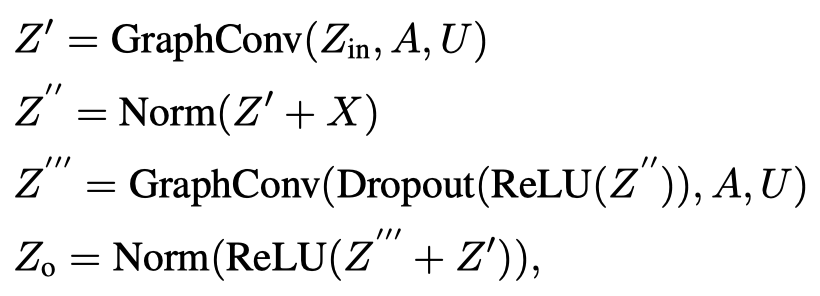GNN-1000-layers
Training Graph Neural Networks with 1000 Layers
ICML 2021
这篇文章通过在GNN中引入grouped reversible connections,实现了将GNN拓展到1000层,可能是当前最深的GNN之一。这篇文章的意义在于,实现了GNN的层数与模型所需的显存无关,使用较少的显存就可以在显存基本不增加的情况下,任意增加GNN深度。
下图是作者提出的Rev-GNN在ogbn-proteins数据集上的结果,很少的memory,达到了很好的效果。
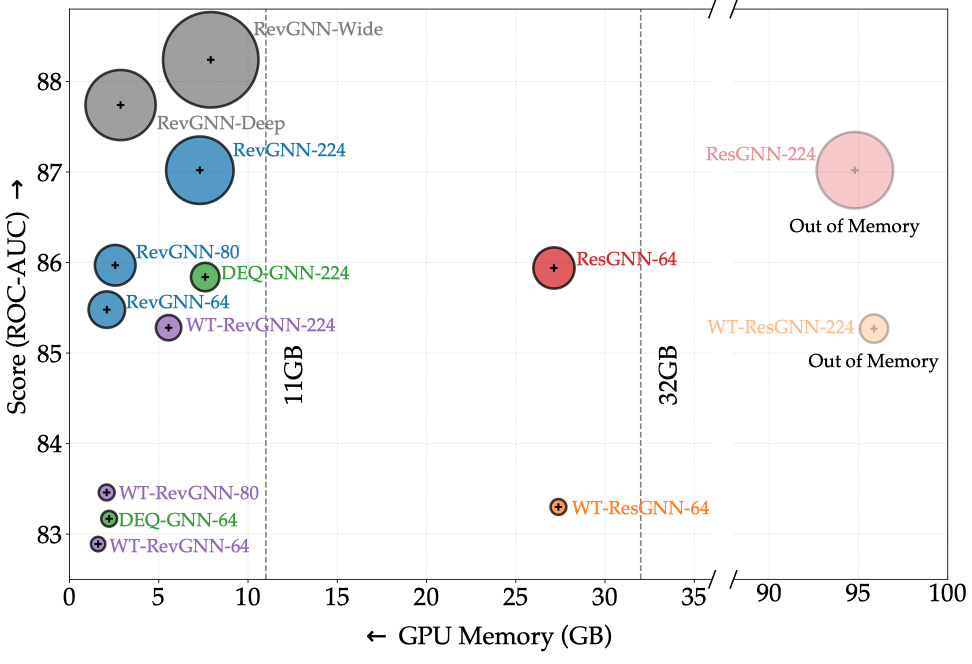
看一下作者的核心思路,在一层的GNN中的grouped reversible connections。首先,将输入划分的节点特征矩阵\(X\in \mathbb{R}^{N\times D}\)随机划分为不同的group:
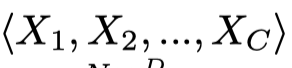
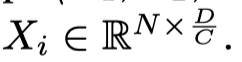
然后作者基于划分好的group产生新的输出:
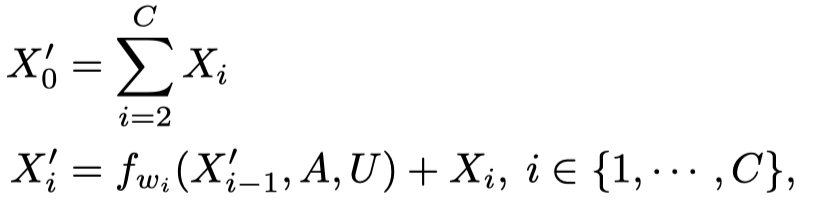
上面的式子里,\(f_{w_i}\)表示是图卷积操作。注意这里的输出\(X_i^\prime\),除了\(X_1^\prime\)依赖于\(X_0^\prime\)外,其它的\(X_i^\prime\)都是由前一个的\(X_{i-1}^\prime\)推出的。
这样做的好处是,可以通过输出直接推导出输入。比如用在backwards过程中:
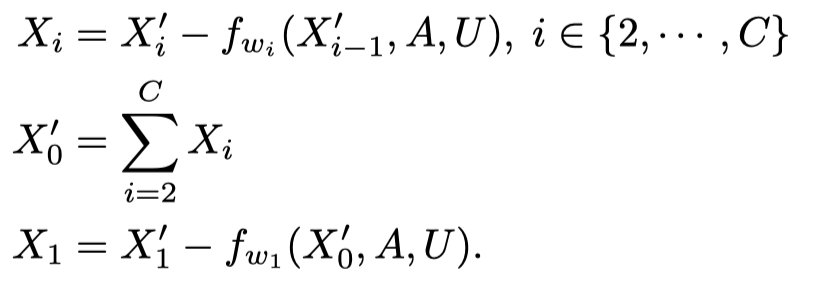
因此,在作者的RevGNN中,只需要保留最后一个GNN层的输出即可,前面所有层的中间状态都可以反向求出。从这里也可以看出来,\(X_0^\prime\)之所以不从group 1开始累加,就是为了后续能够反向重构输入。否则的话,在后续重构\(X_1^\prime\),需要提前知道\(X_0^\prime\),但是想知道\(X_0^\prime\)又需要知道\(X_1^\prime\),成为了死锁。
另外,作者提到了需要normalization layers和dropout layers:
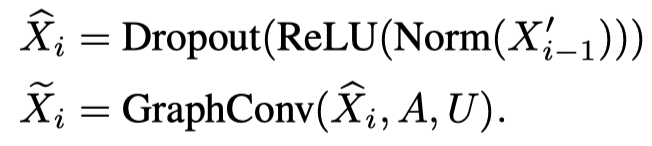
dropout操作会影响重构输入,如果每层dropout都不一样,backward的时候,每层都需要提前保存dropout,因此作者直接让所有层都是保持一样的dropout设置。
以上就是作者的核心思想,同时作者还做了两个拓展:
- Weight-tied GNNs.
意思是让每一层的参数量都固定一样,这样来减小模型参数量。实验结果发现性能并不如每层都有自己的参数的模型,训练速度也差不多一样,优点就是参数量减小。
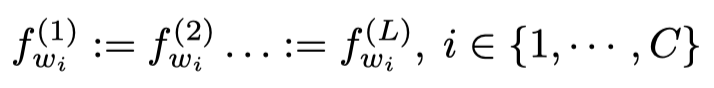
- Deep Equilibrium GNNs
使用implicit differentiation的方法来训练Weight-tied GNN,好处是训练比较快。这一部分没有特别理解,但是大概意思是通过不断的迭代,最终模型能够达到某个平衡点。