ResNet
Deep Residual Learning for Image Recognition
深度残差网络,将CNN拓展到152层乃至更深层,同时表现出更好效果的里程碑文章。核心是将residual connection代入到深层CNN中,使得深层的模型效果不比浅层的模型效果差。

Introduction
Problem
作者认为在CNN中,搭建deep的model能够捕获更高level的特征,最后表现出更好的效果。但是如果model越来越深,导致的问题就是可能出现梯度消失或者梯度爆炸的问题。这个问题被初始值正则化和正则化层所解决。
但是没有解决另外的一个问题,那就是深度的model效果比浅层的model效果还要差,出现了degradation问题,如图所示。

Solution
作者提出,理论上来看,一个更深的模型不应该比一个浅层的模型效果差。因为一个深层的模型,如果所有深的layer的操作都是identity mapping,即什么都不做,那么效果至少应该和浅层的模型效果相近。
但实际不是这样,因为单纯的非线性层,可能比较难训练出这样的identity mapping。虽然理论上多层感知器都能够逼近任意的函数,但是学习的困难程度可能是不一样的,可能需要某种人为的引导降低训练难度。
因此,作者提出对于深层,不再直接学习理想的映射\(\mathcal{H}(\mathbf{x})\),\(\mathbf{x}\)表示浅层的输出,而是让深层学习理想的映射\(\mathcal{H}(\mathbf{x})\)减去\(\mathbf{x}\)之后的残差\(\mathcal{F}(\mathbf{x})\): \[ \mathcal{F}(\mathbf{x})=\mathcal{H}(\mathbf{x})-\mathbf{x} \] 这样,就可以反向获得\(\mathcal{H}(\mathbf{x})\),让\(\mathcal{H}(\mathbf{x})\)再输入到后续的层级 \[ \mathcal{H}(\mathbf{x}) = \mathcal{F}(\mathbf{x})+\mathbf{x} \] 也就是下面的图:
这里作者使用了一个shortcut connection,这并不是什么特别的操作,比如之前在Highway network中,也有shortcut connection,但是Highway network中的shortcut connection是gate-based,本身是有自己的参数的。
但是作者定义这个shortcut connection是一个identity mapping:如果channel相同,直接相加;如果channel不同,可以通过1x1卷积或者padding 0或者线性转换,之后再相加。
Explanation
为什么ResNet能够训练深层的模型,最后效果更好呢?作者在原论文中没有提出详细的说明和解释,下面是李沐大神的课程中的解释,主要是因为能够更好的传递梯度:

可以看到,上面的式子中,原来的梯度是链式的相乘,后面的梯度额外增加了一个之前浅层\(\mathcal{g}{(\mathbf{x})}\)对\(\mathbf{x}\)的梯度,这样最后计算得到的梯度更大。因为一般情况下得到的梯度都是在0左右绝对值较小的值。
Deep Residual Learning
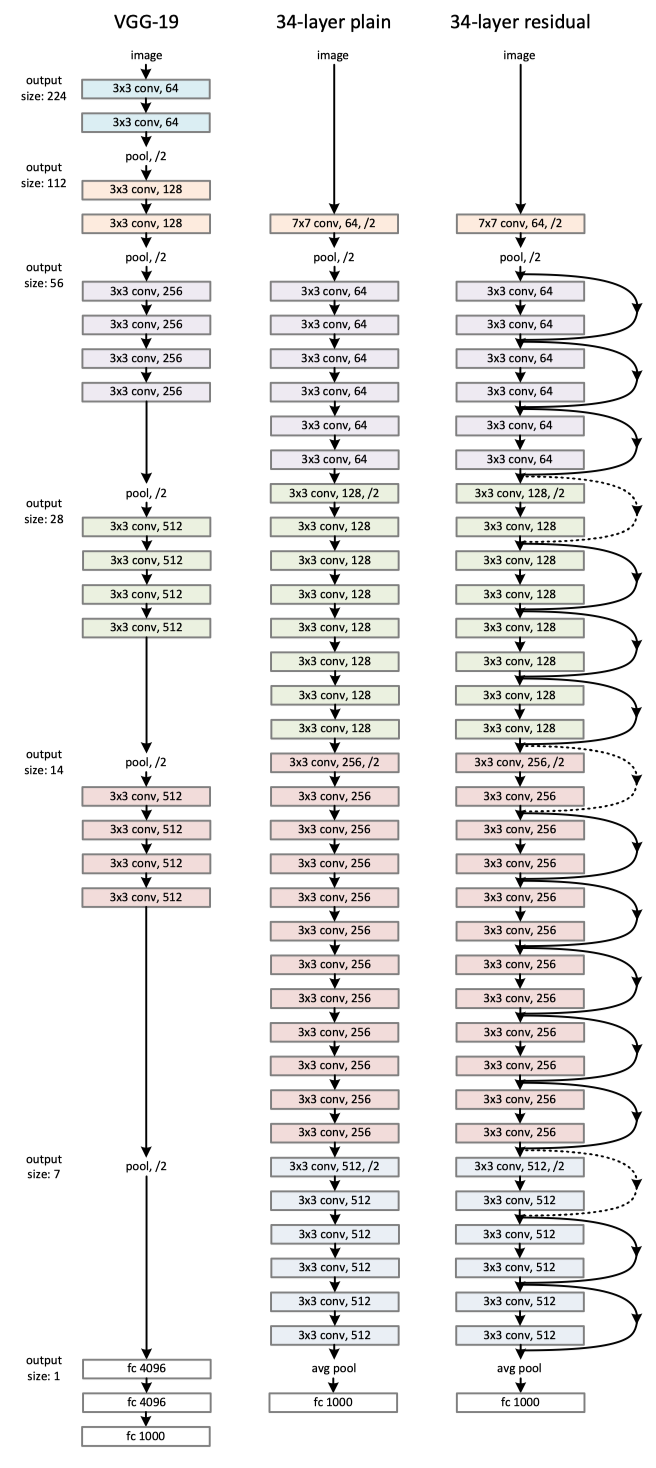
先来看一下ResNet的结构细节:
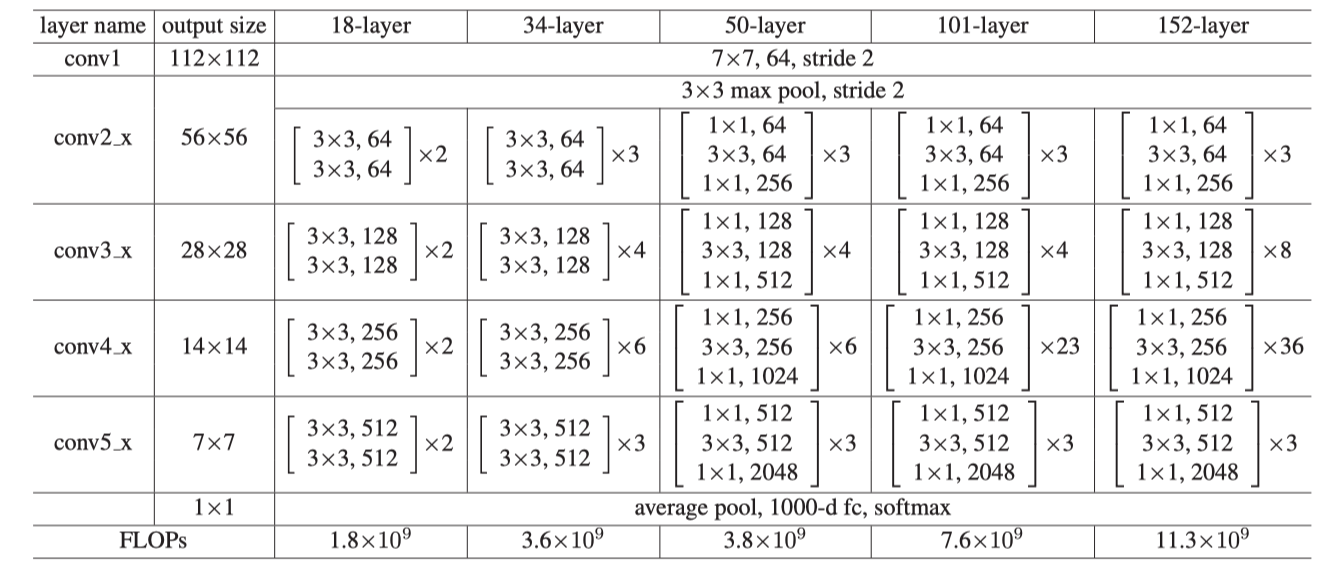
这里需要注意的一点是,ResNet在layer到了50层的时候,每一层使用了bottleneck的设计,先使用1X1的卷积压缩通道数,然后再3X3卷积,最后再1X1卷积回来,目的是为了减小运算复杂度:

最后直接看一下模型结构图: