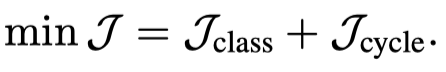HetSANN
An Attention-based Graph Neural Network for Heterogeneous Structural Learning
HetSANN,AAAI 2020
提出了Heterogeneous Graph Structural Attention Neural Network (HetSANN),主要创新点有三个:
- 对于预测标签任务,采用多任务学习,不同type的节点进行预测有不同的classifier(实际是全连接层+softmax)
- 针对edge和reversed edge,除了一般的基于拼接的方法计算attention外,提出了voice-sharing product的计算注意力方法。
- 在不同type的邻居信息转换中,提出了一个保持weight matrix的cycle consistent的方法。
Introduction
作者认为如果使用基于meta-path的方法有以下缺点
- meta-path的选择依赖于专家,并且需要手动设计
- 在meta-path中间的节点和边的信息被忽略。
Method
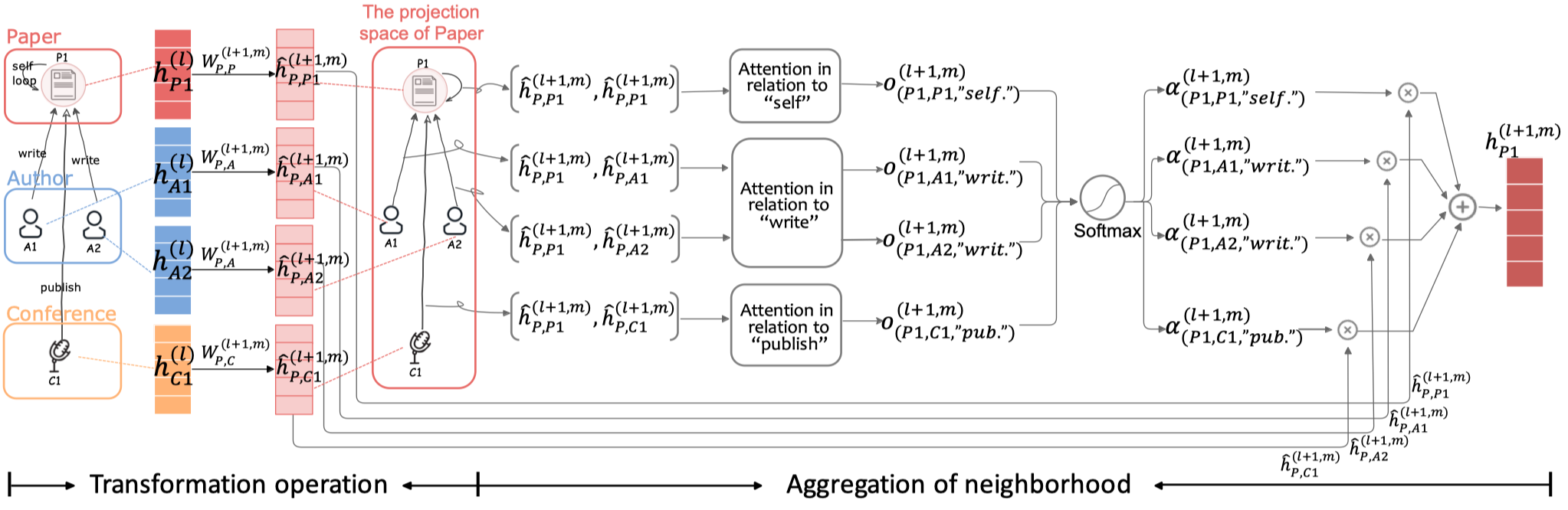
看一下模型的整体结构:
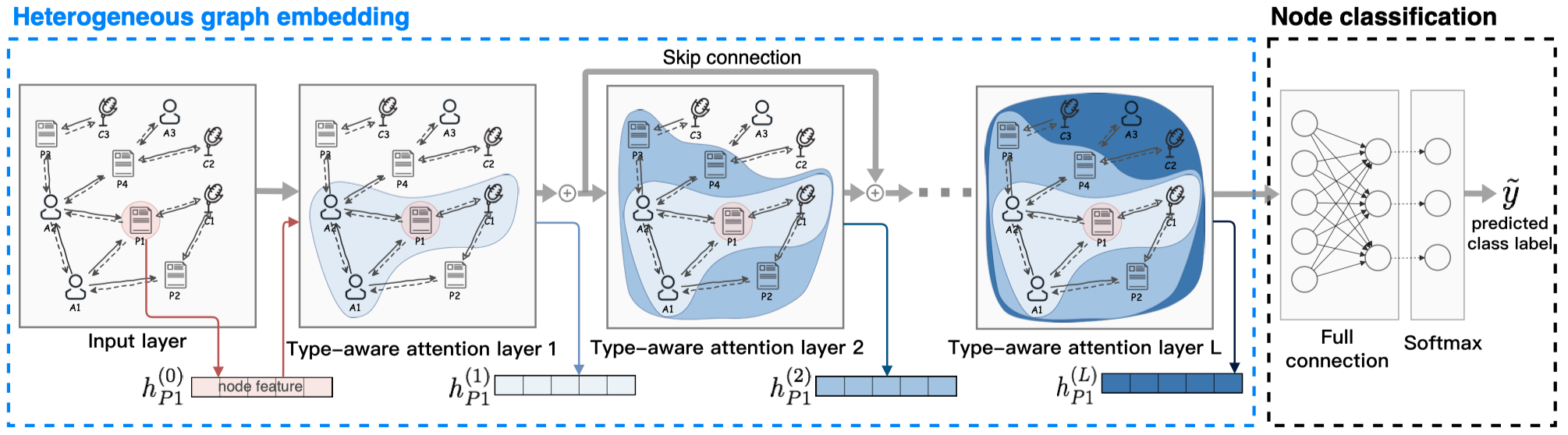
Type-aware Attention Layer (TAL)
采用多头注意力(一般是8个头)
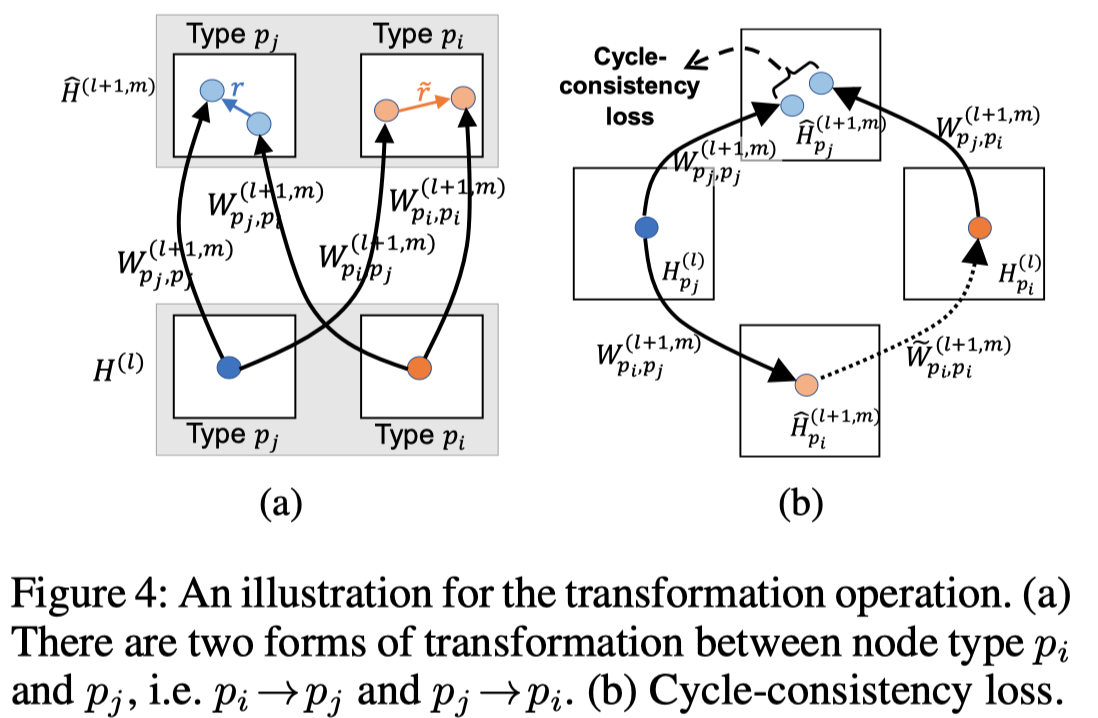
首先是基于type的邻居信息转化,node \(i\) 提供给node \(j\)。
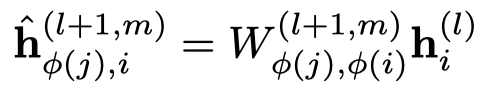
注意,这里的\(W\)是根据中心node和邻居node的type同时区分的。
然后基于注意力聚合邻居信息,下面的是一般的GAT的方法,作者叫做concat product。
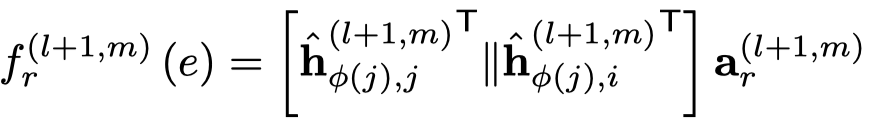
需要注意的是,这里的注意力向量\(\alpha_r\),是每个edge type各有一个。然后就是基于softmax的attention聚合。
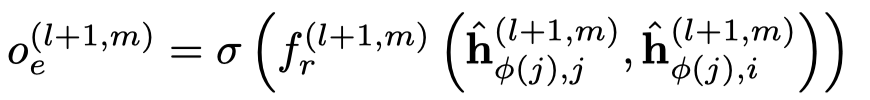
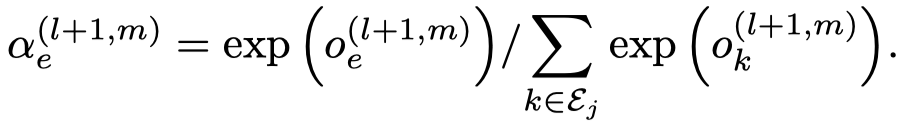
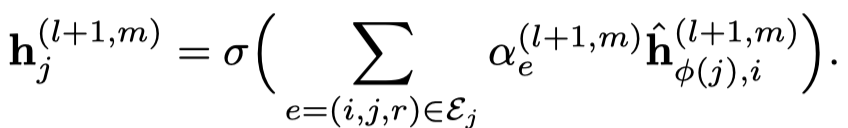
实际上,作者还提出了voice-sharing的注意力计算方法,主要是希望考虑关系和逆关系之间的对应联系。让注意力向量\(\alpha_r\)互为负数,然后利用相加计算注意力。
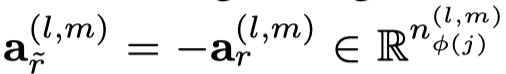
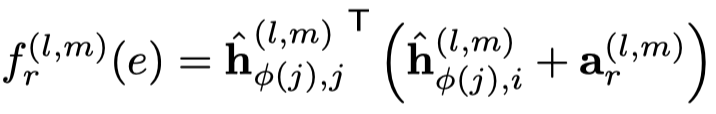
作者起名叫voice-sharing是因为以下的原因:
The voice is the concept of English grammar including active voice and passive voice. Here we refer the active voice to the directed edge (cite, write, etc.) and refer the passive voice to the reversed edge (cited, written, etc.).
最后的输出,就是多头注意力拼接+残差
整个TAL层如图所示。
Multi-task Learning
对于不同type node的预测,定义了不同的output layer(一个全连接层)和softmax。但是gnn的参数是一样的。
Cycle-consistency Loss
这一点很有意思,作者认为对于node的状态转化可以形成一个循环:
从中心节点node \(j\)出发,有一个self-loop,作者认为self-loop之后的状态应该和从\(j\rightarrow i,\ i\rightarrow i,\ i\rightarrow j\)的循环一样。即下面的式子:
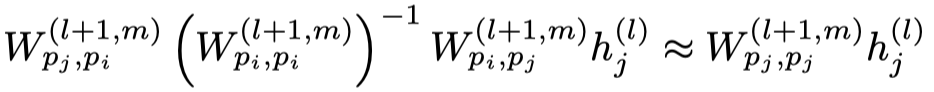
由于matrix的逆矩阵比较难算,作者直接定义了一个新的逆矩阵
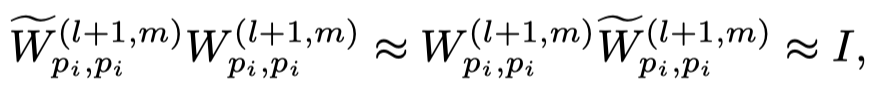
最后,上面的两个约束体现在loss中:
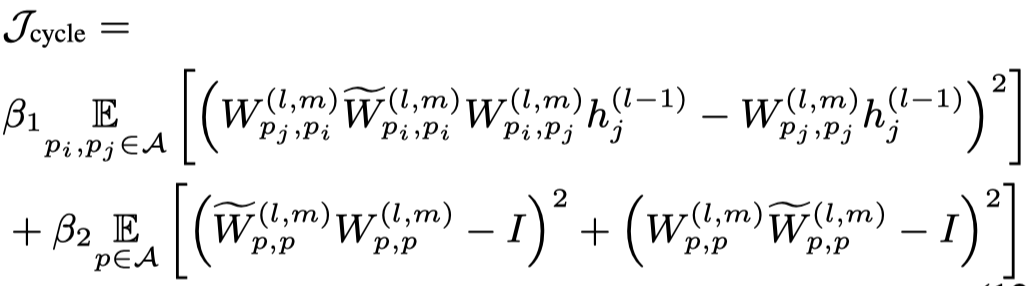
最终的loss: