LMM-Hallucinations-Collection1
Hallucinations in LMM
多模态大模型中的幻觉问题。
LMM alignment survey
Large Vision-Language Model Alignment and Misalignment: A Survey Through the Lens of Explainability. arXiv 2025-02. Northwestern University.
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in processing both visual and textual information. However, the critical challenge of alignment between visual and textual representations is not fully understood. This survey presents a comprehensive examination of alignment and misalignment in LVLMs through an explainability lens. We first examine the fundamentals of alignment, exploring its representational and behavioral aspects, training methodologies, and theoretical foundations. We then analyze misalignment phenomena across three semantic levels: object, attribute, and relational misalignment. Our investigation reveals that misalignment emerges from challenges at multiple levels: the data level, the model level, and the inference level. We provide a comprehensive review of existing mitigation strategies, categorizing them into parameter-frozen and parameter-tuning approaches. Finally, we outline promising future research directions, emphasizing the need for standardized evaluation protocols and in-depth explainability studies.
作者认为多模态中语义的对齐有2种:
- Representational alignment refers to the degree of correspondence between visual representations \(v \in V\) and textual representations \(t \in T\) within the model’s internal embedding space \(E\). 表征的对齐
- Behavioral alignment refers refers to the model’s ability to generate accurate, factual, and consistent textual responses \(y \in Y\) when processing image inputs \(x \in X\). 输出的对齐
LMM可以对齐的理论依据,As Huh et al. argue in their Platonic Representation Hypothesis (Huh et al., 2024), all modalities are measurements of a real world that generates our observations. 多模态就是相同现实各种测量,表面上不一样。
从算法的角度讲,现有研究依据证明,在联合训练之前,分别独立训练的单模态表征已经学习到某些相似的语义结构。这是因为训练的数据都是来源于人类,人类生成的多模态数据内在有某种相似语义。这种学习到的相似的语义结构可以作为后续对齐训练的良好起点,对齐的微调会不断优化这种对齐。
不对齐的现象有3种:
- Object Misalignment:不正确的object
- Attribute Misalignment:不正确的object的形容词和副词,通常被看作属性
- Relation Misalignment:通常是object的动作关系或者空间关系

不对齐发生的原因:
- Dataset Level:低分辨率图片、含糊的caption、错误语法的caption。
- Model Level:
- LLM和visual encoder通常是独立训练的,并且可能是更加依赖LLM的能力来理解图像,所有最终构造得到的MLLM可能注意力分布不均。
- SFT可能会破坏预训练阶段的knowledge
- visual对image内容的感知,可能和LLM的先验knowledge冲突。比如visual encoder探测到一个绿色的西红柿,但是LLM可能总是会认为西红柿应该是red的
- Inference Level:out-of-distribution (OOD) generalization problem。推理时遇到的image特征可能和微调时不一样;需要处理的prompt不一样;需要处理的视觉任务不一样
根据大模型是否需要微调,消除不对齐的方法有:

VCD
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding. CVPR 2024. 阿里达摩. 代码.
Large Vision-Language Models (LVLMs) have advanced considerably, intertwining visual recognition and language understanding to generate content that is not only coherent but also contextually attuned. Despite their success, LVLMs still suffer from the issue of object hallucinations, where models generate plausible yet incorrect outputs that include objects that do not exist in the images. To mitigate this issue, we introduce Visual Contrastive Decoding (VCD), a simple and training-free method that contrasts output distributions derived from original and distorted visual inputs. The proposed VCD effectively reduces the over-reliance on statistical bias and unimodal priors, two essential causes of object hallucinations. This adjustment ensures the generated content is closely grounded to visual inputs, resulting in contextually accurate outputs. Our experiments show that VCD, without either additional training or the usage of external tools, significantly mitigates the object hallucination issue across different LVLM families. Beyond mitigating object hallucinations, VCD also excels in general LVLM benchmarks, highlighting its wide-ranging applicability. Codes will be released.
作者认为多模态大模型中的幻觉有两方面原因:
- statistical biases inherent in training data (e.g., prevalent but superficial object correlations) [1, 2, 19] 继承自预训练的统计bias,常见但是粗浅不正确的object关联
- over-reliance on language priors embedded within the powerful LLMs used as decoders [22, 38, 69, 75]. 过度依赖LLM导致过于依赖语言先验bias
作者然后实验验证了visual uncertainty会增强上面两种bias。具体做法是仿照扩散模型,给原始image增加T步的高斯噪音,然后测试LMM的幻觉现象。
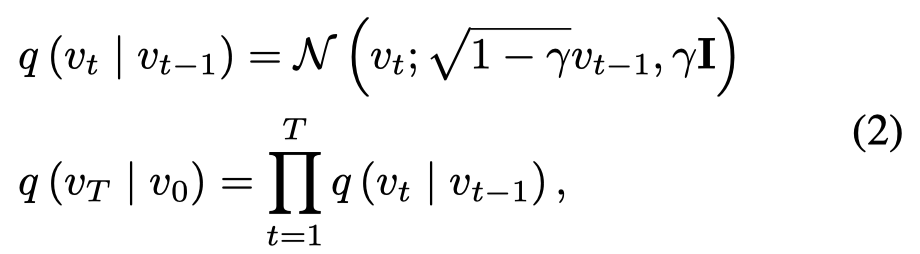
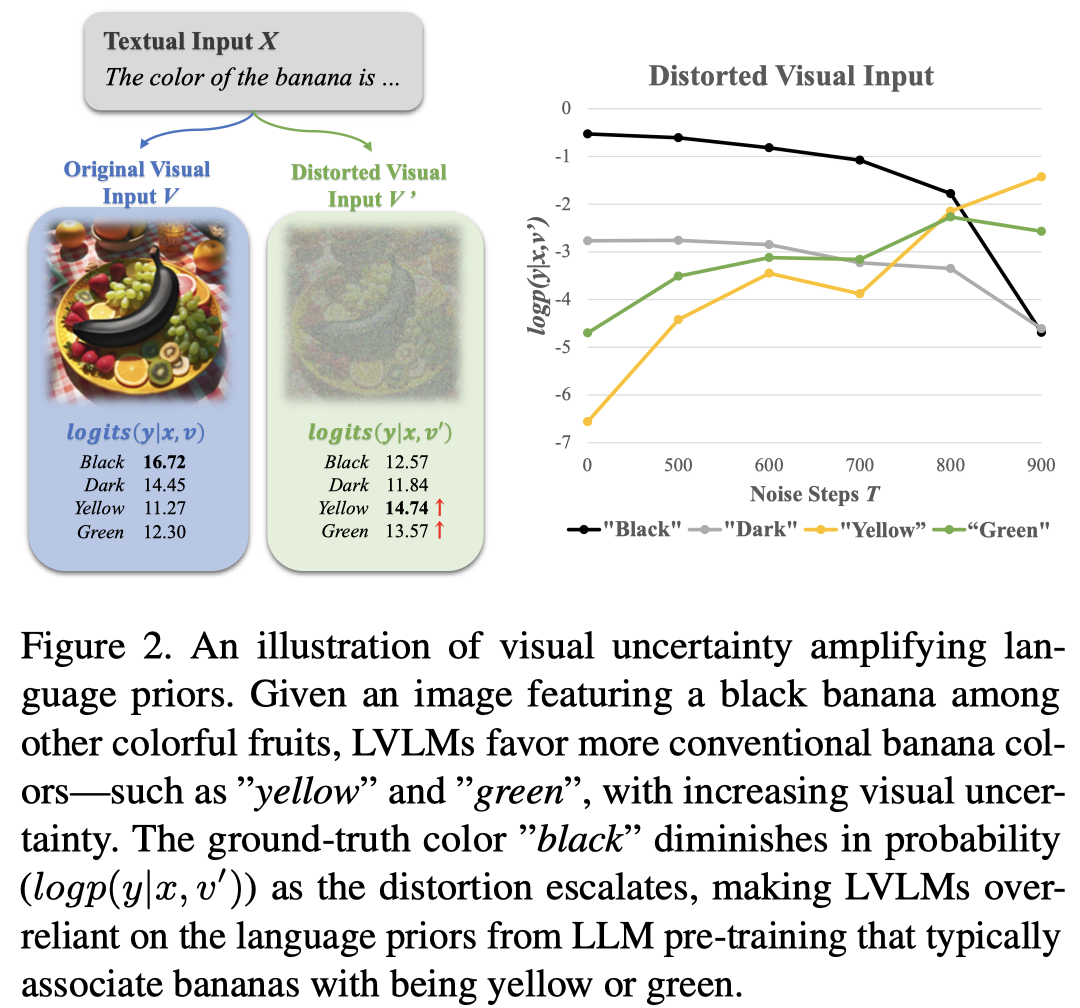
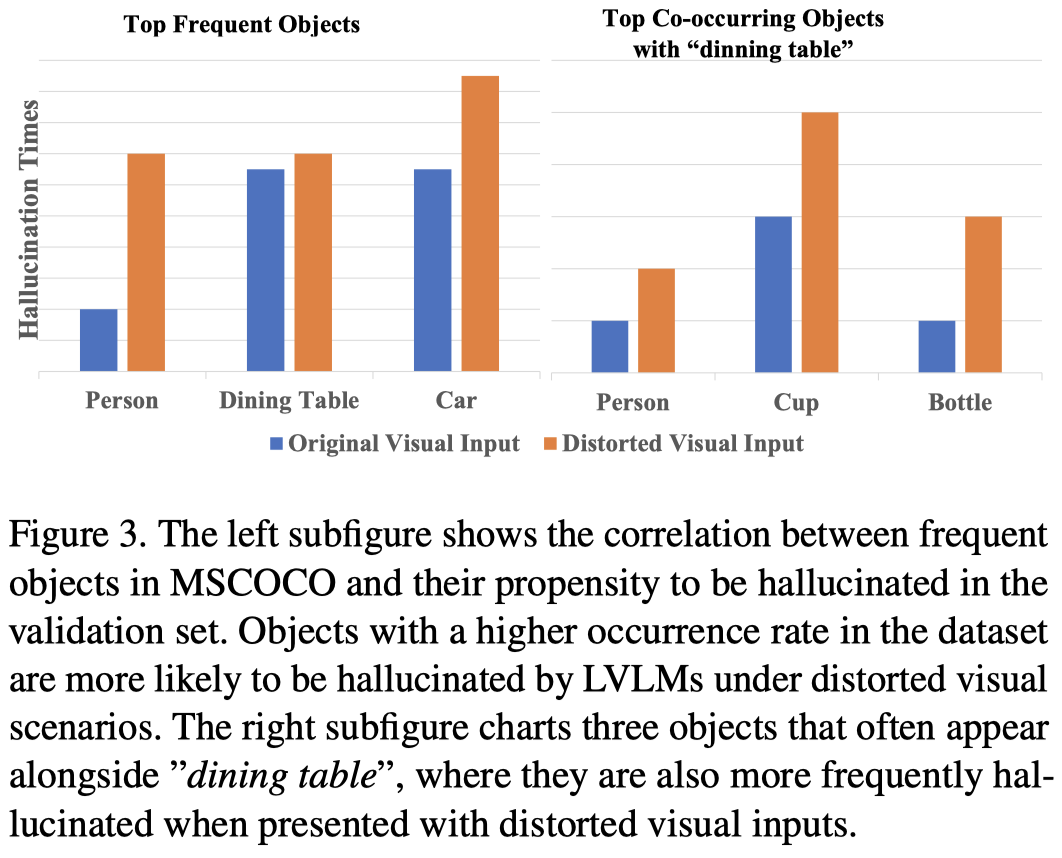
MLLM的幻觉,更有可能是在预训练data里常见的,或一起出现的objects。
为了减低这种由于视觉不确定性带来的幻觉程度,作者提出了Visual Contrastive Decoding方法:
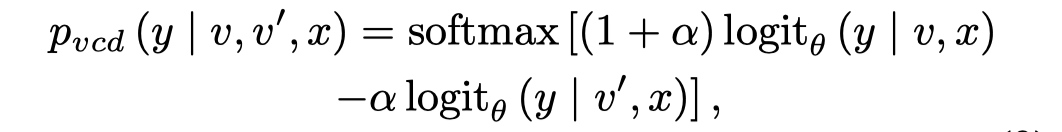
简单来说,就是原始image输出的logit分布加上正常图像的logit分布与噪音增强的logit分布之间的差距。上述式子很类似Classifier-free diffusion guidance模型中的式子。实验中\(\alpha=1.0\)。
噪音增强的logit分布更多的暴露了幻觉的token分布。以上面的case图为例,利用上面的式子,就可以降低语言先验引起的错误Yellow token的logit。
下面是方法图:
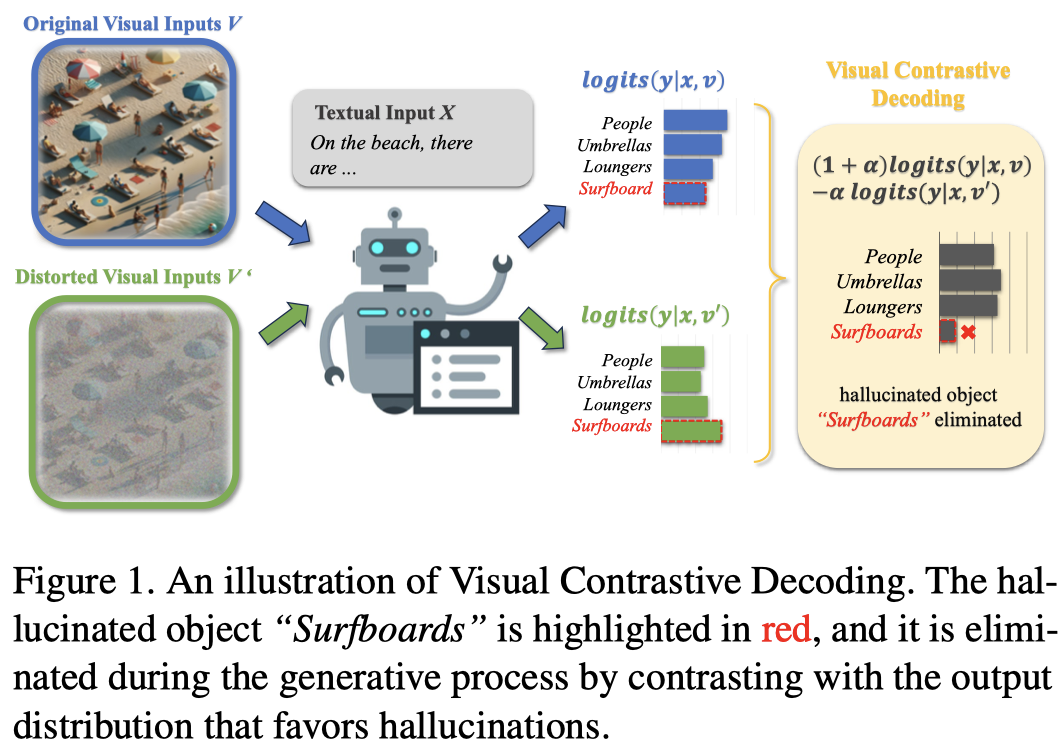
上面的式子是对于所有的token都进行调整。但是由于即使是损坏的image的输入,可能仍然有正确的输出,如基本的语义、常识推理等。很多token根本没有必要调整logit,或者是参与比对。因此,作者采用了一个Adaptive Plausibility Constraints的策略来只选择一部分的候选token。
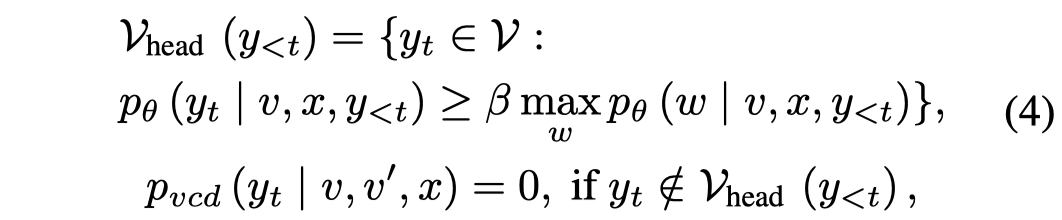
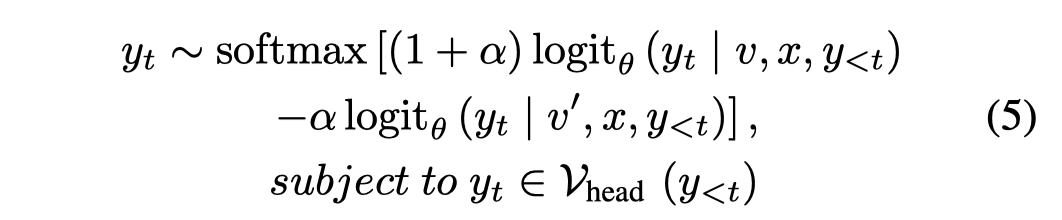
只有logit概率大于\(\beta\ w\)的token会被放入到\(\mathcal{V}_{head}\)里用于解码(\(\beta=0.1\))。本质上,对于在输入正常image情况下,输出非常confident的token,使得其候选token数量很少。
VGDG
Visual Description Grounding Reduces Hallucinations and Boosts Reasoning in LVLMs. University of Maryland. ICLR 2025. 代码.
Large Vision-Language Models (LVLMs) often produce responses that misalign with factual information, a phenomenon known as hallucinations. While hallucinations are well-studied, the exact causes behind them remain underexplored. In this paper, we first investigate the root causes of hallucinations in LVLMs. Our findings reveal that existing mitigation techniques primarily reduce hallucinations for visual recognition prompts—those that require simple descriptions of visual elements—but fail for cognitive prompts that demand deliberate reasoning. We identify the core issue as a lack of true visual perception in LVLMs: although they can accurately recognize visual elements, they struggle to fully interpret these elements in the context of the input prompt and effectively link this recognition to their internal knowledge, which is critical for reasoning. To address this gap, we introduce Visual Description Grounded Decoding (VDGD), a simple, robust, and training-free method designed to enhance visual perception and improve reasoning capabilities in LVLMs. VDGD works by first generating a detailed description of the image and appending it as a prefix to the instruction. During response generation, tokens are sampled based on their KL divergence to the description, favoring candidates with lower divergence. Experimental results on multiple visual reasoning benchmarks and LVLMs demonstrate that VDGD consistently outperforms existing baselines 2% - 33%. Finally, we introduce VaLLu, a benchmark designed for comprehensive evaluation of the cognitive capabilities of LVLMs.
Issue:作者发现之前很多training-free的消除MLLM幻觉的技术,主要是完成了对于简单视觉识别prompt的幻觉;但是对于更复杂的,需要推理的prompt效果不好。作者证明LMM有必要的推理能力和内在知识,但是没有能够很好的感知视觉信息,把视觉内容和内在知识以及推理能力结合起来。
Solution:作者进行了很多分析实验,首先作者假设LMM进行信息处理时遵守以下步骤:

- Visual Recognition (VR) focuses on identifying visual elements and their relationships within the image, such as describing objects or specific details. 识别视觉元素和关系
- Visual Perception (VP) extends beyond VR by interpreting and contextualizing these elements within the broader scene (Fu et al., 2024), essential for tasks requiring more than basic recognition. 视觉感知要进一步解释视觉元素,能够在更加丰富的上下文场景下解释image
- Prompts that demand knowledge-specific insights (also known as information-seeking prompts) engage in knowledge extraction (KE) learned from pre-training. 知识抽取是指需要利用LLM在预训练阶段获得的knowledge
- prompts requiring reasoning involve combining visual data, textual prompts, and extracted knowledge to generate a response. 把各种元素综合利用的推理能力
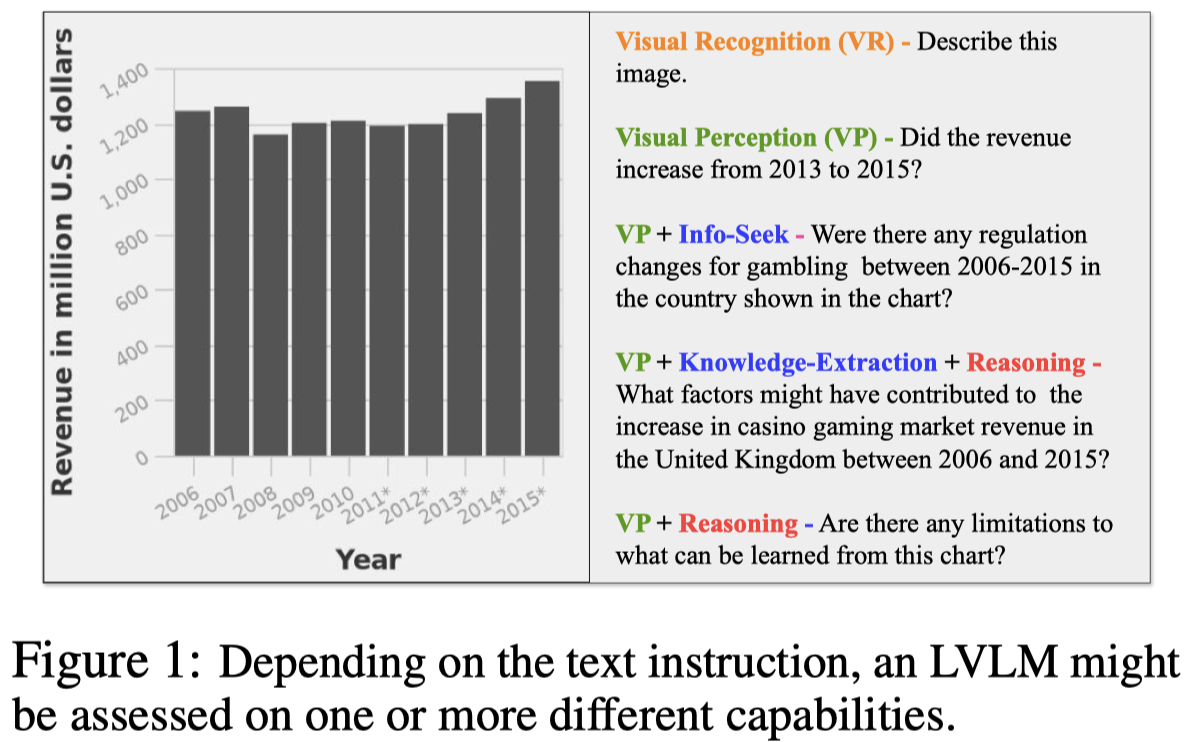
视觉识别依赖于vision encoder,knowledge extraction依赖于LLM,reasoning依赖于LLM,视觉感知可能是在对齐的时候隐式的学习,视觉感知VP是作为能够将视觉识别能力和推理能力结合起来的中间桥梁。
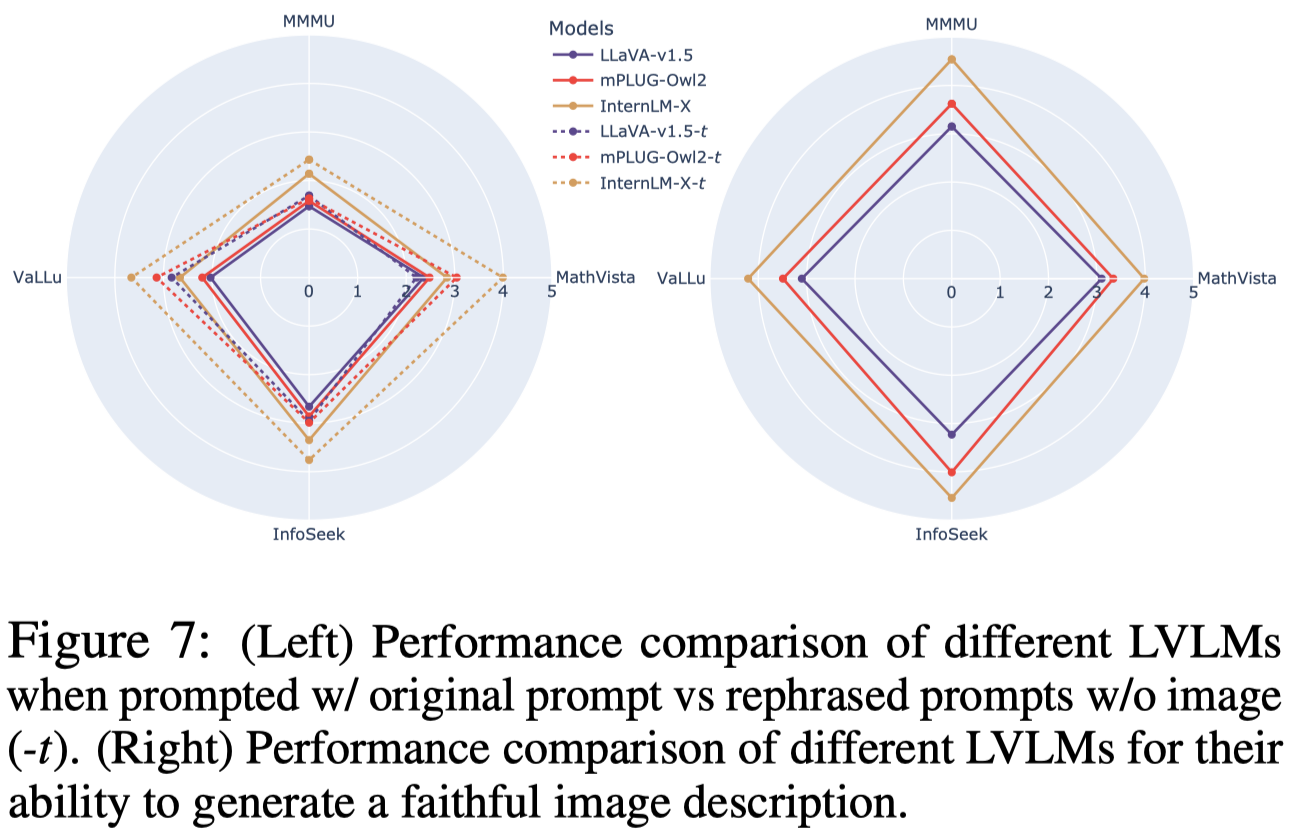
随后作者证明,之前的幻觉消除方法主要是提升了VR的能力(左图),而没有减小其它幻觉(右图):
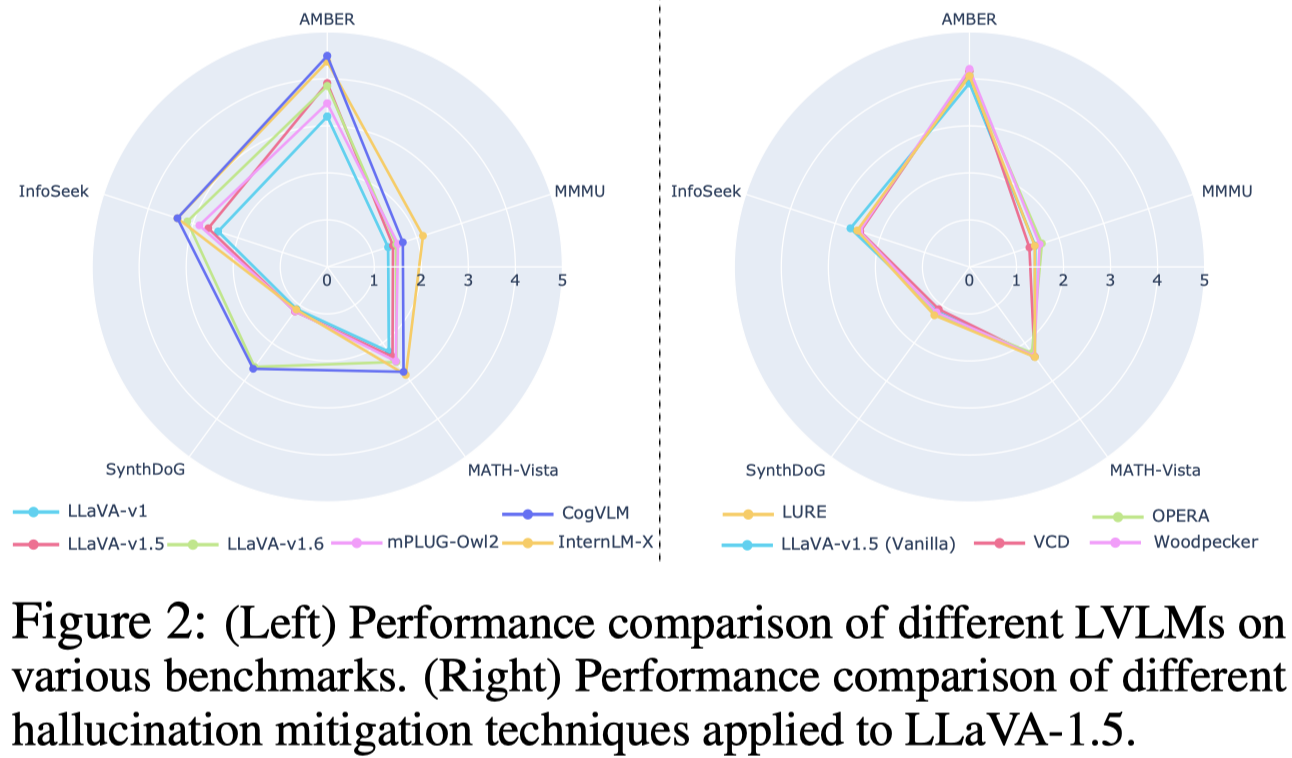
这是使用的不同数据集:AMBER (visual recognition), SynthDoG (OCR), MMMU (expert-level reasoning), MathVista and MATH-Vision (mathematical reasoning), MMC (chart understanding), and MME and HallusionBench.
进一步,作者首先认为幻觉描述短语有3类:
- Object Hallucinations: There are hallucinated visual elements which are objects.
- Relation Hallucinations-Action/Verb Hallucination: Hallucinated visual elements that are not objects but just actions or verbs, e.g., walking, etc.
- Relation Hallucination: Hallucinated visual elements that define relationships (spatial or other kinds) between objects.
这三类幻觉短语的识别依赖于GPT-4对image description进行分析:

作者认为引起上面3类幻觉短语的原因有4种:

- Language Hallucinations:LMM语言先验带来的幻觉
- Vision Hallucinations:不正确的识别image元素带来的幻觉
- Style Hallucinations:风格幻觉,模仿多模态微调数据集里的数据风格而强行产生的幻觉
- Instruction Tuning (IT) Hallucinations:由于多模态微调数据集内存在相似数据,而产生的幻觉
为了识别出上面的4种幻觉原因,作者提出了一个算法:

核心操作是,作者引入了纯文本的,没有经过多模态对齐微调的base LLM,让其输入和LMM一样的前置context tokens(不包括image,只有instruction和生成的前面\(t-1\) token)。然后计算base LLM下一个\(t\)-th token的分布概率,从大到小排序,查看原来多模态LMM的概率最大的token,在base LLM输出分布中的rank \(\eta\),记为Base rank。
base rank可以用来反映image加入对于回复的影响程度,越大,证明image的影响越大。
换句话说,在经过了微调的aligned LLM上输出的最大logit对应的token,在base LLM的logit分布中从大到小的排序顺序。如果还是最大的(\(\eta=0\)),就是unshifted;如果是第一或者第二大(\(0<\eta\leq 2\)),就是marginal;否咋,就是shifted。
算法核心步骤:
- 利用GPT-4获取幻觉phrase
- 计算幻觉短语在多模态微调数据集内,最相似的数据样本集合\(S_R\)
- 计算Base rank
- 如果Base rank=0,纯文本LLM和LMM幻觉token都是概率最大的,就是language hallucination引起的
- 如果Base rank>0并且短语在\(S_R\)内出现过,LMM幻觉的token是在多模态微调数据集里出现过类似的,那就是IT幻觉引起的;
- 如果Base rank>0并且短语没有在\(S_R\)内出现过,幻觉短语是Relation幻觉,就认为style幻觉引起的;否则就是vision幻觉引起的
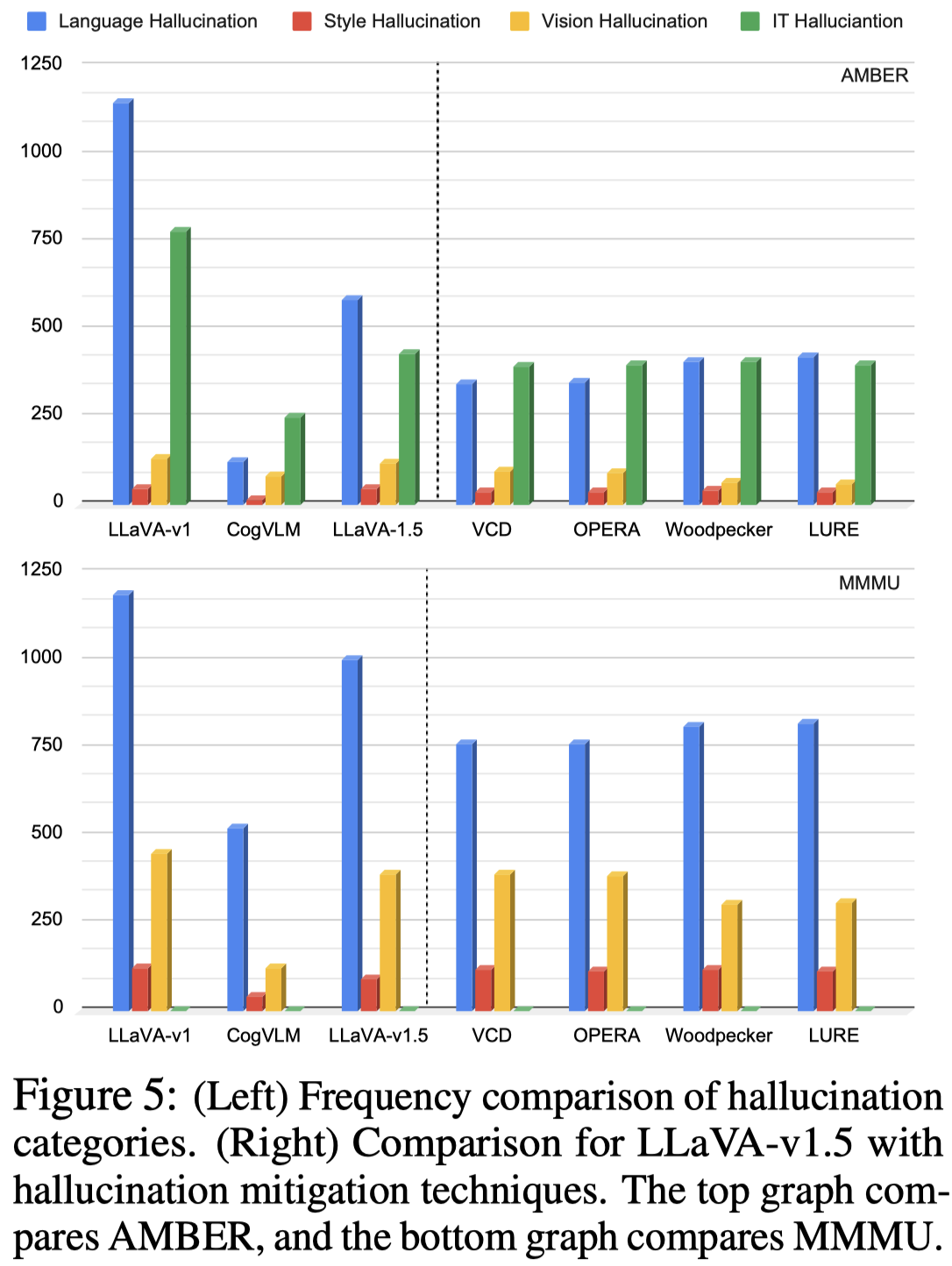
从上面的统计结果可以看出,语言幻觉和IT幻觉是最大的影响因素;之前的方法更加擅长消除语言和vision幻觉带来的幻觉短语描述。也就是说之前的方法更加擅长提升视觉识别能力。
进一步的实验发现LMM实际上更加依赖语言,而不是视觉信息来进行推理的:
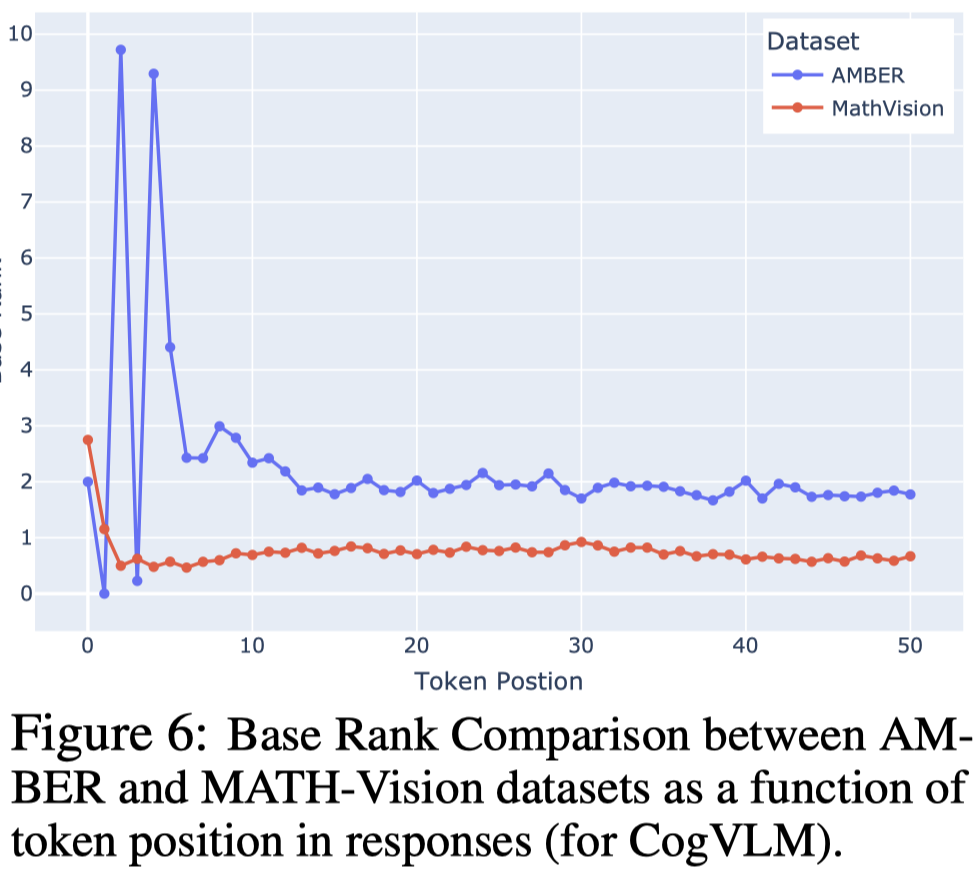
在更加需要视觉推理的MathVision数据集内,image发挥的作用反而降低了(base rank更低了)。
下面实验显示,如果image用准确的文本描述,输入到LMM内,然后对于推理任务,LMM就能够产生更少的幻觉。这证明LMM有必要的推理能力和内在知识,但是没有能够很好的感知视觉信息,把视觉内容和内在知识以及推理能力结合起来。
下面是作者对于非幻觉/幻觉短语中首个token分布logit的统计,\(k\)是把logit按照从大到小的顺序排列,然后寻找到的拐点(elbow)。

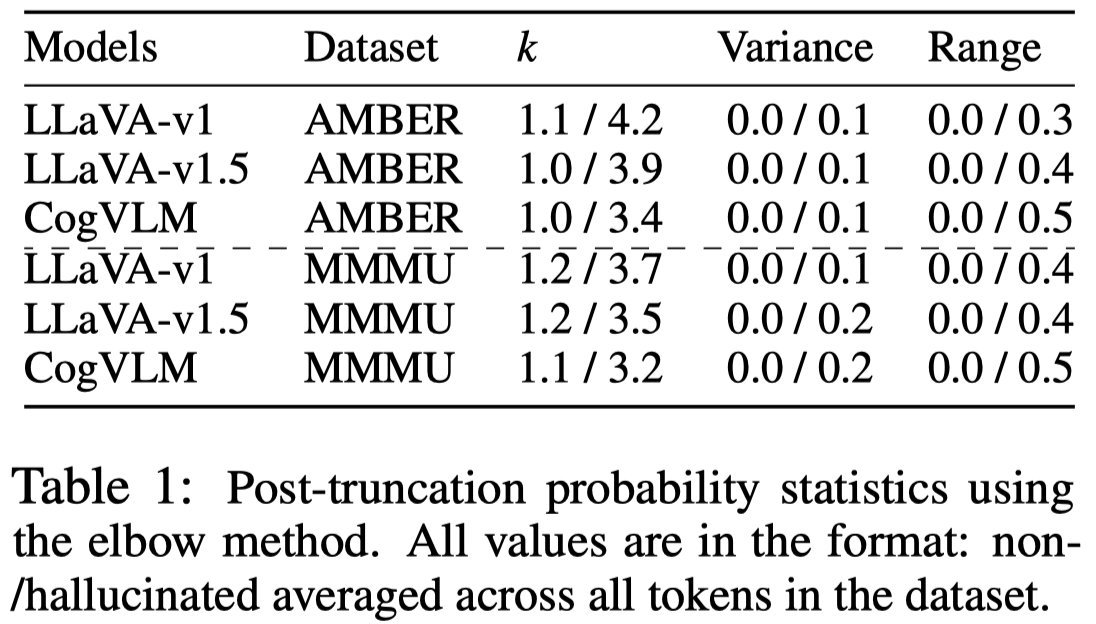
出现幻觉的token对应的logit分布,有更多confident相近的候选,\(k\)更大。
作者的方法,先是生成image的描述,然后惩罚偏移描述太大的新token的logit。
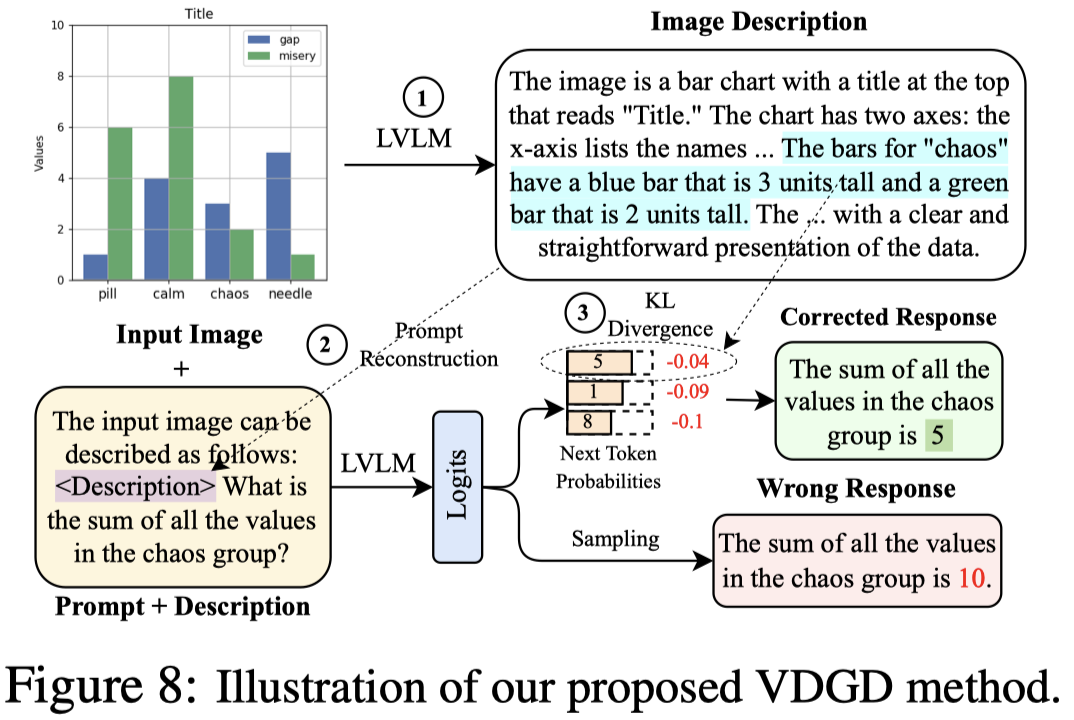

和VCD方法类似,作者会先截取概率较大的token:
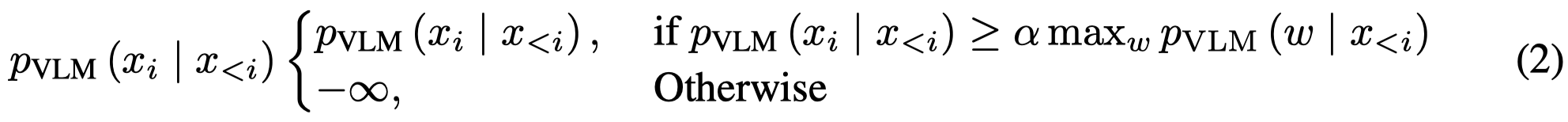
然后,作者计算当前候选token的one hot向量,和输入prompt \(n\)个token的logit分布,最小的KL散度:
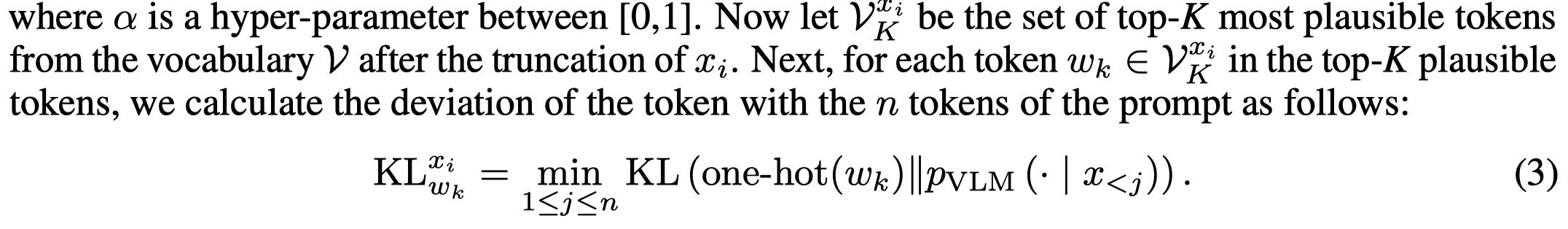
当前候选token的logit减去上面的KL散度,就得到了新的logit。
部分实验结果:

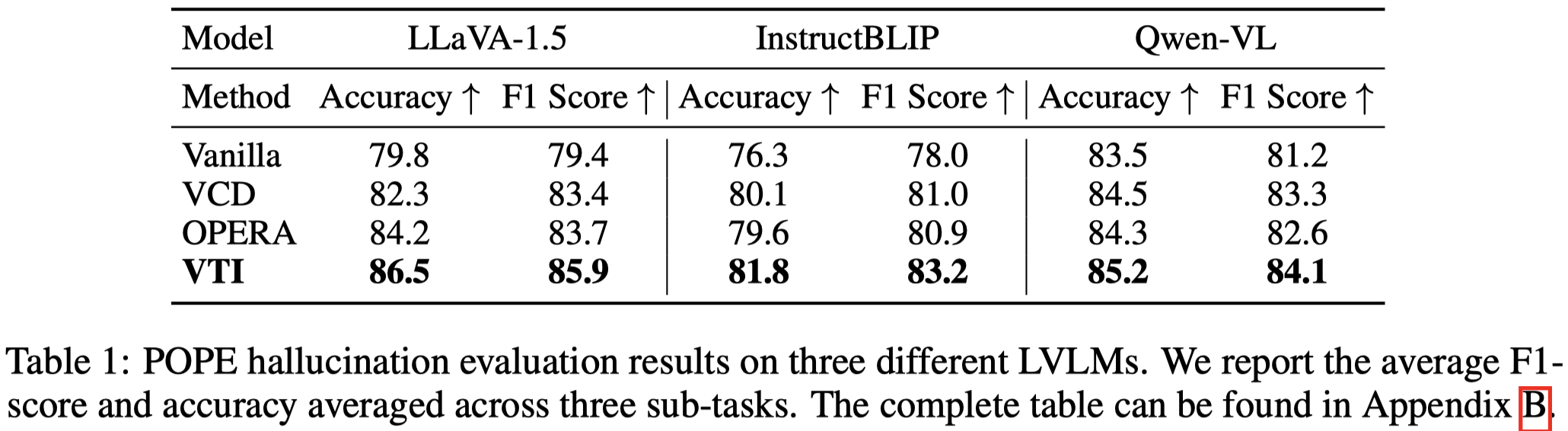
VTI
Reducing Hallucinations in Large Vision-Language Models via Latent Space Steering. 斯坦福. ICLR 2025. 代码.
Hallucination poses a challenge to the deployment of large vision-language models (LVLMs) in applications. Unlike in large language models (LLMs), hallucination in LVLMs often arises from misalignments between visual inputs and textual outputs. This paper investigates the underlying mechanisms of hallucination, focusing on the unique structure of LVLMs that distinguishes them from LLMs. We identify that hallucinations often arise from the sensitivity of text decoders to vision inputs, a natural phenomenon when image encoders and text decoders are pre-trained separately. Inspired by this, we introduce Visual and Textual Intervention (VTI), a novel technique designed to reduce hallucinations by steering latent space representations during inference to enhance the stability of vision features. As a task-agnostic test-time intervention, VTI can be easily applied to any problem without additional training costs. Extensive experiments demonstrate that it can effectively reduce hallucinations and outperform baseline methods across multiple metrics, highlighting the critical role of vision feature stability in LVLMs.
Issue:之前探究幻觉底层机制的方法,没有特别区分LLM和LMM之间的区别。即从image的vision encoder信息流是如何影响幻觉的。
Solution:作者认为LMM里,vision encoder的输入是text decoder的序列输入,因此其学习特征的效果会理所当然的影响输出结果。而一个鲁棒的vision encoder,给image加入噪音,如果这个噪音没有大幅改变image的语义,vision encoder的输出改变应该比较小。
作者先给image加入噪音,然后统计噪音加入后vision embedding变化的方差。如下面的左图所示,绝大部分的方差都靠近0,但是有15%的image embedding表现出很大的方差。
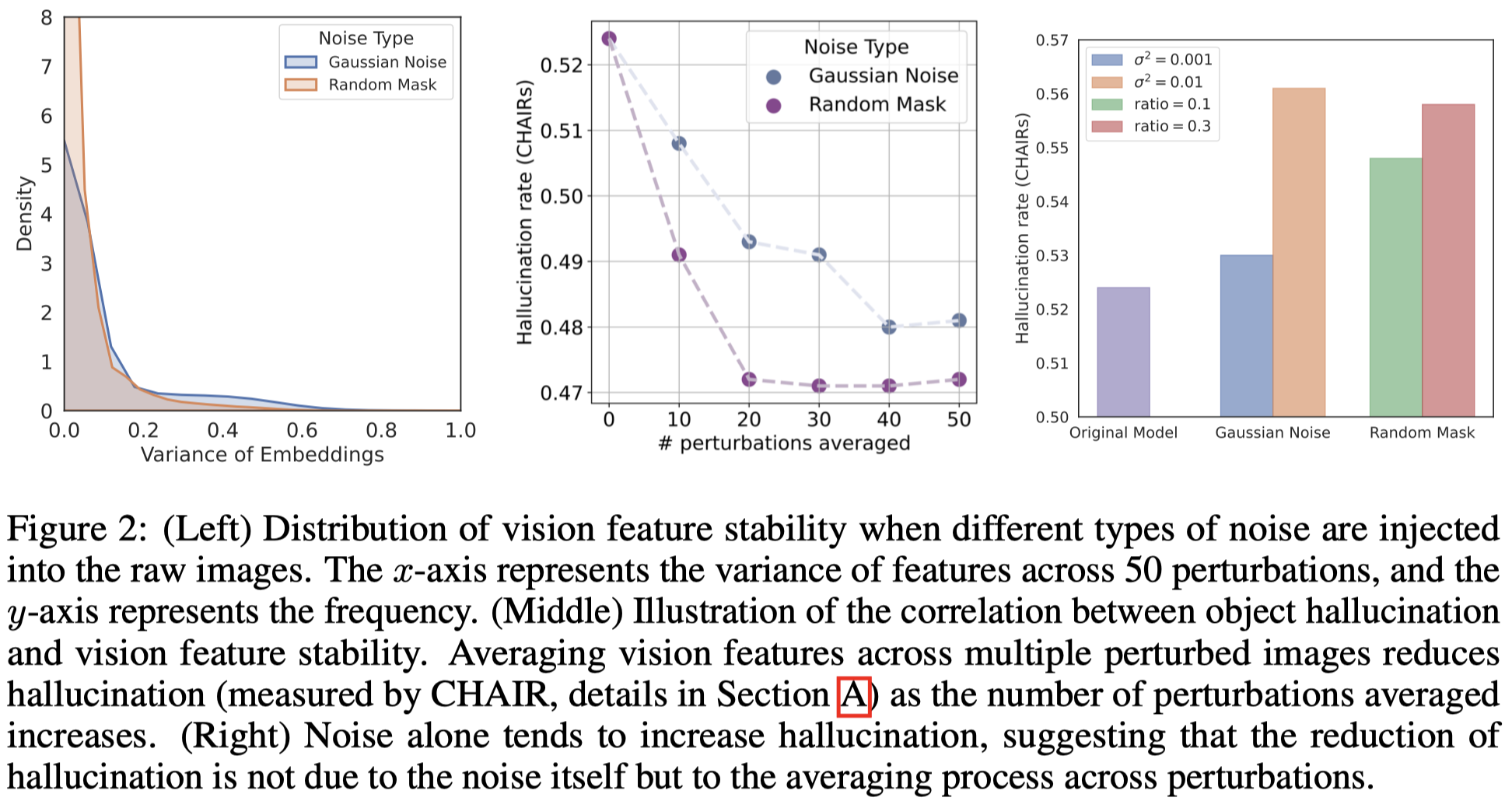
进一步,作者考虑如果学习更加鲁棒的vision embedding的效果。如果平均了加入不同噪音后的vision embedding,更加鲁棒的embedding导致了幻觉降低,如上图中所示。
需要注意的是,单纯加入噪音而不平均,只会导致幻觉增加,如上图右图所示。
上面这种做法的坏处在于,(1)需要几十次的重复输入image,然后平均,极大增加推理time成本;(2)加入噪音的操作本身会损坏一些原始image信息。
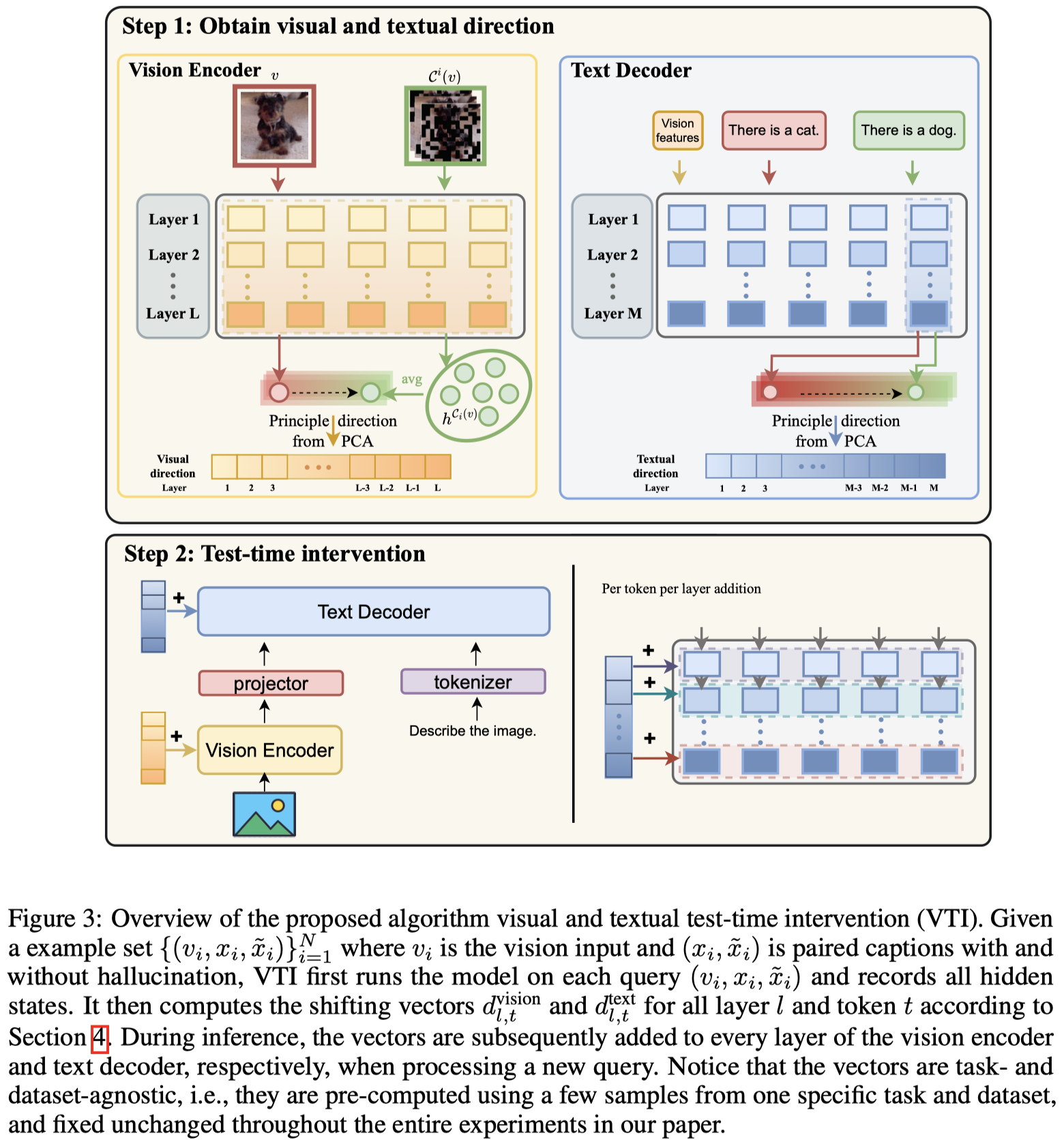
作者的方法是选择50个数据样本提前计算intervention direction,修改embedding。
首先对于单个样本的image,加入random masking的噪音,计算出每一层第\(t\)个位置的带有噪音的embedding。噪音的embedding平均之后:
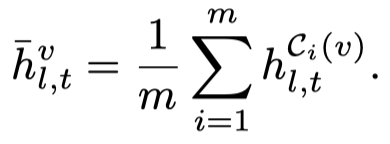
计算visual shifting vector:
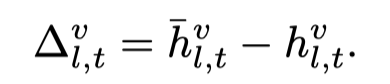
接下来需要去除掉这个shifting vector的image-specific的信息,作者把50个example的visual shifting vector拼接,然后利用PCA计算principal direction:
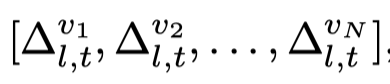
对于text,作者follow Analyzing and mitigating object hallucination in large vision-language models.的做法,为正确的image caption \(x\)加入幻觉得到\(\tilde{x}\),然后仿照上面的做法,计算text embedding的变化:
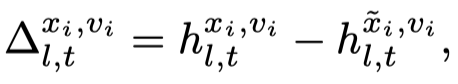
需要注意的是,因为text embedding是因果建模的,作者只使用last text token的embedding来计算principal direction。
最后,利用visual and textual direction来干预各个层的embedding:

\(\alpha,\beta\)常设置为0.4。