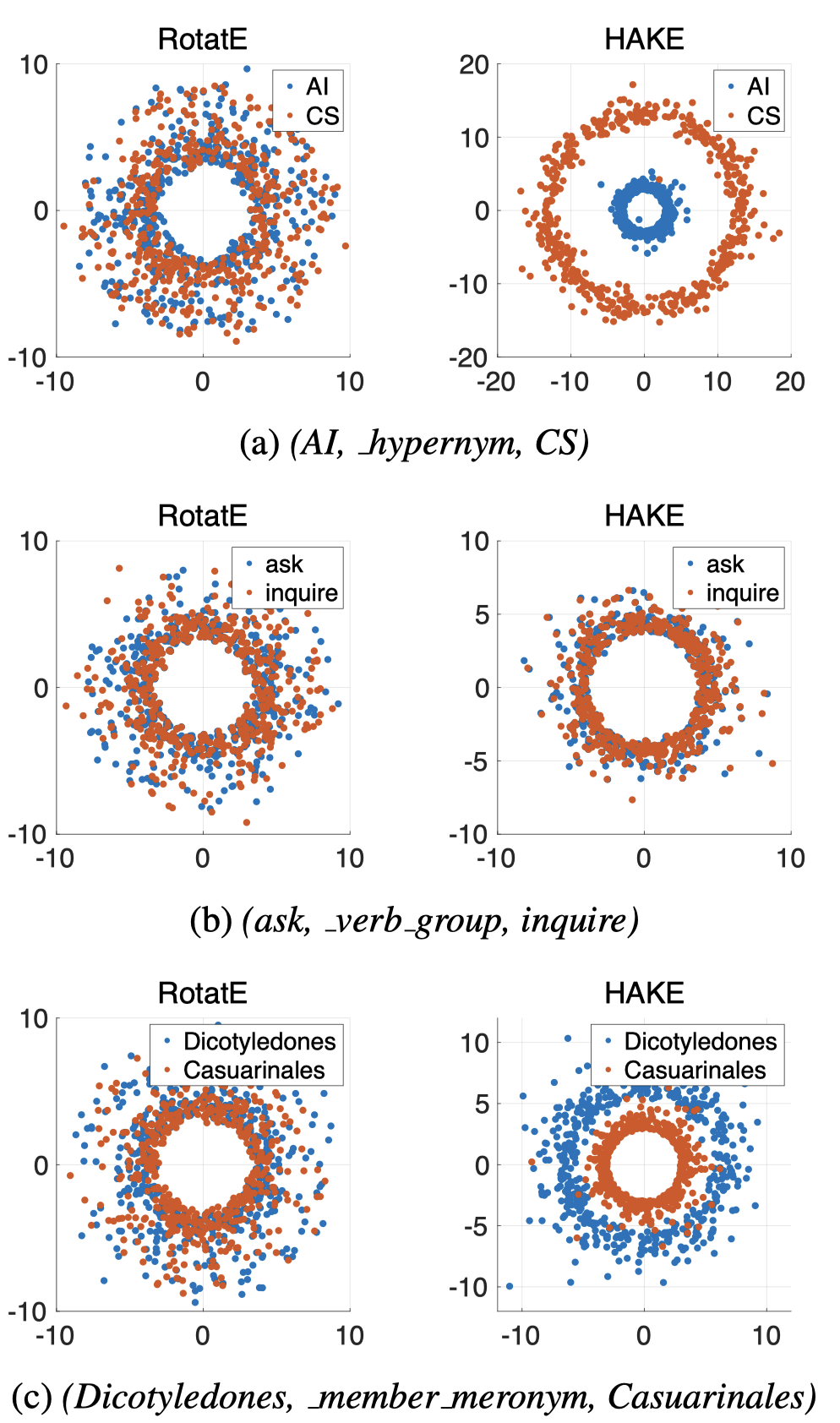
因为是使用极坐标来表示语义层级,可以把实体embedding在极坐标中可视化。
实体embedding大小为1000,选500个维度画在二维极坐标中,对原始的极径使用对数函数,来更好的展示结果。由于所有模的值都小于1,因此在图中,更大的直径表示更小的模值,即更高的语义层级。
图中显示的结果说明HAKE比RotatE能够更好的捕获层级关系。
3.4 Ablation Studies