hypernetworks-collection
Collection of Hypernetworks Papers
调研hypernetwork相关文章
- Dynamic Convlutional Layer(CVPR 2015)
- SRCNN(ICCV 2015)
- DFN(NIPS 2016)
- HyperNetworks(ICLR 2017)
- Nachmani et al. (arxiv 2020)
- Hyper-CNN(arxiv 2021)
- HyperSeg(CVPR 2021)
- LGNN(IJCAI 2021)
Dynamic Convlutional Layer
A Dynamic Convolutional Layer for Short Range Weather Prediction CVPR 2015
针对短时天气预测任务,这个任务会接收一个时序的图像数据,然后预测新的天气图像。构造了一个动态卷积层,对于当前的天气图像要使用的卷积参数,该参数由前面时序的图像输入生成。
模型的整体结构,DC表示动态卷积层,Network B就是用来生成卷积核的网络,同样是一个卷积网络。Network B的输出是两个,垂直卷积核V和水平卷积核H,经过softmax得到SV1和SH1。最后的CROP是一个裁剪层crop layer,只取DC2输出的中心patch。
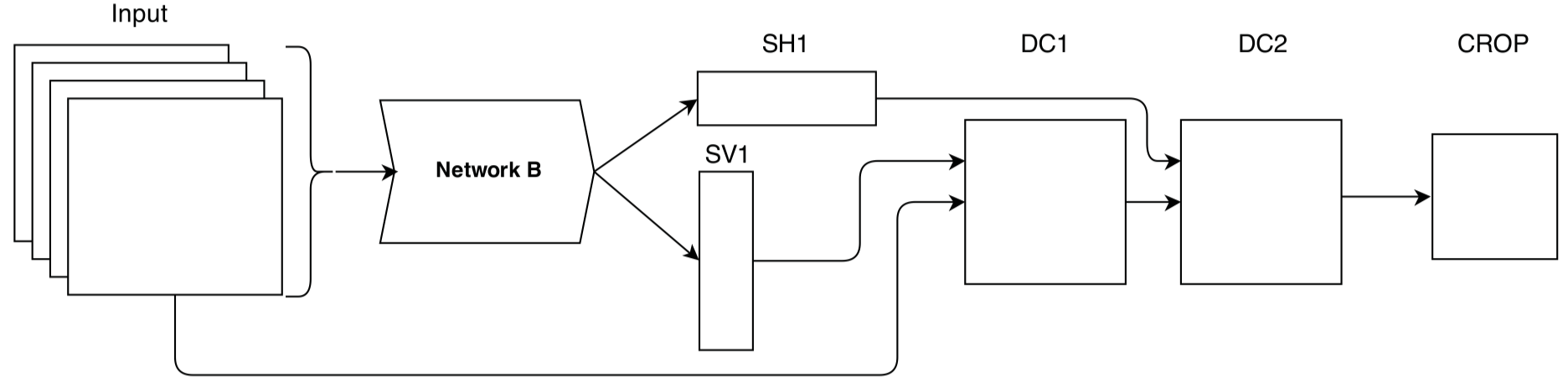
产生卷积核的network B结构:
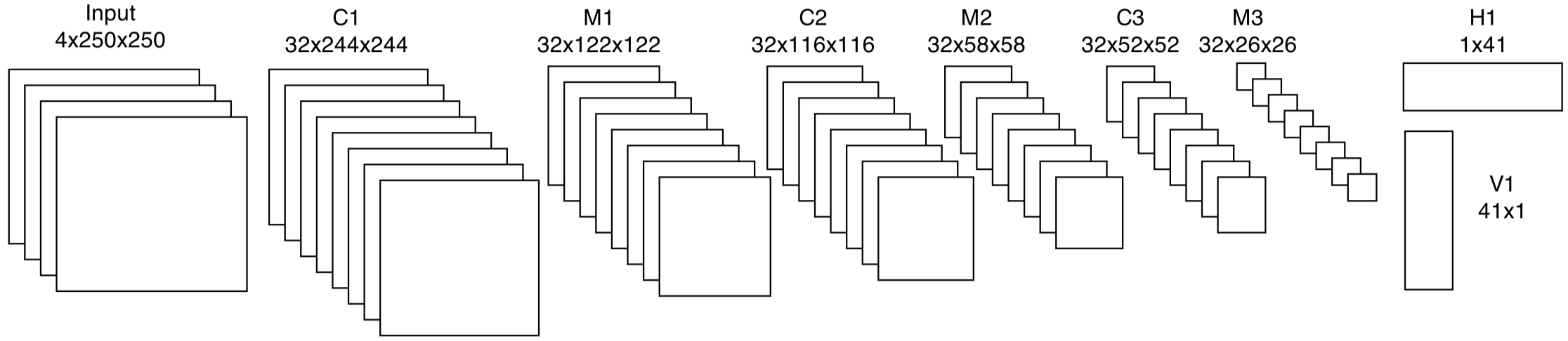
SRCNN
Conditioned Regression Models for Non-Blind Single Image Super-Resolution ICCV 2015
针对Single image super-resolution(SISR)任务,它接收一个低分率的图像\(l\),输出高分辨率图像\(h\)。作者认为在还原为高分辨率的图片时,对于不同的图片,应该是有不同的blur kernel,而不是让blur kernel在训练和测试过程中一直固定。
作者为每个image都定义了一个额外的blur kernel,然后使用生成参数的方法生成新的blur 卷积核。SRCNN的示例图。
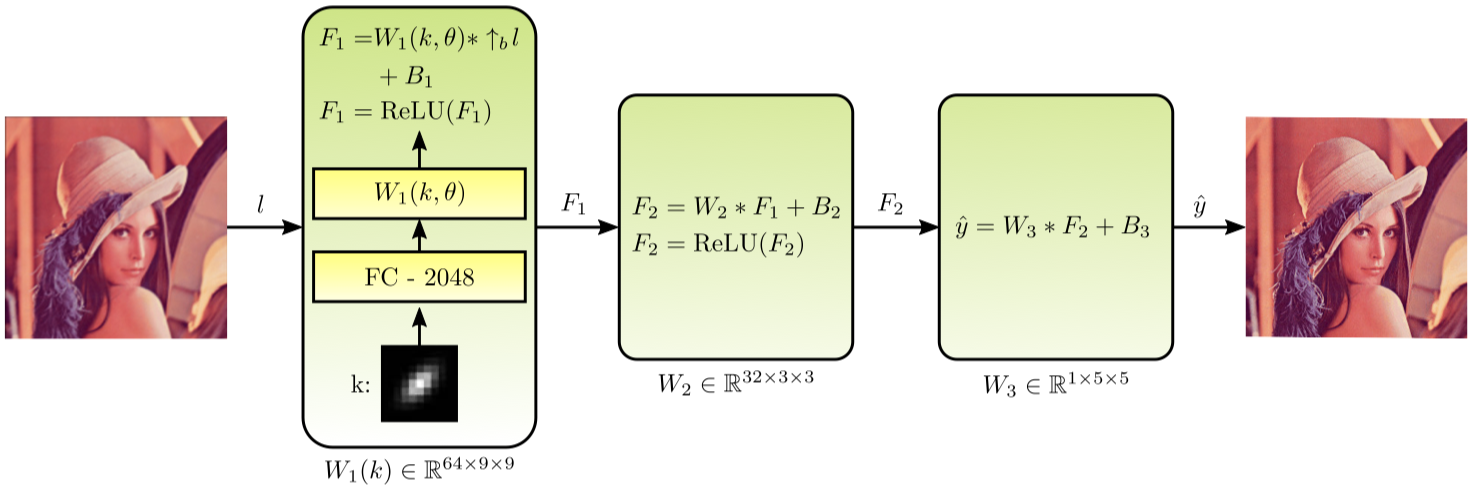
图片中的\(W_{1}(k,\theta)\)就是生成的blur kernels,生成方式就是简单的全连接层。
DFN
Dynamic Filter Networks NIPS 2016
作者在video and stereo prediction任务上进行实验,使用一个filter-generating network生成参数,然后进行dynamic filtering layer。作者除了让参数sample-specific,还产生了location-specific的参数。
概念图如下,其中input B依赖于之前的input A。
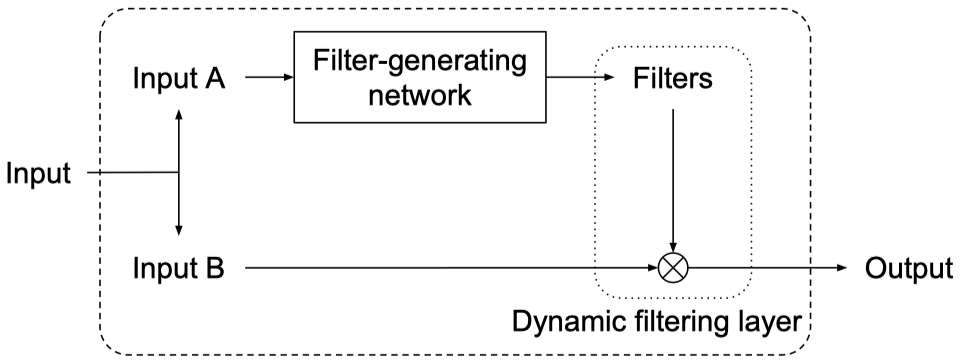
针对不同预测任务,作者设计了了不同的DFN。
在video prediction上,产生参数的网络是一个encoder-decoder的网络,输出是location-specific的卷积核。 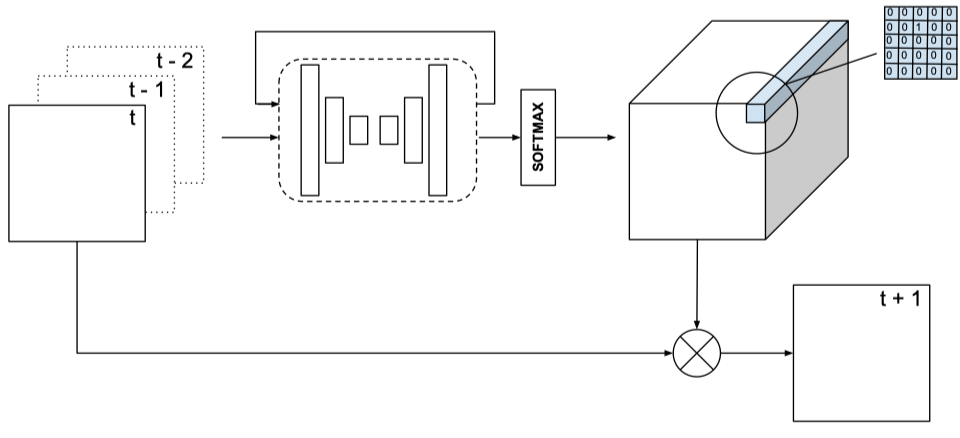 学习steerable filters,产生参数的网络是MLP。
学习steerable filters,产生参数的网络是MLP。
 ## HyperNetworks
## HyperNetworks
HyperNetworks ICLR 2017
Post not found: HyperNetworks[个人详细博客]核心贡献是将Hypernetwork扩展到了convolutional networks和long recurrent networks,证明其在使用更少的参数情况下,在序列模型和卷积网络的多个预测任务下都达到了不错的训练结果。
CNN:
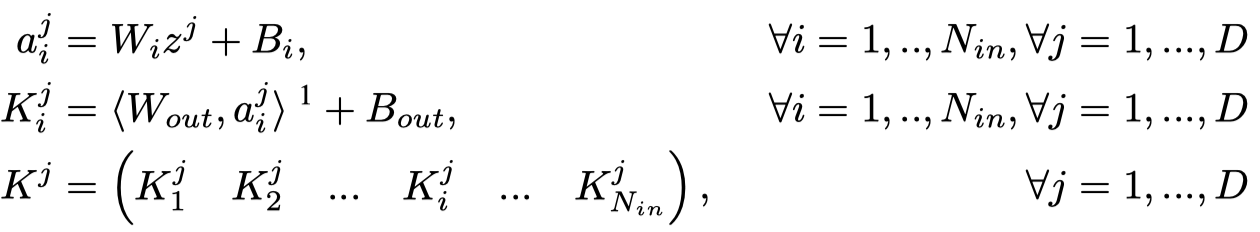
RNN:
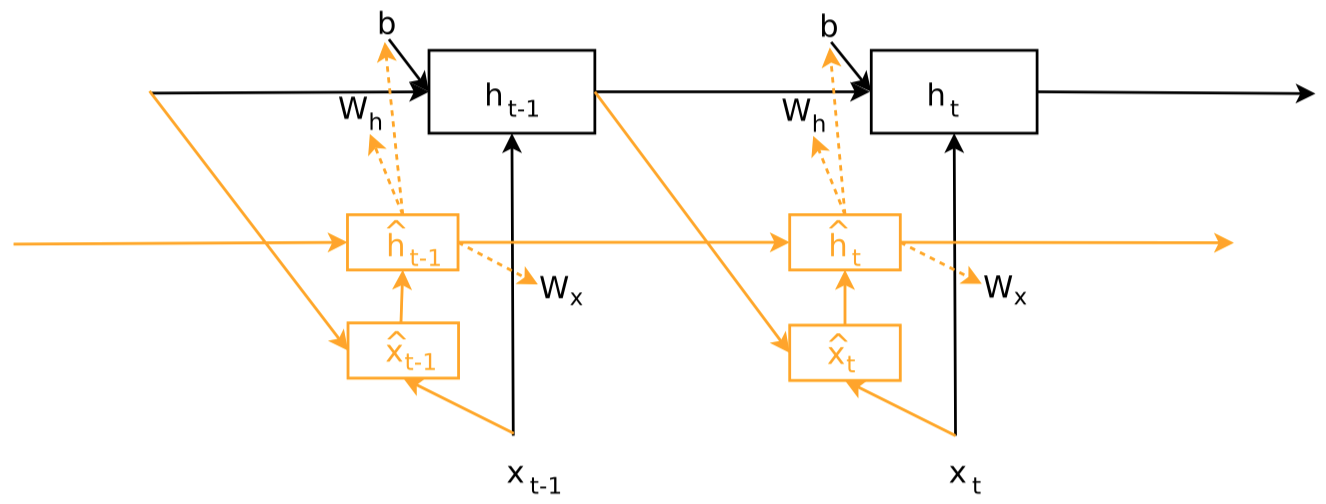
Nachmani et al.
Molecule Property Prediction and Classification with Graph Hypernetworks arxiv 2020
在molecule property prediction and classification任务上,将hypernetwork引入GNN提升模型效果。为了解决hypernetwork存在的不稳定问题,作者发现拼接current message和first message来作为hypernetwork的输入能够解决这一问题。
作者针对NMP-Edge network, Invariant Graph Network和Graph Isomorphism Network都引入了hypernetwork。下面重点关注对GIN的改进。
GIN原来的形式
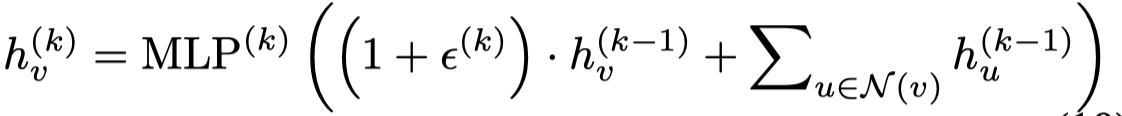
改进后:
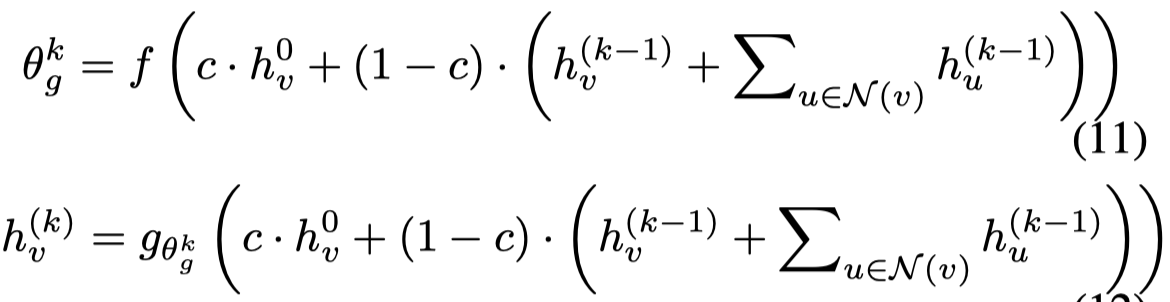
\(f\)和\(g\)是3层和2层使用tanh的MLP。可以看到,它使用current message和first message作为hypernetwork输入,hypernetwork同样是一个GNN的形式,以节点为中心。
Hyper-CNN
Hyper-Convolution Networks for Biomedical Image Segmentation arxiv 2021
作者将filter kernel的二维坐标作为输入,经过hypernetwork产生对应的kernel value。
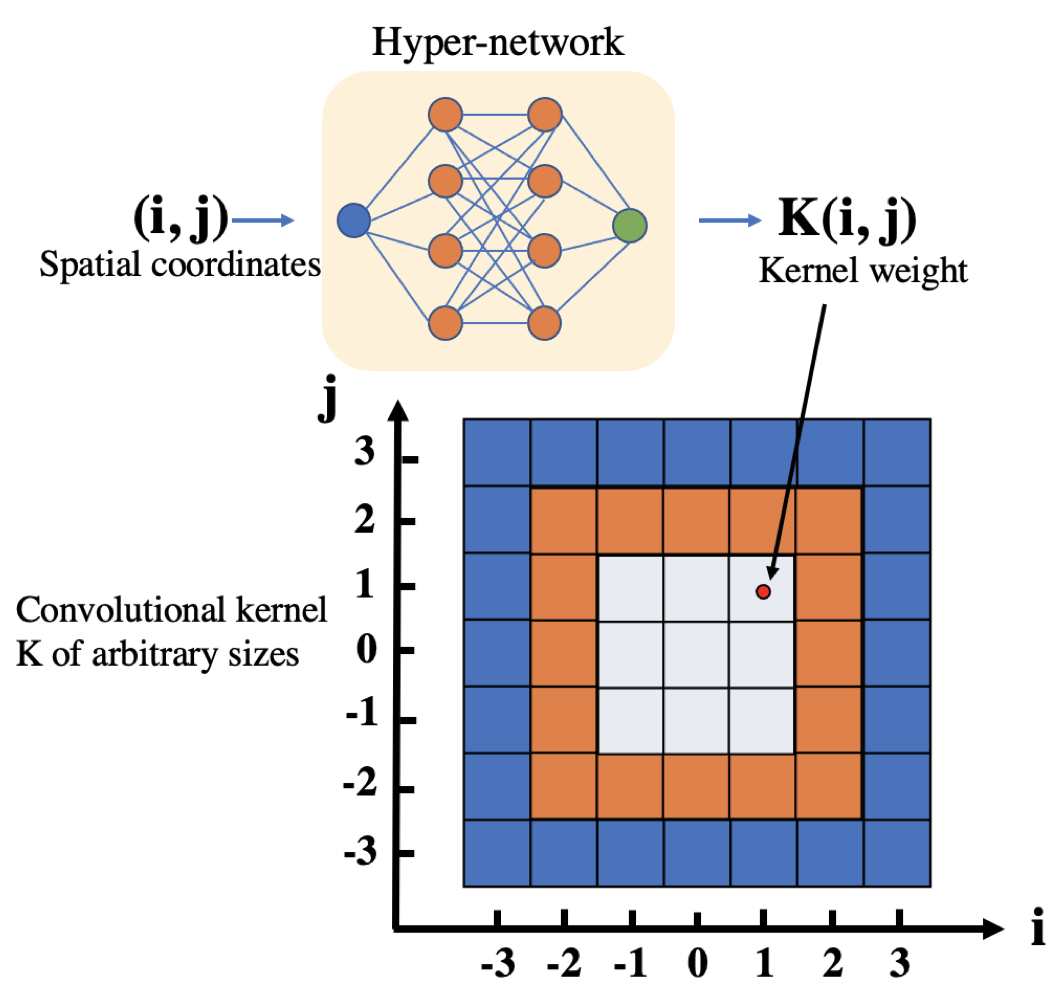
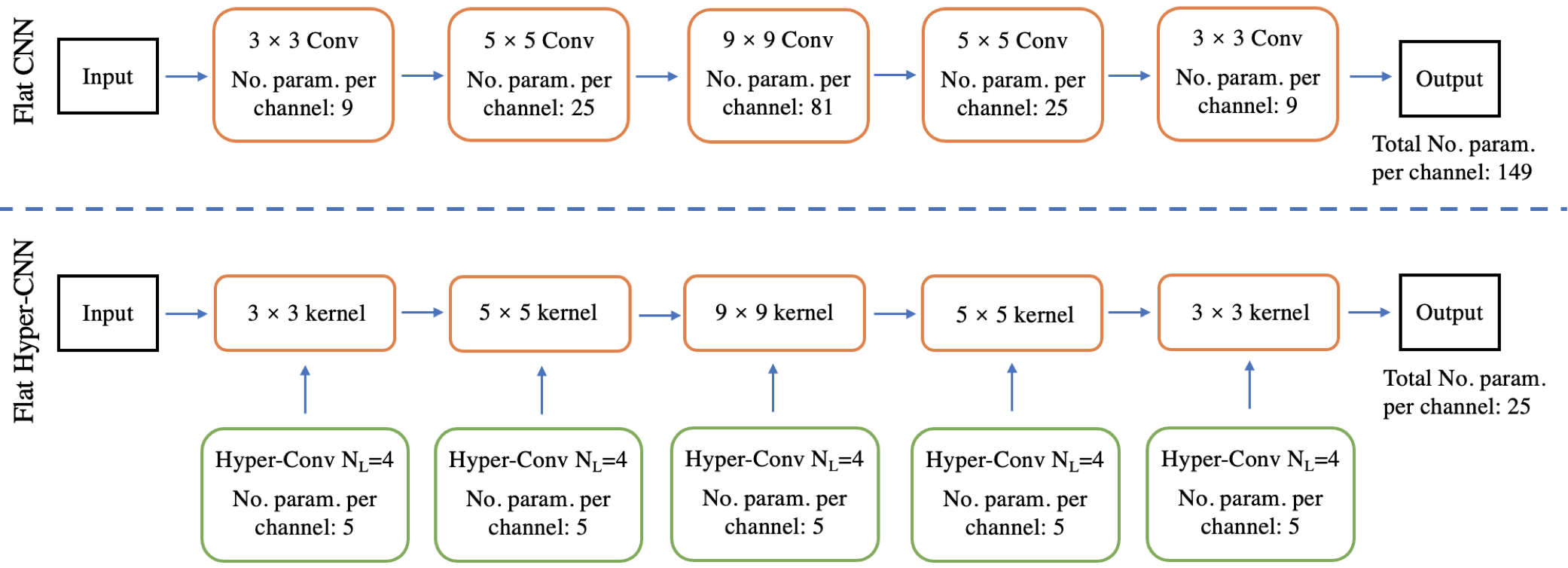
作者的hypernetwork是一个多层(四层)的1x1卷积网络,在实现的时候,主网络的每一层都有一个对应的hyper-CNN作为补充。
hypernetwork输入是表示x和y轴的两个channel输入,然后不断经过1x1卷积,不改变channel维度,最后输出weight。
HyperSeg
HyperSeg: Patch-wise Hypernetwork for Real-time Semantic Segmentation CVPR 2021
这篇文章是针对Real-time Semantic Segmentation任务,不是很了解这个任务,看起来是针对实时拍摄的image进行scene understanding,划分图像边界。
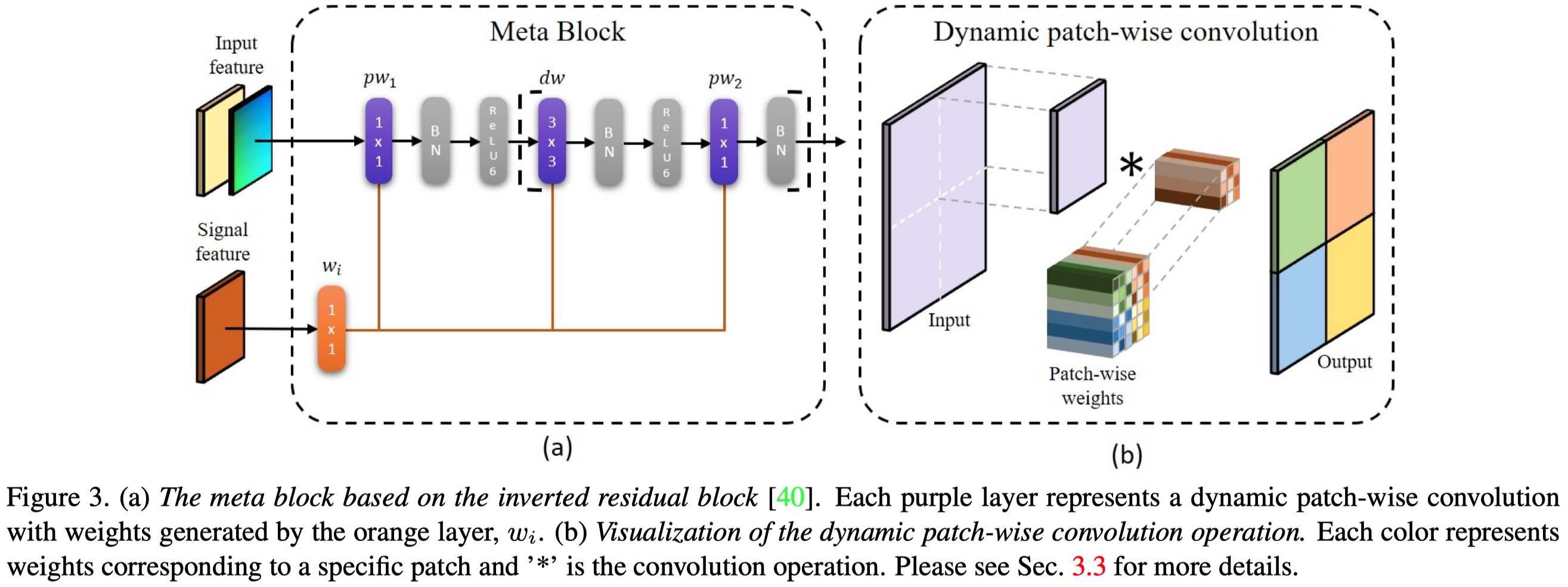
作者引入了hypernetwork,动态产生卷积weight,进行patch-wise的卷积操作,最后输出预测。hypernetwork使用了U-Net的结构(同样不了解)。
整体结构:
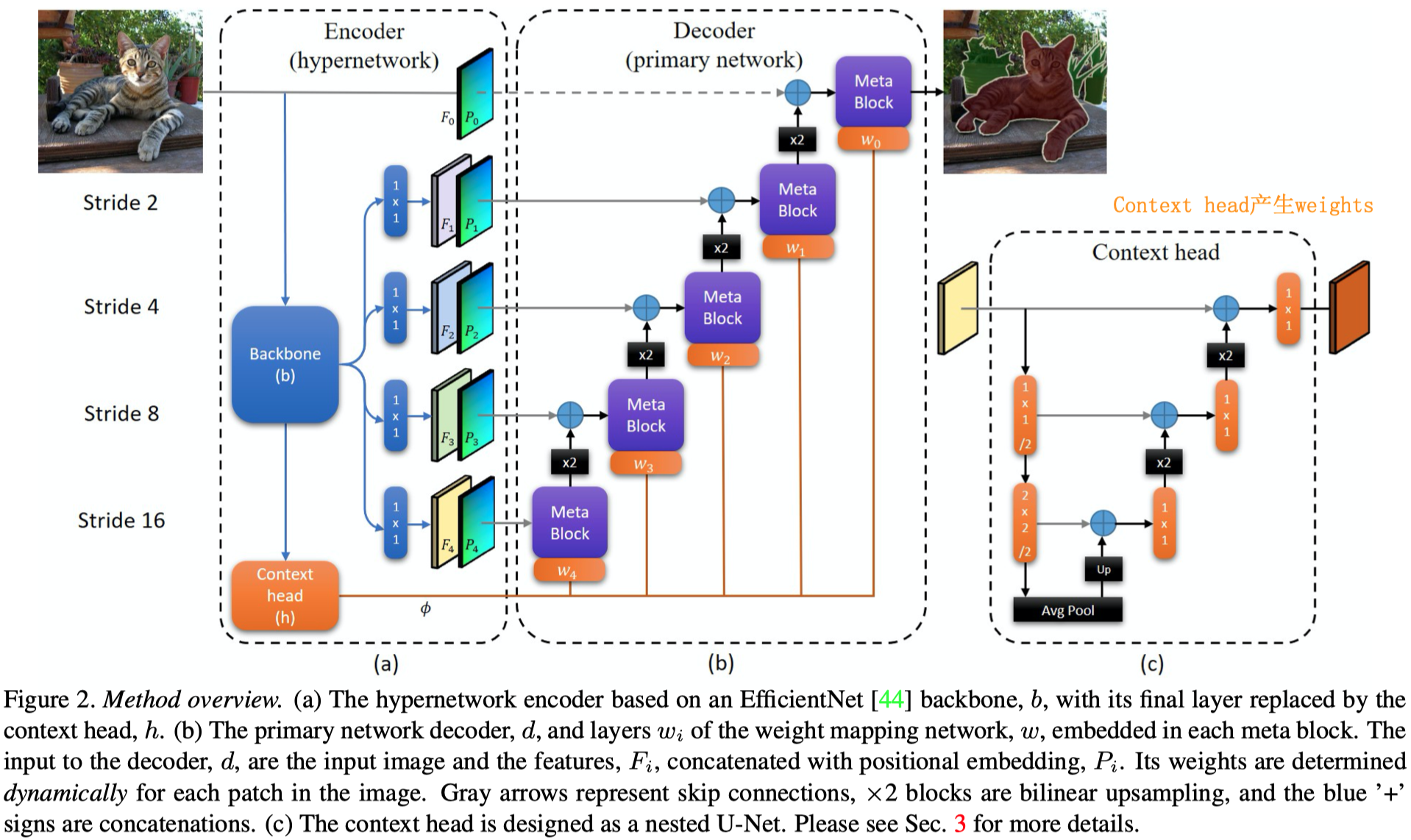
这里hypernetwork就是context head,它接受backbone的输出。backbone会把原来的image划分为不同resolution的feature map,最后的一个feature map输出给hypernetwork。
hypernetwork的输出是一个大的signal map,提供给不同的meta-block使用,划分方式是作者设计了一个根据channel和不同meta-block需要的weights进行划分,划分方法在附录里,没有细看。
LGNN
Node-wise Localization of Graph Neural Networks IJCAI 2021
作者认为对于整个图学习同样的weight matrix,可能导致模型倾向于建模最常见的pattern,而不是针对不同node的不同的local context进行学习。作者让graph中不同node拥有不同的weight matrix。
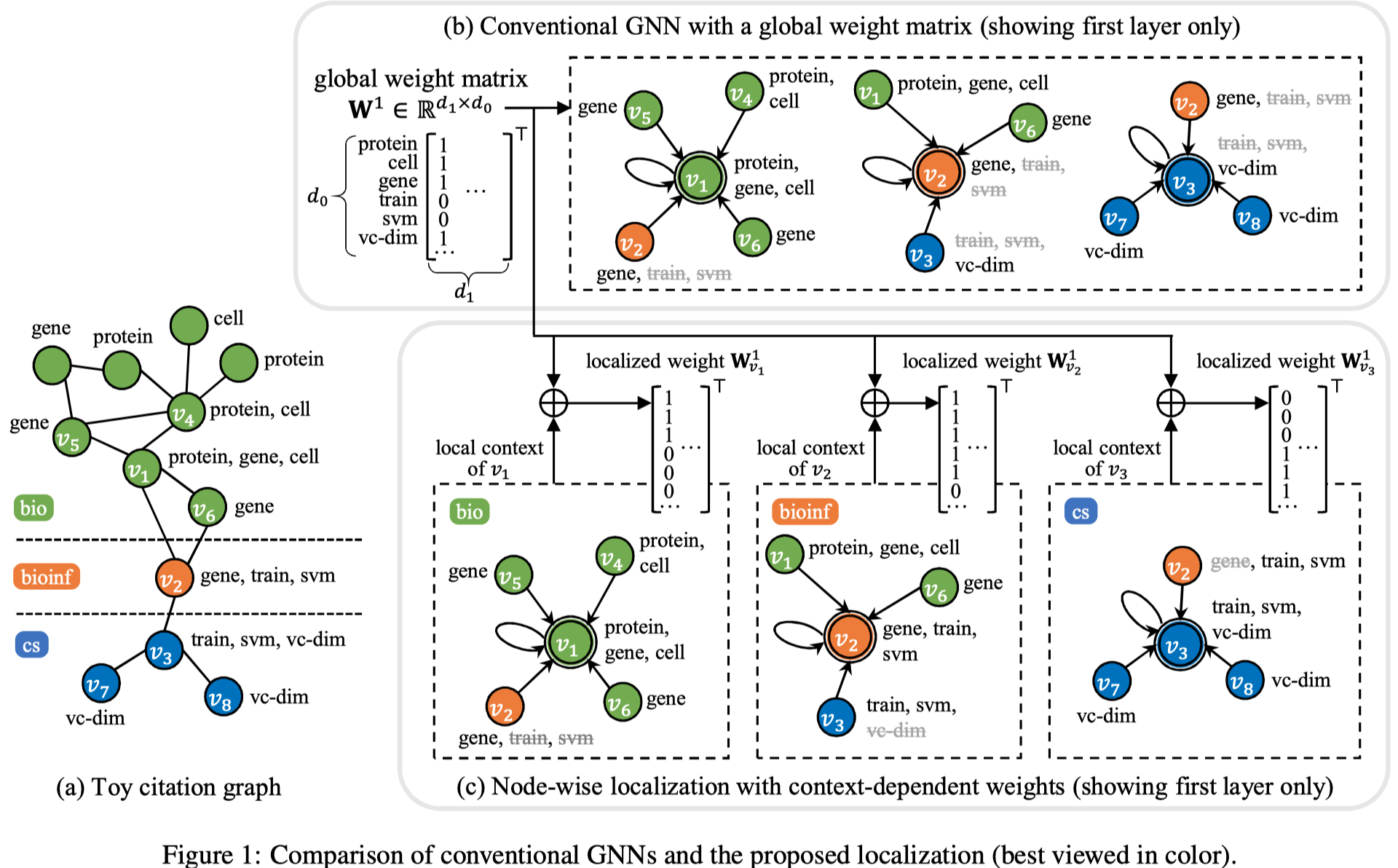
具体有两个Node-level localization和Edge-level localization.
Node-level localization
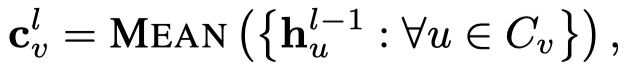

注意,这里没有给不同node都定义新的vector,而是直接从上一层的邻居直接mean聚合,然后进行转换,生成的向量\(a_v\)和\(b_v\)之后用于生成node \(v\)的weight matrix。
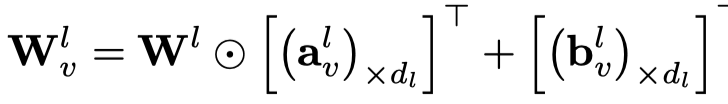
注意这里,是把\(a_v\)和\(b_v\)作为一行,然后复制,最后作用到graph global matrix\(W_l\)上。
Edge-level localization
作者对node \(v\)的不同邻居edge进一步建模:

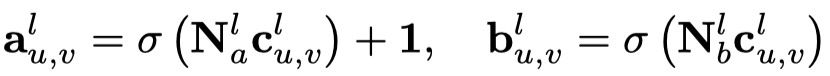
最后聚合: